

VB.NET提取TXT文档指定内容
今天有浏览论坛时,又看见一篇是读取TXT文本文件的论题。Insus.NET也想以自己的想法来实现,并分享于此。
文本文件是比较复杂,获取数据也是一些文本行中取其中一部分。为了能够取到较精准的数据,Insus.NET分写几步来实现。每一步使用一个类。毕竟现在我们写的程序是面向对象嘛。首先在站点下面创建文本文件:


================================================== Sat Feb 12, 16:45 CST-0800 2011 (OK) -------------------------------------------------- CELLPAG: 'D51179C' Number Value Name 1 32 PAGPCHCONG 2 524 PAGETOOOLD -------------------------------------------------- Sat Feb 12, 16:45 CST-0800 2011 (OK) -------------------------------------------------- CELLPAG: 'D5143A' Number Value Name 1 64 PAGPCHCONG 2 537 PAGETOOOLD -------------------------------------------------- Sat Feb 12, 16:45 CST-0800 2011 (OK) -------------------------------------------------- CELLPAG: '516A' Number Value Name 1 75 PAGPCHCONG 2 3677 PAGETOOOLD --------------------------------------------------
如下图:
要汲取的数据应该是高亮部分的数据。下面先写一个类SourceDataList:
这个类,处理粗糙的数据,去除每行文本行的头尾空格,去除每行文本行中有连续几个空格的,仅保留一个。然后对文本行进行以空格为分隔,只要分段为二段或三段的文本行。
再进一步,写另外一个类DataParse,根据类名,就大约知道这是对初次获取的数据时行分析。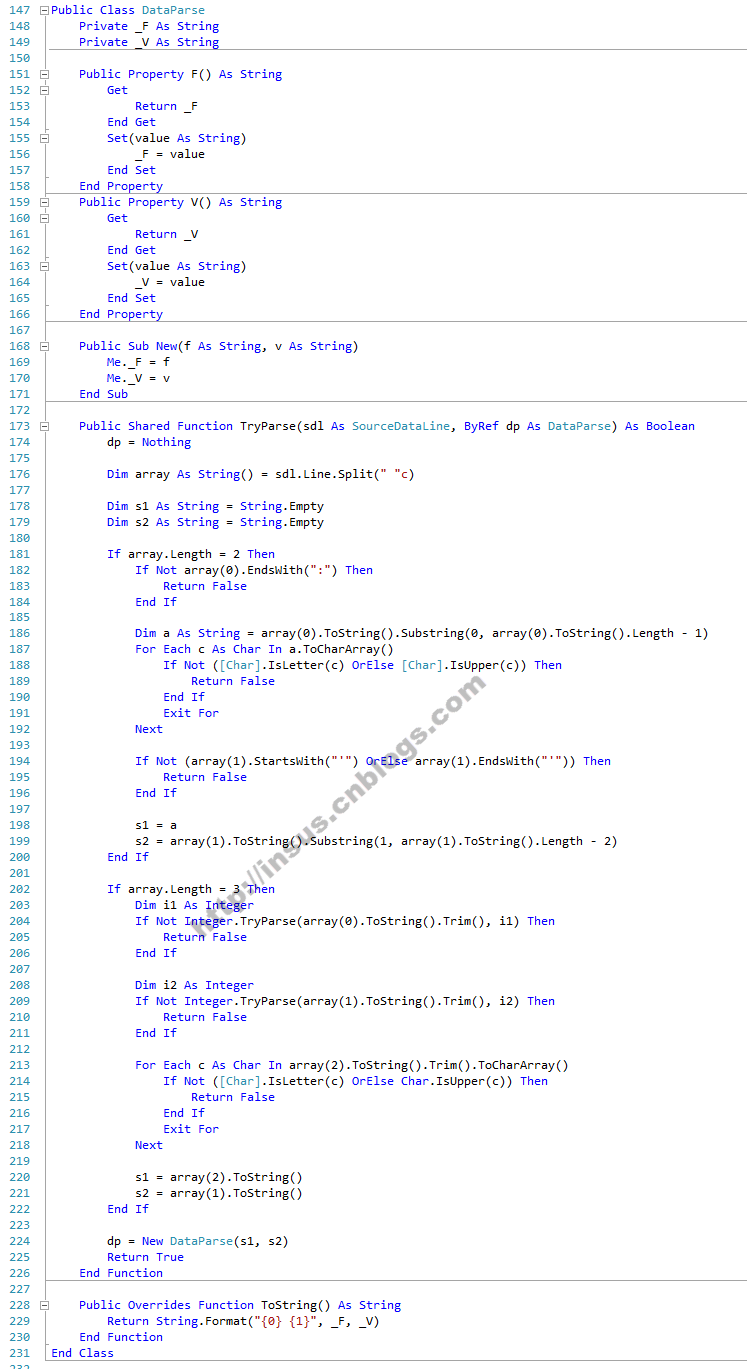
这个类,能取到基本上定型的数据。对转入的文本行进分割(空格为分隔符),分别以二段三段来判断。
如果是二段的文本行。第一个元素是":"结束的,截除冒号符号之后,还要判断是否全是大写字母。第二个元素,是单引号"'"开始和结束的。只要全符合这些条件,就是我们需要文件行。
如果是三段文本行,第一,第二个元素均是整型,而第三个元素,应该是全大写字母。符合条件的文本行,就是需要获取的文本行。
接下来,我们再写一个类别,是对上面获取的数据进行组合,DataStructures: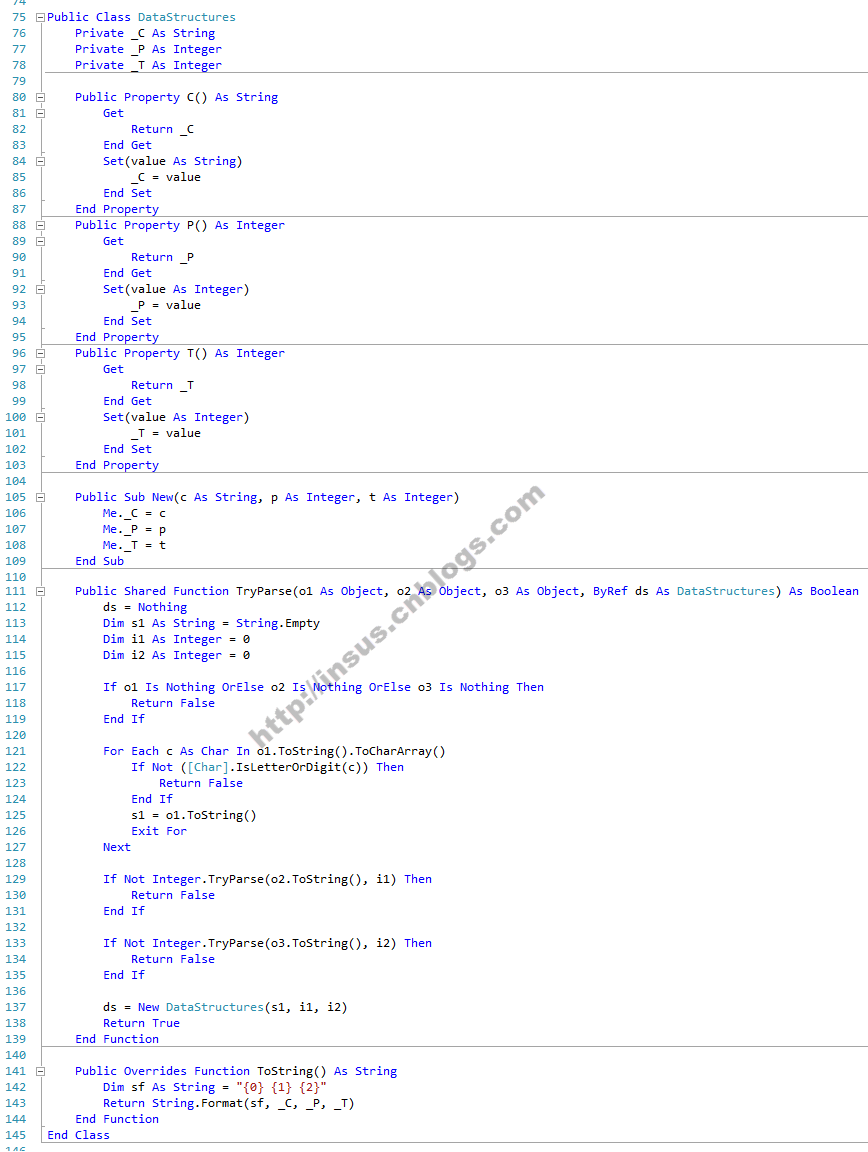
从这个类来处理到的数据,已经接近我们需要数据行了。每行数据有三个字段,一个为字符串,第二和第三字段为整型。
最后一个类DataHelper:
处理文本文件,去获取数据,并收集于List(Of DataStructures)集合中。
OK,现在我们就可以展现获取的数据了,在站点中,创建一个网页.aspx,去Page_Load事件写: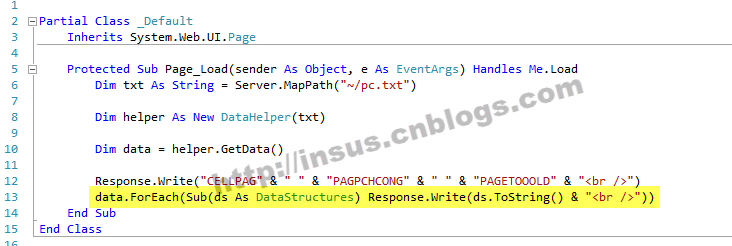
运行网页时,看到效果: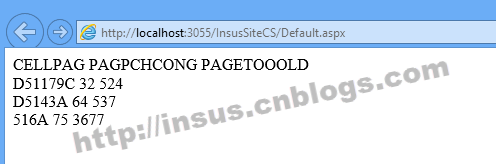

 浙公网安备 33010602011771号
浙公网安备 33010602011771号