
一些常用的数据统计shell
1. 求文件交集、并集、差集
1.1 使用命令comm
comm命令按行比较两个已对记录排序的文件。要注意两个文件必须是排序和唯一(sorted and unique)的,默认输出为三列,第一列为是A-B,第二列B-A,第三列为A交B。
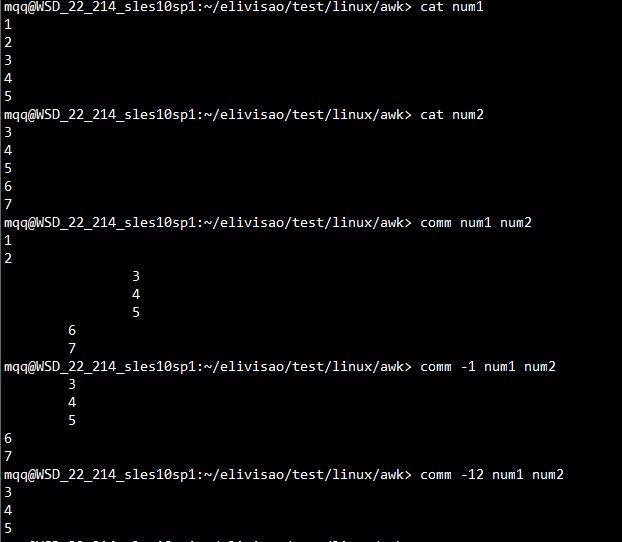
选项:-1 排除仅在文件1 中出现的记录
-2 排除仅在文件2 中出现的记录
-3 排除同时在文件1 和 2中出现的记录
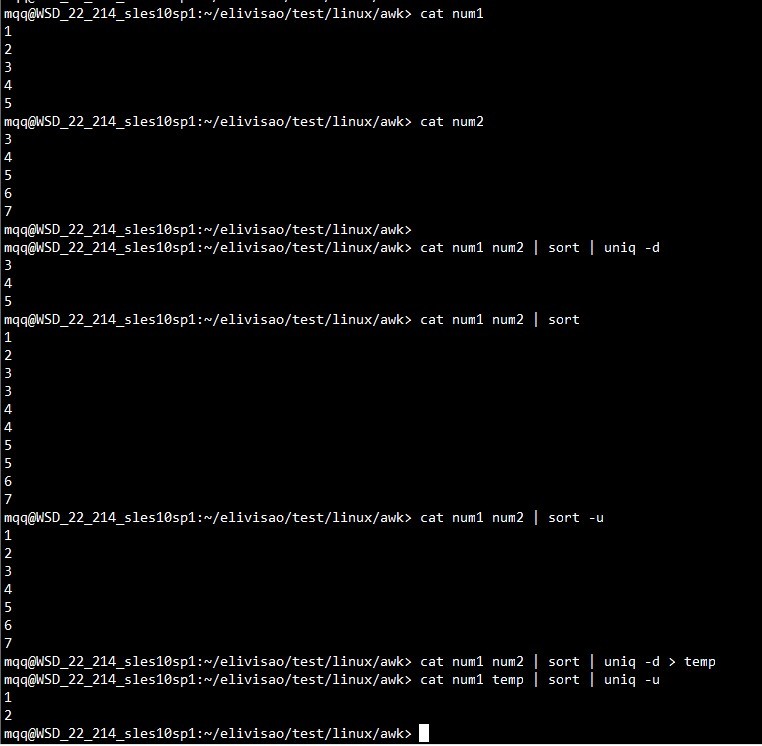
1.2 使用sort 和 uniq命令
前提:文件1和文件2都是已去重。
求交集:cat file1 file2 | sort | uniq -d
求并集不去重:cat file1 file2 | sort
求并集去重:cat file1 file2 | sort -u
求差集:cat file1 file2 | sort | uniq -d > temp
cat file1 temp | sort | uniq -u
2. 随机取若干条记录
awk中使用rand()函数
cat file | awk '{print rand() "|" $1}' | sort -k1 -t"|" | awk -F'|' '{print$2}' |head -5
3. 分组求和
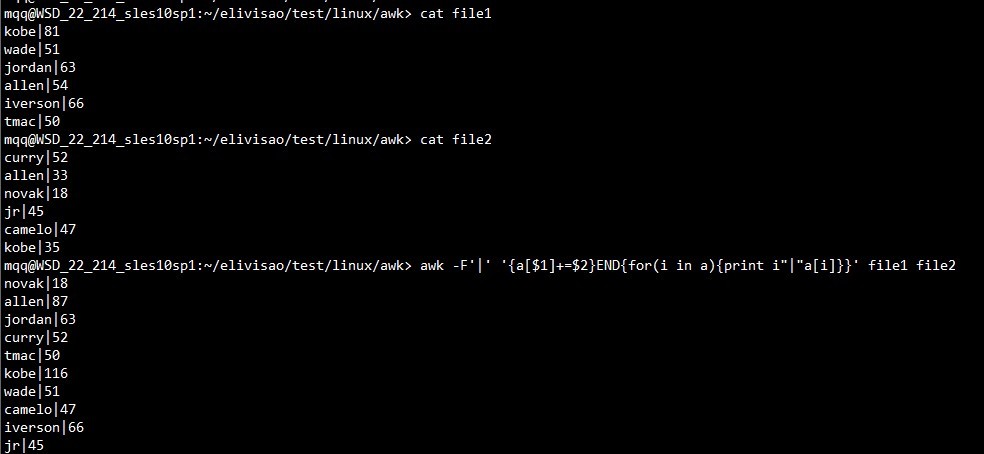
3.1 将第一列相同的记录的第二列数值相加并打印:awk -F'|' '{a[$1]+=$2}END{for(i in a){print i"|"a[i]}}' file1 file2
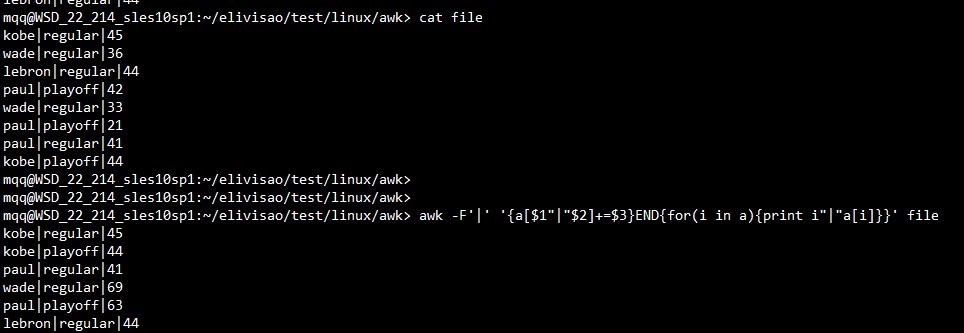
3.2 将第一列和第二列都相同的记录的第三列相加并将结果打印出来:awk -F'|' '{a[$1"|"$2]+=$3}END{for(i in a){print i"|"a[i]}}' file
3.3 根据第一列,分别将第二列和第三列的数值相加并打印:awk -F'|' '{a[$1]+=$2;b[$1]+=$3}END{for(i in a){print i"|"a[i]"|"b[i]}}' file

4. 匹配
4.1 匹配交集项
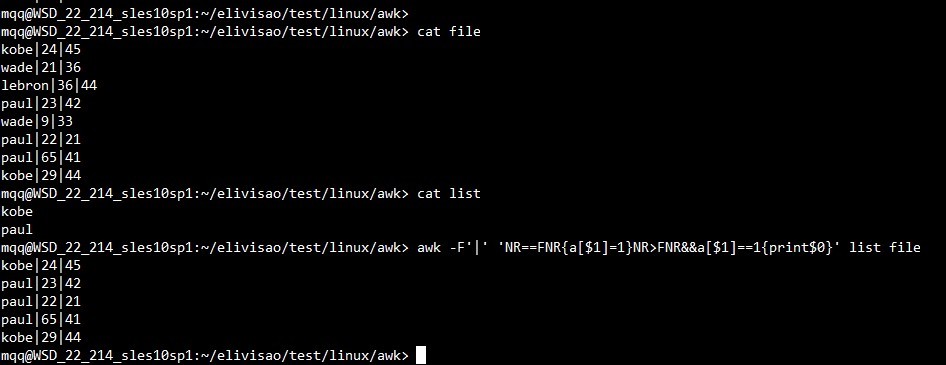
若file中记录的第一列在list中记录的第一列出现过,则输出该记录在file中的整列:awk -F'|' 'NR==FNR{a[$1]=1}NR>FNR&&a[$1]==1{print$0}' list file
4.2 匹配非交集项
若file中记录的第一列未在list中的第一列出现过,则输出该记录在file中的整行:awk -F'|' 'NR==FNR{a[$1]=1}NR>FNR&&a[$1]!=1{print$0}' list file

5. 取最大值最小值
5.1 单列记录
求单列记录中最大值的列:awk -F'|' 'BEGIN{max=0}{if($1>max){max=$1}}END{print max}' number
求单列记录中最小值的列:awk -F'|' 'NR==1{min=$1}{if($1<min){min=$1}}END{print min}' number

5.2 多列记录
以第一列为key,对应多个value,则取key对应的最大值和最小值:
最大值:awk -F'|' '{max[$1]=max[$1]>$2?max[$1]:$2}END{for(i in max){print i"|"max[i]}}' max_min
最小值:awk -F'|' '{if(!min[$1]){min[$1]=$2}else{min[$1]=min[$1]<$2?min[$1]:$2}}END{for(i in min){print i"|"min[i]}}' max_min


