


HADOOP
Hadoop概述:一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
一、 hadoop 的版本
随着这几年大数据浪潮的兴起, hadoop 的各种版本也快速在国内流传和使用。当前主要的 hadoop 版本有以下几种:
1、 Apache hadoop 的 2.0 版本,它的模块主要有以下几个:
(1) hadoop 通用模块,支持其他 hadoop 模块的通用工具集;
(2) Hadoop 分布式文件系统,支持对应数据高吞吐量访问的分布式文件系统;
(3) 用于作业调度和集群资源管理的 Hadoop YANRN 框架;
(4) Hadoop MapReduce ,基于 YARN 的大数据并行处理系统 。
2 、 Cloudera hadoop : Cloudera 版本层次更加清晰,且它提供了适用于各种操作系统的 Hadoop 安装包,可直接使用 apt-get 或者 yum 命令进行安装,更加省事。
3 、 Hortonworks : Hortonworks 的主打产品是 Hortonworks Data Platform (HDP) ,也同样是 100% 开源的产品, HDP 除了常见的项目外还包含了 Ambari ,一款开源的安装和管理系统。 HCatalog ,一个元数据管理系统, HCatalog 现已集成到 Facebook 开源的 Hive 中。 Hortonworks 的 Stinger 开创性地极大地优化了 Hive 项目。 Hortonworks 为入门提供了一个非常好的,易于使用的沙盒。 Hortonworks 开发了很多增强特性并提交至核心主干,这使得 Apache Hadoop 能够在包括 Windows Server 和 Windows Azure 在内的 Microsoft Windows 平台上本地运行。
二、国产 hadoop 发行版有哪些
国内做 hadoop 发行版的像 华为 、 大快搜索 都有推出自己的发行版。华为在硬件上有天然的有事, 华为的 FusionInsight Hadoop 版本基于 Apache Hadoop ,构建 NameNode 、 JobTracker 、 HiveServer 的 HA 功能,进程故障后系统自动 Failover ,无需人工干预,这个也是对 Hadoop 的小修补,远不如 MapR 解决的彻底。
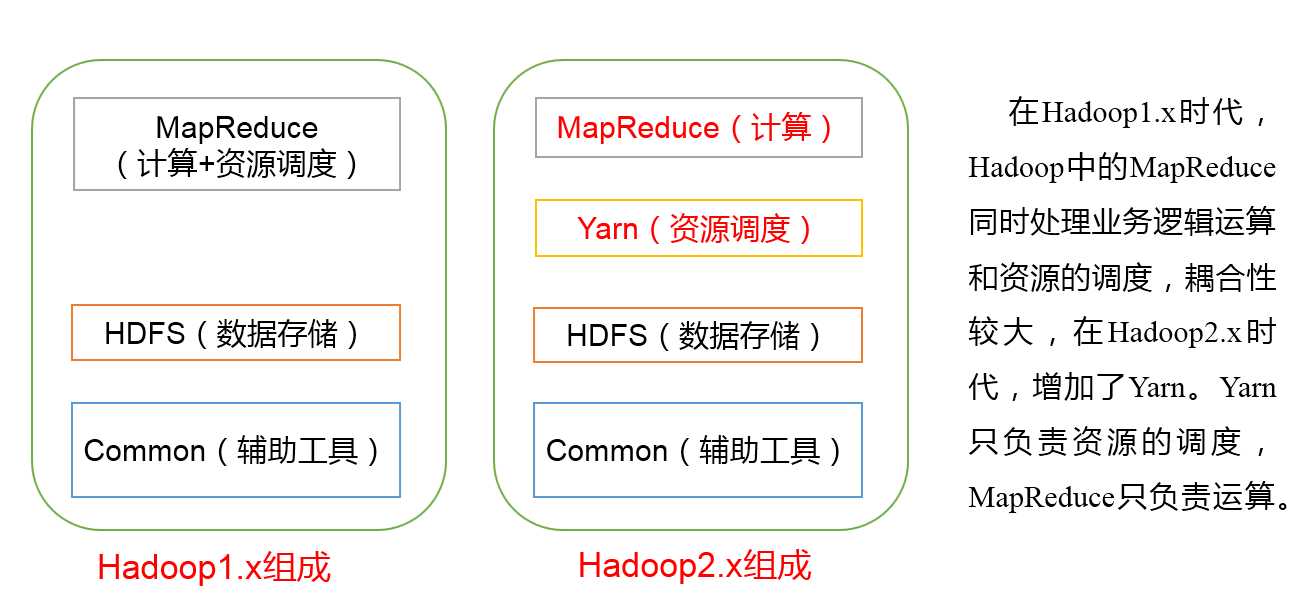
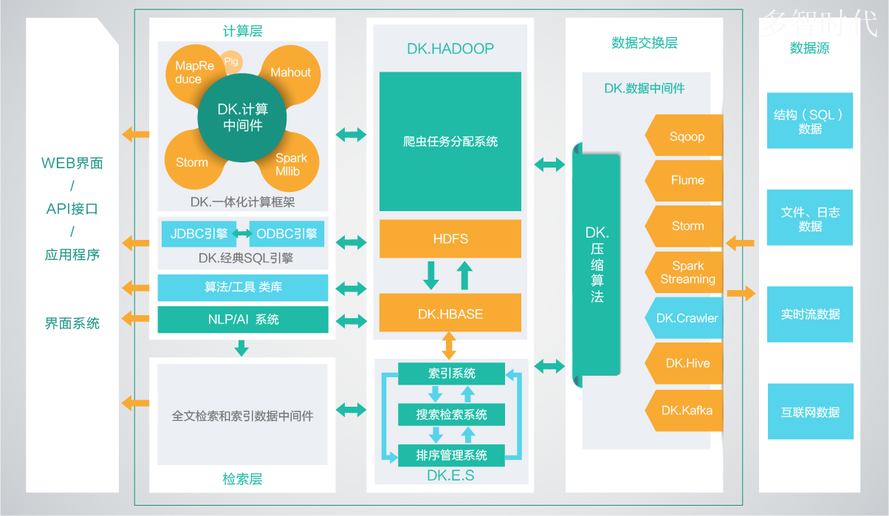
大快搜索推出的 DKhaoop , 是目前已知的国产发行版中唯一一个纯原生态的开发, 集成了整个 HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。
三、hadoop生态圈
组件简介 Ambari/Cloudera Manager Hue BigTop
Shark、Storm、Spark、Mesos、Tez Drill Hama、Flume Hcatalog、Sqoop Map Reduce、Chukwa Pig、HBase Hive、Cassandra Impala Mahout、Accumulo RHadoop、Phoenix Giraph、Search Whirr、HttpFs WebHdfs、YARN:分布式操作系统 HDFS:分布式存储、Avro Zookeeper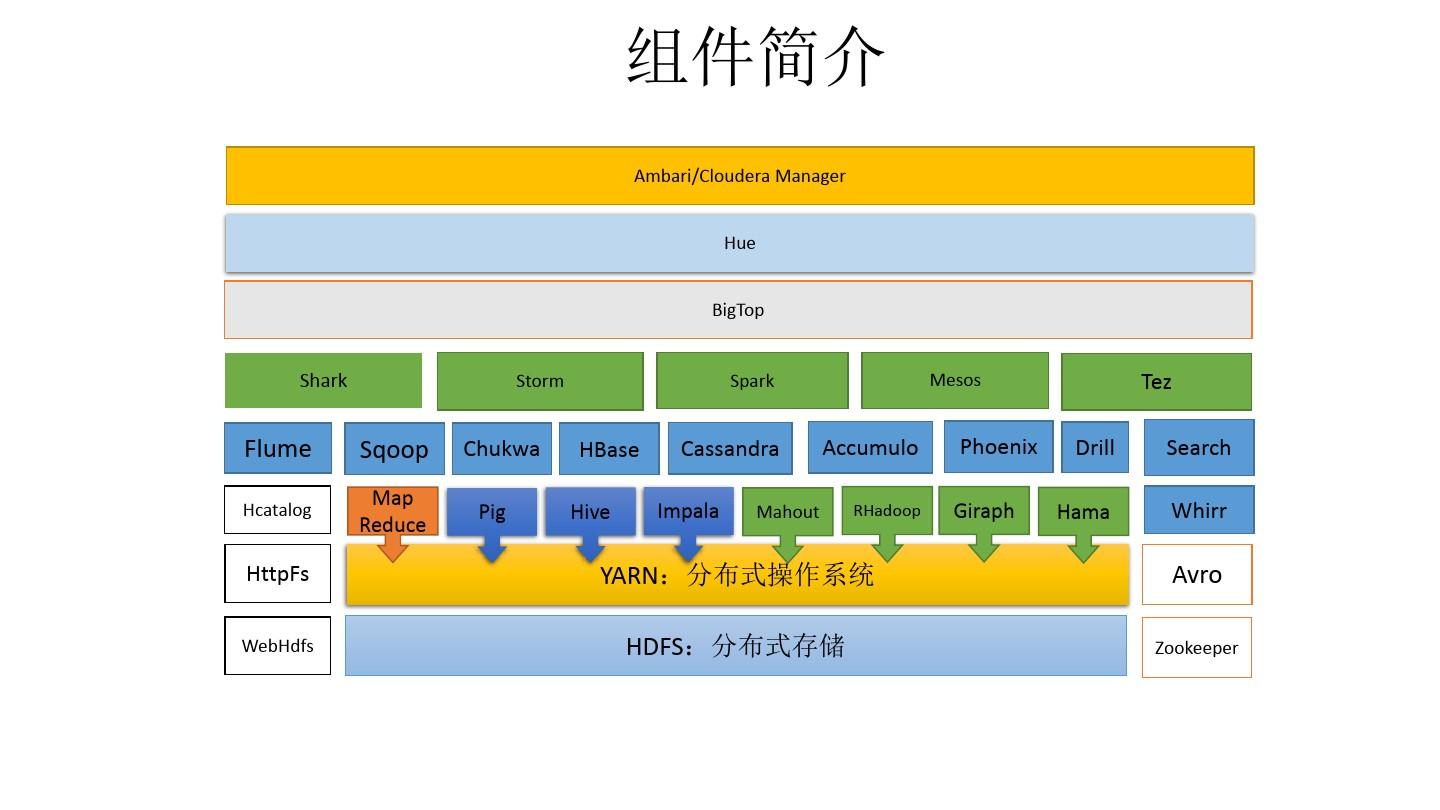
| 组件名 | 功能及作用 | 优势 | 局限 | 应用场景 | 相关功能组件 |
|---|---|---|---|---|---|
| HDFS | 分布式文件系统。存储是大数据技术的基础 | (1)高吞吐量访问; (2)高容错性; (3)容量扩充 | (1)不适合低延迟数据访问; (2)不适合存储大量小文件; (3)不支持多用户写入及任意修改文件(只能执行追加操作,写操作只能在文件末位完成) | 可处理超大文件,可运行于廉价的商用机器集群。 | hadoop文件系统包含local(支持有客户端校验和的本地文件系统)、har(构建在其他文件系统上进行归档文件的文件系统,在hadoop主要被用来减少namenode的内存使用)、kfs(cloudstroe前身是Kosmos文件系统,是类似于HDFS和Google的GFS的文件系统)、ftp(由FTP服务器支持的文件系统) |
| Mapreduce | 计算模型 | (1)被多台主机同事处理,速度快; (2)擅长处理少量大数据; (3)容错性,节点故障导致失败作业时,mapreduce计算框架会自动将作业安排到健康的节点 | (1)不适合大量小数据; (2)过于底层化,编程复杂; (3)JobTracker单点瓶颈,JobTracker负责作业的分发、管理和调度,任务量多会造成其内存和网络带宽的快速消耗,最终使其成为集群的单点瓶颈; (4)Task分配容易不均; (5)作业延迟高(TaskTracker汇报资源和运行情况,JobTracker根据其汇报情况分配作业等过程); (6)编程框架不够灵活; (7)Map池和Reduce池区分降低了资源利用率; | 日志分析、海量数据排序、在海量数据中查找特定模式等 | 可用hive简化操作,完成简单任务 |
| Yarn | 改善MapReduce的缺陷 | (1)分散了JobTracker任务,提高了集群的扩展性和可用性; (2)扩大了MapReduce编程人员范围; (3)在资管管理器故障时,可快速重启恢复状态; (4)不再区分Map池和Reduce池,提高了资源利用率; | |||
| Hive | 数据仓库 | (1)易操作; (2)能处理不变的大规模数据级上的批量任务; (3)可扩展性(可自动适应机器数目和数据量的动态变化); (4)可延展性(结合mapreduce和用户定义的函数库); (5)良好的容错性; (6)低约束的数据输入格式 | (1)不提供数据排序和查询功能; (2)不提供在线事务处理; (3)不提供实时查询; (4)执行延迟 | ||
| Hbase | 数据仓库 | 数据库,存储松散型数据。向下提供存储,向上提供运算。 | (1)海量存储; (2)列式存储; (3)极易扩展(基于RegionServer上层处理能力的扩展和基于HDFS存储的扩展); (4)高并发; (5)稀疏,列数据为空时,不会占用存储空间。 | (1)对多表关联查询支持不足; (2)不支持sql,开发难度加大 | 查询简单、不涉及复杂关联的场景,如海量流水数据、交易记录、数据库历史数据 |
| Pig | 数据分析平台,侧重数据查询和分析,而不是对数据进行修改和删除等。需要把真正的查询转换成相应的MapReduce作业 | (1)处理海量数据的速度快 (2)相较mapreduce,使用Pig Latin编写程序时,不需关心程序如何更好地在hadoop云平台上运行,因为这些都有pig系统自行分配。 (3)在资管管理器故障时,可快速重启恢复状态; (4)不再区分Map池和Reduce池,提高了资源利用率; | 处理系统内日志文件、处理大型数据库文件、处理特定web数据 | 可看做简化mapreduce的高级语言 | |
| Zookeeper | 协调服务 | (1)高吞吐量 (2)低延迟 (3)高可靠 (4)有序性,每一次更新操作都有一个全局版本号 | 控制集群中的数据,如管理hadoop集群中的NameNode、Hbase中的Mster Election、Server见的状态同步 | ||
| Avro | 基于二进制数据传输高性能的中间件。数据序列化系统,可以将数据结构或对象转化成便于存储或传输的格式,以节约数据存储空间和网络传输贷款。适用于远程或本地大批量数据交互。 | (1)模式和数据在一起,反序列化时写入的模式和独处的模式都是已知的; (2)多语言支持; (3)可有效减少大规模存储较小的数据文件的数据量; (4)丰富的数据结构类型 | hadoop的RPC | ||
| Chukwa | 数据收集系统,帮助hadoop用户清晰了解系统运行的状态,分析作业运行的状态及HDFS的文件存储状态 | Scribe存储在中央存储系统(NFS)、Kafka、Flume。看到一篇对于日志系统讲的比较清晰的,也做了分类比较,再次引用给大家。 |
四、Hadoop的安装与使用
| 三种安装模式 | ||
| 单机模式 | 伪分布式模式 | 完全分布式模式 |
1.装备hadoop集群节点,配置相关节点(Linux主机)的配置信息。
1.0先将虚拟机的网络模式选为NAT
1.1修改主机名
hostnamectl set-hostname server1
1.2修改IP
修改配置文件方式(修改的是网卡信息 ip a 查看网卡),第一次启动时没有ip的,需要将 网卡配置之中 ONBOOT=yes, 然后重启网络

vim /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE="eth0" BOOTPROTO="static" ### HWADDR="00:0C:29:3C:BF:E7" IPV6INIT="yes" NM_CONTROLLED="yes" ONBOOT="yes" TYPE="Ethernet" UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c" IPADDR="192.168.1.101" ### NETMASK="255.255.255.0" ### GATEWAY="192.168.1.1" ###
1.3修改主机名和IP的映射关系(每台机器都要有)
192.168.33.101 server1
192.168.33.102 server2
192.168.33.103 server3
1.4关闭防火墙
#查看防火墙状态 service iptables status #关闭防火墙 service iptables stop #查看防火墙开机启动状态 chkconfig iptables --list #关闭防火墙开机启动 chkconfig iptables off
1.5 关闭linux服务器的图形界面:
vi /etc/inittab
1.6重启Linux
reboot
2.配置节点JDK环境。
#创建文件夹 mkdir /home/hadoop/app #解压 tar -zxvf jdk-7u55-linux-i586.tar.gz -C /home/hadoop/app
2.3将java添加到环境变量中(如果在 .bashrc 之中配置了java环境变量,hadoop 是不需要指定 JAVA_HOME,如果在 /etc/profile 需要指定,因为 ssh 默认不会加载 /et/profile)
vim ~/.bashrc #在文件最后添加 export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585 export PATH=$PATH:$JAVA_HOME/bin
#刷新配置
source ~/.bashrc
3.安装hadoop2.4.1(要保证以下文件都有读写权限)
先上传hadoop的安装包到服务器上去/home/hadoop/
分布式需要修改5个配置文件
3.1配置hadoop
vim hadoop-env.sh export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585
第二个:core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://server1:9000</value>
</property>
<!--hadoop 的默认用户-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>master</value>
</property>
<!--datanode.data.dir 存储文件目录, namenode.name.dir 元数据,namenode.edits.dir 日志目录 三者都依赖于此目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.7.0/data/tmp</value>
</property>
第三个:hdfs-site.xml
<!--其他用户使用hdfs 操作文件,是否进行验证!-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
第四个:mapred-site.xml (mv mapred-site.xml.template mapred-site.xml)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--日志页面的显示 ip:port-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>sserver1:10020</value>
</property>
<!--运行 yarn 任务跳转的页面-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>server1:19888</value>
</property>
第五个:yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>server1</value>
</property>
<!-- reducer获取数据的方式,一种辅助 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--开启日志聚集-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志存放的时间(s)-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>100000</value>
</property>
第六个 salves(代表着 DataNode个数, 在sbin/slaves 之中 ssh 遍历连接)
server1
server2
server3
3.2将hadoop添加到环境变量
vim /etc/proflie export JAVA_HOME=/usr/java/jdk1.7.0_65 export HADOOP_HOME=/master/hadoop-2.4.1 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile
3.3 将 app 文件夹 配置到 其他的节点之上(节点信息与master配置信息是一样的)
scp -r app/ hdp-node-01:/home/slave
3.4 格式化namenode(是对namenode进行初始化)
hdfs namenode -format (hadoop namenode -format)
3.5启动hadoop
先启动HDFS sbin/start-dfs.sh 再启动YARN sbin/start-yarn.sh
3.6验证是否启动成功
使用jps命令验证 27408 NameNode 28218 Jps 27643 SecondaryNameNode 28066 NodeManager 27803 ResourceManager 27512 DataNode http://192.168.1.101:50070 (HDFS管理界面) http://192.168.1.101:8088 (MR管理界面)
4.安装SSH,并配置SSH无密码访问,连通各个节点。
#生成ssh免登陆密钥
#进入到我的home目录
cd ~
ssh-keygen -t rsa #四个回车
#执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
# master ,authorized_keys 文件(新生成)
ssh-copy-id -i ~/.ssh/id_rsa.pub localhost
#slave, authorized_keys 文件(新生成),此处是在 /etc/hosts 写入的(集群是相同的用户名)
ssh-copy-id -i ~/.ssh/id_rsa.pub server1![复制代码]()
5,注:更改文件夹权限
更改文件夹权限 # 切换超级权限 su # 当前文件夹所有的用户与组 chown -R hadoop:hadoop *
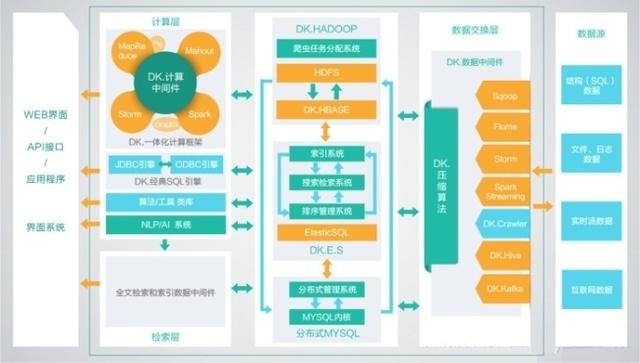
1、DKhadoop发行版:有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。
因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。
DKhadoop将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),极大的简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。
2、Cloudera发行版:CDH是Cloudera的hadoop发行版,完全开源,比Apache hadoop在兼容性,安全性,稳定性上有增强。
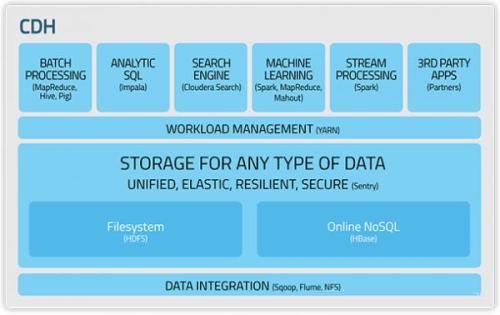
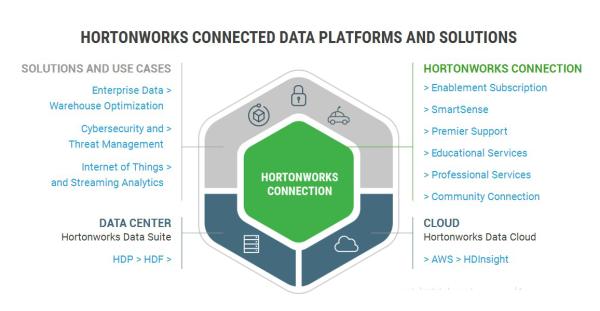
3、Hortonworks发行版:Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,其版本特点:HDP包括稳定版本的Apache Hadoop的所有关键组件;
安装方便,HDP包括一个现代化的,直观的用户界面的安装和配置工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号