

白话C++系列(10)--对象的生离死别
2016-04-23 22:38 Keiven_LY 阅读(1476) 评论(0) 收藏 举报对象的生离死别
思考:实例化的对象是如何在内存中存储的?
思考:类中的代码又是如何存储的?
思考:数据和代码之间又有怎样的关系呢?
带着这些问题,先学习一下对象的结构
对象结构
要想为大家说清对象是如何存储的,就必须先为大家介绍一下内存中按照用途被划分的5个区域。

- 栈区的特点是内存由系统进行控制,无论是分配还是回收都不需要程序员关心;
- 如果我们使用new来分配一段内存,那么这段内存会分配在堆区,最后我们自己必须用delete回收这段内存;
- 全局区用来存储全局变量和静态变量;
- 常量区用来存放一些字符串以及常量;
- 代码区则是存储编译过后的二进制代码。
下面通过一个例子来说明对象中数据是如何存储的。

首先定义一个Car类,在这个类被实例化之前,是不会占用堆或栈中的内存的,但是当它实例化之后,比如实例化一个car1,实例化一个car2,又实例化一个car3,这个时候每个实例化对象都会在栈中开辟一段内存用来存储各自的数据,但是它们是不同的变量,也就占据着不同的内存,而逻辑代码却只编译出一份,放在代码区,当需要的时候,这个代码区中的代码供所有的对象进行使用。谁需要了就去调用它,找到相应的代码入口,就可以执行相应的程序了。
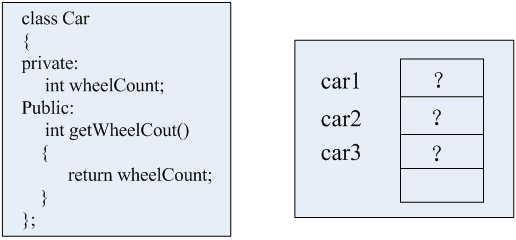
这时候,我们就注意到一个问题,当我们实例化三个对象之后,每个对象中的数据都是不可控的,都是未知的,因为我们没有对这些数据进行初始化。
如果没有进行初始化,我们就无法对这些数据进行预想的逻辑操作,可见我们必须要对数据进行初始化。
对象初始化
说到初始化,大家都不会陌生。相信大家都非常熟悉《坦克大战》这款游戏,每关开始的时候,玩家的坦克都会出现在固定的位置(最下面),而敌方的坦克都会在三个地方出现(左上角、右上角,上方中间位置),这就是初始化的结果。下面用程序描述一下初始化的过程。
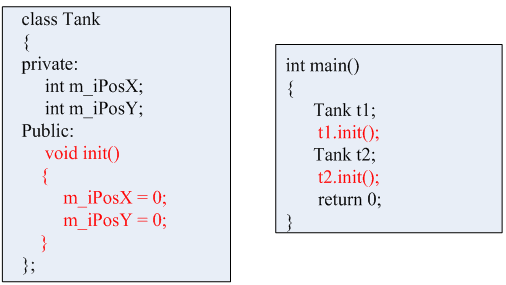
如果我们定义一个坦克的类,我们只描述坦克出现的位置,就需要两个变量(一个横坐标,一个纵坐标),另外,还需定义一个初始化函数(init),给横纵坐标赋初值0,那么其后面的位置就清晰可控了。使用的时候,先实例化一个坦克对象t1,通过t1来调用初始化函数(init),这样就将t1中的横坐标和纵坐标都置为0了。如果再实例化一个坦克对象t2,也调用初始化函数(init),这样就将t2的横坐标和纵坐标也置为了0。如下所示。
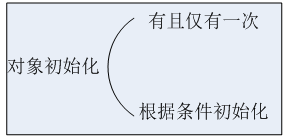
对于对象的初始化来说,不同的场合,可能有些只需要初始化一次,有些则需要根据条件而初始化多次,所以初始化也分为以下两种类型:
下面重点讲解有且仅有一次的初始化操作。
思考:对于有且仅有一次的初始化操作,初始化函数如何避免误操作呢?比如写代码时,一不小心忘记了调用初始化函数,也有可能在写程序时重复调用了初始化函数。那么这些误操作就有可能给程序带来灭顶之灾。为了能够帮助程序员避开这些风险,c++推出了一种新的函数,那就是构造函数,接下来我们就讲讲什么是构造函数。
构造函数
构造函数一个最大的特点就是在对象实例化时被自动调用,通常只需要将初始化的代码写在构造函数内就能够起到初始化数据的作用。这里面要强调的是,构造函数在实例化对象时,被调用且仅被调用一次。定义构造函数时,构造函数的名字必须与类同名。其次,构造函数没有返回值。(写构造函数时,连void这样的返回类型都不用写)。此外,构造函数可以有多个重载形式(重载时要遵循重载函数的规则)。另外,在实例化对象的时候,即便有多个构造函数,也仅用到其中的一个构造函数。最后一条非常重要,当用户没有定义构造函数时,编译器将自动生成一个构造函数(这个构造函数中没有做任何事情)。
总的来说,构造函数具有如下规则和特点:
- 构造函数在对象实例化时被自动调用;
- 构造函数必须与类同名;
- 构造函数没有返回值;
- 构造函数可以有多个重载形式;
- 实例化对象时仅用到一个构造函数;
- 当用户没有定义构造函数时,编译器将自动生成一个构造函数。
下面我们来看看构造函数是如何定义的。
无参构造函数
所谓无参构造函数就是构造函数没有参数,比如:

在这个Student类中,我们可以看到构造函数Student()与类名相同,构造函数的前面没有任何的返回值,构造函数的内部,我们对数据成员进行了赋值操作(即给了数据成员一个初始值)。
有参构造函数
所谓有参构造函数就是构造函数含有参数,比如:

这个构造函数的作用,就是用户在实例化一个Student对象时,可以传进来一个name,传进来的name就可以给数据成员一个初始值,从而就初始化了这个数据成员。
当然,构造函数是可以重载的,只需要遵循重载函数的规则就可以,比如:

构造函数代码实践
题目描述:
定义一个Teacher类,自定义无参构造函数,自定义有参构造函数;数据成员包含姓名和年龄;成员函数为数据成员的封装函数。
程序框架如下:

头文件(Teacher.h)
#include<iostream> #include<string> using namespace std; class Teacher { public: Teacher(); //申明无参构造函数 Teacher(string name, int age);//申明有参构造函数 void setName(string name); string getName(); void setAge(int age); int getAge(); private: string m_strName; int m_iAge; };
源文件:
#include"Teacher.h" #include<iostream> #include<stdlib.h> using namespace std; /* ************************************************************************/ /* 定义一个Teacher类,具体要求如下: /* 自定义无参构造函数 /* 自定义有参构造函数 /* 数据成员: /* 名字 /* 年龄 /* 成员函数: /* 数据成员的封装函数 /* ************************************************************************/ Teacher::Teacher() { m_strName = "Keiven"; m_iAge = 20; cout<<"Teacher()"<<endl; } Teacher::Teacher(string name, int age) { m_strName = name; m_iAge = age; cout<<"Teacher(string name, int age)"<<endl; } void Teacher::setName(string _name) { m_strName = _name; } string Teacher::getName() { return m_strName; } void Teacher::setAge(int _age) { m_iAge = _age; } int Teacher::getAge() { return m_iAge; } int main() { Teacher t1; //调用无参构造函数 Teacher t2("Mery", 30); //调用有参构造函数 //下面来看看这两个构造函数是不是完成了数据成员的初始化工作 cout<< t1.getName() <<" "<< t1.getAge() <<endl; cout<< t2.getName() <<" "<< t2.getAge() <<endl; system("pause"); return 0; }
运行结果:
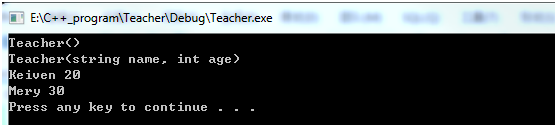
接下来要说另外一个问题,在我们的构造函数定义的时候,能不能给构造函数赋一个默认值呢?其实是可以的!!
比如在上面的有参构造函数中,我们给年龄赋值40,如果后面我们不对年龄赋值的话,我们将使用年龄40这个默认值。
Teacher::Teacher(string name, int age = 40)
然后实例化一个t3的对象,
Teacher t3("James"); //调用有参构造函数,只对名字赋值,不对年龄赋值
最后,我们打印t3的相关内容
cout<< t3.getName() <<" "<< t3.getAge() <<endl;

从而得到结论:
构造函数除了可以重载,还可以给参数赋默认值,但不能随意的赋默认值,有时会引起编译时不通过,原因是实例化对象时,编译器不知道调用哪一个构造函数了。
默认构造函数
问题:什么是默认构造函数呢?
其实对于大家来说,这仅仅是一个概念,实际内容在前面已经讲过了。为了说明默认构造函数这个概念,我们用一个例子来进行讲解。
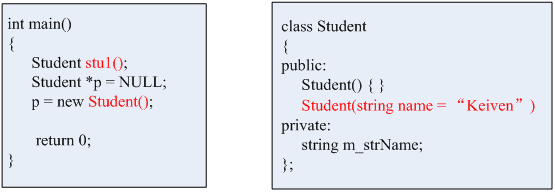
在main函数中,我们实例化了两个对象,一个是stu1,另一个是用p指向了内存中的一块空,从堆中实例化一个对象,并用指针p指向了它。无论是从栈中实例化对象还是从堆中实例化对象,都有一个共同的特点,即调用的构造函数都不用传参数。那么对于这样的调用形式,在定义构造函数的时候可以有不同的方式,比如像下面这样去定义,Student(){ }这样定义呢,构造函数本身就没有参数;当然,也可以这样去定义,Student(string name = “Keiven”)。在这两种情况下,实例化Student对象时,都不用给构造函数传递实参。我们把这种在实例化对象时,不需要传递参数的构造函数就称为默认构造函数。
构造函数初始化列表
首先来看一个例子

在这个例子中,我们定义了一个学生Student的类,在这个类中,我们定义了两个数据成员(一个名字,一个年龄),名字和年龄都通过初始化列表(即红色标记部分)进行了初始化。写的时候需要注意,在构造函数后面需要用冒号隔开,对于多个数据成员进行初始化的时候,中间要用逗号隔开,赋值时要用括号进行赋值,而不能用等号进行赋值。
初始化列表特性
---初始化列表先于构造函数执行---意味着编译器会献给初始化列表中的数据成员赋值,再执行构造函数中的相关代码。
---初始化列表只能用于构造函数
---初始化列表可以同时初始化多个数据成员
学习完初始化列表,大家肯定会有这样的疑问:C++大费周章地搞了一个初始化列表,而初始化列表的工作由构造函数完全可以代劳,最多也就稍微慢点,那初始化列表这个功能岂不是意义不大?
下面就通过一个例子来说明初始化列表的必要性。

在这个例子中,我们定义了一个圆Circle的类,在这个类中定义了一个pi值,因为pi是不变的,我们用const来修饰,从而pi就变成了一个常量。我们如果用构造函数来初始化这个常量(像上面那样),这样的话编译器就会报错,而且会告诉我们,因为pi是常量,不能再给它进行赋值。也就是说,我们用构造函数对pi进行赋值,就相当于第二次给pi赋值了。那如果我们想给这个pi赋值,并且又不导致语法错误,怎么办呢?唯一的办法就是通过初始化列表来实现(如下)。这个时候,编译器就可以正常工作了。

初始化列表代码实践
题目描述:
定义一个Teacher类,自定义有参默认构造函数,适用初始化列表初始化数据;数据成员包含姓名和年龄;成员函数为数据成员的封装函数;拓展:定义可以带最多学生的个数,此为常量。
程序框架如下:
头文件(Teacher.h)
#include<iostream> #include<string> using namespace std; class Teacher { public: Teacher(string name = "Keiven", int age = 20, int m = 100);//申明有参默认构造函数,带有初始值 void setName(string name); string getName(); void setAge(int age); int getAge(); int getMax(); private: string m_strName; int m_iAge; const int m_iMax; //由于该数据成员是常量,只能通过初始化列表的方式进行初始化 };
源文件:
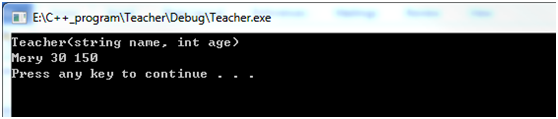
#include"Teacher.h" #include<iostream> #include<stdlib.h> using namespace std; /* ************************************************************************/ /* 定义一个Teacher类,具体要求如下: /* 自定义有参默认构造函数 /* 适用初始化列表初始化数据 /* 数据成员: /* 名字 /* 年龄 /* 成员函数: /* 数据成员的封装函数 /* 拓展: /* 定义可以带最多学生的个数,此为常量 /* ************************************************************************/ Teacher::Teacher(string name, int age, int m):m_strName(name), m_iAge(age), m_iMax(m) //初始化列表形式定义有参构造函数 { cout<<"Teacher(string name, int age)"<<endl; } int Teacher:: getMax() { return m_iMax; } void Teacher::setName(string _name) { m_strName = _name; } string Teacher::getName() { return m_strName; } void Teacher::setAge(int _age) { m_iAge = _age; } int Teacher::getAge() { return m_iAge; } int main() { Teacher t1("Mery", 30, 150); //调用有参构造函数 //下面来看看这两个构造函数是不是完成了数据成员的初始化工作 cout<< t1.getName() <<" "<< t1.getAge() <<" "<< t1.getMax() <<endl; system("pause"); return 0; }
运行结果:
拷贝构造函数
引例:

在这个例子中,我们定义了一个Student类,在类中又定义了一个默认构造函数,将字符串”Student”打印出来。然后在main函数中,首先实例化一个对象stu1(实例化过程中会调用默认构造函数),然后又实例化了两个对象stu2和stu3,并将stu1的值分别赋给stu2和stu3。但是当我们运行时,屏幕上只打印出一行字符串”Student”的字样,并没有像我们想象中那样应该会打印出三行字符串”Student”的字样,毕竟我们实例化了三个对象,理论上应该调用三次默认构造函数才对。这个时候,我们是不是有这样的疑问:实例化对象的时候不是一定能够调用默认构造函数的吗?现在怎么会出现这种问题呢?
实际上,后面两次实例化对象确实也调用了构造函数,只不过不是调用的我们在这定义的默认构造函数,而是调用的是另一种特殊的构造函数,叫做拷贝构造函数。
拷贝构造函数在定义的时候与普通构造函数基本相同,只是在参数上面有一些严格的要求。
下面通过一个例子来讲解如何定义拷贝构造函数。

还是以Student这个类为例,首先我们已经定义了一个构造函数,与这个构造函数相对比下面红色标记的就是拷贝构造函数。拷贝构造函数在名称上与普通构造函数一样,但是在参数设计上却有所不同。首先要加一个const关键字,其次传入的是一个引用,这个引用还是一个与自己的数据类型完全相同(也就是说,也是一个Student的一个对象)的引用。通过这样的定义方式,我们就定义出了一个拷贝构造函数。如果我们将相应的代码写在拷贝构造函数的实现的部分,那么我们再采用上面两种实例化对象的方式,就会执行拷贝构造函数里面的相应代码。我们发现,在实例化stu2和stu3的时候,我们并没有去定义拷贝构造函数,但是仍然可以将这两个对象实例化出来。可见,拷贝构造函数与普通的构造函数一样。
- 如果没有自定义拷贝构造函数,则系统会自动生成一个默认的拷贝构造函数。
- 当采用直接初始化或复制初始化实例化对象时,系统自动调用拷贝构造函数。
构造函数小结:
构造函数分为无参构造函数和有参构造函数两大类。无参构造函数因为没有参数,那么我们可以确定所有的无参构造函数都是默认构造函数;有参构造函数又分为两种:参数带有默认值的有参构造函数,参数不带默认值的有参构造函数。对于参数带有默认值的有参构造函数来说,如果所有的参数都带有默认值,那么它就是一个默认构造函数。
我们在学习构造函数这一块知识的时候,我们会发现系统会自动生成一些函数,这些自动生成的函数又分为普通构造函数和拷贝构造函数两大类。如果我们自定义了普通的构造函数,则系统就不会再自动生成普通构造函数,同理,如果我们定义了拷贝构造函数,那么系统也不会再生成拷贝构造函数。
对于初始化列表,只能连接在普通构造函数或者拷贝构造函数的后面。
对于拷贝构造函数,由于参数是确定的,所以不能进行重载。
析构函数
如果说构造函数是对象来到世间的第一首我难过呼吸,那么析构函数就是对象离开世间的临终的遗言。
析构函数在对象销毁时会被自动调用,完成的任务是归还系统的资源,收拾最后的残局。
析构函数的定义

思考:析构函数有存在的必要吗?
下面看一个经典的例子来说明析构函数的必要性
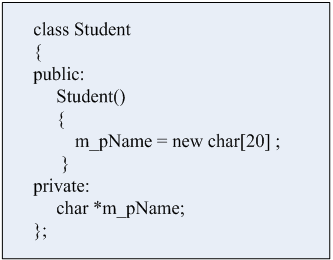
还是以Student这个学生的类为例,在它的数据成员中,我们不用string类型来定义姓名,我们改用指针,并且在其构造函数中,让这个指针指向堆中分配的一段内存,那么在这个对象销毁的时候,就必须释放掉这段内存,否则就会造成内存泄漏。要释放内存,最好的时机就是对象被销毁之前,如果销毁早了的话,其他的程序用到这些资源的时候就会报错。可见,设计一个在对象销毁之前被自动调用的函数就非常有必要了,那这个函数就是析构函数。
析构函数唯一的功能就是释放资源,其没有参数,所以析构函数就不能重载。
析构函数的特性
- 如果没有自定义析构函数,那么系统会自动生成一个析构函数。(这一点与构造函数和拷贝构造函数类似)
- 析构函数在对象销毁时被自动调用(与其相对的构造函数,则是在对象实例化时被自动调用)
- 析构函数没有返回值,也没有参数,也就不能重载
对象的生命历程
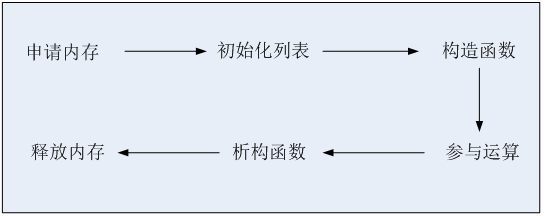
析构函数代码实践
题目描述:
定义一个Teacher类,自定义析构函数;对于普通方式实例化的对象,在销毁对象时是否自动调用析构函数;通过拷贝构造函数实例化的对象,在销毁对象时是否自动调用析构函数;数据成员包含姓名和年龄;成员函数为数据成员的封装函数。
程序框架如下:

头文件(Teacher.h)
#include<iostream> #include<string> using namespace std; class Teacher { public: Teacher(string name = "Keiven", int age = 20);//申明有参默认构造函数,带有初始值 Teacher(const Teacher &tea); //申明拷贝构造函数 ~Teacher(); void setName(string name); string getName(); void setAge(int age); int getAge(); int getMax(); private: string m_strName; int m_iAge; };
源文件:
#include"Teacher.h" #include<iostream> #include<stdlib.h> using namespace std; /* ************************************************************************/ /* 定义一个Teacher类,具体要求如下: /* 1、自定义析构函数 /* 2、对于普通方式实例化的对象,在销毁对象时是否自动调用析构函数 /* 3、通过拷贝构造函数实例化的对象,在销毁对象时是否自动调用析构函数 /* 数据成员: /* 名字 /* 年龄 /* 成员函数: /* 数据成员的封装函数 /* ************************************************************************/ Teacher::Teacher(string name, int age):m_strName(name), m_iAge(age) //初始化列表形式定义有参构造函数 { cout<<"Teacher(string name, int age)"<<endl; } Teacher::Teacher(const Teacher &tea) { cout<<"Teacher(const Teacher &tea)"<<endl; } Teacher::~Teacher() { cout<<"~Teacher()"<<endl; } void Teacher::setName(string _name) { m_strName = _name; } string Teacher::getName() { return m_strName; } void Teacher::setAge(int _age) { m_iAge = _age; } int Teacher::getAge() { return m_iAge; } int main() { Teacher t1; //在栈上实例化一个对象 Teacher *p = newTeacher(); //在堆上实例化一个对象 delete p; system("pause"); return 0; }
运行结果:

我们在按任意键结束后,会有调用的析构函数过程一闪而过(这就是普通构造函数实例化对象销毁时也自动调用了析构函数)
下面通过拷贝构造函数来实例化对象:
int main() { Teacher t1; //在栈上实例化一个对象 Teacher t2(t1); //通过拷贝构造函数实例化对象 system("pause"); return 0; }
运行结果:

我们在按任意键结束后,会有调用的析构函数过程一闪而过(这就是普通构造函数实例化对象和通过拷贝构造函数实例化对象销毁时也自动调用了析构函数)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号