
这是我在训练神经网络时用到的基本方法
初始模型训练完成后,我们首先要知道算法的偏差高不高。如果偏差较高,试着评估训练集或者训练数据的性能,如果偏差确实很高,甚至无法拟合训练集,那么你要做的就是选择一个新的更大的网络,比如含有更多隐藏层或者隐藏单元的网络,或者花费更多时间来训练网络(整个方法可能有用,也可能没用)。不断的尝试各种方法,直到可以拟合数据为止,至少可以拟合训练集。如果网络足够大,通常可以很好的拟合训练集,只要你能扩大网络规模,
一旦偏差降低到可以接受的数值,检查方差有没有问题。为了评估方差,我们要查看验证集性能。我们能从一个性能理想的训练集推断出验证集性能也理想吗?如果方差高,最好的解决方法就是采用更多的数据;但是有时候无法获得更多数据,我们也可以尝试通过正则化来减少过拟合;有时候我们不得不反复尝试,但是如果能找到更合适的神经网络框架,有时候合适的网络会使偏差和方差都变得比较小。
不断尝试,直到找到一个低偏差、低方差的框架

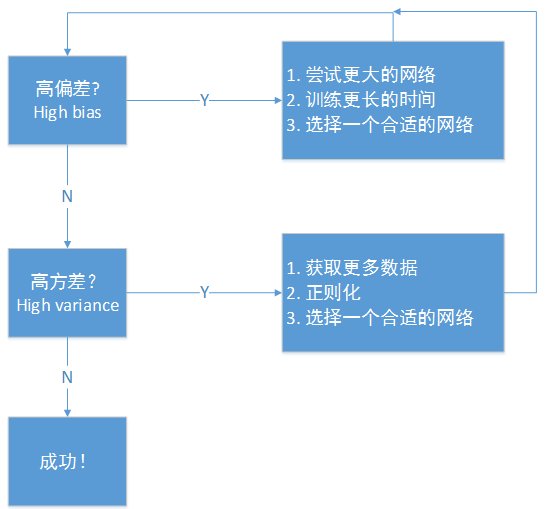
有两点需要注意。第一点是,高偏差和高方差是两种不同的情况,我们后续尝试的方法也可能完全不同。我通常会用训练/验证集来诊断算法是否存在偏差或者方差问题,然后根据结果选择尝试部分方法。举个例子,如果算法存在高偏差问题,准备更多数据其实没什么用,至少这不是最有效的方法。第二点,在机器学习的初期阶段,关于所谓的偏差方差权衡(bias variance tradeoff)的探讨非常多,原因是,我们能尝试的方法有很多,可以增加偏差,减少方差;也可以减少偏差,增加方差。但是在深度学习的早期阶段,我们没有太多工具可以做到只减少偏差或方差,却不影响到另一方。但是在当前深度学习和大数据时代,只要持续训练一个更大的网络,只要准备更多数据,那么也并非只有这两种情况。我们这样假设,只要正则适度,通常构建一个更大的网络便可以在不影响方差的同时,减少偏差;而采用更多数据通常可以在不过多影响偏差的同时,减少方差。这两步实际要做的工作是训练网络,选择网络或者准备更多的数据,现在我们有工具可以做到在减少偏差或者方差的同时,不对另一方产生过多不良影响。
最终,我们会得到一个非常规范化的网络,训练一个更大的网络几乎没有任何负面影响,而训练一个大型神经网络的主要代价也只是计算时间,前提是网络比较规范化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号