

白话C++系列(19) -- is-a
2016-05-20 14:12 Keiven_LY 阅读(841) 评论(0) 收藏 举报is-a
什么是is-a?
我们看下面两个例子:
隐形眼镜也是眼镜。如果眼镜是基类,那么隐形眼镜就可以是眼镜的派生类。于是,对于任何一个隐形眼镜的对象来说,我们都可以称之为眼镜,这是没有错误的。在C++中,我们就把这种关系称之为is-a。
再比如,我们定义一个人的类,再定义一个工人的类,再定义一个士兵的类,如果将人这个类作为基类,工人和士兵分别继承人这个类,那么我们就可以把每一个工人的对象称之为一个人的对象,也可以把每一个士兵的对象称之为一个人的对象。我们来看一个这样的例子。

例子分析:
在这个例子中,我们实例化了Soldier类的一个对象s1,然后,在实例化Person对象的时候,让Person的对象p1直接接收s1,也就是说,用s1去实例化p1。(这样做在语法上是正确的,因为一个士兵也是一个人,那么用士兵初始化人是可以的)。接着又定义了一个Person的指针p2,并且让p2指向Soldier对象s1。看到这里,前面三行代码是正确的。接着看下面的,将人的对象赋值给士兵(s1 = p1),同时,如果用一个士兵的指针去指向一个人的对象(Soldier *s2 = &p1),这两种写法就是有问题的。
那么在上面三行代码是正确的前提下,这就意味着,派生类的对象可以赋值给基类(也可以说,子类的对象可以赋值给父类),也可以说,用基类的指针指向派生类的对象。既然如此,我们就可以将基类的指针或者是基类的对象或者是基类的引用作为函数的参数来接收传入的子类的对象,当然也可以接收传入的基类的对象。看下面的一个例子。

当我们定义了fun1和fun2这两个函数的时候,我们注意到,这里用的是Person的指针和Person的引用来作为函数的参数的。那么在main函数中使用的时候,我们实例化了一个Person类的对象p1,还实例化了一个Soldier类的对象s1,从而我们就可以将这两个对象的地址传入进去,这个时候所使用的是fun1(因为fun1的参数是一个Person的指针,所以它既可以指向Person的对象,也可以指向Soldier的对象,因为Soldier继承了Person),同样,如果使用第二个函数fun2的话呢,也可以传入p1和s1,因为fun2所使用的参数是Person的引用,所以这里不需要加&符号,直接传对象本身就可以了。
相信,讲到这的时候,大家对Is-a的语法,使用方式上应该没有什么疑惑了,下面从内存的角度来说明Is-a的关系。
存储结构
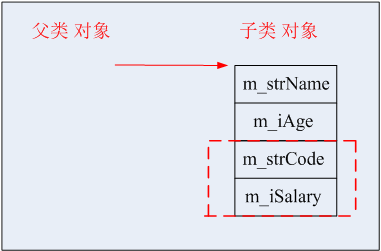
首先,第一种情况,将子类的对象赋值给父类的对象,或者是用子类的对象初始化父类的变量。

如果父类中含有m_strName和m_iAge这两个数据成员的时候,那么子类在继承父类的时候一定也含有m_strName和m_iAge这两个数据成员,同时,子类应该还含有其自身的数据成员。当我们用子类的对象向父类的对象赋值或者是用子类的对象初始化父类的一个对象的时候,它的本质就是将子类当中从父类继承下来的数据成员赋值给父类的对象,那么子类中其他的数据成员此时就会被截断,因为,对于父类来说,它只能接收自己拥有的数据成员的数据,而无法接收其他数据。如果是用父类的指针指向一个子类对象,那么,父类的指针也只能够访问到父类所拥有的数据成员。而无法访问到子类所独有的数据成员。也就是说,如果我们用一个父类指针去指向一个子类对象的话,我们只能够通过这个父类指针去访问父类原有的数据成员和成员函数,而无法访问子类所独有的数据成员和成员函数。
is-a编码实践
题目描述:
/*****************************************/
/* 继承关系中的隐藏
要求:
1. Person类,数据成员:m_strName,成员函数:构造函数、play()
2. Soldier类,数据成员:m_iAge,成员函数:构造函数、析构函数、work()
3. 定义函数test1(Person p) test2(Person &p) test3(Person *p)
/*****************************************/
程序框架:

头文件(Person.h)
#include<string> using namespace std; class Person { public: Person(string name = "Jim");//这里给定默认参数值 ~Person(); void play(); protected: string m_strName; };
源程序(Person.cpp)
#include"Person.h" #include<iostream> using namespace std; Person::Person(string name) { m_strName = name; cout <<"Person()"<< endl; } Person::~Person() { cout <<"~Person()"<< endl; } void Person::play() { cout <<"Person---play()"<< endl; cout << m_strName << endl; }
头文件(Soldier.h)
#include"Person.h"//这里如果不包含这个头文件,编译时就会出现“Person”未定义基类 class Soldier:public Person { public: Soldier(string name = "James", int age = 20);//这里也给定默认参数值 ~Soldier(); void work(); protected: int m_iAge; };
源程序(Soldier.cpp)
#include"Soldier.h" #include<iostream> using namespace std; Soldier::Soldier(string name, intage) { m_strName = name; m_iAge = age; cout <<"Soldier()"<< endl; } Soldier::~Soldier() { cout <<"~Soldier()"<< endl; } void Soldier::work() { cout << m_strName << endl; cout << m_iAge << endl; cout <<"Soldier--work()"<< endl; }
主调程序(demo.cpp)
#include<iostream> #include<stdlib.h> #include"Soldier.h" using namespace std; int main() { Soldier soldier; Person p = soldier; p.play(); system("pause"); return 0; }
在这里我们实例化了一个Soldier对象soldier,并且用soldier去初始化Person的对象p,大家想一想,这里p中m_strName的值究竟是什么呢?那我们就来调用一下play函数来观察看一看,运行结果如下:
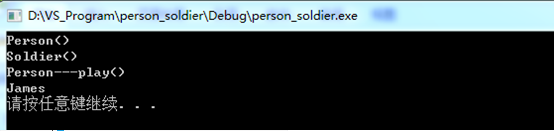
从运行结果来看,前面两行输出是因为,第一行代码我们实例化了Soldier对象,对象实例化时会自动调用其默认构造函数,这里由于Soldier是子类,所以先调用其父类的默认构造函数,再调用其自身的默认构造函数。后面两行输出是因为调用了play函数,打印出了m_strName是James,这就意味着,我们使用soldier去初始化Person的对象p,就使得p中的m_strName的值是James。这就意味着,这里做了截断(前面介绍过,即把soldier中的m_strName赋值给了p中的m_strName)。接下来,我们直接来实例化对象p,如下
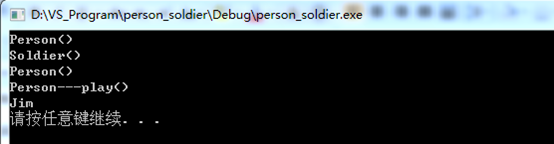
int main() { Soldier soldier; Person p; p.play(); system("pause"); return 0; }
因为p有默认构造函数,并且有默认值“Jim”,当调用play函数时,一定打印出的是Jim,我们来看一下运行结果:
前面我使用的是soldier来实例化p,接下来我们让soldier直接赋值给p这个对象,如下:
int main() { Soldier soldier; Person p; p = soldier; p.play(); system("pause"); return 0; }
运行结果:
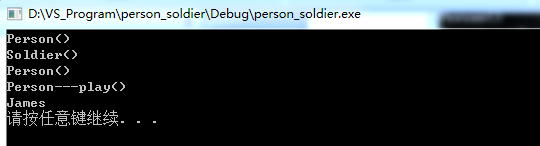
我们可以看到,当Soldier对象直接赋值给Person对象后,再用p去调用play函数,打印出的就是James,这就意味着,无论是用soldier去初始化p,还是将soldier直接赋值给p,那么soldier中的m_strName都可以赋值给其父类中队形对应的那个数据成员。接下来,我们使用指针来试一试效果如何(如下)。
int main() { Soldier soldier; Person *p = &soldier; p->play(); system("pause"); return 0; }
在这里我们定义了一个Person类的指针对象p,并且让p指向Soldier类的对象soldier,然后我们用p来调用play函数,看一看运行结果:
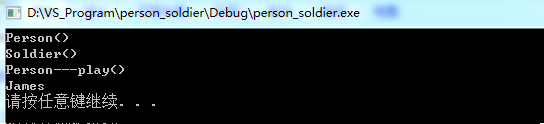
我们可以看到,效果是一样的,也打印出的是James。可见,无论是用对象赋值的方式,还是用指针指向的方式,如果用父类去指向或者接收子类对象的值,打印出的都是子类对象所拥有的那个值。
那么,使用父类的指针能不能调用子类的成员函数呢?我们来试一下(如下)
int main() { Soldier soldier; Person *p = &soldier; p->play(); p->work(); system("pause"); return 0; }
运行如下:
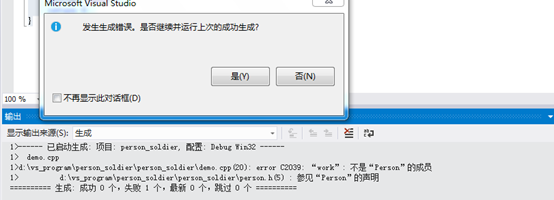
我们看到程序报错,错误的提示是work函数不是Person类的成员,可见,我们使用Person类的对象或者指针,只能调用Person自己的数据成员和成员函数,无法调用其子类的成员和成员函数。
下面,我们来做另外一个实验,如果我们通过父类的指针指向子类的对象,那么指针销毁的时候,究竟执行的是父类的析构函数还是子类的析构函数呢?我们一起看一下(如下)
int main() { Person *p = new Soldier; p->play(); delete p; p = NULL; system("pause"); return 0; }
运行结果:

从运行结果来看,当我们用父类的指针去指向子类的一个对象的时候,那么子类的这个对象会去实例化,所以实例化的过程是先调用父类的构造函数,再调用子类的构造函数,但是当我们去销毁指针的时候,我们会发现,只执行了父类的析构函数,这意味着,子类的析构函数没有被执行,那就有可能造成内存的泄漏。
那这种情况下,我们如何来避免内存泄漏呢?我们是有办法能够解决这个问题的。
首先,我们需要学习一个新的知识点----虚析构函数。
什么时候需要用到虚析构函数呢?当存在继承关系的时候,我们使用父类的指针去指向堆中的子类的对象,并且我们还想使用父类的指针去释放这块内存,这个时候就需要使用虚析构函数。写法很简单,只需要在析构函数前面加上关键字virtual即可。如果父类的析构函数是虚析构函数,那么其子类的析构函数无论前面加不加关键字virtual,其都是虚析构函数(这里,我们建议都加上,方便理解)。那么这里我们来修改一下析构函数使其变成虚析构函数,即分别在Person.h和Soldier.h中在析构函数的前面加上关键字virtual即可,如下:
virtual ~Person(); virtual ~Soldier();
main函数还是之前的main函数,如下
int main() { Person *p = new Soldier; p->play(); delete p; p = NULL; system("pause"); return 0; }
现在再来看一看执行效果如何:
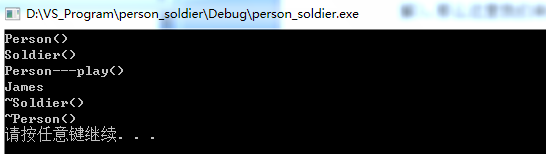
从运行结果,我们可以看到,其最后两行分别执行的是Soldier类的析构函数和Person类的析构函数,也就是说,它可以将soldier这个对象完全的释放掉。
接下来,我们来实现题目描述中的第3个要求。
下面我们在demo.cpp中来定义这3个函数(我们不关心其返回值),如下:
void test1(Personp) { p.play(); } void test2(Person&p) { p.play(); } void test3(Person *p) { p->play(); }
然后在main函数中,我们分别实例化两个对象p和s。我们分别使用Person和Soldier的对象作为参数,分别传递给函数test1、test2和test3。注意观察三者的区别。
首先将p和s传递给test1,如下:
int main() { Person p; Soldier s; test1(p); test1(s); system("pause"); return 0; }
我们来看一下运行结果:

从运行结果可以看到,由于实例化Person对象,所以打印出了Person的构造函数;接着由于实例化Soldier对象,这里由于Soldier是子类,所以先调用其父类的默认构造函数,再调用其自身的默认构造函数。然后,就需要注意的是:在我们调用test1函数的时候,因为我们在test1中所定义的参数是一个对象p,所以在传值的时候,先实例化一个临时对象p,这就使得它在接收参数的时候,会临时地实例化一个对象p,通过这个临时对象p来调用play函数,并且在函数test1执行完毕之后,p这个临时对象就会被销毁。这就是为什么在我们的执行结果中会打印出两次Person的析构函数来的原因。在销毁之前,它确实调用过play函数。我们看到,当我们传入的是Person的对象时,打印出的是Jim,而当我们传入的是Soldier对象时,打印出的是James。可见,如果函数的参数是基类的对象,那么基类的对象和派生类的对象都可以作为实参传递进来,并且能够正常的使用。
下面来看一下test2的执行情况,如下:
int main() { Person p; Soldier s; test2(p); test2(s); system("pause"); return 0; }
我们来看一下运行结果:

从运行结果可以看到,前三行的打印结果跟之前一样(先实例化Person对象,再实例化子类Soldier对象),然后调用test2。大家注意,test2因为是一个引用,所以在传入参数的时候,会将这个参数起一个别名p,通过这个别名p来调用play函数,可见,这个过程中,并没有实例化临时对象,所以也没有销毁临时对象的痕迹。其他的打印结果与调用test1的打印结果是相同的。这也可以说明,使用基类的引用,也可以接收基类的对象以及派生类的对象。
下面来看一下test3的执行情况,如下:
int main() { Person p; Soldier s; //因为test3要求传入的是一个指针,所以这里需要传入的是p和s的地址 test3(&p); test3(&s); system("pause"); return 0; }
我们来看一下运行结果:

从运行结果可以看到,与调用test2的结果是一样的。这是因为test3的参数是一个指针,而这个指针是一个基类的指针,当我们使用基类或者是派生类的对象的地址传入之后,会使用指针p分别调用基类和派生类的play函数,所以打印出Jim和James。
通过对于test1、test2和test3三个函数的对比调用,我们可以发现,使用test2和test3并不会产生新的临时变量,所以效率更高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号