
[Spark性能调优] 源码补充 : Spark 2.1.X 中 Unified 和 Static MemoryManager
本课主题
- Static MemoryManager 的源码鉴赏
- Unified MemoryManager 的源码鉴赏
引言
从源码的角度了解 Spark 内存管理是怎么设计的,从而知道应该配置那个参数让程序运行更适合你的实际需要,我们为什么要把 Spark Memory 这块内存调大,原因很简单,理论上讲你调得愈来,你占用的空间愈大,程序运行时所产生的 IO 就会愈来愈少,理论可以参考第四章 : Spark 中 JVM 内存使用及配置内幕详情。这一章是对于理论的源码补充!希望这篇文章能为读者带出以下的启发:
- 了解 MemoryManger: Unified Memory Manager, Static Memory Manager 以及它们的核心功能与方法
- 了解 MemoryPool: StorageMemoryPool 和 ExecutionMemoryPool 以及它们的核心功能与方法
Spark 2.1.0 中两种内存管理的源码剖析
回顾上一章所讲的 Spark Shuffle 内存分配理论,我们知道 Spark Shuffle 的内存管理有两种:一种是联合内存管理器 (Spark Unified Memory)、一种是静态内存管理器 (Spark Static Memory),首先这两个类都是继承著 MemoryManager,MemoryManager 是一个抽象类,它这样设计很容易理解呀,我们应用程序中使用接口就是为了包容未来的变化,因为现在只有两个内存管理器,将来可能会有好几种内存控制器。

MemoryManager 主要有几个功能:
- 记录用了多少 StorageMemory 和 ExecutionMemory
- 申请 Storage、Execution 和 Unroll Memory:acquireStorageMemory, acquireExectionMemory, acquireUnrollMemory
- 释放 Storage 和 Execution Memory
抽象类 MemoryManager
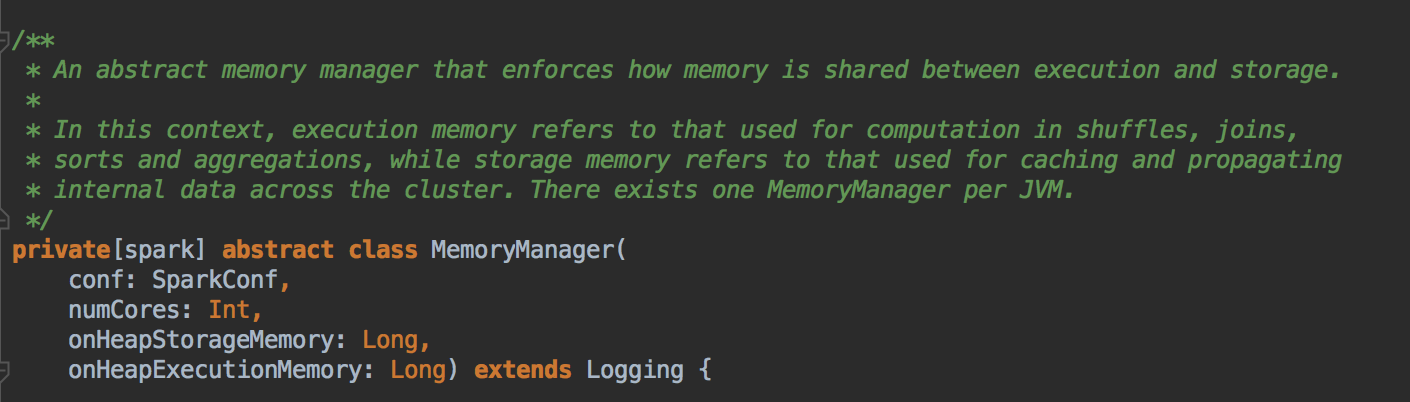
- 首先看看 MemoryManger ,它会强制管理储存(Storage)和执行(Execution)之间的内存使用,从 MemoryManager 申请可以把剩馀空间借给对方。所有 Task 的运行就是 ShuffleTask 的运行,ExecutionMemory是指 Shuffles,joins,sorts 和 aggregation 的操作;而 StorageMemory 是缓存和广播数据相关的,每一个 JVM 会产生一个 MemoryManager 来负责管理内存。MemoryManager 构造时,需要指定 onHeapStorageMemeory和 onHeapExecutionMemory 的参数。
[下图是 MemoryManager.scala 中 抽象类 MemoryManager 接收的参数]![]()
- 在 MemoryManager 对象构造的时候创建 StorageMemoryPool 和 ExecutionMemoryPool 对象,用来管理了 Storage 和 Execution 的内存分配。
[下图是 MemoryManager.scala 中 OnHeapStorageMemoryPool, OffHeapStorageMemoryPool, OnHeapExecutionMemoryPool, OffHeapExecutionMemoryPool 变量]![]()
这里是 StorageMemory 用来记录 Storage 使用了多少内存
[下图是 StorageMemoryPool.scala 中 memoryUsed 方法]![]()
这里是 ExecutionMemory 用来记录 Execution 使用了多少内存,它创建一些 HashMap 来存储每个 Task 的内存使用量,把 Map 中的所有 Value 加起来便用当前 ExecutionMemory 的总使用量。
[下图是 ExecutionMemoryPool.scala 中 memoryUsed 方法]![]()
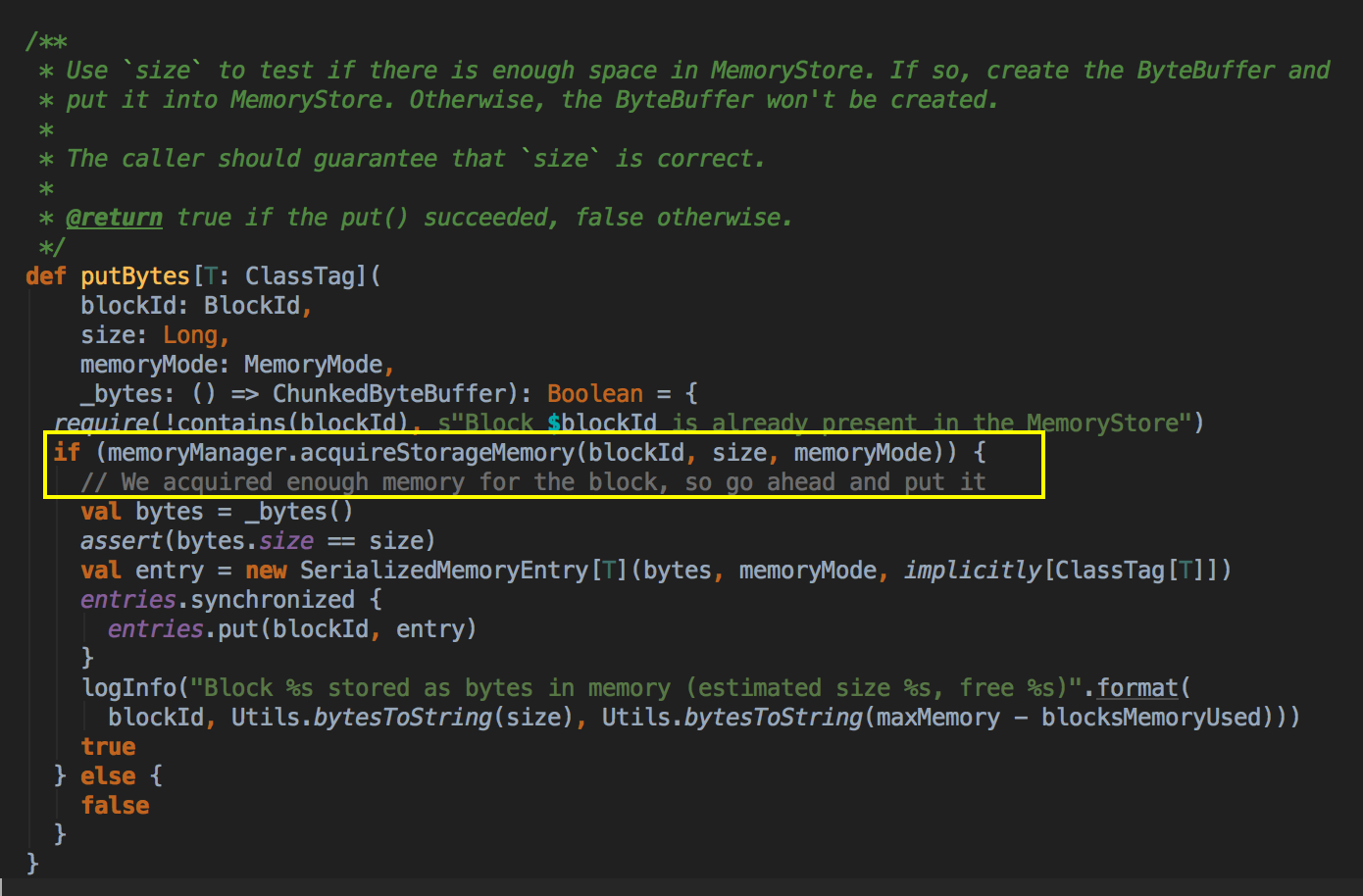
- MemoryStore 也是被 BlockManager 管理的,以下是其中一个 MemoryStore 调用 acquireStorageMemory 方法的源代码,一个 Block 怎么实代化可以参考 [Spark内核] 第38课:BlockManager架构原理、运行流程图和源码解密
[下图是 MemoryStore.scala 中 putBytes 方法]![]()
- 现在 Spark 2.1 默认的 MemoryManager 是 UnifiedMemoryManager,你可以看到下里有一段条件判断的逻辑,如果 spark.memory.userLegacyMode 是 true 的话,MemeoryManager 便是 StaticMemoryManager,否则的话就是 Spark Unified Memory。
[下图是 SparkEnv.scala 中 memoryManager 变量]![]()
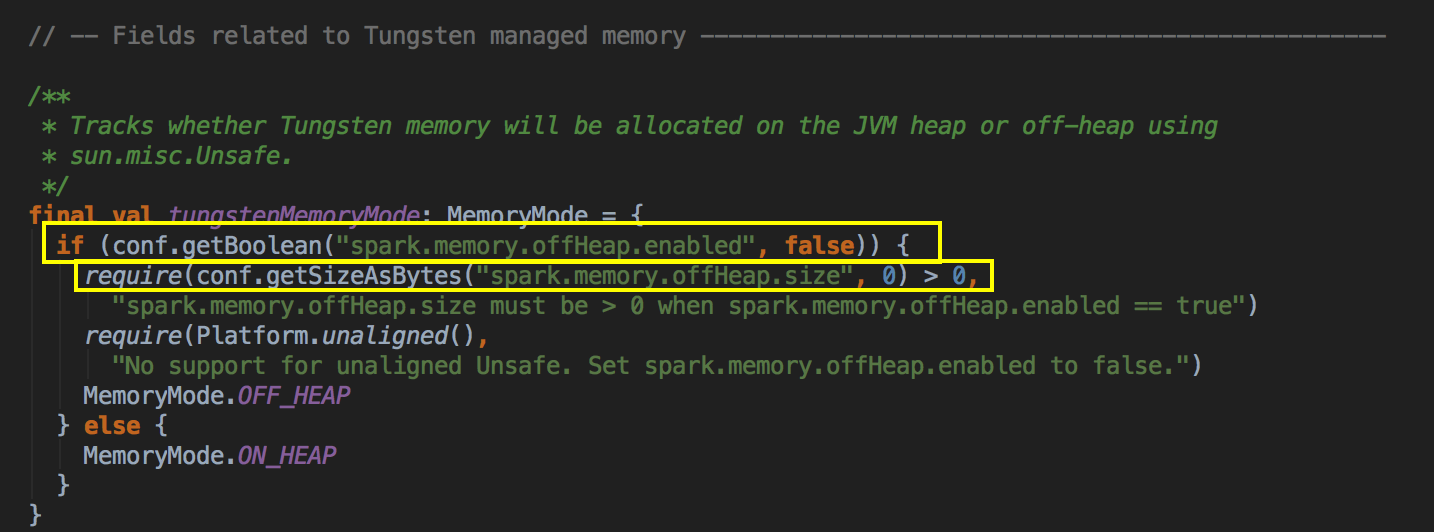
- 在 MemoryManager 中有一个很关键的代码,如果你想使用 OffHeap 作为储存的话,你必需设置 spark.memory.offHeap.enabled 为 true,还有确定你的 offHeap 系统的空间必须大于 0。
[下图是 MemoryManager.scala 中 tungstenMemoryMode 变量]![]()




Static MemoryManager 的源码鉴赏
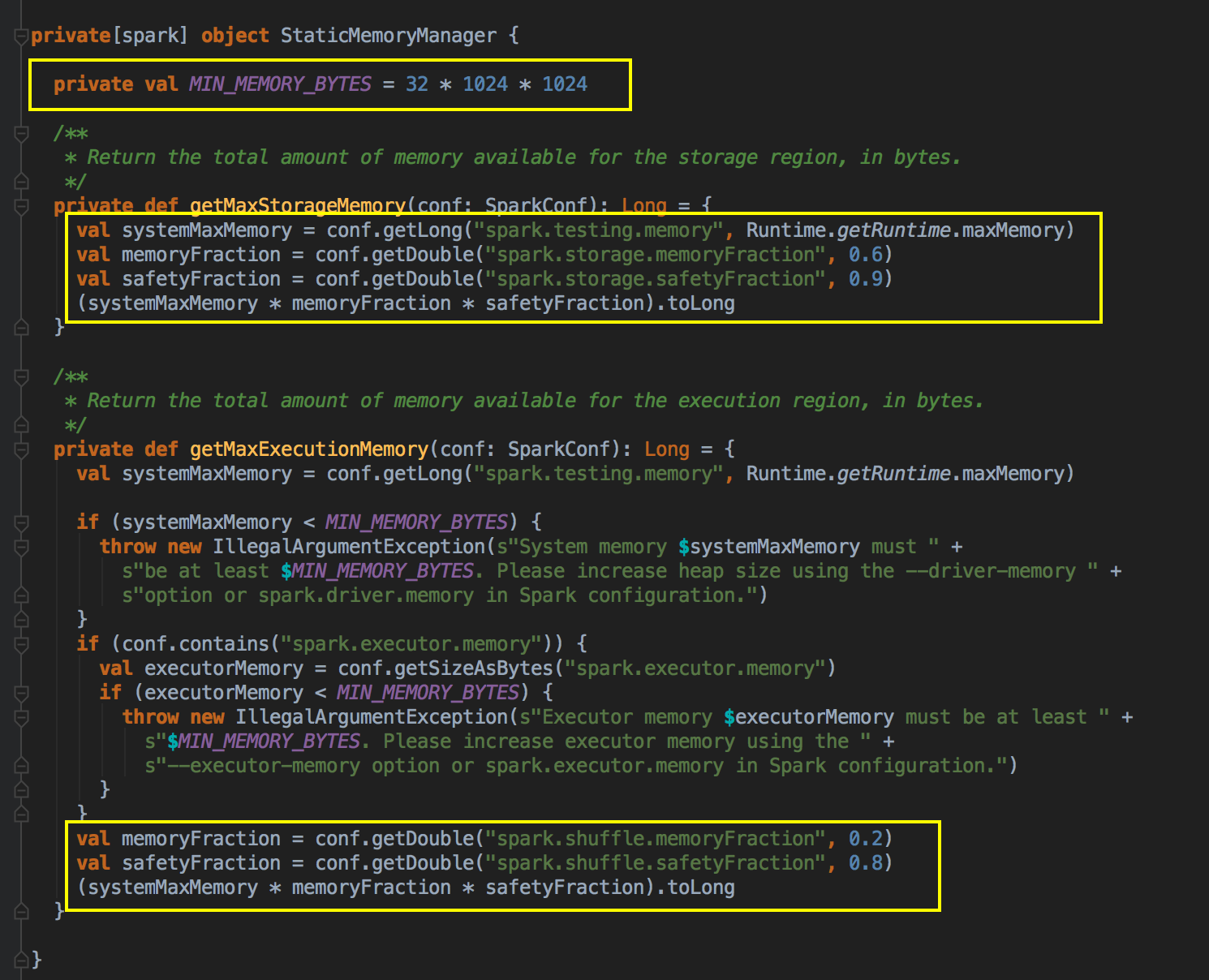
- 默认空间的计算方式
[下图是 StaticMemoryManager.scala 中 getMaxStorageMemory 方法]![]()
[下图是 StaticMemoryManager.scala 中 maxUnrollMemory 变量]![]()
- acquireStorageMemory
[下图是 StaticMemoryManager.scala 中 acquireStorageMemory 方法]![]()
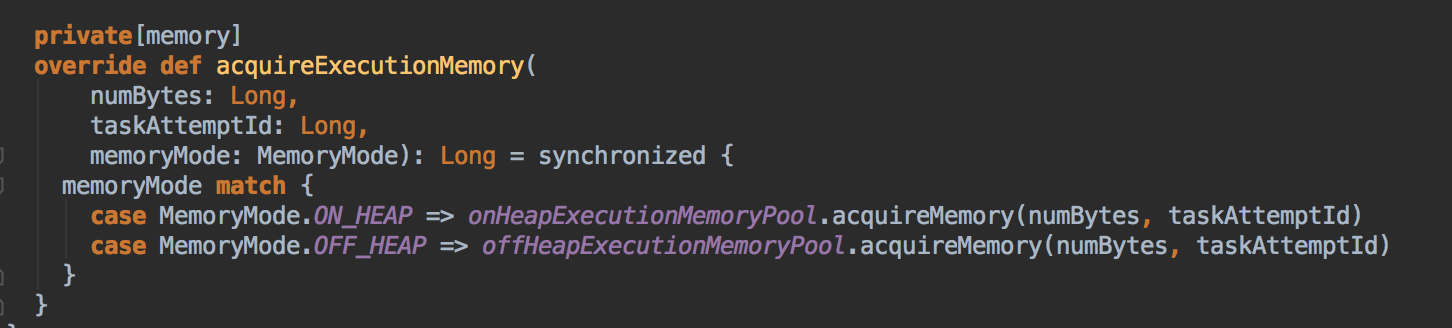
- acquireExecutionMemory
[下图是 StaticMemoryManager.scala 中 acquireExecutionMemory 方法]![]()
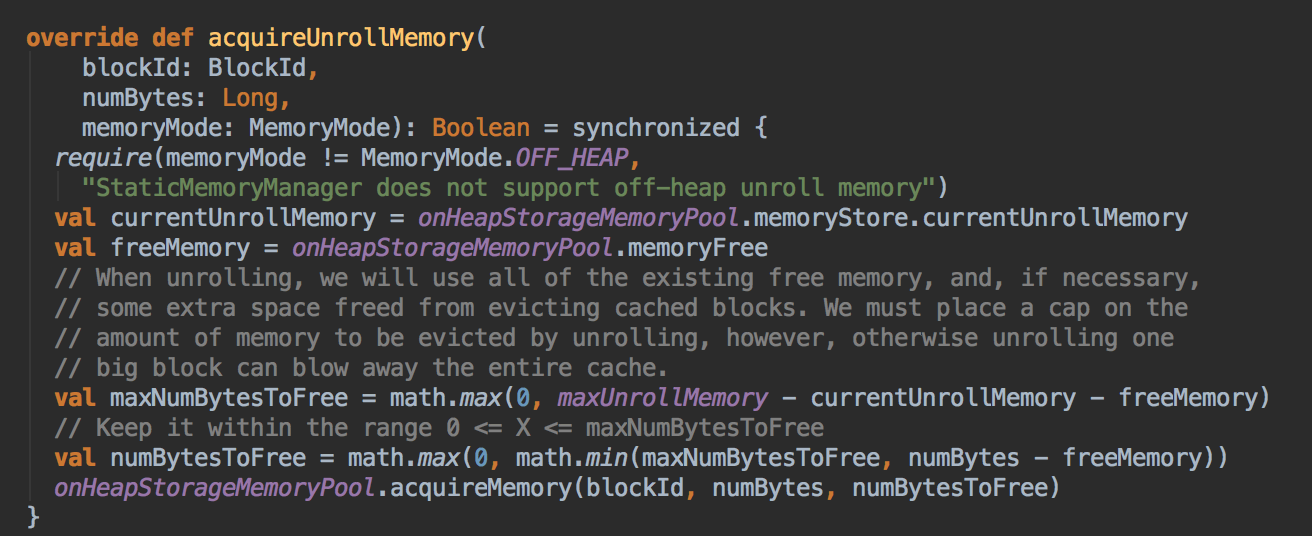
- acquireUnrollMemory
[下图是 StaticMemoryManager.scala 中 acquireUnrollMemory 方法]![]()


Unified MemoryManager 的源码鉴赏
- UnifiedMemoryManager 构造时调用工厂方法 apply( ),默认是把 Storage空间的50%给 Execution
[下图是 UnifiedMemoryManager.scala 中 UnifiedMemoryManager 构造参数]![]()
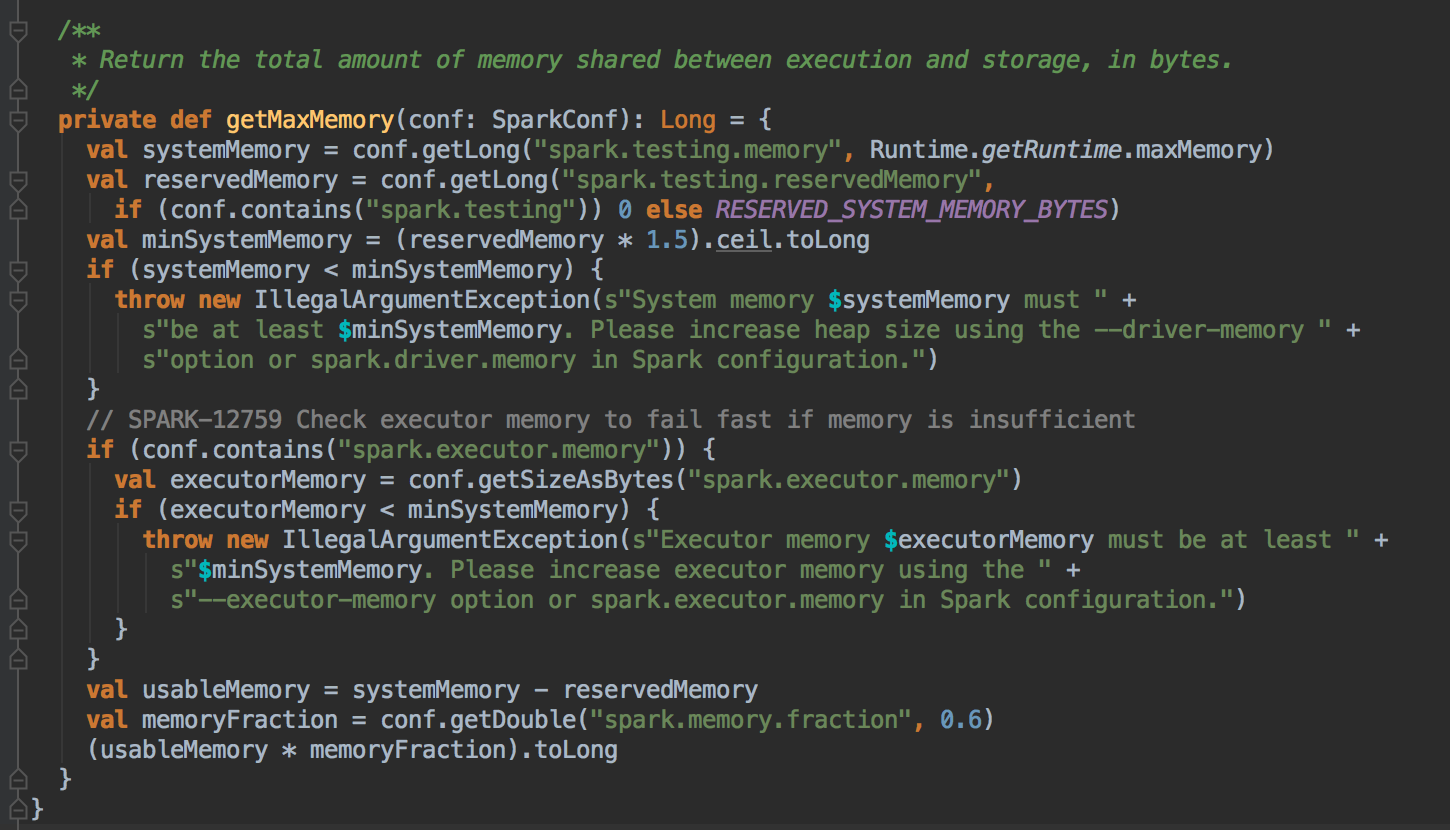
你可以很清楚的看见:默认的 Reserved System Memory 是 300M,然后默认的 HeapStorageRegionSize 是 MaxMemory x 50%,如果实现了 OffHeapExecutionMemoryPool 你觉得会不会有从 StorageMemory 获得储存这个概念? 实际上不需要找 Storage 借空间。如果是 ShuffleTask 计算比较复杂的情况,使用 Unified Memory Management 会取得更好的效率,但是如果说计算的业务逻辑需要更大的缓存空间,此时使用 StaticMemoryManagement 效果会更好。
[下图是 UnifiedMemoryManager.scala 中 UnifiedMemoryManager 伴生对象里的 RESERVED_SYSTEM_MEMORY_BYTES 参数和 apply 方法]![]()
[下图是 UnifiedMemoryManager.scala 中 UnifiedMemoryManager 伴生对象里的 getMaxMemory 方法]![]()
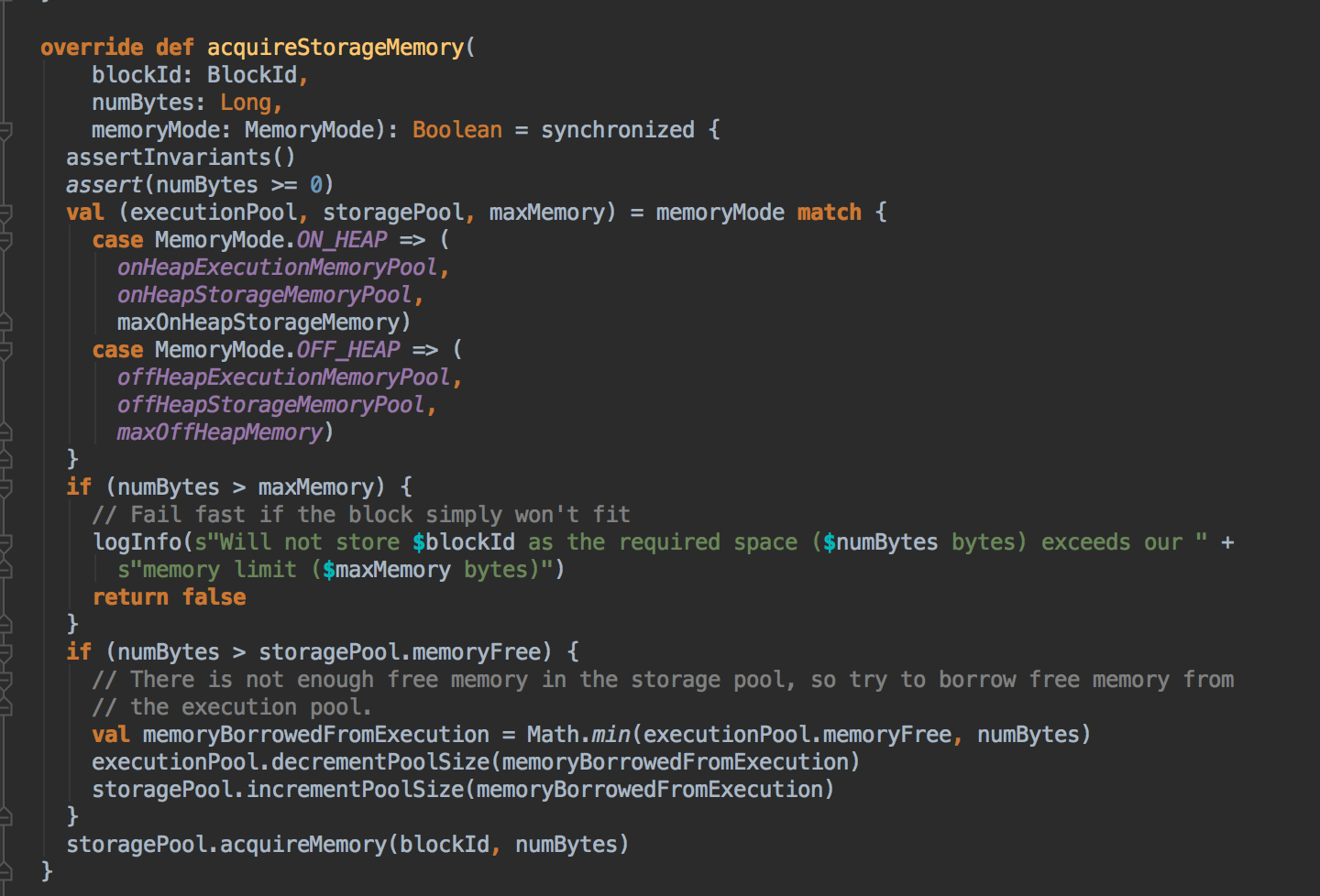
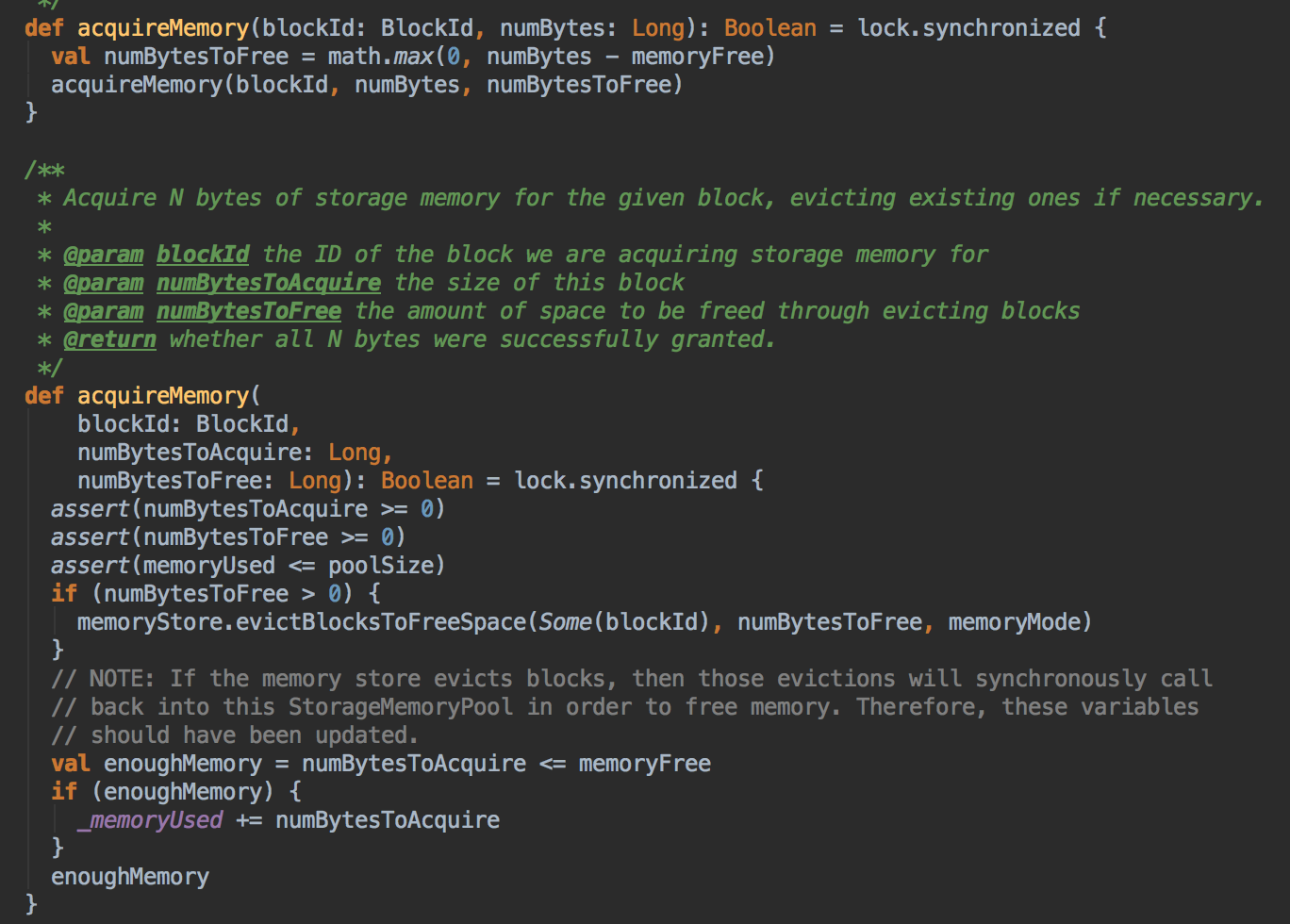
- 上一章讨论过在 Unified 机制下有两种方法 Execution 会向 Storage 借空间,现在配合源码来证明这个说法。Unified Memory Manager 有两个核心方法,第一个是 acquiredExecutionMemeory 和 acquireStorageMemory,当 ExecutionMemory 有剩馀空间时可以借给 StorageMemory,然后通过调用 StorageMemoryPool 的 acquireMemory 方法向 storageMemoryPool 申请空间。
[下图是 UnifiedMemoryManager.scala 中 acquireStorageMemory 方法]![]()
[下图是 ExecutionMemoryPool.scala 中 acquireMemory 方法]![]()
- acquiredExecutionMemory 主要是为当前的执行任务去获得的执行空间,它首先会根据我们的 onHeap 和 offHeap 这两种不同的方式来进行配。
[下图是 UnifiedMemoryManager.scala 中 acquireExecutionMemory 方法]![]()
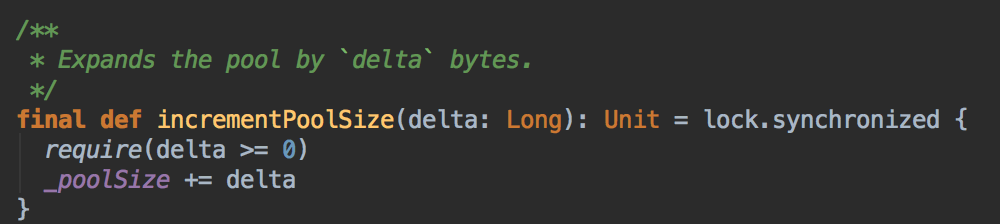
- 在MemoryManager 构造的时候也分配一定的内存空间 poolSize
[下图是 MemoryManager.scala 中调用了 incremenPoolSize 方法]![]()
[下图是 MemoryPool.scala 中 incremenPoolSize 方法]![]()
- 调用 computeMaxExecutionPoolSize 方法向 ExecutionPool 申请资源。过程中会调用 maybeGrowExecutionPool来判断需要多少内存,包括计算内存空间的空闲资源与Storage曾经占用的空间。
[下图是 UnifiedMemoryManager.scala 中 computeMaxExecutionPoolSize 方法]![]()
maybeGrowExecutionPool 方法会首先判断申请的内存申请资源是大于0,然后判断是剩馀空间和 Storage曾经占用的空间多,把需要的内存资源量提交给 StorageMemoryPool 的 freeSpaceToShrinkPool 方法。
[下图是 UnifiedMemoryManager.scala 中 maybeGrowExecutionPool 方法]![]()
然后会判断是当前 FreeSpace 能不能满足 Execution 的需要,如果无法满足则调用 MemoryStore的evictVlocksToFreeSpace方法在 StorageMemoryPool 中挤掉一部份数据。
[下图是 StorageMemoryPool.scala 中 freeSpaceToShrinkPool 方法]![]()
- 调用 ExecutionPool 的 acquireMemory 方法向 ExecutionPool 申请内存资源,每个 Task 理论上讲一般能使用的大小是从 poolSize /(2 x numActiveTasks) 到 maxPoolSize/numActiveTasks
[下图是 ExecutionMemoryPool.scala 中 acquireMemory 方法]![]()
![]()








參考資料
资料来源来至 DT大数据梦工厂 大数据商业案例以及性能调优
第31课:彻底解密Spark 2.1.X中Shuffle中内存管理源码解密:StaticMemory和UnifiedMemory
Spark源码图片取自于 Spark 2.1.0版本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号