
数据库优化实践【索引篇】
你和你的团队经过不懈努力,终于使网站成功上线,刚开始时,注册用户较少,网站性能表现不错,但随着注册用户的增多,访问速度开始变慢,一些用户开始发来邮件表示抗议,事情变得越来越糟,为了留住用户,你开始着手调查访问变慢的原因。
经过紧张的调查,你发现问题出在数据库上,当应用程序尝试访问/更新数据时,数据库执行得相当慢,再次深入调查数据库后,你发现数据库表增长得很大,有些表甚至有上千万行数据,测试团队开始在生产数据库上测试,发现订单提交过程需要花5分钟时间,但在网站上线前的测试中,提交一次订单只需要2/3秒。
类似这种故事在世界各个角落每天都会上演,几乎每个开发人员在其开发生涯中都会遇到这种事情,我也曾多次遇到这种情况,因此我希望将我解决这种问题的经验和大家分享。
如果你正身处这种项目,逃避不是办法,只有勇敢地去面对现实。首先,我认为你的应用程序中一定没有写数据访问程序,我将在这个系列的文章中介绍如何编写最佳的数据访问程序,以及如何优化现有的数据访问程序。
范围
在正式开始之前,有必要澄清一下本系列文章的写作边界,我想谈的是“事务性(OLTP)SQL Server数据库中的数据访问性能优化”,但文中介绍的这些技巧也可以用于其它数据库平台。
同时,我介绍的这些技巧主要是面向程序开发人员的,虽然DBA也是优化数据库的一支主要力量,但DBA使用的优化方法不在我的讨论范围之内。
当一个基于数据库的应用程序运行起来很慢时,90%的可能都是由于数据访问程序的问题,要么是没有优化,要么是没有按最佳方法编写代码,因此你需要审查和优化你的数据访问/处理程序。
我将会谈到10个步骤来优化数据访问程序,先从最基本的索引说起吧!
第一步:应用正确的索引
我之所以先从索引谈起是因为采用正确的索引会使生产系统的性能得到质的提升,另一个原因是创建或修改索引是在数据库上进行的,不会涉及到修改程序,并可以立即见到成效。
我们还是温习一下索引的基础知识吧,我相信你已经知道什么是索引了,但我见到很多人都还不是很明白,我先给大家将一个故事吧。
很久以前,在一个古城的的大图书馆中珍藏有成千上万本书籍,但书架上的书没有按任何顺序摆放,因此每当有人询问某本书时,图书管理员只有挨个寻找,每一次都要花费大量的时间。
[这就好比数据表没有主键一样,搜索表中的数据时,数据库引擎必须进行全表扫描,效率极其低下。]
更糟的是图书馆的图书越来越多,图书管理员的工作变得异常痛苦,有一天来了一个聪明的小伙子,他看到图书管理员的痛苦工作后,想出了一个办法,他建议将每本书都编上号,然后按编号放到书架上,如果有人指定了图书编号,那么图书管理员很快就可以找到它的位置了。
[给图书编号就象给表创建主键一样,创建主键时,会创建聚集索引树,表中的所有行会在文件系统上根据主键值进行物理排序,当查询表中任一行时,数据库首先使用聚集索引树找到对应的数据页(就象首先找到书架一样),然后在数据页中根据主键键值找到目标行(就象找到书架上的书一样)。]
于是图书管理员开始给图书编号,然后根据编号将书放到书架上,为此他花了整整一天时间,但最后经过测试,他发现找书的效率大大提高了。
[在一个表上只能创建一个聚集索引,就象书只能按一种规则摆放一样。]
但问题并未完全解决,因为很多人记不住书的编号,只记得书的名字,图书管理员无赖又只有扫描所有的图书编号挨个寻找,但这次他只花了20分钟,以前未给图书编号时要花2-3小时,但与根据图书编号查找图书相比,时间还是太长了,因此他向那个聪明的小伙子求助。
[这就好像你给Product表增加了主键ProductID,但除此之外没有建立其它索引,当使用Product Name进行检索时,数据库引擎又只要进行全表扫描,逐个寻找了。]
聪明的小伙告诉图书管理员,之前已经创建好了图书编号,现在只需要再创建一个索引或目录,将图书名称和对应的编号一起存储起来,但这一次是按图书名称进行排序,如果有人想找“Database Management System”一书,你只需要跳到“D”开头的目录,然后按照编号就可以找到图书了。
于是图书管理员兴奋地花了几个小时创建了一个“图书名称”目录,经过测试,现在找一本书的时间缩短到1分钟了(其中30秒用于从“图书名称”目录中查找编号,另外根据编号查找图书用了30秒)。
图书管理员开始了新的思考,读者可能还会根据图书的其它属性来找书,如作者,于是他用同样的办法为作者也创建了目录,现在可以根据图书编号,书名和作者在1分钟内查找任何图书了,图书管理员的工作变得轻松了,故事也到此结束。
到此,我相信你已经完全理解了索引的真正含义。假设我们有一个Products表,创建了一个聚集索引(根据表的主键自动创建的),我们还需要在ProductName列上创建一个非聚集索引,创建非聚集索引时,数据库引擎会为非聚集索引自动创建一个索引树(就象故事中的“图书名称”目录一样),产品名称会存储在索引页中,每个索引页包括一定范围的产品名称和它们对应的主键键值,当使用产品名称进行检索时,数据库引擎首先会根据产品名称查找非聚集索引树查出主键键值,然后使用主键键值查找聚集索引树找到最终的产品。
下图显示了一个索引树的结构
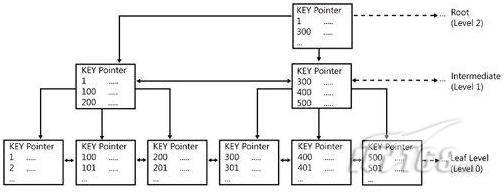
图 1 索引树结构
它叫做B+树(或平衡树),中间节点包含值的范围,指引SQL引擎应该在哪里去查找特定的索引值,叶子节点包含真正的索引值,如果这是一个聚集索引树,叶子节点就是物理数据页,如果这是一个非聚集索引树,叶子节点包含索引值和聚集索引键(数据库引擎使用它在聚集索引树中查找对应的行)。
通常,在索引树中查找目标值,然后跳到真实的行,这个过程是花不了什么时间的,因此索引一般会提高数据检索速度。下面的步骤将有助于你正确应用索引。
确保每个表都有主键
这样可以确保每个表都有聚集索引(表在磁盘上的物理存储是按照主键顺序排列的),使用主键检索表中的数据,或在主键字段上进行排序,或在where子句中指定任意范围的主键键值时,其速度都是非常快的。
在下面这些列上创建非聚集索引:
1)搜索时经常使用到的;
2)用于连接其它表的;
3)用于外键字段的;
4)高选中性的;
5)ORDER BY子句使用到的;
6)XML类型。
下面是一个创建索引的例子:
NCLIX_OrderDetails_ProductID ON
dbo.OrderDetails(ProductID)
也可以使用SQL Server管理工作台在表上创建索引,如图2所示。
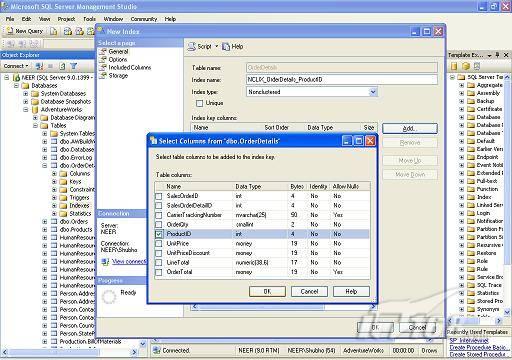
图 2 使用SQL Server管理工作台创建索引
第二步:创建适当的覆盖索引
假设你在Sales表(SelesID,SalesDate,SalesPersonID,ProductID,Qty)的外键列(ProductID)上创建了一个索引,假设ProductID列是一个高选中性列,那么任何在where子句中使用索引列(ProductID)的select查询都会更快,如果在外键上没有创建索引,将会发生全部扫描,但还有办法可以进一步提升查询性能。
假设Sales表有10,000行记录,下面的SQL语句选中400行(总行数的4%):
我们来看看这条SQL语句在SQL执行引擎中是如何执行的:
1)Sales表在ProductID列上有一个非聚集索引,因此它查找非聚集索引树找出ProductID=112的记录;
2)包含ProductID = 112记录的索引页也包括所有的聚集索引键(所有的主键键值,即SalesID);
3)针对每一个主键(这里是400),SQL Server引擎查找聚集索引树找出真实的行在对应页面中的位置;
SQL Server引擎从对应的行查找SalesDate和SalesPersonID列的值。
在上面的步骤中,对ProductID = 112的每个主键记录(这里是400),SQL Server引擎要搜索400次聚集索引树以检索查询中指定的其它列(SalesDate,SalesPersonID)。
如果非聚集索引页中包括了聚集索引键和其它两列(SalesDate,,SalesPersonID)的值,SQL Server引擎可能不会执行上面的第3和4步,直接从非聚集索引树查找ProductID列速度还会快一些,直接从索引页读取这三列的数值。
幸运的是,有一种方法实现了这个功能,它被称为“覆盖索引”,在表列上创建覆盖索引时,需要指定哪些额外的列值需要和聚集索引键值(主键)一起存储在索引页中。下面是在Sales 表ProductID列上创建覆盖索引的例子:
ON dbo.Sales(ProductID)--Column on which index is to be created
INCLUDE(SalesDate, SalesPersonID)--Additional column values to include
应该在那些select查询中常使用到的列上创建覆盖索引,但覆盖索引中包括过多的列也不行,因为覆盖索引列的值是存储在内存中的,这样会消耗过多内存,引发性能下降。
创建覆盖索引时使用数据库调整顾问
我们知道,当SQL出问题时,SQL Server引擎中的优化器根据下列因素自动生成不同的查询计划:
1)数据量
2)统计数据
3)索引变化
4)TSQL中的参数值
5)服务器负载
这就意味着,对于特定的SQL,即使表和索引结构是一样的,但在生产服务器和在测试服务器上产生的执行计划可能会不一样,这也意味着在测试服务器上创建的索引可以提高应用程序的性能,但在生产服务器上创建同样的索引却未必会提高应用程序的性能。因为测试环境中的执行计划利用了新创建的索引,但在生产环境中执行计划可能不会利用新创建的索引(例如,一个非聚集索引列在生产环境中不是一个高选中性列,但在测试环境中可能就不一样)。
因此我们在创建索引时,要知道执行计划是否会真正利用它,但我们怎么才能知道呢?答案就是在测试服务器上模拟生产环境负载,然后创建合适的索引并进行测试,如果这样测试发现索引可以提高性能,那么它在生产环境也就更可能提高应用程序的性能了。
虽然要模拟一个真实的负载比较困难,但目前已经有很多工具可以帮助我们。
使用SQL profiler跟踪生产服务器,尽管不建议在生产环境中使用SQL profiler,但有时没有办法,要诊断性能问题关键所在,必须得用,在http://msdn.microsoft.com/en-us/library/ms181091.aspx有SQL profiler的使用方法。
使用SQL profiler创建的跟踪文件,在测试服务器上利用数据库调整顾问创建一个类似的负载,大多数时候,调整顾问会给出一些可以立即使用的索引建议,在http://msdn.microsoft.com/en-us/library/ms166575.aspx有调整顾问的详细介绍。
第三步:整理索引碎片
你可能已经创建好了索引,并且所有索引都在工作,但性能却仍然不好,那很可能是产生了索引碎片,你需要进行索引碎片整理。
什么是索引碎片?
由于表上有过度地插入、修改和删除操作,索引页被分成多块就形成了索引碎片,如果索引碎片严重,那扫描索引的时间就会变长,甚至导致索引不可用,因此数据检索操作就慢下来了。
有两种类型的索引碎片:内部碎片和外部碎片。
内部碎片:为了有效的利用内存,使内存产生更少的碎片,要对内存分页,内存以页为单位来使用,最后一页往往装不满,于是形成了内部碎片。
外部碎片:为了共享要分段,在段的换入换出时形成外部碎片,比如5K的段换出后,有一个4k的段进来放到原来5k的地方,于是形成1k的外部碎片。
如何知道是否发生了索引碎片?
执行下面的SQL语句就知道了(下面的语句可以在SQL Server 2005及后续版本中运行,用你的数据库名替换掉这里的AdventureWorks):
IndexName,dt.avg_fragmentation_in_percent AS
ExternalFragmentation,dt.avg_page_space_used_in_percent AS
InternalFragmentation
FROM
(
SELECT object_id,index_id,avg_fragmentation_in_percent,avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats (db_id('AdventureWorks'),null,null,null,'DETAILED'
)
WHERE index_id <> 0) AS dt INNER JOIN sys.indexes si ON si.object_id=dt.object_id
AND si.index_id=dt.index_id AND dt.avg_fragmentation_in_percent>10
AND dt.avg_page_space_used_in_percent<75 ORDER BY avg_fragmentation_in_percent DESC
执行后显示AdventureWorks数据库的索引碎片信息。

图 3 索引碎片信息
使用下面的规则分析结果,你就可以找出哪里发生了索引碎片:
1)ExternalFragmentation的值>10表示对应的索引发生了外部碎片;
2)InternalFragmentation的值<75表示对应的索引发生了内部碎片。
如何整理索引碎片?
有两种整理索引碎片的方法:
1)重组有碎片的索引:执行下面的命令
ALTER INDEX ALL ON TableName REORGANIZE
2)重建索引:执行下面的命令
ALTER INDEX ALL ON TableName REBUILD WITH (FILLFACTOR=90,ONLINE=ON)
也可以使用索引名代替这里的“ALL”关键字重组或重建单个索引,也可以使用SQL Server管理工作台进行索引碎片的整理。
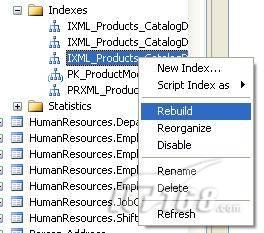
图 4 使用SQL Server管理工作台整理索引碎片
什么时候用重组,什么时候用重建呢?
当对应索引的外部碎片值介于10-15之间,内部碎片值介于60-75之间时使用重组,其它情况就应该使用重建。
值得注意的是重建索引时,索引对应的表会被锁定,但重组不会锁表,因此在生产系统中,对大表重建索引要慎重,因为在大表上创建索引可能会花几个小时,幸运的是,从SQL Server 2005开始,微软提出了一个解决办法,在重建索引时,将ONLINE选项设置为ON,这样可以保证重建索引时表仍然可以正常使用。
虽然索引可以提高查询速度,但如果你的数据库是一个事务型数据库,大多数时候都是更新操作,更新数据也就意味着要更新索引,这个时候就要兼顾查询和更新操作了,因为在OLTP数据库表上创建过多的索引会降低整体数据库性能。
我给大家一个建议:如果你的数据库是事务型的,平均每个表上不能超过5个索引,如果你的数据库是数据仓库型,平均每个表可以创建10个索引都没问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号