搭建centos7的开发环境3-Spark安装配置
说起大数据开发,必然就会提到Spark,在这片博文中,我们就介绍一下Spark的安装和配置。
这是Centos7开发环境系列的第三篇,本篇的安装会基于之前的配置进行,有需要的请回复搭建centos7的开发环境1-系统安装及Python配置、搭建centos7的开发环境2-单机版Hadoop2.7.3配置。
安装Spark
这里说明一下各种软件的版本号:
open-JDK: 1.8.0
Hadoop: 2.7.3
scala: 2.11.8
Spark: 2.1.0
scala
- 下载 sacla2.11.8
- 解压安装,并配置环境变量
tar -zxvf scala-2.11.8.tgzsudo mv scala-2.11.8 /usr/scala
spark
- 下载 spark 2.1.0
- 解压安装,并配置环境变量
tar -zxvf spark-2.1.0-bin-hadoop2.7.tgzsudo mv spark-2.1.0 /usr/sparkvim /etc/profile========================export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"SCALA_HOME=/usr/scalaexport PATH=$PATH:$SCALA_HOME/binSPARK_HOME=/usr/sparkexport PATH=$SPARK_HOME/bin:$PATH========================source /etc/profile###########################export SCALA_HOME=/usr/scalaexport JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64export SPARK_MASTER_IP=127.0.0.1export SPARK_LOCAL_IP=127.0.0.1export SPARK_WORKER_MEMORY=1gexport HADOOP_CONF_DIR=/usr/hadoop/etc/hadoop
配置完成之后,启动命令
/usr/hadoop/sbin/start-all.sh
/usr/spark/sbin/start-all.sh
打开链接 http://127.0.0.1:8080/,现在可以看到:
![]()
在终端分别输入spark-shell和pyspark都运行正常。

wordcount测试
创建数据集
在spark官网拷贝了一个网页作为数据源创建words.txt作为输入数据,并导入hdfs.
touch words.txtvim words.txtcd /usr/hadoop/sbinhadoop fs -mkdir hdfs://localhost:9000/inputhadoop fs -put /home/kejun/words.txt hdfs://localhost:90000/inputpyspark
现在进入pyspark的界面:
textFile=sc.textFile("hdfs://localhost:9000/input/words.txt")counts = textFile.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)counts.saveAsTextFile("hdfs://localhost:9000/input/out")
在hdfs的filesystem可以下载到wordcount结果
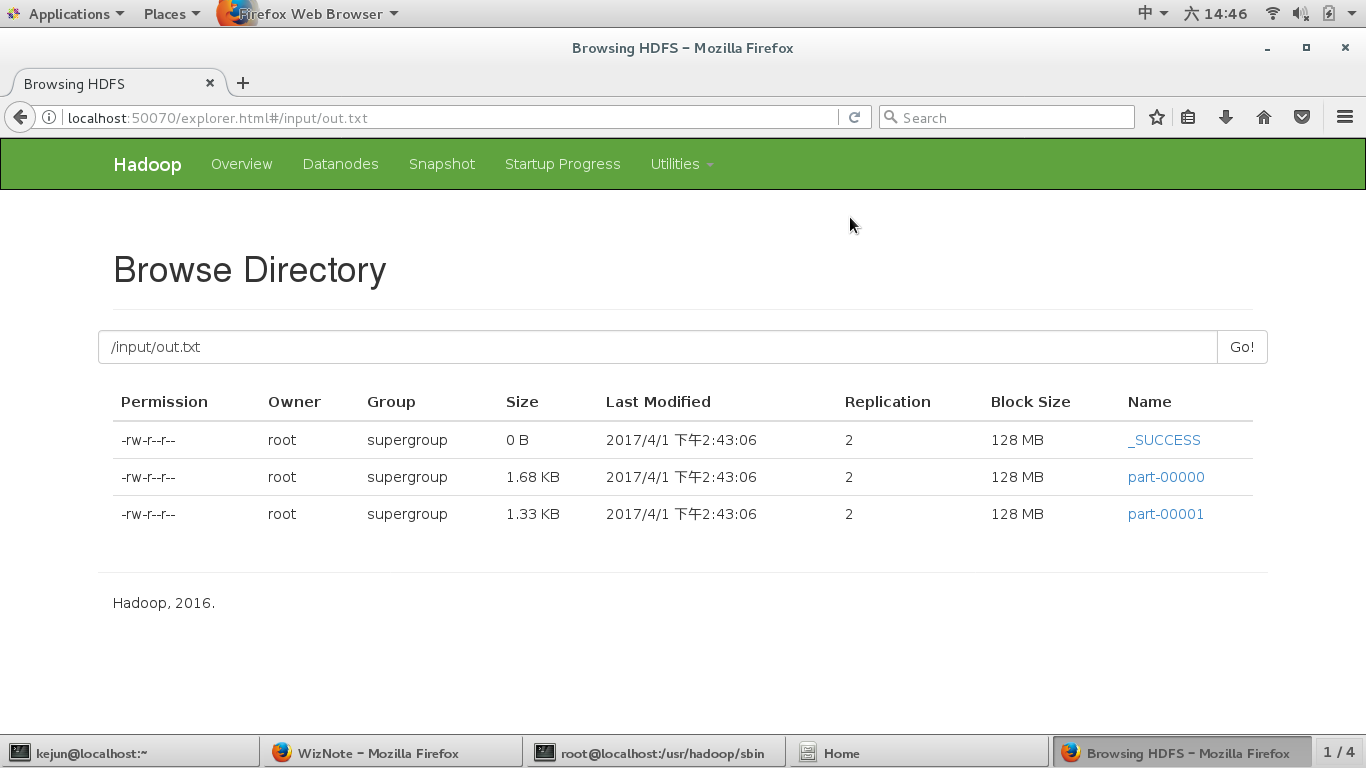
spark安装成功啦~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号