

MySQL数据库优化(二)
索引
索引是通过BTREE结构进行数据检索的,以平衡二叉树检索的方式缩短数据查询的时间。
索引类型
- 主键索引(primary),在innodb存储引擎下,由于数据和索引都在ibd文件里存储,所以数据的组织方式是由主键索引的BTREE结构,即聚簇索引,如果表没有主键系统会查找一列唯一数据列当主键,如果还没有唯一数据列,系统则虚拟主键索引。在innodb存储引擎下,其他索引都引用主键索引的地址,即非聚簇索引。
-
mysql> create table t1(id int primary key); #或 mysql> alter table t2 add primary key(id);
- 普通索引(normal)
mysql> create index idx_name on t1(name);
- 唯一索引(unique)
mysql> create table t1(id int unique);
- 全文索引(full)
由于MySQL默认的全文索引对中文的支持不好,所以通常使用别他工具来实现,比如:sphinx 或 coreseek
查询索引
mysql> show keys from table_name; mysql> show index from table_name;
删除索引
mysql> alter table table_name drop index index_name
索引的优点和缺点
- 优点
- 提高检索速度,降低磁盘读取I/O
- 索引是排序好的,降低数据排序运算的成本,也就降低了CPU的消耗
- 缺点
- 索引也需要存储,所以也需要空间
- 降低更新表的速度,更新不仅仅只是数据本身,如果有索引也需要更新索引信息
Explain
语法
EXPLAIN SELECT ...
作用
- 描述MySQL如何执行查询操作、执行顺序、使用到的索引和MySQL成功返回结果集需要执行的行数等信息。
- 可以帮我们分析SELECT语句,让我们知道查询效率低下的原因,从而改进我们的查询,让查询优化器能够更好的工作。
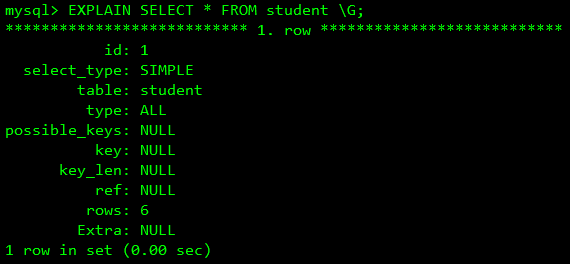
- id:标识符,表示执行顺序
- select_type:查询类型
- table:查询的表
- partitions:使用的哪个分区,需要结合表分区才能看到,MySQL 5.7版本之前需要在EXPLAIN 和 SELECT 之间加 PARTITIONS 才能看见
- type:连接的类型
- possible_keys:可能使用到的索引,保存索引名称,如果多个则用逗号分隔
- ken_len:使用到的索引长度
- ref:引用索引对应表中哪些行
- rows:显示MySQL认为执行查询时必须要返回的行数
- filtered:通过过滤条件之后对比总数的百分比,MySQL 5.7+才有该属性
- Extra:额外信息
id
当多行id值都一致时,则顺序执行SQL

上图中先执行teacher表,再执行course表,最后执行student表。
当多行id不一致时,则按从大到小执行

上图中先执行teacher表,再执行course表,最后执行score表。
当多行id部分一致时,则先按从大到小,一致的id顺序执行
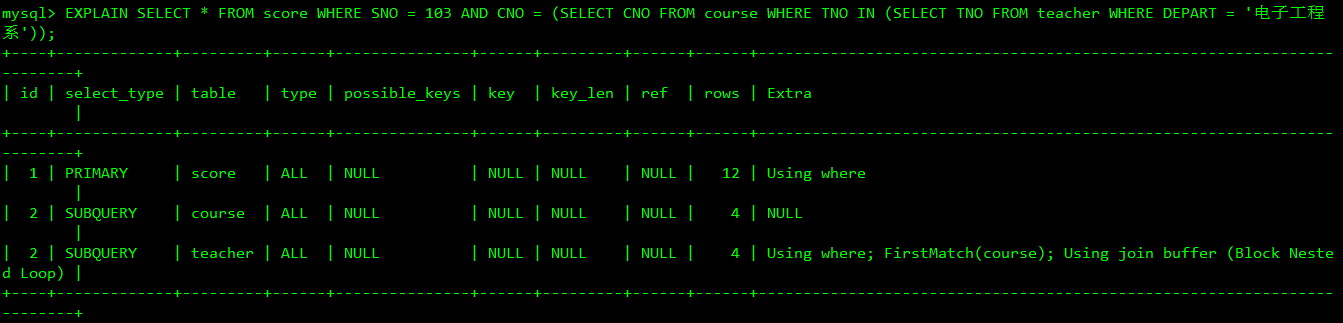
上图中先执行course表,再执行teacher表,最后执行score表。
select_type
SIMPLE:简单的查询

PRIMARY:主查询,或者说是最外层查询
SUBQUERY:子查询

UNION:UNION中第二个或者后面那个SELECT查询
UNION RESULT:UNION之后的结果

DEPENDENT UNION:UNION中第二个或者后面的SELECT
DEPENDENT SUBQUERY:子查询中第一个SELECT

DERIVED:衍生表,只有在MySQL 5.5x 和 5.6x里面有这个类型

table
所使用的表
partitions
使用到的表分区,只有在创建表分区之后才有效
type
表示按照某种类型来查询
const:表示表中最多有一个匹配行

eq_ref:对于每个来自于前面表的记录,所有匹配的行从这张表中取出

ref:对于每个来自于前面表的记录,所有匹配的行从这张表中取出,后张表id是唯一索引,于前表id一致

ref_or_null:类似于ref,但是可以搜索包含null值得行,address建立索引

index_merge:出现在使用一张表中的多个索引时,如果数据量太小,优化器判断全表扫描更快就不会使用index_merge
rang:按指定范围来检索

index:从索引数中查找

ALL:全表扫描

possible_key,key
表示可能用到的索引和用到的索引
key_len
表示索引长度,长度根据一套算法得来
key_len的长度计算公式:
varchr(10)变长字段且允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段)
varchr(10)变长字段且不允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)+2(变长字段)
char(10)固定字段且允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)+1(NULL)
char(10)固定字段且不允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)
int类型且允许NULL : 4+1(NULL)
int类型且不允许NULL : 4
详细可参考该文
ref
表示引用
rows
表示扫描的行数,值越小越好,说明扫描的范围小
Extra
using where:表示用到where

using index:表示用到索引

using join buffer:表示使用了连接缓存

using filesort:表示使用了文件内存排序,必须优化,严重影响性能

using temporary:表示使用了中间表或者临时表


 浙公网安备 33010602011771号
浙公网安备 33010602011771号