搭建centos7的开发环境2-单机版Hadoop2.7.3配置
最近公司准备升级spark环境,主要原因是生产环境的spark和hadoop版本都比较低,但是具体升级到何种版本还不确定,需要做进一步的测试分析。这个任务对于大数据开发环境配置有要求,这里记录一下配置过程,但是对于为什么要做这些配置还不是很了解,算是知其然不知其所以然,深入了解再写篇博文分析。
JDK配置
按照上一篇博文的配置,我发现centos7的 JDK已经安装好了,可以通过下面的代码进行检查,如下图,显示的1.8.0_121的openJDK
[kejun@localhost ~]$ java -version
openjdk version "1.8.0_121"
OpenJDK Runtime Environment (build 1.8.0_121-b13)
OpenJDK 64-Bit Server VM (build 25.121-b13, mixed mode)
没有安装也不要紧,通过yum安装还是很方便的,可以通过下面的指令来安装JDK:
yum search java|grep jdk
yum install java-1.8.0-openjdk
下一步是配置JAVA的环境变量,因为是系统默认安装的JDK,所以要找到JDK的目录比较困难,需要通过下面两个语句来进行查询,第一个查询是获得/usr/bin/java的依赖连接,第二个查询是进一步获得依赖的依赖的:
[kejun@localhost ~]$ ll /usr/bin/java
lrwxrwxrwx. 1 root root 22 3月 16 17:11 /usr/bin/java -> /etc/alternatives/java
[kejun@localhost ~]$ ll /etc/alternatives/java
lrwxrwxrwx. 1 root root 73 3月 16 17:11 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64/jre/bin/java通过这个办法得到的/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64就是系统默认的JDK目录。获得JDK目录后,配置环境变量的指令为:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH有三种方法可以支持配置JAVA的环境变量:
在shell终端中通过上述命令直接执行,这种配置只对当前的shell有效,所以不推荐。
修改~/.bash_profile文件,在下面的两个语句中进行插入即可
PATH=$PATH:$HOME/.local/bin:$HOME/bin
#这里插入
export PATH这个修改只针对当前的用户生效。但是hadoop配置中可能需要切换到另外一个用户hadoop进行配置,因此这个方法也不适合。
修改/etc/profile,这种配置方法适合于所有用户,但是这种修改比较适合单人的开发环境使用,我们选择这种方式。
vi /etc/profile
source /etc/profile到此,我们完成了JDK的配置。下一步进入hadoop的安装。
hadoop安装
安装参考的文档是:CentOS 6.5 hadoop 2.7.3 集群环境搭建
Linux Hadoop2.7.3 安装(单机模式) 一
hadoop有三种安装模式:单机standlone模式,伪分布式模式,分布式模式。
因为没有多余的服务器资源供我测试,这里我选择了单机模式的安装。
- 首先是安装hadoop,目前hadoop已经更新到3.0版本了,但是2.7.3肯定还是主流版本,我选择从清华的源下载了hadoop安装包:
cd /tmp
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
tar -zxvf hadoop-2.7.3.tar.gz
cp -R /tmp/hadoop-2.7.3 /usr/hadoop- 增加hadoop的环境变量
sudo -i
vim /etc/profile
HADOOP_HOME=/usr/hadoop
export JAVA_LIBRARY_PATH='/usr/hadoop/lib/native
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin- 设置免密钥登陆。
hadoop中客户端和服务器、计算节点之间通信都需要通过SSH,Hadoop并没有提供SSH输入密码的登录形式,因此为了保证可以顺利登录每台机器,需要将所有机器配置为namenode可以无密码登录它们。不配置免密钥有什么坏处我还没搞清楚,后续再补充。
首先通过rpm -qa | grep ssh 检查ssh是否安装:
[root@localhost ~]# rpm -qa | grep ssh
openssh-clients-6.6.1p1-33.el7_3.x86_64
openssh-6.6.1p1-33.el7_3.x86_64
openssh-server-6.6.1p1-33.el7_3.x86_64
libssh2-1.4.3-10.el7_2.1.x86_64如果没有发现ssh也不要紧,可以通过yum安装:
yum install openssh-clients
yum install openssh-server 接下来依次执行,下面的指令可以确保当前用户可以免密钥登陆:
ssh localhost
cd ~/.ssh/
ssh-keygen -t dsa
cat id_dsa.pub >> authorized_keys
通过root用户修改ssh的配置:
sudo -i
vim /etc/ssh/sshd_config
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
service sshd restart后续在配置hadoop的过程中,我们会发现会出现ssh的错误:The authenticity of host 0.0.0.0 can't be established.
解决方法可以通过下列命令解决:
ssh -o StrictHostKeyChecking=no 0.0.0.0配置hadoop
完成hadoop及ssh的安装步骤后,接下来是对hadoop的配置文件进行修改。
- 修改/usr/hadoop/etc/hadoop/core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://0.0.0.0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/temp</value>
</property>
</configuration>- 修改/usr/hadoop/etc/hadoop/hdfs-site.xmll文件
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>- 首次启动需要格式化namenode文件
/usr/hadoop/bin/hdfs namenode -format- 然后可以启动和停止hdfs
/usr/hadoop/sbin/start-dfs.sh
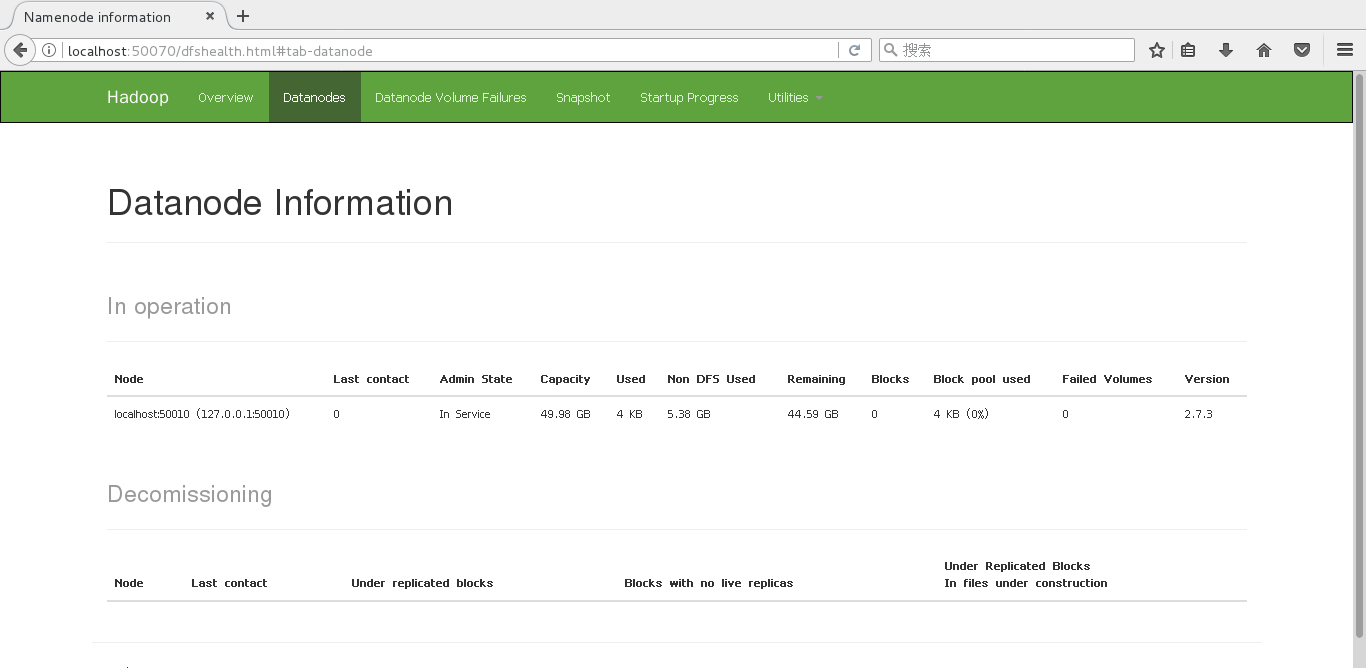
/usr/hadoop/sbin/stop-dfs.sh启动后,访问 http://localhost:50070/dfshealth.html#tab-datanode 可以得到这个页面,就是配置成功了。
##Map-Reduce示例
为了验证单机版的hadoop配置是否正确,接下来做一个map-reduce的样例。对于一个文本的单词集进行计数
具体的配置如下:
- 首先配置mapred-site.xml
cd /usr/hadoop/etc/hadoop
mv mapred-site.xml.template mapred-site.xml
vim mapred-site xml
===============================
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
===============================
</configuration>- 配置 yarn-site.xml:
vim mapred-site xml
===============================
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration
===============================- 准备数据words.txt,并将其导入hdfs:
[root@localhost hadoop]# cd /usr/hadoop
[root@localhost hadoop]# vi words.txt
[root@localhost hadoop]# cat words.txt
=============================
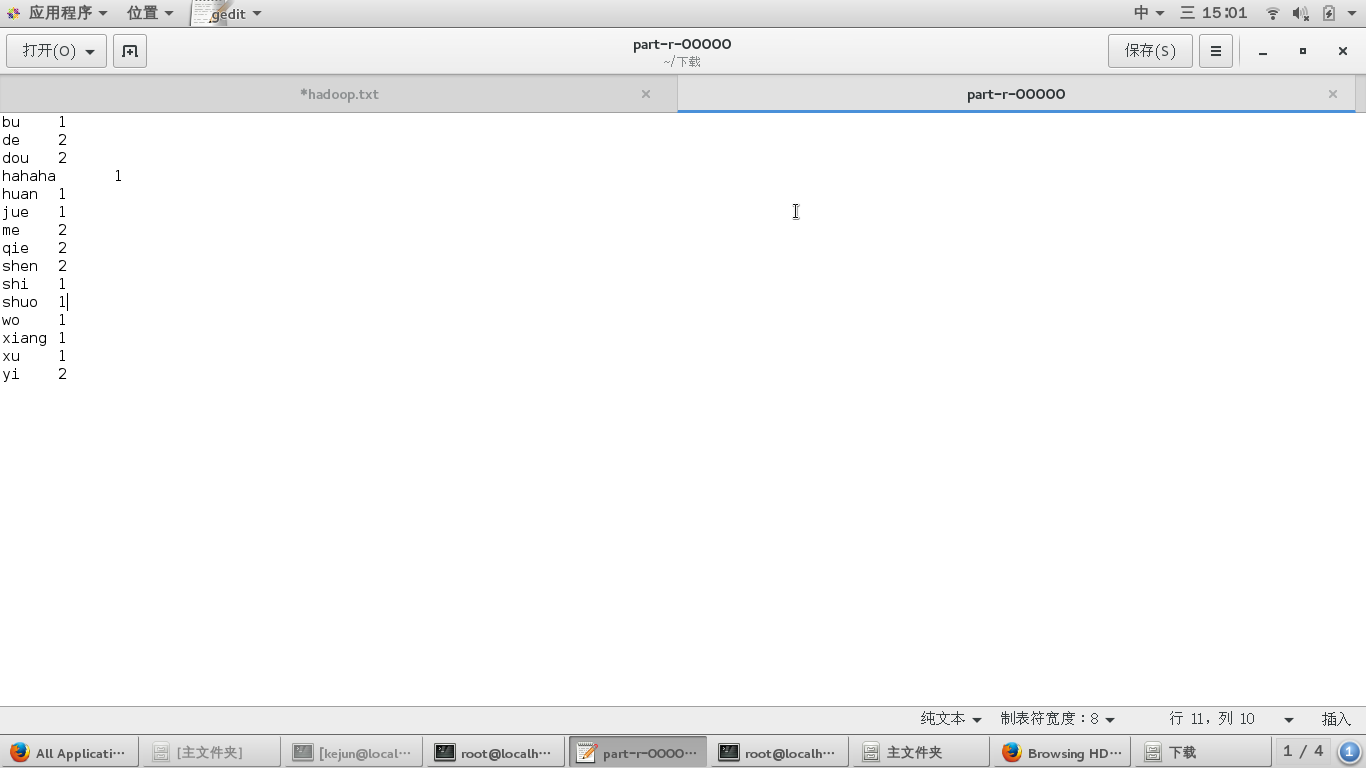
wo xiang shuo shen me
shen me dou bu jue de
yi qie yi qie dou shi xu huan de
hahaha
=============================
[root@localhost hadoop]# cd bin
[root@localhost bin]# hadoop fs -put /usr/hadoop/words.tx- 启动yarn,并执行wordcount任务:
[root@localhost bin]# start-yarn.sh
[root@localhost bin]# hadoop jar /usr/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount hdfs://localhost:9000/words.txt hdfs://localhost:9000/out3接下来,打开链接就可以看到结果了http://localhost:50070/explorer.html#/
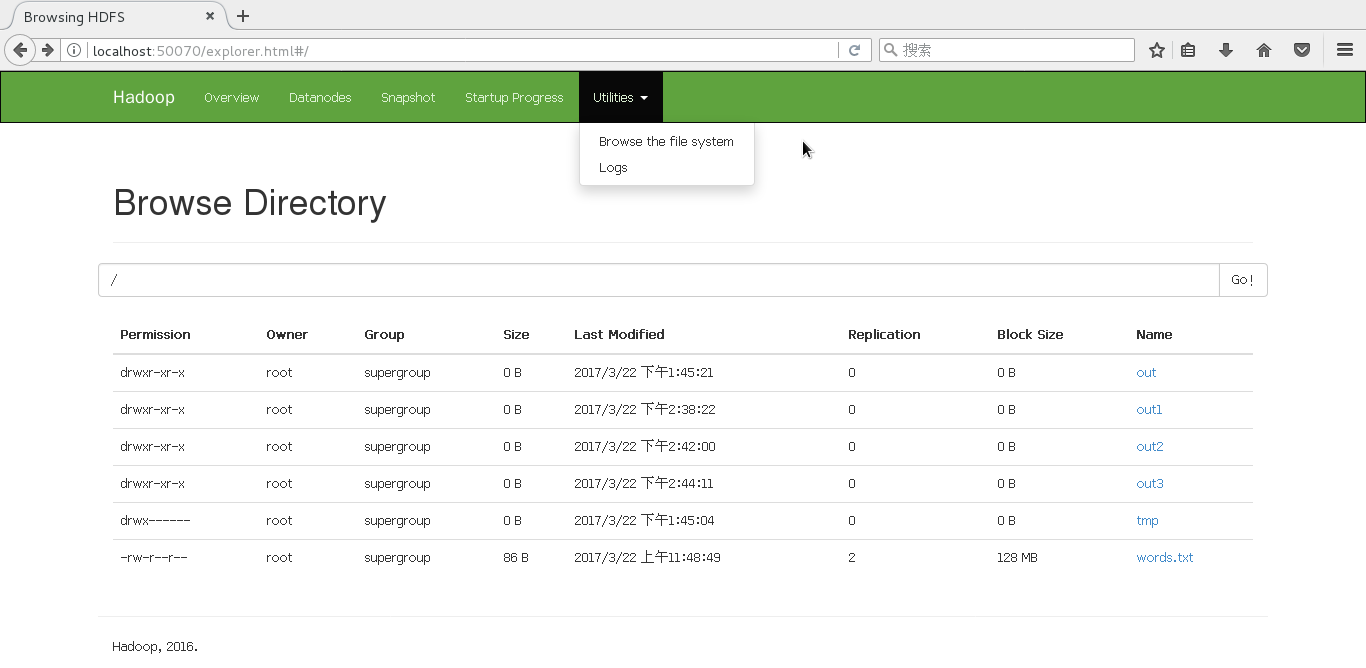
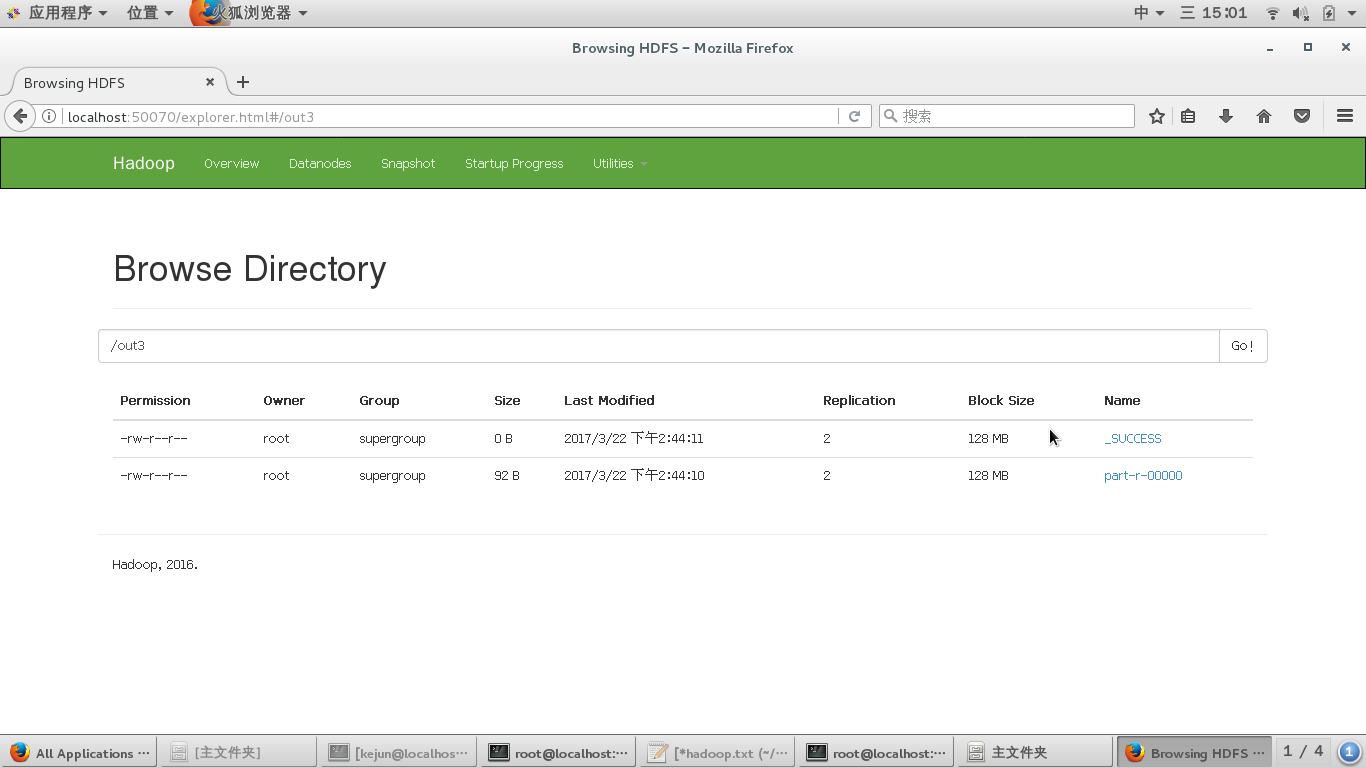
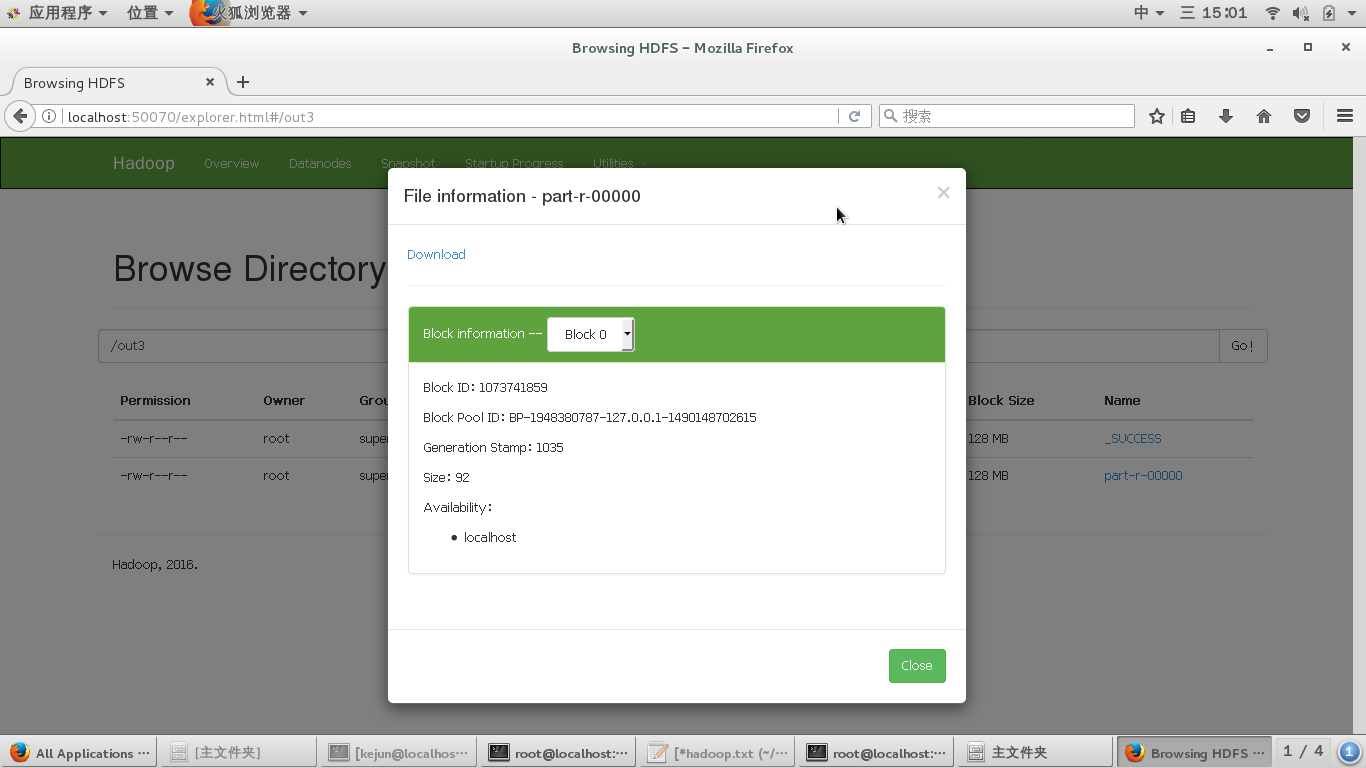
遇到的问题及解决
- p1:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
首先,启动在终端显示debug信息,然后再开始寻找原因:
export HADOOP_ROOT_LOGGER=DEBUG,console网上也有人有类似的问题,但是原因并不总是一样的,我配置的出现这个问题是因为JAVA_LIBRARY_PATH没有配置,这个在配置我已经在上文的hadoop环境配置中增加上了(标粗体)
- p2: data node没有启动
这个问题出现的比较隐蔽,我打开页面http://localhost:50070/dfshealth.html#tab-datanode 发现没有data node在运行。
首先name node、data node和namesecondary的运行文件都在/usr/hadoop/logs这个目录中
然后检查logs文件目录中的hadoop-root-datanode-localhost.localdomain.log就可以发现问题了:
[root@localhost logs]# ls
hadoop-root-datanode-localhost.localdomain.log
hadoop-root-datanode-localhost.localdomain.out
hadoop-root-datanode-localhost.localdomain.out.1
hadoop-root-datanode-localhost.localdomain.out.2
hadoop-root-datanode-localhost.localdomain.out.3
hadoop-root-datanode-localhost.localdomain.out.4
hadoop-root-datanode-localhost.localdomain.out.5
hadoop-root-namenode-localhost.localdomain.log
hadoop-root-namenode-localhost.localdomain.out
hadoop-root-namenode-localhost.localdomain.out.1
hadoop-root-namenode-localhost.localdomain.out.2
hadoop-root-namenode-localhost.localdomain.out.3
hadoop-root-namenode-localhost.localdomain.out.4
hadoop-root-namenode-localhost.localdomain.out.5
hadoop-root-secondarynamenode-localhost.localdomain.log
hadoop-root-secondarynamenode-localhost.localdomain.out
hadoop-root-secondarynamenode-localhost.localdomain.out.1
hadoop-root-secondarynamenode-localhost.localdomain.out.2
hadoop-root-secondarynamenode-localhost.localdomain.out.3
hadoop-root-secondarynamenode-localhost.localdomain.out.4
hadoop-root-secondarynamenode-localhost.localdomain.out.5
SecurityAuth-root.audit
userlogs
yarn-root-nodemanager-localhost.localdomain.log
yarn-root-nodemanager-localhost.localdomain.out
yarn-root-nodemanager-localhost.localdomain.out.1
yarn-root-nodemanager-localhost.localdomain.out.2
yarn-root-nodemanager-localhost.localdomain.out.3
yarn-root-resourcemanager-localhost.localdomain.log
yarn-root-resourcemanager-localhost.localdomain.out
yarn-root-resourcemanager-localhost.localdomain.out.1
yarn-root-resourcemanager-localhost.localdomain.out.2
yarn-root-resourcemanager-localhost.localdomain.out.3检查log后发现出现data node不启动的原因是使用了多次namenode format的操作,后台存储的clusterID为第一次format的ID,再次format后datanode的clusterID没有变化,导致匹配不上,具体的报错情况为:
java.io.IOException: Incompatible clusterIDs in /usr/hadoop/temp/dfs/data: namenode clusterID = CID-9754ec5b-c309-4b36-89ce-f00de7285927; datanode clusterID = CID-d05d2a3a-4fe7-4de4-a53a-6960403696cc
解决这个问题比较简单,到datanode目录下修改VISION即可:
[root@localhost hadoop]# cd /usr/hadoop/temp/dfs/data/current/
[root@localhost current]# ls
BP-1948380787-127.0.0.1-1490148702615 VERSION
BP-2135918609-127.0.0.1-1490082190396
[root@localhost current]# vim VERSION
=======================================
storageID=DS-34e30373-c8e1-4bfa-a5c7-84fd43ac99e2
clusterID=#在这里修改#
cTime=0
datanodeUuid=ae0dae79-7de1-4207-8151-af6a6b86079d
storageType=DATA_NODE
layoutVersion=-56
=======================================
 浙公网安备 33010602011771号
浙公网安备 33010602011771号