Ubuntu16.04+hadoop2.7.3环境搭建
转载请注明源出处:http://www.cnblogs.com/lighten/p/6106891.html
最近开始学习大数据相关的知识,最著名的就是开源的hadoop平台了。这里记录一下目前最新版的hadoop在Ubuntu系统下的搭建过程。搭建过程中发现一篇十分清晰全面的搭建文章,本文删减了一些不重要的内容,细化了一些内容。可以点击此处查看:原文。
1.JDK的安装
hadoop是使用Java开发的一个大数据平台,自然少不了Java运行环境的安装了,当然使用hadoop不一定需要java语言,hadoop的开发支持很多种语言。
Java运行环境的安装详见另一篇文章,这里就不叙述了:Ubuntu16.04安装JDK。
2.配置SSH及免密码登陆
hadoop需要使用SSH的方式登陆,linux下需要安装SSH。客户端已经安装好了,只需要安装服务端就可以了:
sudo apt-get install openssh-server
测试登陆本机 ssh localhost 输入yes就应该可以登录了。但是每次输入比较繁琐,如果是集群那就是灾难了,所以要配置成免密码登陆的方式。
一共有三步:
1.生成公钥私钥 ssh -keygen -t rsa,将在~/.ssh文件夹下生成文件id_rsa:私钥,id_rsa.pub:公钥
2.导入公钥到认证文件,更改权限:
1)导入本机:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
2)导入服务器:
首先将公钥复制到服务器:
scp ~/.ssh/id_rsa.pub xxx@host:/home/xxx/id_rsa.pub
然后,将公钥导入到认证文件,这一步的操作在服务器上进行:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
最后在服务器上更改权限:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
3)测试:ssh localhost 第一次需要输入yes,之后就不需要了。
3.Hadoop的安装
1.下载hadoop安装包,下载地址:点这里。下载binary就行了。也可以使用wget命令下载。
2.解压、移动到你想要放置的文件夹
tar -zvxf hadoop-2.7.3.tar.gz
mv ./hadoop-2.7.3.tar.gz /opt/hadoop
3.创建hadoop用户和组,并授予执行权限
sudo addgroup hadoop
sudo usermod -a -G hadoop xxx #将当前用户加入到hadoop组
sudo gedit etc/sudoers #将hadoop组加入到sudoer
在root ALL=(ALL) ALL后 hadoop ALL=(ALL) ALL
sudo chmod -R 755 /opt/hadoop
sudo chown -R xxx:hadoop /opt/hadoop //否则ssh会拒绝访问
这些都是一般需要的操作,这篇文章还进行了其它的配置,如果遇到问题可以看看,是不是由于这些配置导致的:点这里。
4.修改配置文件,和JDK的安装一样,可以选择修改哪个文件。这里修改/etc/profile
export HADOOP_HOME=/opt/hadoop2.7.3
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
source /etc/hadoop
这篇配置文章还配了很多其它配置,我暂时没有配置,遇到问题,可以做为参考。点这里。
5.测试是否配置成功
hadoop version
6.hadoop单机配置(非分布式模式)
hadoop默认是非分布式模式,不需要进行其它配置。可以测试demo来观察是否配置正确。
cd /opt/hadoop
mkdir input
cp README.txt input
bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.7.3-sources.jar org.apache.hadoop.examples.WordCount input output
7.hadoop伪分布式配置
伪分布式只需要更改两个文件就够了。配置文件都在hadoop目录下的etc/hadoop中。
首先是core-site.xml,设置临时目录位置,否则默认会在/tmp/hadoo-hadoop中,这个文件夹在重启时可能被系统清除掉,所以需要改变配置路径。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
然后就是hdfs-site.xml,伪分布式只有一个节点,所以必须配置成1。还配置了datanode和namenode的节点位置。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>
</configuration>
接着执行format命令,格式化名称节点:./bin/hdfs namenode -format
开启hdfs:./sbin/start-dfs.sh 如果出现ssh认证 输入yes就可以了。
输入jps命令查看是否启动成功

访问http://localhost:50070 查看节点信息。
关闭hdfs: ./sbin/stop-dfs.sh
上面都是hdfs的配置,接下来就需要配置mapreduce的相关配置了,不配这个也不会影响到什么。但是缺少了资源调度,hadoop2.x版本使用yarn来进行任务调度管理,这是与1.x版本最大的不同。
cp ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
vim ./etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn的配置文件:yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动yarn,要先启动了hdfs:./sbin/start-yarn.sh

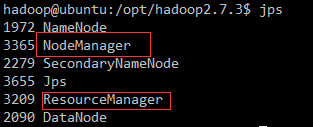
开启历史服务器,这样可以在web界面中查看任务运行情况:./sbin/mr-jobhistory-daemon.sh start historyserver
不启用 YARN 时,是 “mapred.LocalJobRunner” 在跑任务,启用 YARN 之后,是 “mapred.YARNRunner” 在跑任务。启动 YARN 有个好处是可以通过 Web 界面查看任务的运行情况:http://localhost:8088/cluster 。
8.分布式部署,没有两台电脑,没有尝试,具体见:这里。
4 后语
由于本机之前进行的配置,所以难免在写的时候会遗漏一些细节,如果有什么问题,请指教。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号