

20162320刘先润大二 实验二
1-实现二叉树
实验目标:完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)
实验步骤:
public LinkedBinaryTree<T> getRight() {
if (root == null)
throw new EmptyCollectionException("Get right operation " + "failed. The tree is empty.");
LinkedBinaryTree<T> result = new LinkedBinaryTree<T>();
result.root = root.getRight();
return result;
}
public boolean contains (T target) {
if (root.find(target) != null)
return true;
else
return false;
}
public String toString() {
ArrayIterator<T> lxr=new ArrayIterator();
lxr= (ArrayIterator<T>) levelorder();//强制转化
String content="";
for (T i: lxr){//临时引用lxr的每一个元素
content += i +" ";
}
return content;
}
public Iterator<T> preorder() {
ArrayIterator<T> iter = new ArrayIterator <>();
if (root != null)
root.preorder(iter);
return iter;
}
public Iterator<T> postorder() {
ArrayIterator<T> iter = new ArrayIterator<T>();
if(root!=null){
root.postorder (iter);
}
return iter;}
public boolean isEmpty() {
if (root.count() != 0)
return false;
else
return true;
}
- 1.根据已经提供的
getLeft()套用补全getRight() - 2.对于包含方法,可以使用LinkedBinaryTree类前面的查找
find方法,该方法最后会返回查找的元素,则使用find查找target目标元素,根据查找结果返回true或false - 3.对于比较树中是否为空可以通过查看根结点是否为空,所以直接比较根的count是否为0来比较。
- 4.对于后序遍历,参照树中给出的先序遍历补全。
- 5.
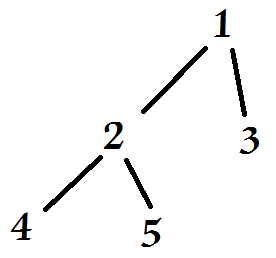
toString方法有些复杂,因为最后打印的结果要一目了然,知道树的轮廓,所以我选择使用levelorder()层序遍历来打印。将树中的元素进行层序遍历,创建T建立for循环临时引用树中的每一个元素并将其加入一个String的变量上,最后返回它。最后测试,建立一个树如图,得到打印结果1 2 3 4 5![]()
- 6.编写BTNode中先序和后序遍历的方法,根据它已经给出的中序遍历方法,可以变换得知,三者的区别在于加入元素的位置,先序在最前边添加,后序在最后面添加,附上BTNode
- 7.编写测试类LinkedBinargTreeTest
2-中序先序序列构造二叉树
实验目标:基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能![]()
代码链接
参考链接:我参考了这位博主的博客根据先序和中序遍历重建二叉树java实现,依葫芦画瓢完成实验
实验步骤:
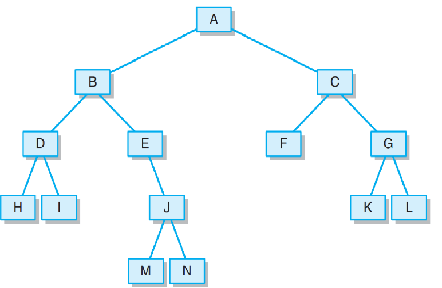
- 1.题目要求根据先序后中序实现树,问题在于如何将其打印出来,打印出一个具有枝叶联系的二叉树很难实现,但是可以把通过已知的遍历得到它的后序遍历,再进行比较,即实现目标。已知中序和先序分别为给出HDIBEMJNAFCKGL和ABDHIEJMNCFGKL的树,通过图可知它的后序为HIDMNJEFKLGCA 。
- 2.由于中序的特殊性可以得到根结点A的左右子树分别有哪些元素,我可以将左子树和右子树分别作为新的二叉树,找到子结点,左子树和右子树。
- 3.代码实现,首先建立一个简单的二叉树的类TNode,规定其左右子树。然后实现二叉树的重建过程PreAndInToPost,使用递归的算法进行扫描,再将元素进行不同的遍历得到后序遍历结果。
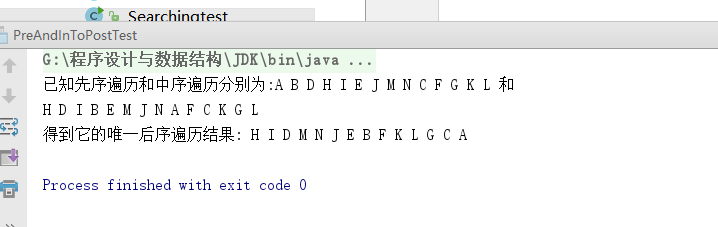
- 4.编写测试类,截图如下,符合预期测试成功
![]()
3-决策树
实验目标:“20问”模型,猜一个人,通过问问题方式得到结果
代码链接
实验步骤:
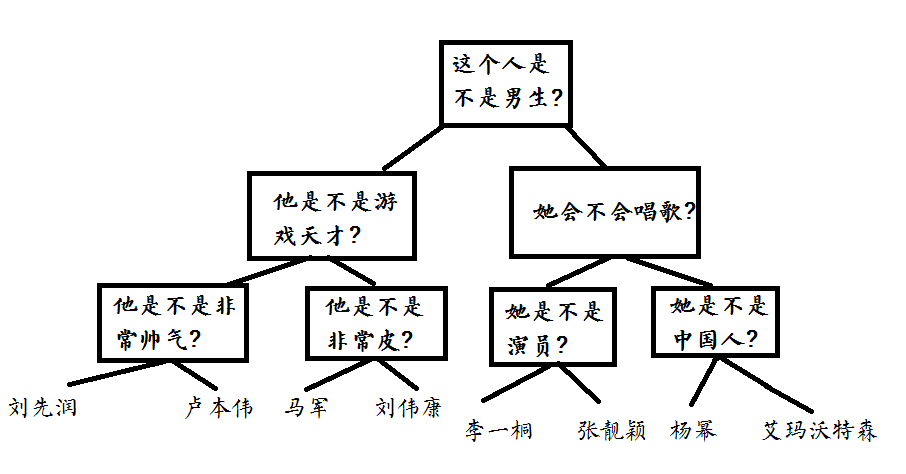
- 1.建立一个20问的模型,我的树如下图所示
![]()
- 2.根据书上代码确定并建立问题结点,但由于最后要返回答案值所以还需要创建保存答案的结点以得到返回值。
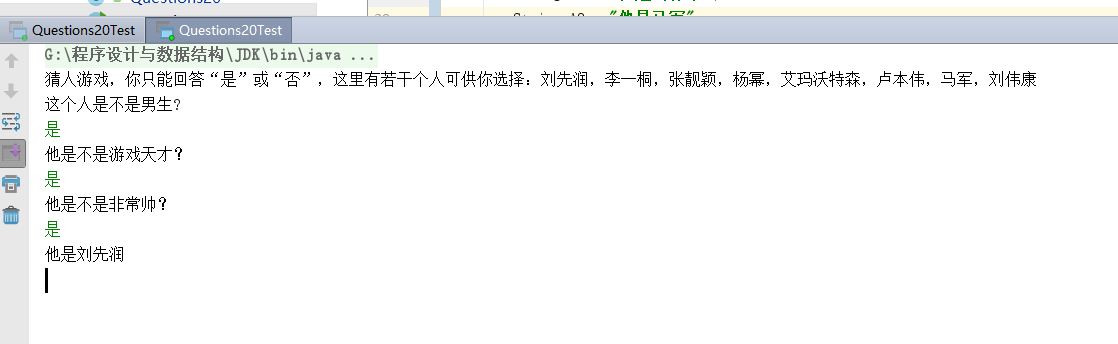
- 3.创建如下所示的Asking()提问方法,建立while循环以得到每次需要的问题,并输出答案是或否,当不为否时则取树结点的左子树。
public void Asking() {
Scanner scan = new Scanner(System.in);
System.out.println("猜人游戏,你只能回答“是”或“否”,这里有若干个人可供你选择:刘先润,李一桐,张靓颖,杨幂,艾玛沃特森,卢本伟,马军,刘伟康");
while(NewTree.size()>0){
System.out.println(NewTree.getRootElement());
String a=scan.nextLine();
if (a.equalsIgnoreCase("否")){
if(NewTree.getRight()!=null) {
NewTree = NewTree.getRight();
}else {
break;
}
}
else {
if(NewTree.getLeft()!=null) {
NewTree = NewTree.getLeft();
}else {
break;
}
}
- 4.建立测试类,测试答案全为是的结果,如下图,测试成功。
![]()
4-表达式树
实验目标:设计并实现程序,使用二叉树来表示表达式树,提供方法对数进行计算,得到表达式的结果。
代码链接
实验步骤:
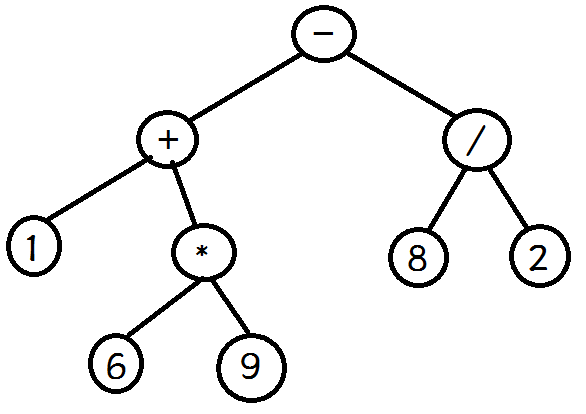
- 1.建立一个创建二叉树的类ExpressionTree,该类可以建立标准的二叉树或表达式树。题目要通过一个表达式建立树,我设的表达式为
1 + 6 * 9 -8 / 2,将其构建进这个树中,可知建立的形状如下图所示
![]()
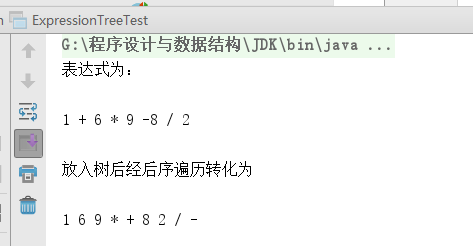
- 2.在该类中添加后序遍历的方法,因为表达式的后序遍历即次表达式的后缀形式,而且后序遍历之前也写过,不多阐述。但是树中的元素是由list保存的,所以在主函数中需要通过通过循环将后缀表达式打印出来,如图所示
![]()
- 3.在该类中添加计算后缀表达式的方法,求得该后缀表达式结果将其输出。
- 4.测试,如下图所示,测试成功,附上测试代码链接ExpressionTreeTest
![]()

5-二叉查找树
实验目标:完成17章LinkedBinarySearchTree类的实现,特别是findMin和findMax两个操作
代码链接
实验步骤:
- 1.查看二叉查找树代码,与一般二叉树的实现方法类似,LinkedBInarySearchTree操作了一组表示树中结点的独立对象。
- 2.由于二叉查找树的特殊性质,小的数在左子树,大的树在右子树,所以在写findMin()的时候考虑三种情况(正常,边界,异常)
- 3.首先当根为空,返回一个空子集;当树中只有一个根结点时,返回根结点;当根有左孩子时让根等于他的左孩子,建立循环,直到结点没有左孩子,返回当前结点元素。依葫芦画瓢编写findMax()方法。
public T findMin() {
if (root == null) {
return null;
}
if (root!=null && root.getLeft()==null) {
return root.getElement();
}
while (root.getLeft() != null) {
root = root.getLeft();
if (root.getLeft()==null) {
break;
}
}return root.getElement();
}
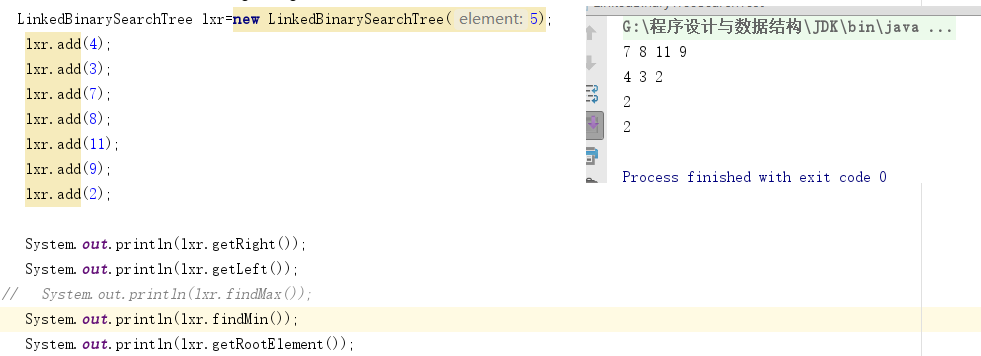
- 4.测试结果截图如下,测试成功。
![]()
6-红黑树分析
实验目标:对Java中的红黑树(TreeMap,HashMap)进行源码分析
分析结果:
首先我需要了解红黑树的概念,何为红黑树?它是一种特殊的二叉查找树。红黑树的每个节点上都有存储位表示节点的颜色。根结点是黑色,结点颜色与子结点颜色不同。主要是用它来存储有序的数据,它的时间复杂度是O(lgn),效率非常之高。附上参考资料链接:红黑树(一)之 原理和算法详细介绍、HashMap详细介绍
然后分析TreeMap,它是基于红黑树的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。 TreeMap存储的是key-value键值对,TreeMap的排序是基于对key的排序,它本质上就是一个红黑树。它内部有 Comparator用来给TreeMap排序,带有Map和SortMap的构造函数会成为TreeMap的子集。
分析具体的方法get,获取键key对应的值value,首先要获取key键的节点p,若节点p不为null,返回节点对应的值。
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
分析putAll方法,它的作用是将map中的全部节点添加到TreeMap中。首先获取map的大小,如果TreeMap的大小是0,且map的大小不是0,且map是已排序的“key-value对”,如果TreeMap和Map的comparator相等,则将map的元素全部拷贝到TreeNap中,然后返回。最后调用AbstractMap中的putAll(),而putAll()又会调用TreeMap的put()。
public void putAll(Map<? extends K, ? extends V> map) {
int mapSize = map.size();
if (size==0 && mapSize!=0 && map instanceof SortedMap) {
Comparator c = ((SortedMap)map).comparator();
if (c == comparator || (c != null && c.equals(comparator))) {
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),
null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return;
}
}
super.putAll(map);
}
对TreeMap有一个初步了解后再分析HashMap,通过查阅JDK文件得知,HashMap是基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。HashMap有两个重要参数,它存在一个容量(哈希表中桶的数量)和一个加载因子(容量自动增加之前可以达到多满的一种尺度)
接着分析源码,HashMap中的key-value都是存储在Entry数组中的。它有4个构造函数,例如下列代码,这是一个默认的构造函数,它首先设置加载因子,然后设置“HashMap阈值”,当HashMap中存储的量达到threshold时,就将HashMap的容量加倍。最后创建Entry数组保存数据。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
再分析一个方法get(),返回指定键所映射的值;如果对于该键来说,此映射不包含任何映射关系,则返回 null。它首先会获取key的hash值,在该hash值对应的链表上查找键值为key的元素。
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
通过本次源码分析对TreeMap和HashMap有了更深的了解,它的方法实现思路非常值得像我这样的新手学习借鉴。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号