

Apache Calcite系列(三):SQL查询优化
前言:前两篇文章介绍了Calcite的整体流程,以及SQL Parser原理,本文重点关注下Calcite的SQL优化。
Apache Calcite系列文章:
Apache Calcite系列(一):整体流程解析
Apache Calcite系列(二):SQL Parser
Apache Calcite系列(三):查询优化
Apache Calcite系列(四):物理计划执行
Apache Calcite系列(五):数据库驱动实现
Apache Calcite系列(六):Kylin查询原理分析
Apache Calcite系列(七):FlinkSQL原理分析
优化基础知识
关系代数
关系数据库基于关系代数。关系数据库的对外接口是SQL语句,所以SQL语句中的DML、DQL基于关系代数实现了关系的运算。
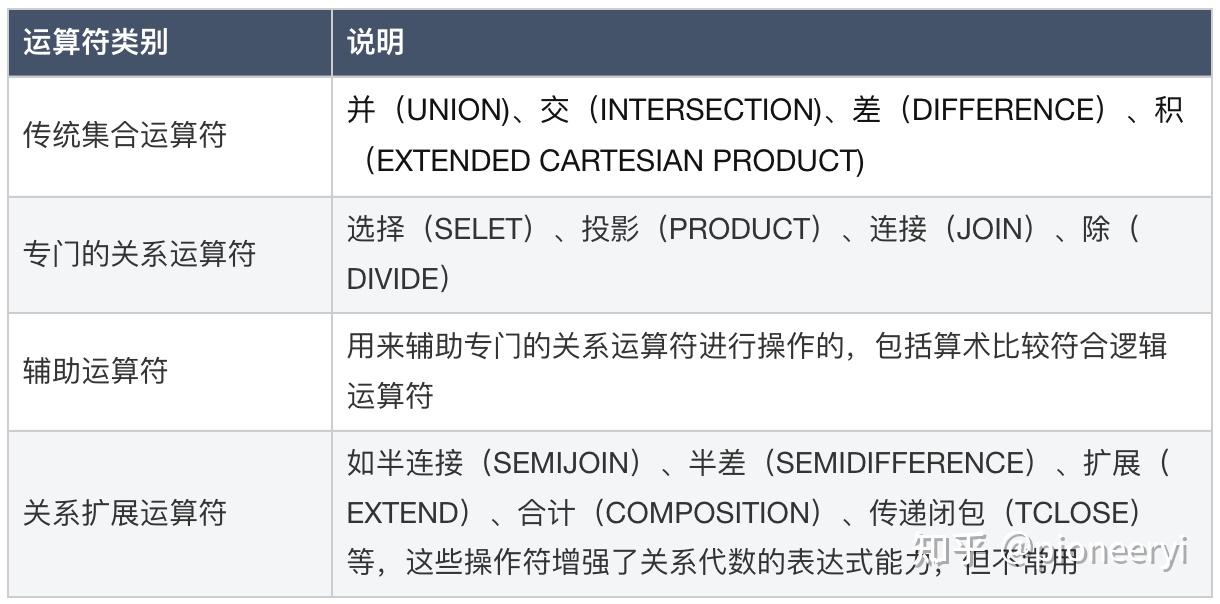
关系代数的运算符类别
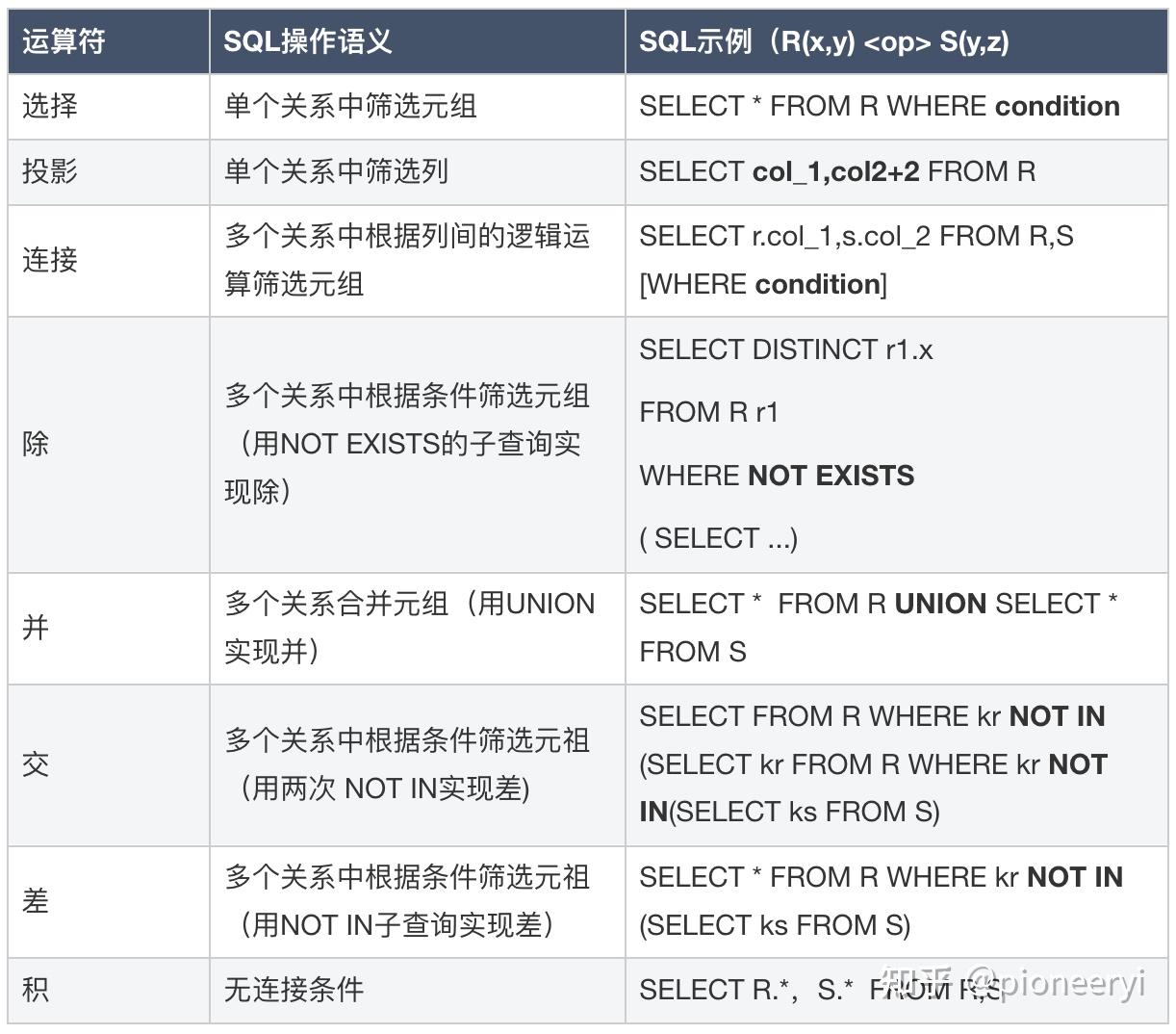
基本关系运算与对应的SQL
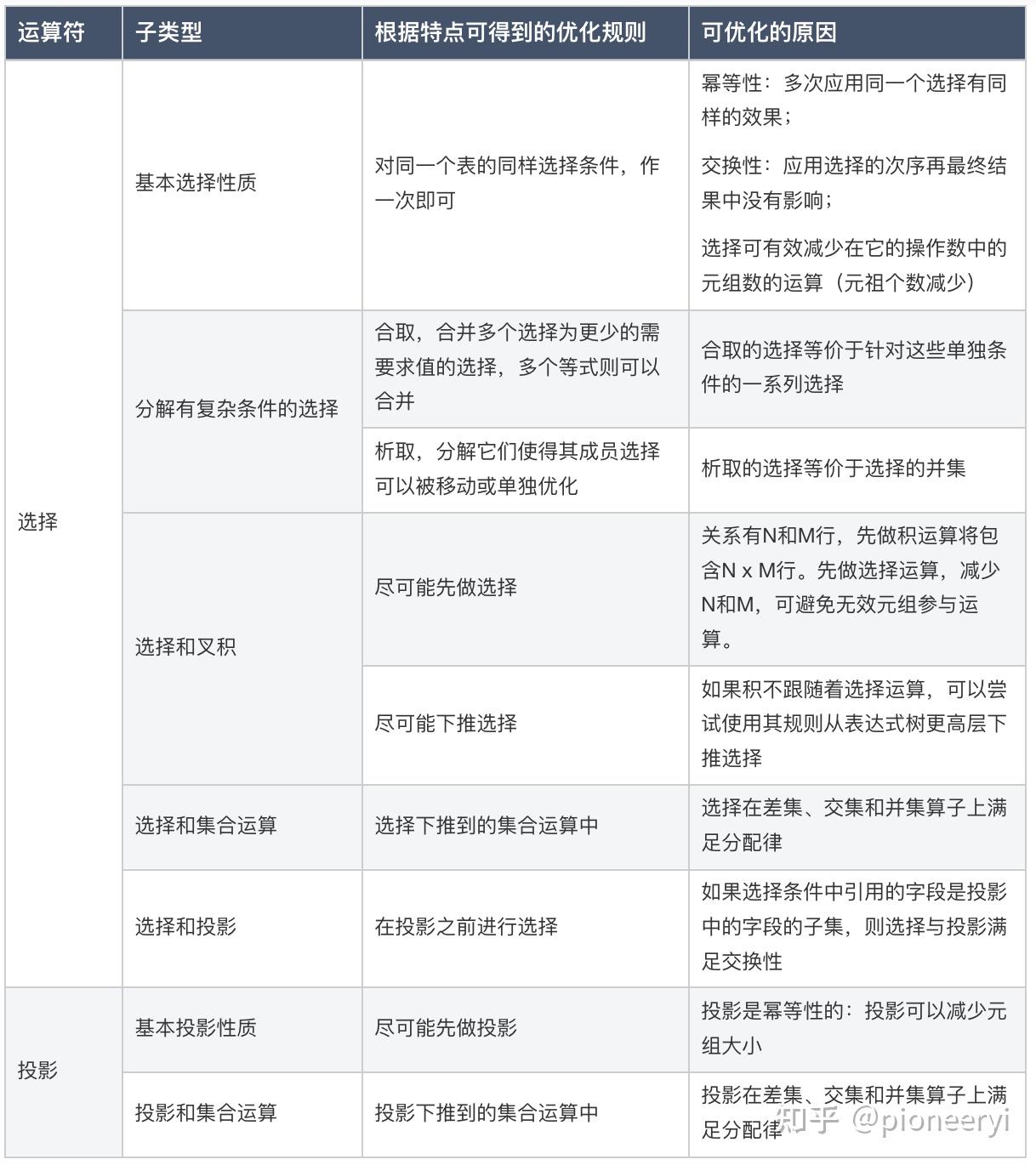
运算符主导的优化
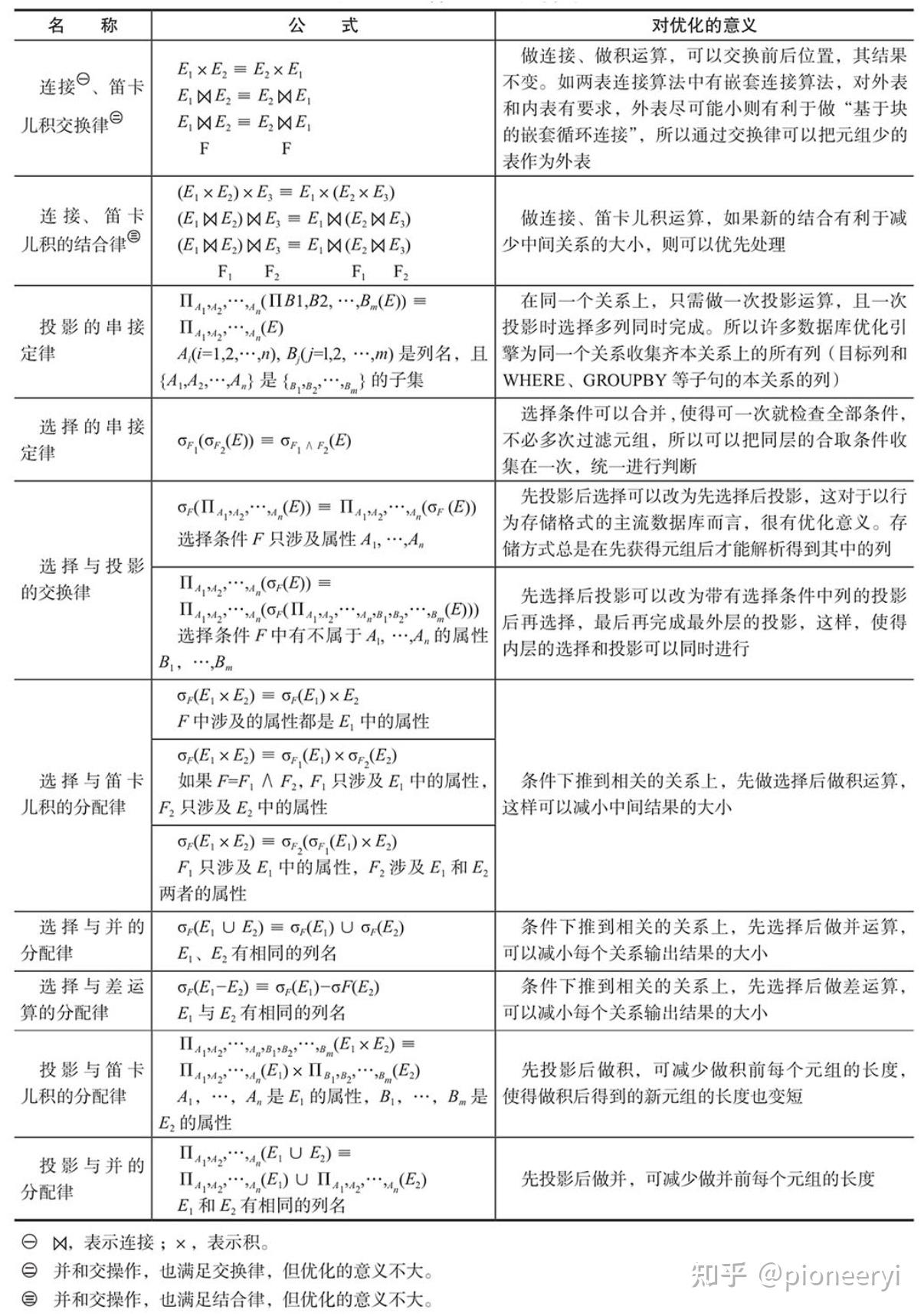
运算规则主导的优化
代价估算模型
查询代价估算基于CPU代价和IO代价,所以代价模型可以用以下计算公式表示:
总代价=IO代价 + CPU代价
选择率在代价估算模型中占有重要地位,其精确程度直接影响最优计划的选取。选择率计算的常用方法如下:
- 无参数方法(Non-Parametric Method)。使用ad hoc数据结构或直方图维护属性值的分布,最常用的是直方图方法。
- 参数法(Parametric Method)。使用具有一些自由统计参数(参数是预先估计出来的)的数学分布函数逼近真实分布。
- 曲线拟合法(Curve Fitting)。为克服参数法的不灵活性,用一般多项式和标准最小方差来逼近属性值的分布。
- 抽样法(sampling)。从数据库中抽取部分样本元组,针对这些样本进行查询,然后收集统计数据,只有足够的样本被测试之后,才能达到预期的精度。
- 综合法。将以上几种方法结合起来,如抽样法和直方图法结合。
查询优化器划分
基于上面的关系代数转换,以及代价评估,一般优化器可以分为两类,分别为:基于规则的优化(RBO)、基于成本优化(CBO)。
基于规则优化(RBO)
基于规则的优化器(Rule-Based Optimizer,RBO):根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会变成另外一个关系表达式,同时原有表达式会被裁剪掉,经过一系列转换后生成最终的执行计划。
RBO 中包含了一套有着严格顺序的优化规则,同样一条 SQL,无论读取的表中数据是怎么样的,最后生成的执行计划都是一样的。同时,在 RBO 中 SQL 写法的不同很有可能影响最终的执行计划,从而影响执行计划的性能。
基于成本优化(CBO)
基于代价的优化器(Cost-Based Optimizer,CBO):根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会生成另外一个关系表达式,同时原有表达式也会保留,经过一系列转换后会生成多个执行计划,然后 CBO 会根据统计信息和代价模型 (Cost Model) 计算每个执行计划的 Cost,从中挑选 Cost 最小的执行计划。
由上可知,CBO 中有两个依赖:统计信息和代价模型。统计信息的准确与否、代价模型的合理与否都会影响 CBO 选择最优计划。 从上述描述可知,CBO 是优于 RBO 的,原因是 RBO 是一种只认规则,对数据不敏感的呆板的优化器,而在实际过程中,数据往往是有变化的,通过 RBO 生成的执行计划很有可能不是最优的。事实上目前各大数据库和大数据计算引擎都倾向于使用 CBO,但是对于流式计算引擎来说,使用 CBO 还是有很大难度的,因为并不能提前预知数据量等信息,这会极大地影响优化效果,CBO 主要还是应用在离线的场景。
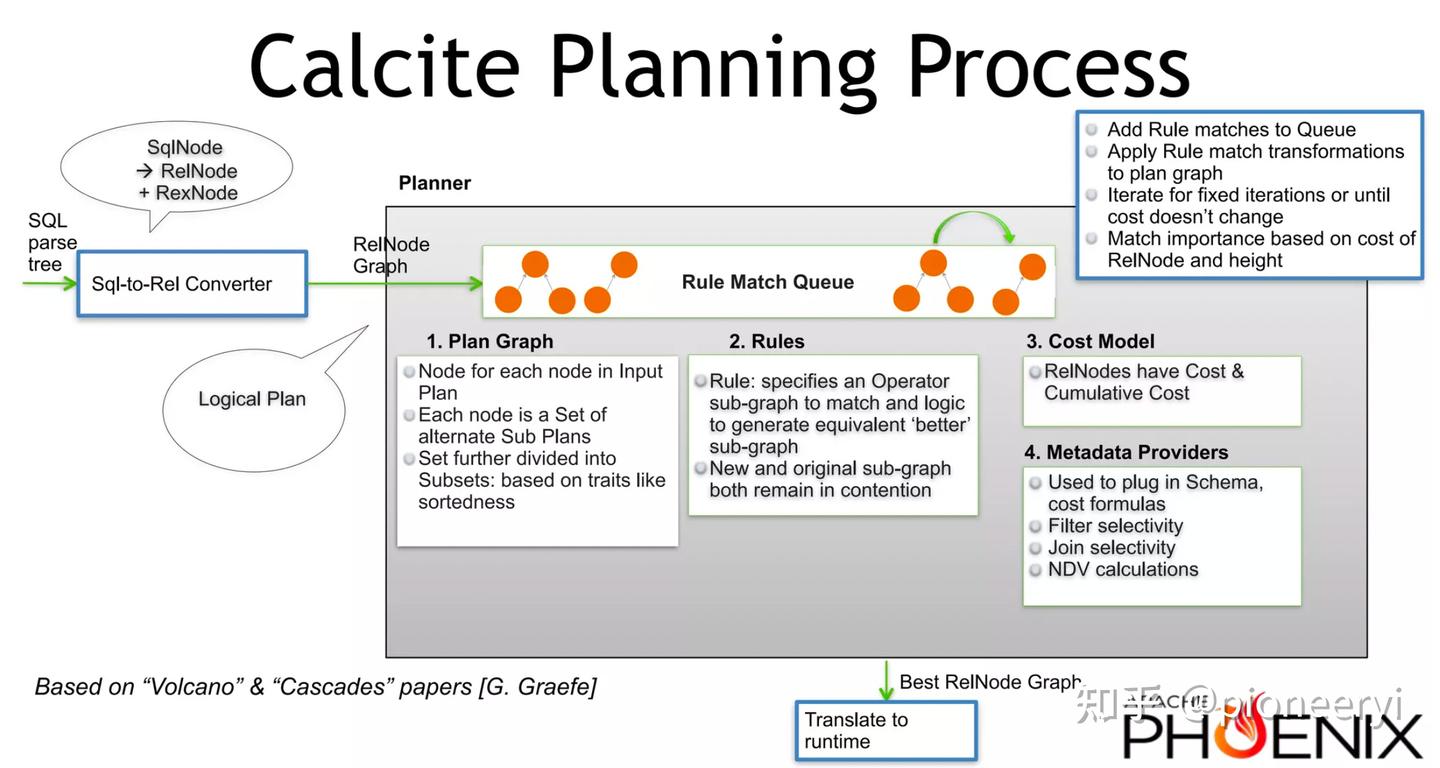
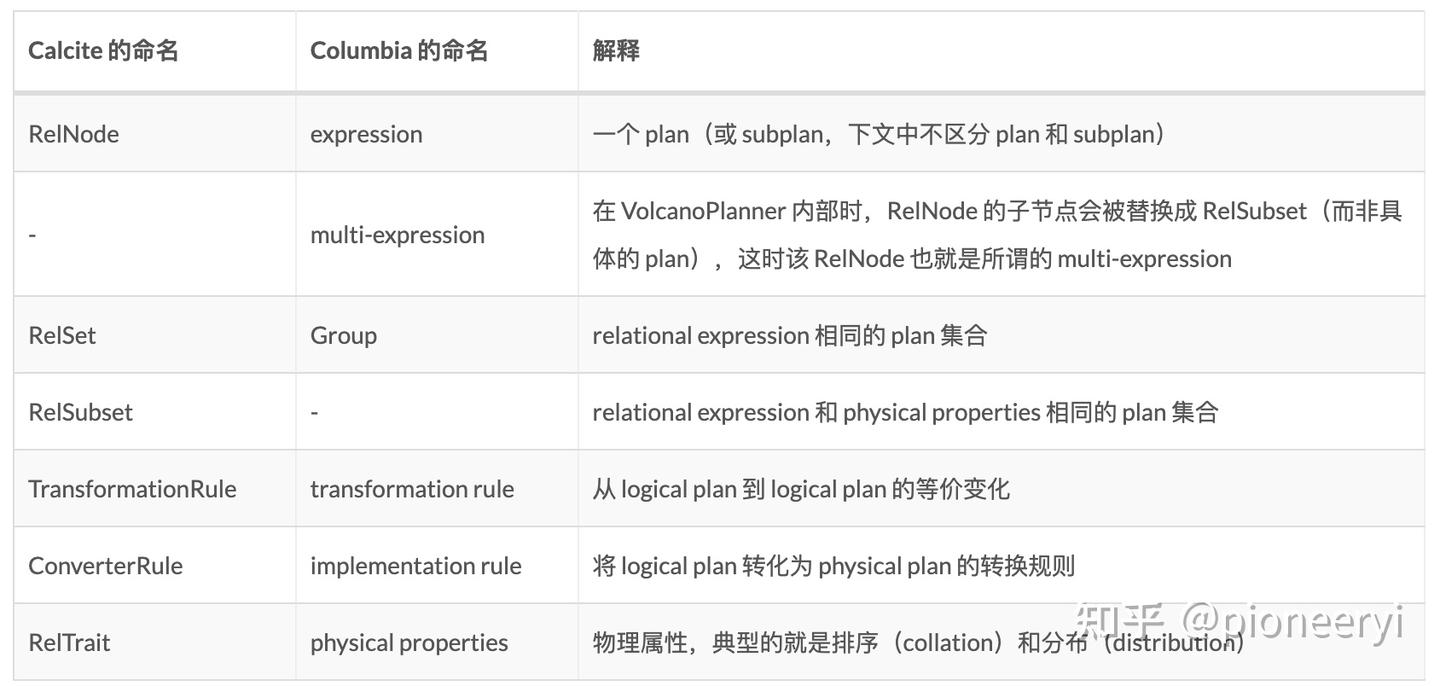
Volcano/Cascades/Columia Optimizer
本节内容来自:揭秘 TiDB 新优化器:Cascades Planner 原理解析
Volcano/Cascades Optimizer 是经典的优化器框架,分别产自论文 《The Volcano Optimizer Generator: Extensibility and Efficient Search 》以及 《The Cascades Framework for Query Optimization》,其主要作者都是 Goetz Graefe。Cascades Framework 已经被很多常见的数据库系统所实现,我们简单介绍一下其中的一些基本概念。
Volcano Optimizer
Volcano Optimizer Generator 本身的定位是一个优化器的“生成器”,其核心贡献是提供了一个搜索引擎。作者提供了一个数据库查询优化器的基本框架,而数据库实现者要为自己的 Data Model 实现相应的接口后便可以生成一个查询优化器。我们下面抛开生成器的概念,只介绍其在“优化器”方向提出的一些方法:
- Volcano Optimizer 使用两阶段的优化,使用 “Logical Algebra” 来表示各种关系代数算子,而使用 “Physical Algebra” 来表示各种关系代数算子的实现算法。Logical Algebra 之间使用 Transformation 来完成变换,而 Logical Algebra 到 Physical Algebra 之间的转换使用基于代价的(cost-based)选择。
- Volcano Optimizer 中的变化都使用 Rule 来描述。例如 Logical Algebra 之间的变化使用 Transformation Rule;而 Logical Algebra 到 Physical Algebra 之间的转换使用 Implementation Rule。
- Volcano Optimizer 中各个算子、表达式的结果使用 Property 来表示。Logical Propery 可以从 Logical Algebra 中提取,主要包括算子的 Schema、统计信息等;Physical Property 可以从 Physical Algebra 中提取,表示算子所产生的数的具有的物理属性,比如按照某个 Key 排序、按照某个 Key 分布在集群中等。
- Volcano Optimizer 的搜索采用自顶向下的动态规划算法(记忆化搜索)。
Cascades Optmizer
Cascades Optimizer 是 Volcano Optimizer 的后续作品,其对 Volcano Optimizer 做了进一步的优化,下面介绍一些 Cascades Optimizer 中的基本概念。
Memo
Cascades Optimizer 在搜索的过程中,其搜索的空间是一个关系代数算子树所组成的森林,而保存这个森林的数据结构就是 Memo。Memo 中两个最基本的概念就是 Expression Group(下文简称 Group) 以及 Group Expression(对应关系代数算子)。每个 Group 中保存的是逻辑等价的 Group Expression,而 Group Expression 的子节点是由 Group 组成。下图是由五个 Group 组成的 Memo:
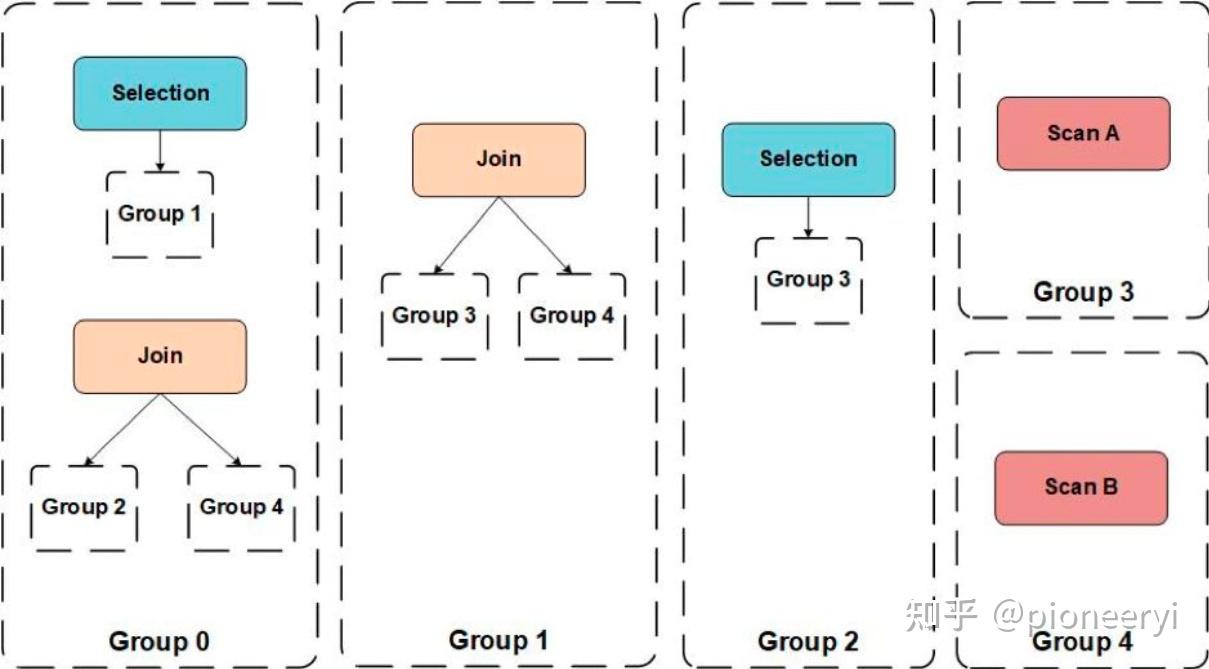
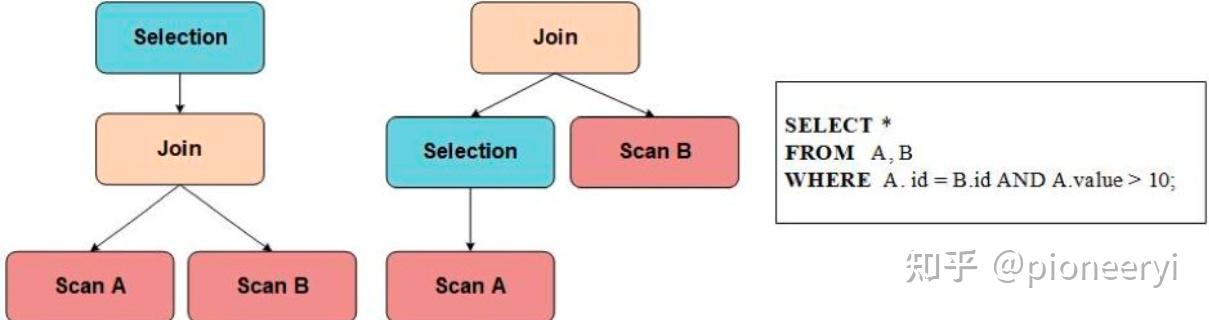
我们可以通过上面的 Memo 提取出以下两棵等价的算子树,使用 Memo 存储下面两棵树,可以避免存储冗余的算子(如 Scan A 以及 Scan B)。
Rule
在 Volcano Optimizer 中,Rule 被分为了 Transformation Rule 和 Implementation Rule 两种。其中 Transformation Rule 用来在 Memo 中添加逻辑等价的 Group Expression。Transformation Rule 具有原子性,只作用于算子树的一个局部小片段,每个 Transformation Rule 都有自己的匹配条件,应用某个 Transformation Rule,通过不停的应用可以匹配上的 Transformation Rule 来扩展搜索的空间,寻找可能的最优解。Implementation Rule 则是为 Group Expression 选择物理算子。
而在 Cascades Optimizer 中,不再对这两类 Rule 做区分。
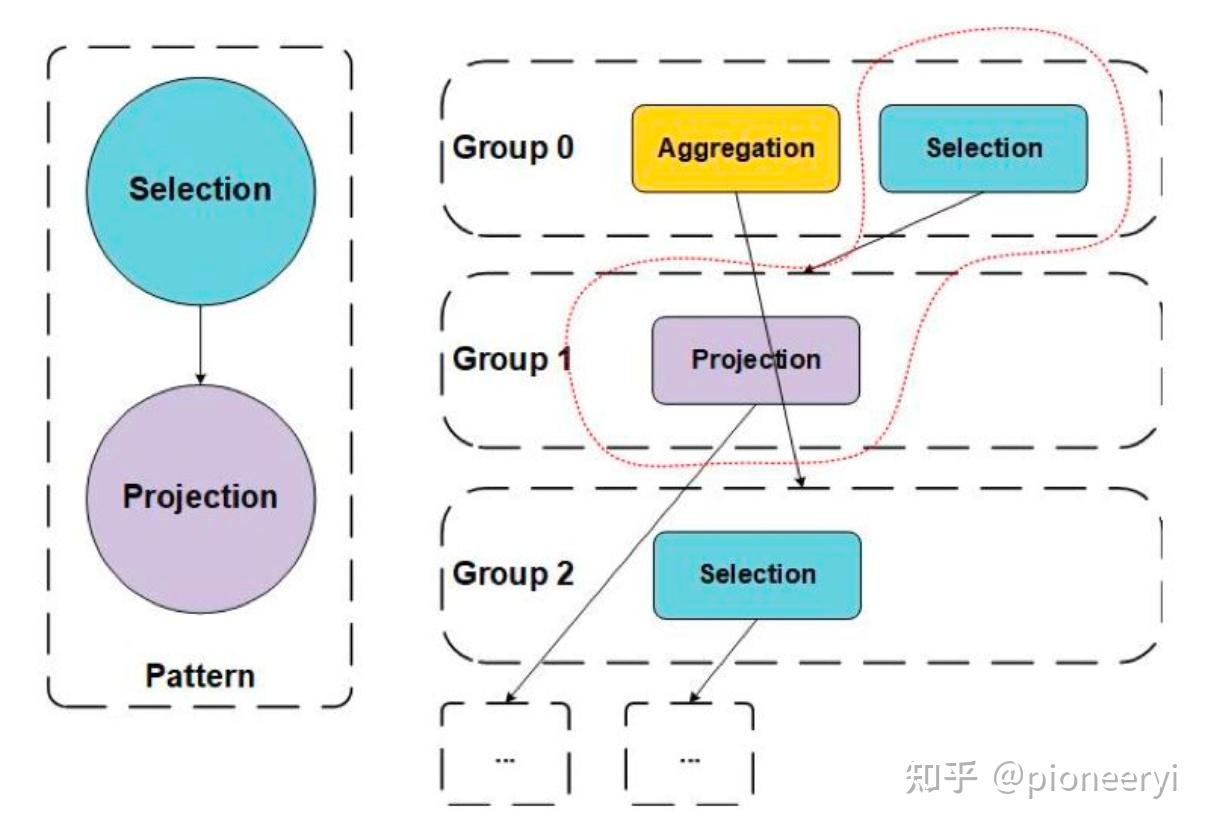
Pattern
Pattern 用于描述 Group Expression 的局部特征。每个 Rule 都有自己的 Pattern,只有满足了相应 Pattern 的 Group Expression 才能够应用该 Rule。下图中左侧定义了一个 Selection->Projection的 Pattern,并在右侧 Memo 中红色虚线内出现了匹配的 Group Expression。
Searching Algorithm
Cascades Optimizer 为 Rule 的应用顺序做了很细致的设计,例如每个 Rule 都有 promise 和 condition 两个方法,其中 promise 用来表示 Rule 在当前搜索过程中的重要性,promise 值越高,则该规则越可能有用,当 promise 值小于等于 0 时,这个 Rule 就不会被执行;而 condition 直接通过返回一个布尔值决定一个 Rule 是否可以在当前过程中被应用。当一个 Rule 被成功应用之后,会计算下一步有可能会被应用的 Rule 的集合。
Cascades Optimizer 的搜索算法与 Volcano Optimizer 有所不同,Volcano Optimizer 将搜索分为两个阶段,在第一个阶段枚举所有逻辑等价的 Logical Algebra,而在第二阶段运用动态规划的方法自顶向下地搜索代价最小的 Physical Algebra。Cascades Optimizer 则将这两个阶段融合在一起,通过提供一个 Guidance 来指导 Rule 的执行顺序,在枚举逻辑等价算子的同时也进行物理算子的生成,这样做可以避免枚举所有的逻辑执行计划,但是其弊端就是错误的 Guidance 会导致搜索在局部收敛,因而搜索不到最优的执行计划。
Volcano/Cascades Optimzier 都使用了 Branch-And-Bound 的方法对搜索空间进行剪枝。由于两者都采用了自顶向下的搜索,在搜索的过程中可以为算子设置其 Cost Upper Bound,如果在向下搜索的过程中还没有搜索到叶子节点就超过了预设的 Cost Upper Bound,就可以对这个搜索分支预先进行剪枝。
Columnbia Optimizer
Columnbiz完全参考了Cascades中的概念和Top-Down的实现,并做了一系列优化来改善Cascade的效率,可以更高的帮我们理解Casecades。Paper:《EFFICIENCY IN THE COLUMBIA DATABASE QUERY OPTIMIZER》,开源实现:columbia
Calcite的设计与实现
有了前面的基础后,这里来看下 Calcite 中优化器的实现。RelOptPlanner 是 Calcite 中优化器的基类,其子类实现如下图所示:
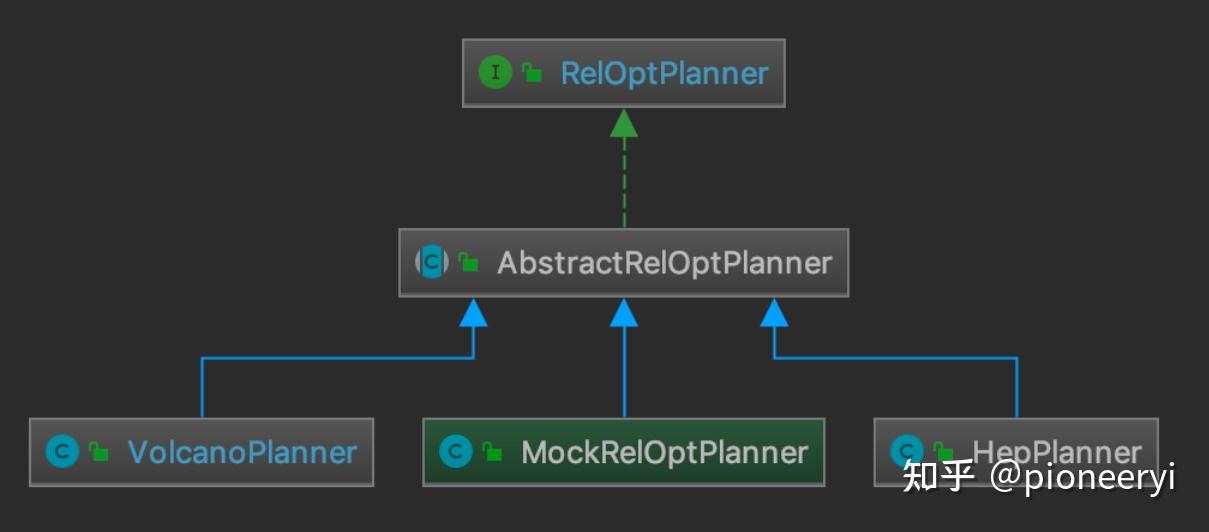
Calcite 中关于优化器提供了两种实现:
1. HepPlanner:就是前面 RBO 的实现,它是一个启发式的优化器,按照规则进行匹配,直到达到次数限制(match 次数限制)或者遍历一遍后不再出现 rule match 的情况才算完成;
2. VolcanoPlanner:就是前面 CBO 的实现,它会一直迭代 rules,直到找到 cost 最小的 paln。
具体优化上,默认使用VolcanoPlanner。下面详细看看两个优化器。
HepPlanner
HepPlanner 会先将所有 relNode tree 转化为 HepRelVertex,这时就构建了一个 Graph:将所有的 elNode 节点使用 Vertex 表示,Gragh 会记录每个 HepRelVertex 的 input 信息,这样就是构成了一张 graph。
构建完graph后,就开始对其进行优化,其入口方法为findBestExp,详细流程如下图所示:
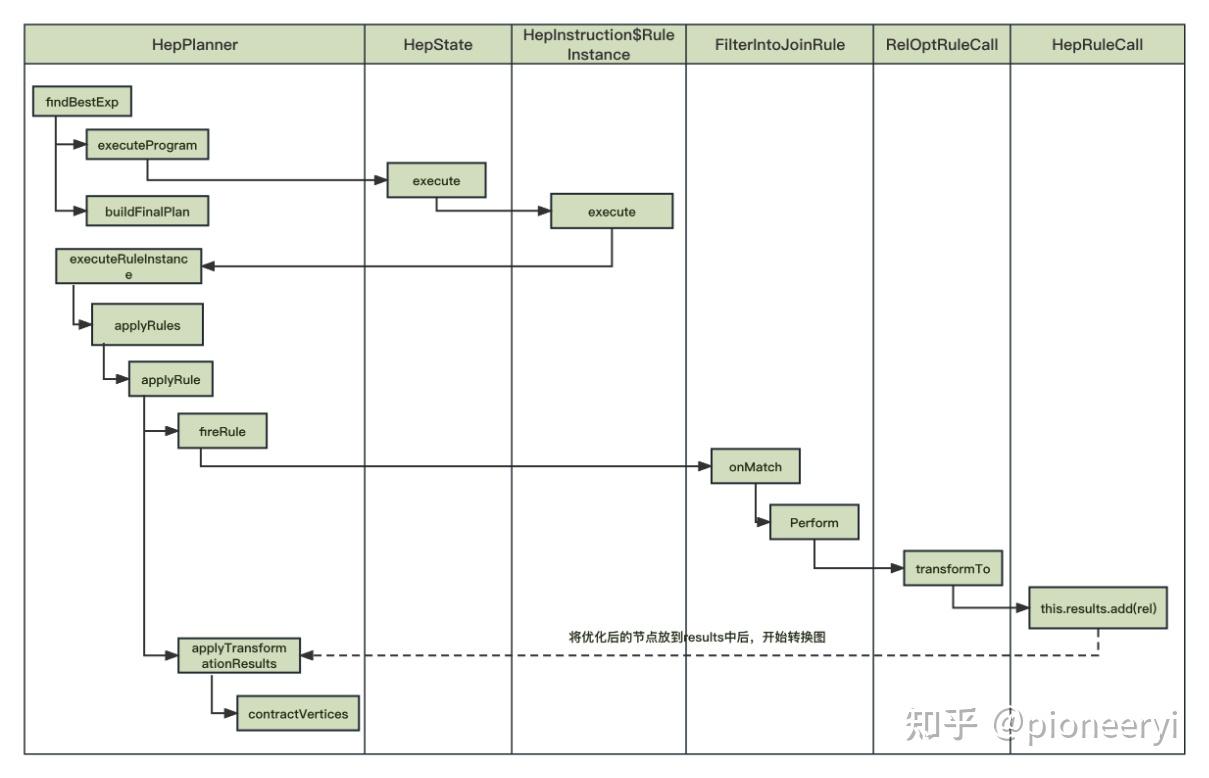
VolcanoPlanner
从代码上看就是对RuleMatch(rule binding)的apply不是以RelSet/RelSubSet为单位从上到下的进行,而是全局共享一个RuleMatch的优先级队列,向其中插入RuleMatch主要在2个时机点:
1. 初始化时调用VolcanoPlanner.setRoot(),设置root RelNode,这会递归触发fireRules,对已有RelNode tree建立一系列RuleMatch,并计算各自的Importance(promise),进入全局RuleQueue。
2. 在优化过程中生成新的RelNode时,会遍历所有rules,尝试为其建立RuleMatch集合并计算importance,加入RuleQueue。
3. 整个过程持续直到RuleQueue为空或者迭代到目标次数。
4. 这样的好处就是可以通过迭代次数有效限制优化时间,但坏处也非常明显,没有了top-down的路径,无法实现pruning,对于physical property的处理也难以优化。
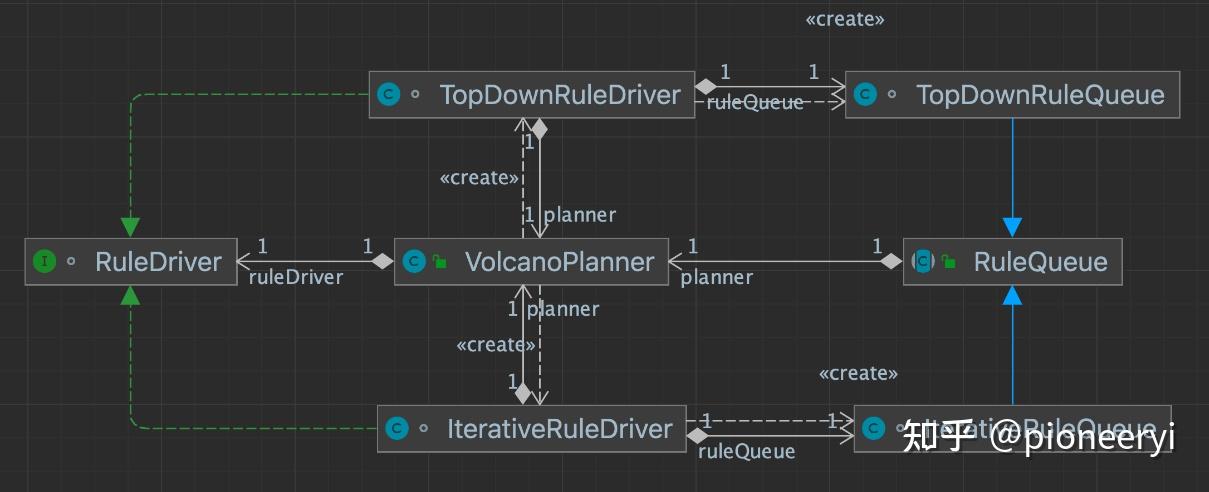
相关术语
相关类图
Apache Calcite原本没有标准的Top-Down优化实现,2020年,Alibaba提了PR增加了Top-Down实现。相应的提交连接如下:
CALCITE-3916: Support cascades style top-down driven rule apply
CALCITE-3916: Support top-down rule apply and upper bound space pruning #1991
更多详细的介绍,可以看这篇文章:Calcite 中新增的 Top-down 优化器
搜索空间
Calcite 的实现则是一个全局的优先队列,即 apply 规则的顺序由全局唯一的优先队列控制。关于优先级队列,详细实现,可以看这篇文章:Calcite 对 Volcano 优化器优先队列的实现
这样做的好处是,如果不希望遍历整个搜索空间,该策略能够在给定的有限步数内给出较优解。但代价则是代码逻辑变得十分难懂,也无法进行进行剪枝优化。从使用者的角度看,原本 top-down 优化中 apply rule 一定是先父节点、后子节点,而 Calcite 中的优化则是“随机”发生在 plan tree 的各个节点上,这也给编写 rule 带来了一些麻烦。
搜索算法
Columnbia优化器的优化算法流程如下所示:

Apache Calacite的优化算法与之类似,如下所示:
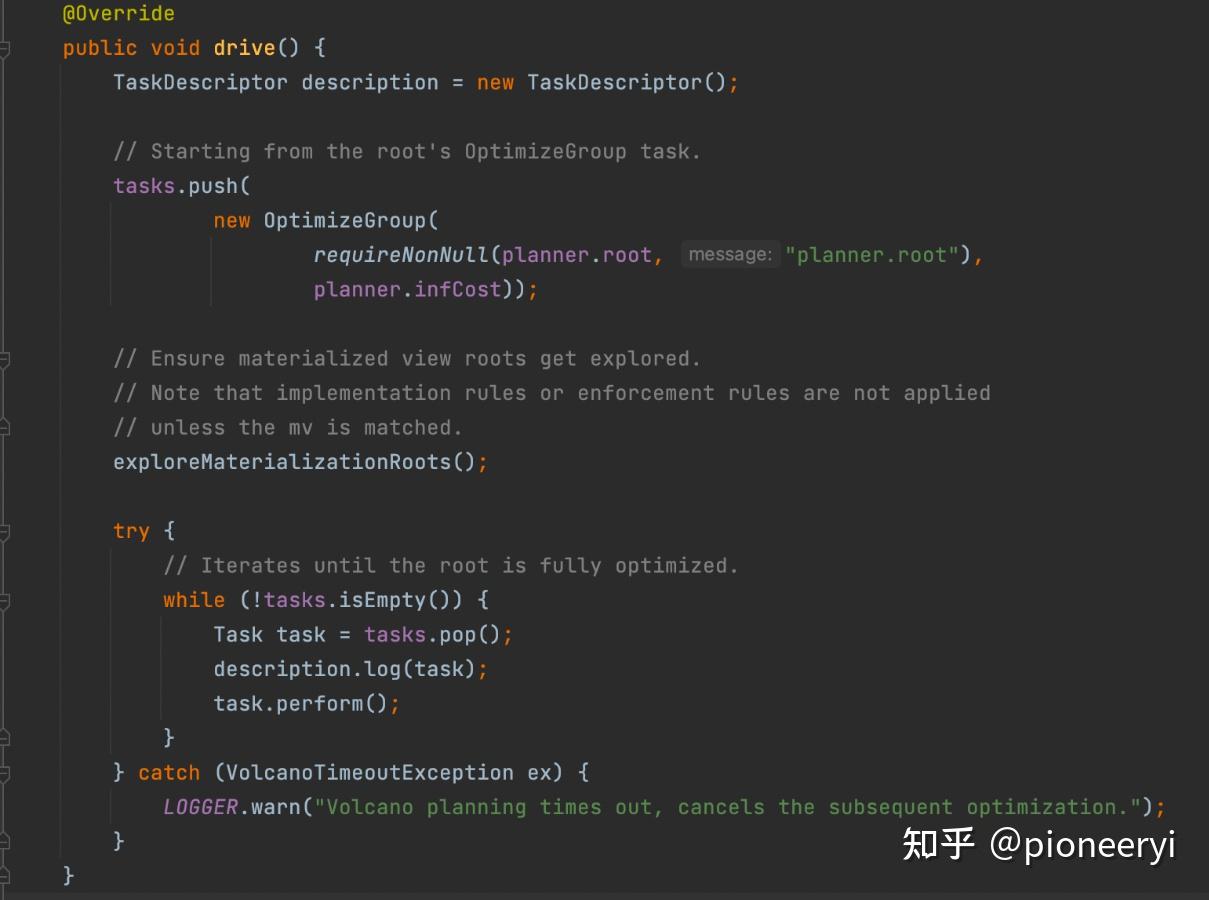
其中Task定义,Columbia主要是下面这几个Task:
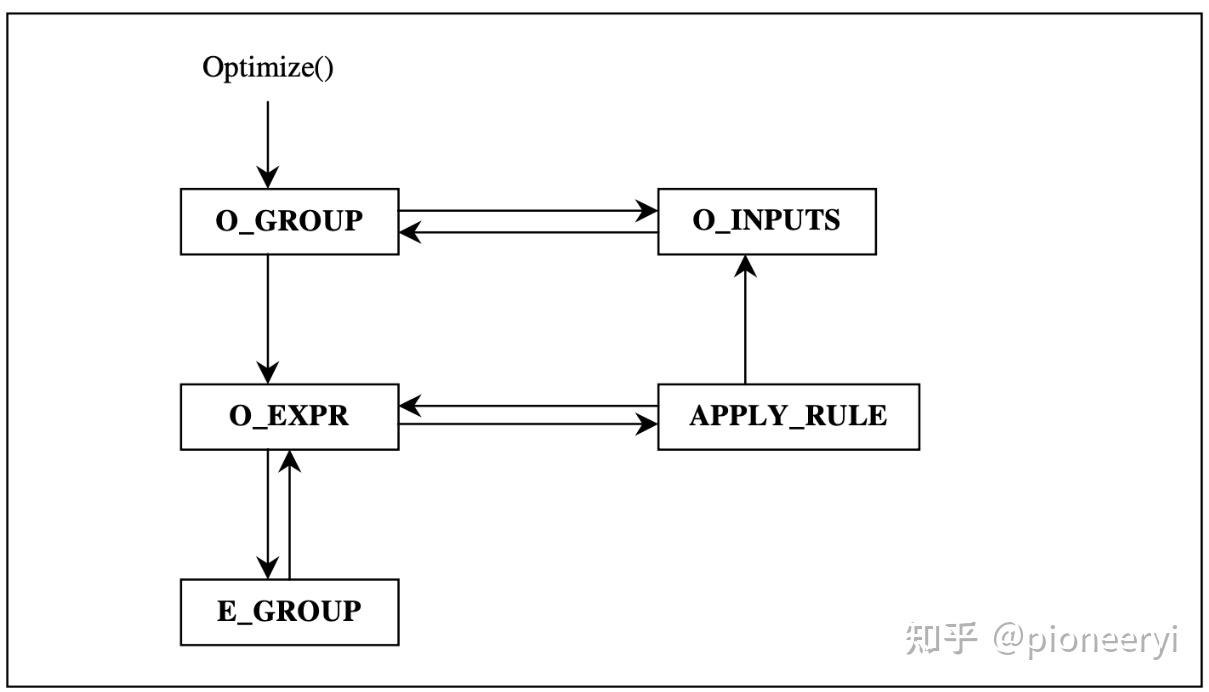
Apache Calcite中的所有Task,以及各个Task之间创建关系如下:
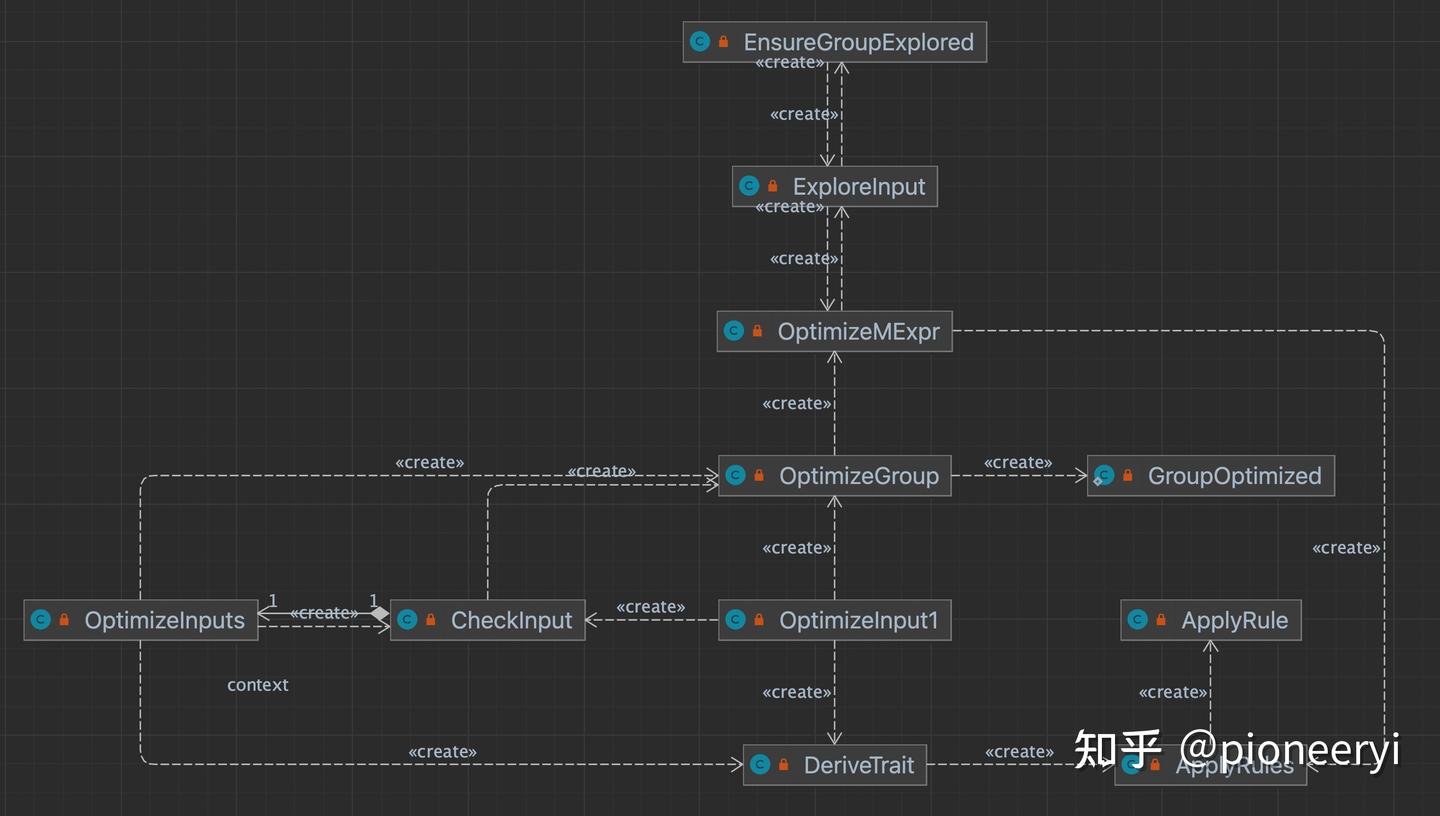
- OptimizeGroup 用于优化一个 RelSubset,类似于 Columbia 中的 O_GROUP。
- OptimizeInputs 以及 OptimizeInput1。OptimizeInputs 依次为调用每个子节点的 OptimizeGroup,对应 Columbia 中的 O_INPUTS。OptimizeInput1 是 OptimizeInputs 在只有一个子节点情况下的简化版本。
- OptimizeMExpr。OptimizeMExpr 用于优化一个 logical plan,类似于 Columbia 中的 E_GROUP。这里 MExpr 的命名是借鉴自 Columbia 中的 M_EXPR(multi-expression)。依次 explore 每个子节点 RelSubset(生成 ExploreInput)。在当前节点匹配所有可能的规则(生成 ApplyRules)
- ExploreInput 为当前 RelSubset 中的每个 logical plan 生成 OptimizeMExpr。不难看出,它们俩来回调用构成了整个 explore 过程。、
- ApplyRules 为当前节点找到所有的 rule match 并生成相应的 ApplyRule,后者 apply rule 生成新的 plan。新 plan 产生后必然会进入某个 RelSubset,进而又会进一步触发后续的优化任务。
剪枝策略
原理说明
这篇文章中关于剪枝原理说明,比较清晰,详细可以看下原文:更高效的Cascades优化器 - Columbia Query Optimizer
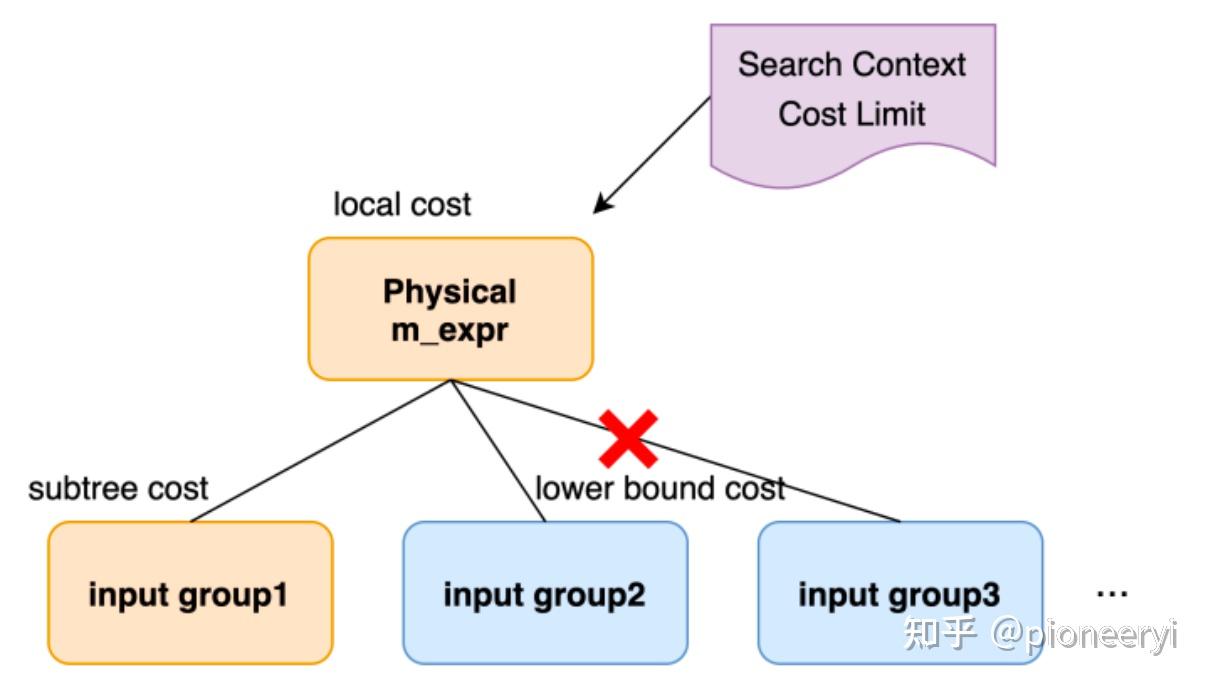
按照Top-Down的优化顺序,在依次优化下层input group时,假设input group1已优化完得到ipute group1 cost1,而input group 2/3尚未优化,但此时:
top local cost + input cost1 + input_group2's lower bound cost > Cost Limit表明无法找到满足context的最优解,从而避免了对input group 2/3的无意义优化。
Calcite中剪枝
Calcite中的剪枝主要发生在OptimizeInputs中,核心逻辑如下:
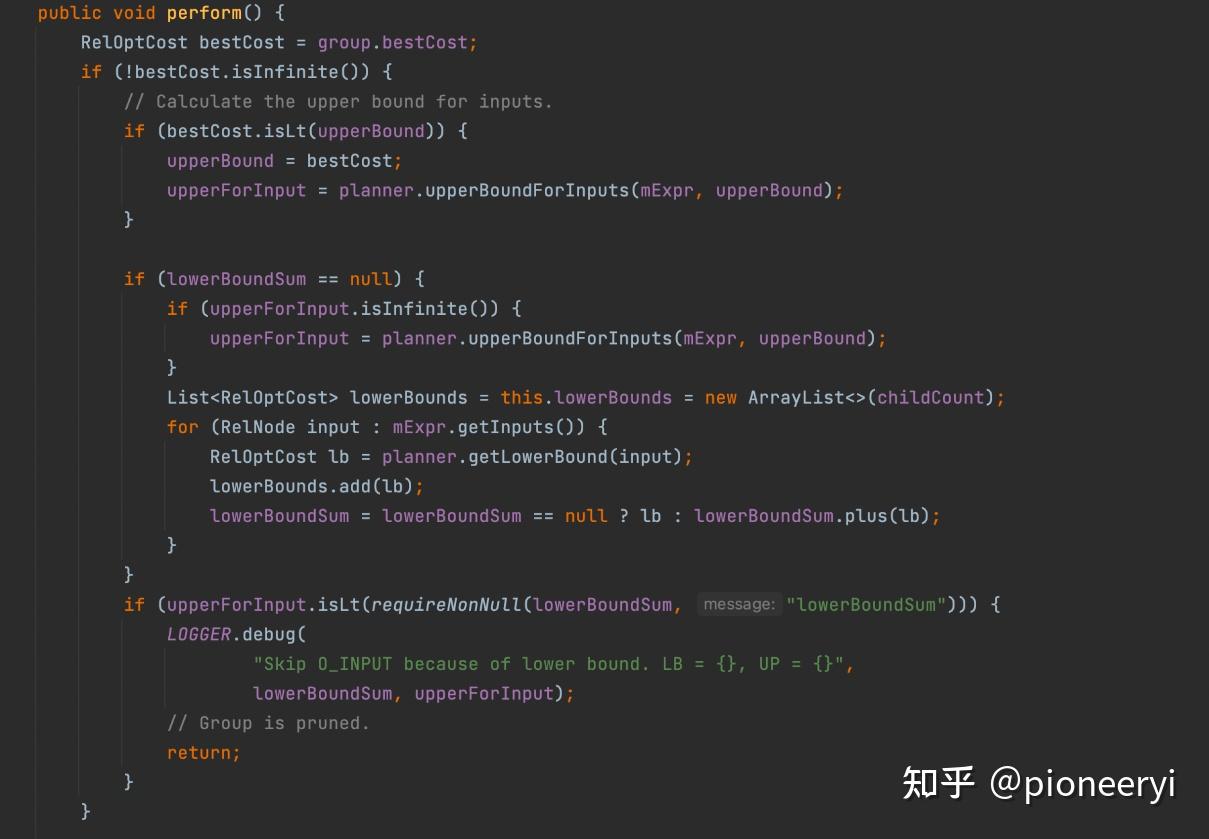
- 计算Inputs的upperBound,也就是最大不能超过;
- 计算lowerBound,也就是当前Inputs的最小开销;
- 如果最小的开销,都超过了upperBound,那说明这个没必要优化了,剪枝
那么如何计算Upper Bound了?
upperForInput = planner.upperBoundForInputs(mExpr, upperBound);
protected RelOptCost upperBoundForInputs(
RelNode mExpr, RelOptCost upperBound) {
if (!upperBound.isInfinite()) {
RelOptCost rootCost = mExpr.getCluster()
.getMetadataQuery().getNonCumulativeCost(mExpr);
if (rootCost != null && !rootCost.isInfinite()) {
return upperBound.minus(rootCost);
}
}
return upperBound;
}
初始的upperBound来自OptimizedGroup,对于一个MExpr,其Inputs的UpperBound=upperBound-rootCost。注意OptimizeGroup的upper会不断更新,也就是会随着优化进行不断缩小。
那么如何计算Lower Bound了?
Calcite中的计算LowerBound代码如下所示:
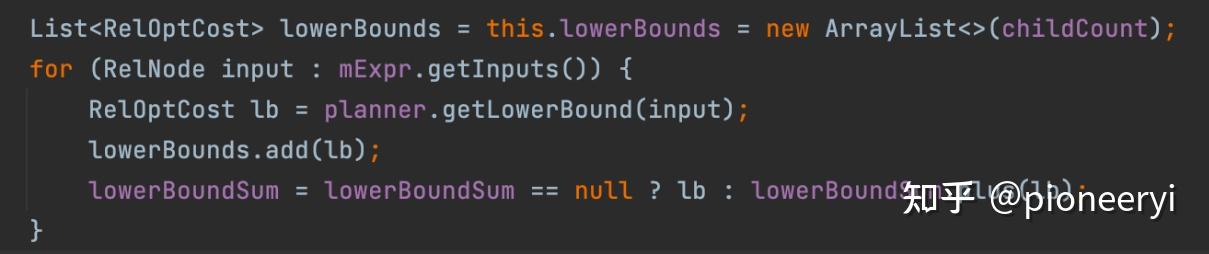
Columba中的LowerBound计算方法如下:

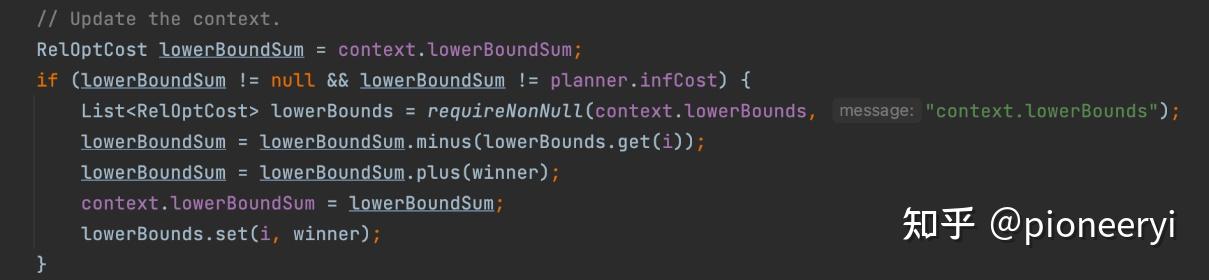
Calcite中,需要自定义实现,如果没有自定义,默认为零。LowerBound会不断更新,具体是在CheckInput这个task中更新,逻辑如下:
总结
本文首先介绍了优化的基础知识,然后介绍了Volcano和Cascade优化器,最后在前两节的基础上,介绍了Calcite的优化实现。坦白来说,优化器是很复杂的一块,我也是一知半解,如果大家想了解更多,还是需要自己去看看论文和源码。
参考文档
《The Volcano Optimizer Generator: Extensibility and Efficient Search 》
《The Cascades Framework for Query Optimization》
《EFFICIENCY IN THE COLUMBIA DATABASE QUERY OPTIMIZER》
更高效的Cascades优化器 - Columbia Query Optimizer
揭秘 TiDB 新优化器:Cascades Planner 原理解析
The Volcano/Cascades Optimizer
Apache Calcite 优化器详解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号