


计算机是怎么样工作的?
实验环境:Ubuntu12.04
下面我们通过 example.c 代码分别生成.cpp .s .o 和ELF可执行文件,并加载运行来分析 程序 example在CPU上执行的整个过程,并由此分析单任务计算机和多任务计算机的工作原理:
example.c
2 int g(int x) 3 { 4 return x + 3; 5 } 6 7 int f(int x) 8 { 9 return g(x); 10 } 11 int main() 12 { 13 return f(8) + 1;
}
一:
为了在系统上运行example.c 程序,每条C语句都必须转化为低级机器语言指令,然后这些指令按照一种称为可执行目标程序的格式打好包,并以二进制磁盘文件的形式存放起来。
在Linux系统上,从源文件到目标文件的转化是由编译器驱动程序完成的:
>gcc - o example example.cd
在这里,GCC编译器,读取源程序文件example.c 并把它翻译成一个可执行目标文件 example。
这个翻译过程分为四个阶段:
1:预处理阶段
预处理器根据以字符#开头的命令,修改原始的C程序,如果这里的example.c中的最前面加上#include<stdio.h>,告诉预处理器,读取系统文件stdio.h的内容,并把它直接插入到程序文本中,结果就得到另外一个C程序。
这里可以通过命令:gcc –E –o example.cpp example.c 来查看预处理之后的程序example.cpp,打开example.cpp文件,可以看到经过预处理的程序。
2:编译阶段
编译器将文本文件example.cpp 翻译成文本文件 example.s,它包含了对应的汇编程序:
可以根据第一阶段预处理后的 example.cpp 来生成汇编程序 命令:> gcc –x cpp-output –S –o example.s example.cpp
也可以直接通过原程序生成:> gcc –S –o example.s example.c
3:汇编阶段
汇编器(as)将example.s翻译成机器语言指令,把这些指令打包成可重定位目标程序的格式,并将结果保存在目标文件example.o中,它是个二进制文件,字节编码是机器语言指令。
这阶段可以通过 第二阶段生成的example.s 来生成:>gcc –x assembler –c example.s -o example.o
也可以直接通过原程序生成: > gcc –c example.c -o example.o
> as –o example.o example.s
4:链接阶段
在example程序中,最后调用了printf函数,它是标准C库中的一个函数。printf函数存在于一个名为printf.o的单独预编译好了的目标文件中,而这个文件必须以某种方式合并到example.o程序中,链接器就是负责这些工作的。结果就得到了example文件,是一个可执行目标文件,可以被加载进内存执行。
生成可执行目标程序:可以接着第三阶段生成: >gcc -o example example.o
也可以从原程序生成: >gcc -o example example.c
此刻,example.c源程序已经被编译系统翻译成了可执行目标文件example,并存放在磁盘上,要想在linux系统上运行,我们将example文件名输入到外壳(shell)应用程序中:
> ./example
初始,shell执行它的指令,等待我们输入命令,当我们输入 ./example 后,shell 应用程序将字符读入寄存器,再存放到存储器中,然后shell执行一系列指令来加载可执行的example文件,将example目标文件中的代码和数据从磁盘复制到内存,然后处理器从main程序中的机器语言指令开始顺序执行。
二:
下面再从汇编代码的角度来具体分析程序执行过程:
1 080483b4 <g>: 2 80483b4: 55 push %ebp 3 80483b5: 89 e5 mov %esp,%ebp 4 80483b7: 8b 45 08 mov 0x8(%ebp),%eax 5 80483ba: 83 c0 03 add $0x3,%eax 6 80483bd: 5d pop %ebp 7 80483be: c3 ret 8 9 080483bf <f>: 10 80483bf: 55 push %ebp 11 80483c0: 89 e5 mov %esp,%ebp 12 80483c2: 83 ec 04 sub $0x4,%esp 13 80483c5: 8b 45 08 mov 0x8(%ebp),%eax 14 80483c8: 89 04 24 mov %eax,(%esp) 15 80483cb: e8 e4 ff ff ff call 80483b4 <g> 16 80483d0: c9 leave 17 80483d1: c3 ret 18 19 080483d2 <main>: 20 80483d2: 55 push %ebp 21 80483d3: 89 e5 mov %esp,%ebp 22 80483d5: 83 ec 04 sub $0x4,%esp 23 80483d8: c7 04 24 08 00 00 00 movl $0x8,(%esp) 24 80483df: e8 db ff ff ff call 80483bf <f> 25 80483e4: 83 c0 01 add $0x1,%eax 26 80483e7: c9 leave
分析之前,先介绍3个寄存器,及3个特殊指令所执行的动作:
1:esp:栈指针,总是指向栈顶 ebp:栈基址指针,指向栈底 eip:总是指向下一条要执行指令的地址
2:call 指令:执行call 指令时:会把当前eip的值压栈保存,并使得eip等于被调用函数的起始地址。
3:leave指令:执行leave指令,等于下面两条指令:
movl %ebp , %esp //使栈顶指针指向栈基指针
pop %ebp //使得栈基指针恢复为前一次保存的ebp的值
4:ret指令:等于 pop %eip 即恢复eip的值。
三:
下面分析指令从main函数开始执行过程中,函数栈的变换:
假设系统刚开始为该进程分配的栈状况如图1:

图 1
从main函数中第一条指令开始运行,直到运行到g函数中的add $0x3,%eax指令后,栈的状态如图2所示:
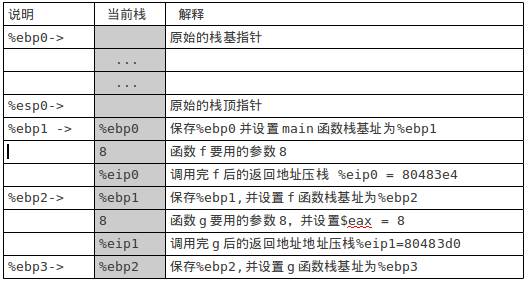
图2
把 x+3的计算结果11存放到%eax 中,下面进行函数返回操作: pop %ebp ret 执行完上面两条指令后的栈如图3:
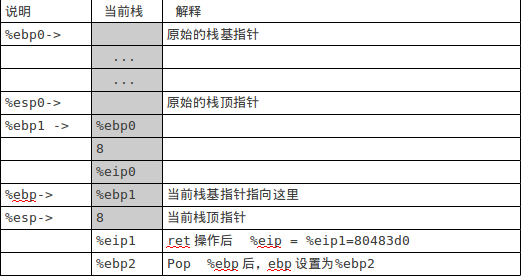
图3
当前eip= 80483d0,即跳转到f函数中的leave指令处开始执行: leave ret 执行完上面两条指令后,栈如图4:
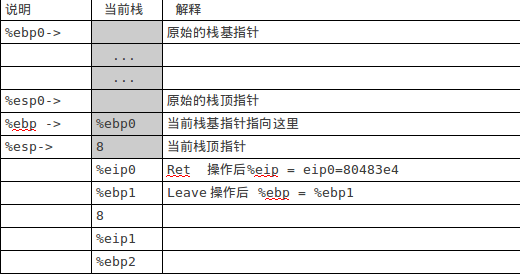
图4
当前eip=80483e4即回到了main函数中,下面执行 f(8)+1对应的操作: add $0x1,%eax 最后计算结果保存在eax中,等于12 执行leave操作后,栈如图5下:
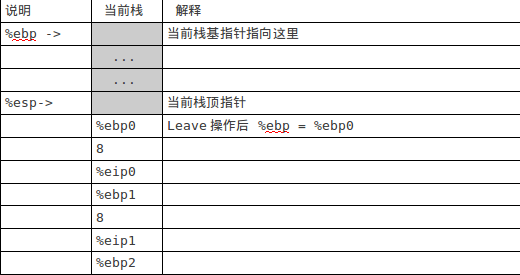
图5
从图5中可以看出,最后栈恢复之前的状态,跟图1中的原始栈一样。
下面我们根据example汇编代码的执行流程来分析单任务计算机和多任务计算机是怎么工作的:
如果把main函数 f函数 g函数看成是3个不同的任务,那么从上面的汇编代码分析可以发现 对于单任务,计算机是按顺序从起始地址一条指令接着一条指令执行的,但是这里实现了main,f,g 多任务的执行,那是通过什么机制来实现的呢?
通过上面的分析,我们不难发现是通过修改堆栈,保存任务流程断点信息(上下文:例如栈基址%ebp,和原下一条将要执行指令的地址%eip),并在将来某个时间恢复该上下文(通过pop,ret,leave操作恢复%ebp %eip的值),然后继续该任务流程”的方式,就是多任务的核心机制。
从上面的汇编代码分析中也可以看出每个任务都设有一个私有堆栈,用于保存任务流被折断(任务切换)时的堆栈内容,方便返回之前的任务继续执行。
由此可见,单任务的执行就是简单的从上到下按控制流执行。
多任务的执行是通过修改堆栈来改变任务的控制流方向实现多任务的并发执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号