
为防止数据丢失,需要将 Redis 中的数据从内存中 dump 到磁盘,这就是持久化。Redis 提供两种持久化方式:RDB 和 AOF。Redis 允许两者结合,也允许两者同时关闭。
RDB 可以定时备份内存中的数据集。服务器启动的时候,可以从 RDB 文件中恢复数据集。
AOF(append only file) 可以记录服务器的所有写操作。在服务器重新启动的时候,会把所有的写操作重新执行一遍,从而实现数据备份。当写操作集过大(比原有的数据集还大),Redis 会重写写操作集。
值得一提的是,因为AOF文件的更新频率通常比RDB文件的更新频率高,所以如果服务器开启了AOF持久化功能,那么服务器会优先使用AOF文件来还原数据库状态。只有在AOF持久化功能处于关闭状态时,服务器才会使用RDB文件来还原数据库状态。
RDB持久化
RDB文件的创建和载入
有两个Redis命令可以用于生成RDB文件,一个是SAVE,另一个是BGSAVE。
两者区别:
- SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求;
- BGSAVE命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求;
创建RDB文件的实际工作由rdb.c/rdbSave函数完成,SAVE命令和BGSAVE命令会以不同的方式调用这个函数,通过以下伪代码可以明显地看出这两个命令之间的区别:
def SAVE(): # 创建RDB 文件 rdbSave() def BGSAVE(): # 创建子进程 pid = fork() if pid == 0: # 子进程负责创建RDB 文件 rdbSave() # 完成之后向父进程发送信号 signal_parent() elif pid > 0: # 父进程继续处理命令请求,并通过轮询等待子进程的信号 handle_request_and_wait_signal() else: # 处理出错情况 handle_fork_error()
载入RDB文件的实际工作由rdb.c/rdbLoad函数完成,这个函数和rdbSave函数之间的关系可以用下图表示: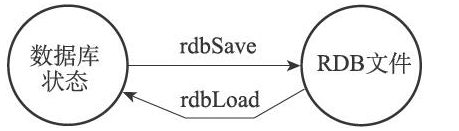
服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止。
自动间隔性保存
用户可以通过save选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会执行BGSAVE命令。
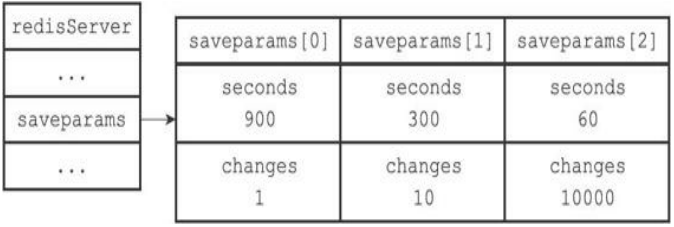
举个例子,如果我们向服务器提供以下配置:
save 900 1
save 300 10
save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE命令就会被执行:
·服务器在900秒之内,对数据库进行了至少1次修改;
·服务器在300秒之内,对数据库进行了至少10次修改;
·服务器在60秒之内,对数据库进行了至少10000次修改。
用户设置完save选项后(或者系统默认),接着,服务器程序会根据save选项所设置的保存条件,设置服务器状态redisServer结构的saveparams属性:
struct redisServer {
// ...
//
记录了保存条件的数组
struct saveparam *saveparams;
// ...
};
struct saveparam {
//
秒数
time_t seconds;
//
修改数
int changes;
};
默认情况下结构如下:
除了saveparams数组之外,服务器状态还维持着一个dirty计数器,以及一个lastsave属性:
·dirty计数器记录距离上一次成功执行SAVE命令或者BGSAVE命令之后,服务器对数据库状态(服务器中的所有数据库)进行了多少次修改(包括写入、删除、更新等操作);
·lastsave属性是一个UNIX时间戳,记录了服务器上一次成功执行SAVE命令或者BGSAVE命令的时间。
Redis的服务器周期性操作函数serverCron默认每隔100毫秒就会执行一次,该函数用于对正在运行的服务器进行维护,它的其中一项工作就是检查save选项所设置的保存条件是否已经满足,如果满足的话,就执行BGSAVE命令。
以下伪代码展示了serverCron函数检查保存条件的过程:
def serverCron():
# ...
#
遍历所有保存条件
for saveparam in server.saveparams:
#
计算距离上次执行保存操作有多少秒
save_interval = unixtime_now()-server.lastsave
#
如果数据库状态的修改次数超过条件所设置的次数,并且距离上次保存的时间超过条件所设置的时间
#
那么执行保存操作
if server.dirty >= saveparam.changes and \
save_interval > saveparam.seconds:
BGSAVE()
# ...
RDB文件结构
下图展示了一个完整RDB文件所包含的各个部分:

为了方便区分变量、数据、常量,上图中用全大写单词标示常量,用全小写单词标示变量和数据。
RDB文件的最开头是REDIS部分,这个部分的长度为5字节,保存着“REDIS”五个字符。通过这五个字符,程序可以在载入文件时,快速检查所载入的文件是否RDB文件。
注意:
因为RDB文件保存的是二进制数据,而不是C字符串,为了简便起见,我们用"REDIS"符号代表'R'、'E'、'D'、'I'、'S'五个字符,而不是带'\0'结尾符号的C字符串'R'、'E'、'D'、'I'、'S'、'\0'。
db_version长度为4字节,它的值是一个字符串表示的整数,这个整数记录了RDB文件的版本号,比如"0006"就代表RDB文件的版本为第六版。
databases部分包含着零个或任意多个数据库,以及各个数据库中的键值对数据:·如果服务器的数据库状态为空(所有数据库都是空的),那么这个部分也为空,长度为0字节。
EOF常量的长度为1字节,这个常量标志着RDB文件正文内容的结束,当读入程序遇到这个值的时候,它知道所有数据库的所有键值对都已经载入完毕了。
check_sum是一个8字节长的无符号整数,保存着一个校验和。
databases部分
上面提到的databases数据库结构如下:

SELECTDB常量的长度为1字节,当读入程序遇到这个值的时候,它知道接下来要读入的将是一个数据库号码。
db_number保存着一个数据库号码,根据号码的大小不同,这个部分的长度可以是1字节、2字节或者5字节。当程序读入db_number部分之后,服务器会调用SELECT命令,根据读入的数据库号码进行数据库切换。
key_value_pairs部分保存了数据库中的所有键值对数据,如果键值对带有过期时间,那么过期时间也会和键值对保存在一起。根据键值对的数量、类型、内容以及是否有过期时间等条件的不同,key_value_pairs部分的长度也会有所不同。
key_value_pairs部分
不带过期时间的键值对在RDB文件中由TYPE、key、value三部分组成,如下图:
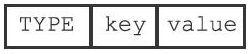
TYPE记录了value的类型,长度为1字节,值可以是以下常量的其中一个:
·REDIS_RDB_TYPE_STRING
·REDIS_RDB_TYPE_LIST
·REDIS_RDB_TYPE_SET
·REDIS_RDB_TYPE_ZSET
·REDIS_RDB_TYPE_HASH
·REDIS_RDB_TYPE_LIST_ZIPLIST
·REDIS_RDB_TYPE_SET_INTSET
·REDIS_RDB_TYPE_ZSET_ZIPLIST
·REDIS_RDB_TYPE_HASH_ZIPLIST
其中key总是一个字符串对象,它的编码方式和REDIS_RDB_TYPE_STRING类型的value一样。
带有过期时间的键值对在RDB文件中的结构如图:

新增的EXPIRETIME_MS和ms,它们的意义如下:
EXPIRETIME_MS常量的长度为1字节,它告知读入程序,接下来要读入的将是一个以毫秒为单位的过期时间;
·ms是一个8字节长的带符号整数,记录着一个以毫秒为单位的UNIX时间戳,这个时间戳就是键值对的过期时间。
关于type的具体讲解,请看redis设计与实现书中,RDB文件结构部分。
分析RDB文件
包含字符串键的RDB文件(分析一个带有单个字符串键的数据库)
redis> FLUSHALL
OK
redis> SET MSG "HELLO"
OK
redis> SAVE
OK
执行od命令:
$ od -c dump.rdb
0000000 R E D I S 0 0 0 6 376 \0 \0 003 M S G
0000020 005 H E L L O 377 207 z = 304 f T L 343
0000037
RDB文件的最开始是REDIS和版本号0006,之后出现的376代表SELECTDB常量,再之后的\0代表整数0,表示被保存的数据库为0号数据库。
在数据库号码之后,直到代表EOF常量的377为止,RDB文件包含有以下内容:
\0 003 M S G 005 H E L L O
\0就是字符串类型的TYPE值REDIS_RDB_TYPE_STRING(这个常量的实际值为整数0),之后的003是键MSG的长度值,再之后的005则是值HELLO的长度。
包含带有过期时间的字符串键的RDB文件
redis> FLUSHALL
OK
redis> SETEX MSG 10086 "HELLO"
OK
redis> SAVE
OK
$ od -c dump.rdb
0000000 R E D I S 0 0 0 6 376 \0 374 \ 2 365 336
0000020 @ 001 \0 \0 \0 003 M S G 005 H E L L O 377
0000040 212 231 x 247 252 } 021 306
0000050
·一个一字节长的EXPIRETIME_MS特殊值。
·一个八字节长的过期时间(ms)。
·一个一字节长的类型(TYPE)。
·一个键(key)和一个值(value)。
根据这些特征,可以得出RDB文件各个部分的意义:
·REDIS0006:RDB文件标志和版本号。
·376\0:切换到0号数据库。
·374:代表特殊值EXPIRETIME_MS。
·\2 365 336@001\0\0:代表八字节长的过期时间。
·\0 003 M S G:\0表示这是一个字符串键,003是键的长度,MSG是键。
·005 H E L L O:005是值的长度,HELLO是值。
·377:代表EOF常量。
·212 231 x 247 252 } 021 306:代表八字节长的校验和。
rdbSave函数具体代码实现
数据结构 rio
持久化的 IO 操作在 rio.h 和 rio.c 中实现,核心数据结构是 struct rio。RDB 中的几乎每一个函数都带有 rio 参数。struct rio 既适用于文件,又适用于内存缓存,从 struct rio 的实现可见一斑,它抽象了文件和内存的操作。
/*
* RIO API 接口和状态
*/
struct _rio {
/* Backend functions.
* Since this functions do not tolerate short writes or reads the return
* value is simplified to: zero on error, non zero on complete success. */
// 返回0表示失败,返回非0表示成功
size_t (*read)(struct _rio *, void *buf, size_t len);
size_t (*write)(struct _rio *, const void *buf, size_t len);
off_t (*tell)(struct _rio *);
/* The update_cksum method if not NULL is used to compute the checksum of
* all the data that was read or written so far. The method should be
* designed so that can be called with the current checksum, and the buf
* and len fields pointing to the new block of data to add to the checksum
* computation. */
// 校验和计算函数,每次有写入/读取新数据时都要计算一次
void (*update_cksum)(struct _rio *, const void *buf, size_t len);
/* The current checksum */
// 当前校验和
uint64_t cksum;
/* number of bytes read or written */
//读或者写的字节数
size_t processed_bytes;
/* maximum single read or write chunk size */
//最大单次读
size_t max_processing_chunk;
/* Backend-specific vars. */
union {
struct {
// 缓存指针
sds ptr;
// 偏移量
off_t pos;
} buffer;
struct {
// 被打开文件的指针
FILE *fp;
// 最近一次 fsync() 以来,写入的字节量
off_t buffered; /* Bytes written since last fsync. */
// 写入多少字节之后,才会自动执行一次 fsync()
off_t autosync; /* fsync after 'autosync' bytes written. */
} file;
} io;
};
typedef struct _rio rio;
redis 定义两个 struct rio(rio.c中),分别是 rioFileIO 和 rioBufferIO,前者用于内存缓存,后者用于文件 IO:
/* * 流为内存时所使用的结构 */ static const rio rioBufferIO = { // 读函数
//static size_t rioBufferRead(rio *r, void *buf, size_t len)从 r 中读取长度为 len 的内容到 buf 中。 rioBufferRead, // 写函数 rioBufferWrite, // 偏移量函数 rioBufferTell, NULL, /* update_checksum */ 0, /* current checksum */ 0, /* bytes read or written */ 0, /* read/write chunk size */ { { NULL, 0 } } /* union for io-specific vars */ }; /* * 流为文件时所使用的结构 */ static const rio rioFileIO = { // 读函数
//size_t rioFileRead(rio *r, void *buf, size_t len)从文件 r 中读取 len 字节到 buf 中。 rioFileRead, // 写函数 rioFileWrite, // 偏移量函数 rioFileTell, NULL, /* update_checksum */ 0, /* current checksum */ 0, /* bytes read or written */ 0, /* read/write chunk size */ { { NULL, 0 } } /* union for io-specific vars */ };
下面查看一下rdbSave源代码:
/* Save the DB on disk. Return REDIS_ERR on error, REDIS_OK on success * 将数据库保存到磁盘上。 * 保存成功返回 REDIS_OK ,出错/失败返回 REDIS_ERR 。 */ int rdbSave(char *filename) { dictIterator *di = NULL; dictEntry *de; char tmpfile[256]; char magic[10]; int j; long long now = mstime();//当前时间 FILE *fp; rio rdb; uint64_t cksum; // 创建临时文件 snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid()); fp = fopen(tmpfile,"w"); if (!fp) { redisLog(REDIS_WARNING, "Failed opening .rdb for saving: %s", strerror(errno)); return REDIS_ERR; } // 初始化rdb rioInitWithFile(&rdb,fp); // 设置校验和函数 if (server.rdb_checksum) rdb.update_cksum = rioGenericUpdateChecksum; // 写入 RDB 版本号 snprintf(magic,sizeof(magic),"REDIS%04d",REDIS_RDB_VERSION); if (rdbWriteRaw(&rdb,magic,9) == -1) goto werr;//rdbWriteRaw(rio *rdb,void *p,size_t len)将长度为len的字符数组p写入到rdb中 // 遍历所有数据库 for (j = 0; j < server.dbnum; j++) { // 指向数据库 redisDb *db = server.db+j; // 指向数据库键空间 dict *d = db->dict; // 跳过空数据库 if (dictSize(d) == 0) continue; // 创建键空间迭代器 di = dictGetSafeIterator(d); if (!di) { fclose(fp); return REDIS_ERR; } /* Write the SELECT DB opcode * * 写入数据库编号 */ if (rdbSaveType(&rdb,REDIS_RDB_OPCODE_SELECTDB) == -1) goto werr; if (rdbSaveLen(&rdb,j) == -1) goto werr; /* Iterate this DB writing every entry * * 遍历数据库,并写入每个键值对的数据 */ while((de = dictNext(di)) != NULL) { sds keystr = dictGetKey(de); robj key, *o = dictGetVal(de); long long expire; // 根据 keystr ,在栈中创建一个 key 对象 initStaticStringObject(key,keystr); // 获取键的过期时间 expire = getExpire(db,&key); // 保存键值对数据 if (rdbSaveKeyValuePair(&rdb,&key,o,expire,now) == -1) goto werr; } dictReleaseIterator(di); } di = NULL; /* So that we don't release it again on error. */ /* EOF opcode * * 写入 EOF 代码 */ if (rdbSaveType(&rdb,REDIS_RDB_OPCODE_EOF) == -1) goto werr; /* CRC64 checksum. It will be zero if checksum computation is disabled, the * loading code skips the check in this case. * * CRC64 校验和。 * * 如果校验和功能已关闭,那么 rdb.cksum 将为 0 , * 在这种情况下, RDB 载入时会跳过校验和检查。 */ cksum = rdb.cksum; memrev64ifbe(&cksum); rioWrite(&rdb,&cksum,8); /* Make sure data will not remain on the OS's output buffers */ // 冲洗缓存,确保数据已写入磁盘 if (fflush(fp) == EOF) goto werr; if (fsync(fileno(fp)) == -1) goto werr; if (fclose(fp) == EOF) goto werr; /* Use RENAME to make sure the DB file is changed atomically only * if the generate DB file is ok. * * 使用 RENAME ,原子性地对临时文件进行改名,覆盖原来的 RDB 文件。 */ if (rename(tmpfile,filename) == -1) { redisLog(REDIS_WARNING,"Error moving temp DB file on the final destination: %s", strerror(errno)); unlink(tmpfile); return REDIS_ERR; } // 写入完成,打印日志 redisLog(REDIS_NOTICE,"DB saved on disk"); // 清零数据库脏状态 server.dirty = 0; // 记录最后一次完成 SAVE 的时间 server.lastsave = time(NULL); // 记录最后一次执行 SAVE 的状态 server.lastbgsave_status = REDIS_OK; return REDIS_OK; werr: // 关闭文件 fclose(fp); // 删除文件 unlink(tmpfile); redisLog(REDIS_WARNING,"Write error saving DB on disk: %s", strerror(errno)); if (di) dictReleaseIterator(di); return REDIS_ERR; }
rdbLoad函数源码
int rdbLoad(char *filename) { uint32_t dbid; int type, rdbver; redisDb *db = server.db+0; char buf[1024]; long long expiretime, now = mstime(); FILE *fp; rio rdb; // 打开 rdb 文件 if ((fp = fopen(filename,"r")) == NULL) return REDIS_ERR; // 初始化写入流 rioInitWithFile(&rdb,fp); rdb.update_cksum = rdbLoadProgressCallback;// 记录载入进度信息,以便让客户端进行查询,这也会在计算 RDB 校验和时用到。 rdb.max_processing_chunk = server.loading_process_events_interval_bytes; if (rioRead(&rdb,buf,9) == 0) goto eoferr; buf[9] = '\0'; //取出最前面的REDIS字符,如果不是REDIS字符,那么就不是rdb文件 if (memcmp(buf,"REDIS",5) != 0) { fclose(fp); redisLog(REDIS_WARNING,"Wrong signature trying to load DB from file"); errno = EINVAL; return REDIS_ERR; } // 检查版本号 rdbver = atoi(buf+5); if (rdbver < 1 || rdbver > REDIS_RDB_VERSION) { fclose(fp); redisLog(REDIS_WARNING,"Can't handle RDB format version %d",rdbver); errno = EINVAL; return REDIS_ERR; } // 将服务器状态调整到开始载入状态 startLoading(fp); while(1) { robj *key, *val; expiretime = -1; /* Read type. * 读入类型指示,决定该如何读入之后跟着的数据。 * 这个指示可以是 rdb.h 中定义的所有以 * REDIS_RDB_TYPE_* 为前缀的常量的其中一个 * 或者所有以 REDIS_RDB_OPCODE_* 为前缀的常量的其中一个 */ if ((type = rdbLoadType(&rdb)) == -1) goto eoferr; // 读入过期时间值 if (type == REDIS_RDB_OPCODE_EXPIRETIME) { // 以秒计算的过期时间 if ((expiretime = rdbLoadTime(&rdb)) == -1) goto eoferr; /* We read the time so we need to read the object type again. * * 在过期时间之后会跟着一个键值对,我们要读入这个键值对的类型 */ if ((type = rdbLoadType(&rdb)) == -1) goto eoferr; /* the EXPIRETIME opcode specifies time in seconds, so convert * into milliseconds. * * 将格式转换为毫秒*/ expiretime *= 1000; } else if (type == REDIS_RDB_OPCODE_EXPIRETIME_MS) { // 以毫秒计算的过期时间 /* Milliseconds precision expire times introduced with RDB * version 3. */ if ((expiretime = rdbLoadMillisecondTime(&rdb)) == -1) goto eoferr; /* We read the time so we need to read the object type again. * * 在过期时间之后会跟着一个键值对,我们要读入这个键值对的类型 */ if ((type = rdbLoadType(&rdb)) == -1) goto eoferr; } // 读入数据 EOF (不是 rdb 文件的 EOF) if (type == REDIS_RDB_OPCODE_EOF) break; /* Handle SELECT DB opcode as a special case * * 如果读入的是REDIS_RDB_OPCODE_SELECTDB,那么切换数据库 */ if (type == REDIS_RDB_OPCODE_SELECTDB) { // 读入数据库号码 if ((dbid = rdbLoadLen(&rdb,NULL)) == REDIS_RDB_LENERR) goto eoferr; // 检查数据库号码的正确性 if (dbid >= (unsigned)server.dbnum) { redisLog(REDIS_WARNING,"FATAL: Data file was created with a Redis server configured to handle more than %d databases. Exiting\n", server.dbnum); exit(1); } // 在程序内容切换数据库 db = server.db+dbid; continue; } /* Read key * * 读入键 */ if ((key = rdbLoadStringObject(&rdb)) == NULL) goto eoferr; /* Read value * * 读入值 */ if ((val = rdbLoadObject(type,&rdb)) == NULL) goto eoferr; /* Check if the key already expired. This function is used when loading * an RDB file from disk, either at startup, or when an RDB was * received from the master. In the latter case, the master is * responsible for key expiry. If we would expire keys here, the * snapshot taken by the master may not be reflected on the slave. * * 如果服务器不是主节点, * 那么在键已经过期的时候,不再将它们关联到数据库中去 */ if (server.masterhost == NULL && expiretime != -1 && expiretime < now) { decrRefCount(key); decrRefCount(val); // 跳过 continue; } /* Add the new object in the hash table * * 将键值对关联到数据库中 */ dbAdd(db,key,val); /* Set the expire time if needed * * 设置过期时间 */ if (expiretime != -1) setExpire(db,key,expiretime); decrRefCount(key);//为对象的引用计数减一??? } /* Verify the checksum if RDB version is >= 5 * * 如果 RDB 版本 >= 5 ,那么比对校验和 */ if (rdbver >= 5 && server.rdb_checksum) { uint64_t cksum, expected = rdb.cksum; // 读入文件的校验和 if (rioRead(&rdb,&cksum,8) == 0) goto eoferr; memrev64ifbe(&cksum); // 比对校验和 if (cksum == 0) { redisLog(REDIS_WARNING,"RDB file was saved with checksum disabled: no check performed."); } else if (cksum != expected) { redisLog(REDIS_WARNING,"Wrong RDB checksum. Aborting now."); exit(1); } } // 关闭 RDB fclose(fp); // 服务器从载入状态中退出 stopLoading(); return REDIS_OK; eoferr: /* unexpected end of file is handled here with a fatal exit */ redisLog(REDIS_WARNING,"Short read or OOM loading DB. Unrecoverable error, aborting now."); exit(1); return REDIS_ERR; /* Just to avoid warning */ }
AOF持久化
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态的。
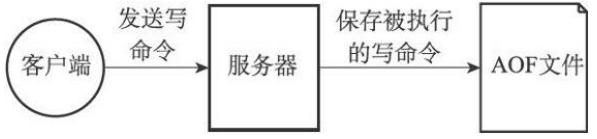
如:
redis> SET msg "hello"
OK
redis> SADD fruits "apple" "banana" "cherry"
(integer) 3
redis> RPUSH numbers 128 256 512
(integer) 3
被写入AOF文件的所有命令都是以Redis的命令请求协议格式保存的,因为Redis的命令请求协议是纯文本格式,所以我们可以直接打开一个AOF文件。
*2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n
*3\r\n$3\r\nSET\r\n$3\r\nmsg\r\n$5\r\nhello\r\n
*5\r\n$4\r\nSADD\r\n$6\r\nfruits\r\n$5\r\napple\r\n$6\r\nbanana\r\n$6\r\ncherry\r\n
*5\r\n$5\r\nRPUSH\r\n$7\r\nnumbers\r\n$3\r\n128\r\n$3\r\n256\r\n$3\r\n512\r\n
在这个AOF文件里面,除了用于指定数据库的SELECT命令是服务器自动添加的之外,其他都是我们之前通过客户端发送的命令。
AOF持久化的实现
AOF持久化功能的实现可以分为命令追加(append)、文件写入、文件同步(sync)三个步骤。
命令追加
当AOF持久化功能处于打开状态时,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区的末尾:
struct redisServer {
// ...
// AOF
缓冲区
sds aof_buf;
// ...
};
如:如果客户端向服务器发送以下命令:
redis> SET KEY VALUE
OK
那么服务器在执行这个SET命令之后,会将以下协议内容追加到aof_buf缓冲区的末尾:
*3\r\n$3\r\nSET\r\n$3\r\nKEY\r\n$5\r\nVALUE\r\n
AOF文件的写入与同步
因为服务器在处理文件事件时可能会执行写命令,使得一些内容被追加到aof_buf缓冲区里面,所以在服务器每次结束一个事件循环之前,它都会调用flushAppendOnlyFile函数,考虑是否需要将aof_buf缓冲区中的内容写入和保存到AOF文件里面。
flushAppendOnlyFile函数的行为由服务器配置的appendfsync选项的值来决定,各个不同值产生的行为如下表所示:

如果用户没有主动为appendfsync选项设置值,那么appendfsync选项的默认值为everysec。
AOF文件的载入与数据还原
因为AOF文件里面包含了重建数据库状态所需的所有写命令,所以服务器只要读入并重新执行一遍AOF文件里面保存的写命令,就可以还原服务器关闭之前的数据库状态。
Redis读取AOF文件并还原数据库状态的详细步骤如下:
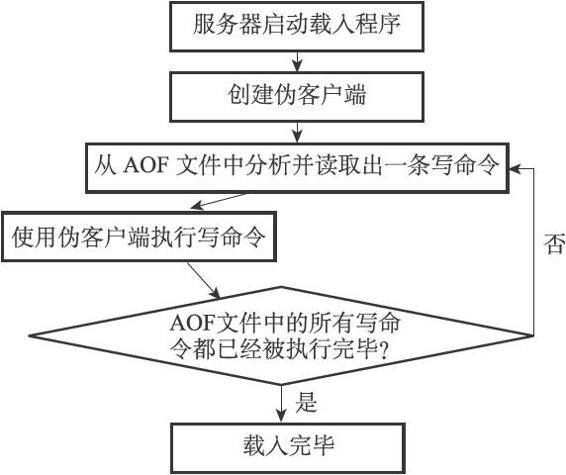
创建一个不带网络连接的伪客户端(fake client):因为Redis的命令只能在客户端上下文中执行,而载入AOF文件时所使用的命令直接来源于AOF文件而不是网络连接,所以服务器使用了一个没有网络连接的伪客户端来执行AOF文件保存的写命令,伪客户端执行命令的效果和带网络连接的客户端执行命令的效果完全一样。
AOF重写
重写是为了解决AOF文件越来越大的问题,所以需要将他的体积缩小。
AOF文件重写的实现
首先从数据库中读取键现在的值,然后用一条命令去记录键值对,代替之前记录这个键值对的多条命令,这就是AOF重写功能的实现原理。
如:
redis> SADD animals "Cat"
// {"Cat"}
(integer) 1
redis> SADD animals "Dog" "Panda" "Tiger" // {"Cat", "Dog", "Panda", "Tiger"}
(integer) 3
redis> SREM animals "Cat" // {"Dog", "Panda", "Tiger"}
(integer) 1
redis> SADD animals "Lion" "Cat" // {"Dog", "Panda", "Tiger",
(integer) 2 "Lion", "Cat"}
可以用:
SADD animals"Dog""Panda""Tiger""Lion""Cat" 命令代替。
注意:
在实际中,为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序在处理列表、哈希表、集合、有序集合这四种可能会带有多个元素的键时,会先检查键所包含的元素数量,如果元素的数量超过了redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD常量的值,那么重写程序将使用多条命令来记录键的值,而不单单使用一条命令。
在目前版本中,REDIS_AOF_REWRITE_ITEMS_PER_CMD常量的值为64,这也就是说,如果一个集合键包含了超过64个元素,那么重写程序会用多条SADD命令来记录这个集合,并且每条命令设置的元素数量也为64个:
SADD <set-key> <elem1> <elem2> ... <elem64>
SADD <set-key> <elem65> <elem66> ... <elem128>
SADD <set-key> <elem129> <elem130> ... <elem192>
...
aof的重写是也是放在子程序中进行。不过,使用子进程也有一个问题需要解决,因为子进程在进行AOF重写期间,服务器进程还需要继续处理命令请求,而新的命令可能会对现有的数据库状态进行修改,从而使得服务器当前的数据库状态和重写后的AOF文件所保存的数据库状态不一致。
为了解决这种数据不一致问题,Redis服务器设置了一个AOF重写缓冲区,这个缓冲区在服务器创建子进程之后开始使用,当Redis服务器执行完一个写命令之后,它会同时将这个写命令发送给AOF缓冲区和AOF重写缓冲区,如图所示:
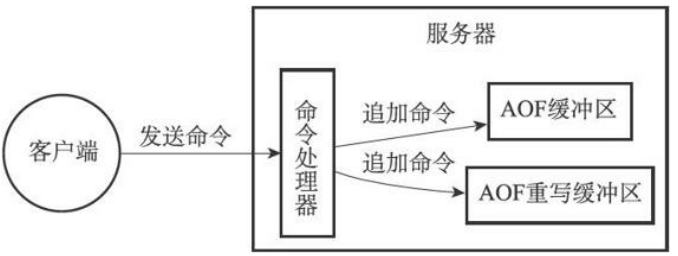
这也就是说,在子进程执行AOF重写期间,服务器进程需要执行以下三个工作:
1)执行客户端发来的命令;
2)将执行后的写命令追加到AOF缓冲区;
3)将执行后的写命令追加到AOF重写缓冲区。
这样一来可以保证:
·AOF缓冲区的内容会定期被写入和同步到AOF文件,对现有AOF文件的处理工作会如常进行。
·从创建子进程开始,服务器执行的所有写命令都会被记录到AOF重写缓冲区里面。
当子进程完成AOF重写工作之后,它会向父进程发送一个信号,父进程在接到该信号之后,会调用一个信号处理函数,并执行以下工作:
1)将AOF重写缓冲区中的所有内容写入到新AOF文件中,这时新AOF文件所保存的数据库状态将和服务器当前的数据库状态一致。
2)对新的AOF文件进行改名,原子地(atomic)覆盖现有的AOF文件,完成新旧两个AOF文件的替换。
这个信号处理函数执行完毕之后,父进程就可以继续像往常一样接受命令请求了。
注意:在整个AOF后台重写过程中,只有信号处理函数执行时会对服务器进程(父进程)造成阻塞,在其他时候,AOF后台重写都不会阻塞父进程,这将AOF重写对服务器性能造成的影响降到了最低。
具体函数源码分析,可以参考:http://wiki.jikexueyuan.com/project/redis/aof.html(感觉代码的注释并不是很好,看英文注释比较靠谱)。
 posted on
posted on
