


[java] 汇率换算器实现-插曲1-正则表达式(1)
[java] 汇率换算器实现-插曲1-正则表达式(1)
[java] 汇率换算器实现-插曲1-正则表达式(1)
Table of Contents
1 系列文章地址
2 前言
3 什么是正则表达式
正则表达式作为计算机科学的一个概念, 可以使用单个字符串来描述, 匹配一系列符合某个句法规则的字符串. 正则表达式的基本语法可以在egrep的使用中了解, 更加复杂的用法就集成到了其他编程语言中, 如perl, python, java, php等.
4 正则表达式的初步运用–egrep
4.1 egrep支持的正则表达式的语法
| 符号 | simple discription | detail discription |
|---|---|---|
| . | 点 | 匹配任何单个字符 |
| [] | 单字符集合 | 匹配任何列在里面的单个字符 |
| [^…] | 单字符的补集 | 匹配任何不在列表中的单个字符 |
| {min, max} | 匹配次数 | 至少匹配min次, 至多匹配max次 |
| ? | 问号 | {0, 1} |
| \(*\) | 星号 | {0,} |
| + | 加号 | {1,} |
| ^ | 脱字号 | 匹配一行的开头 |
| $ | 美元号 | 匹配一行的结尾 |
| \\< | 单词边界 | 匹配一个单词的开始边界 |
| \\> | 单词边界 | 匹配一个单词的结尾边界 |
| vertical line | 选择 | 匹配其中一个表达式 |
| () | 括号 | 限制选择匹配的范围, 给匹配结果一个相应的标识 |
| \1 | 应用 | 应用由()匹配的结果 |
4.2 举例说明
- 匹配一句话中连续重复的单词, 其间由空格分隔
sentence in file.txt: Hello i am a a person, not a thing. exe: egrep -i '([a-zA-Z]+)( +\1){1,}' file.txt explane: -i 表示忽略大小写 - 匹配文中可能出现的输入错误的单词
sentence in file.txt: Teh month exe: egrep -i '\<(hte|teh)\>' file.txt
- 匹配24小时制的时间
exe: egrep '([01]?[0-9]|2[0-3]):[0-5][0-9]' tmp.txt
5 正则表达式更复杂的运用–perl
由于perl的使用不是本文的主题, 因此这里只是简略的说明下.
5.1 perl简单用法
# filename: temps
$celsius = 20; # 变量赋值
while ($celsius <= 45) # 循环结构
{
if ($celsius != 30) # 选择结构
{
$fahrenheit = ($celsius * 9/5) + 32; # 计算
print "$celsius C is $fahrenheit F. \n"; # 输出结果
$celsius = $celsius + 5;
}
}
perl temps
5.2 简单的字符匹配
print "Enter a temperature in Celsius:\n";
$celsius = <STDIN>; # 用户输入
chomp($celsius); # 将结尾的换行符去掉
# 判断是否只有数字
if ($celsius =~ m/^[0-9]+$/) { # m means 尝试进行正则表达式匹配,
# =~ 说明正则表达式的对象是$reply
print "$celsius C\n";
} else {
print "not only digits\n";
}
又考虑到现实中, 温度的表示可以是负数, 小数, 因此, 正则表达式可以改为:
m/^[-+]?[0-9]+(\.[0-9]+)?$/
5.3 获取匹配后的内容
那么如何获取匹配后的内容呢? 采用了()包围的方法, 如下:
print "Enter a temperature in Celsius:\n";
$celsius = <STDIN>; # 用户输入
chomp($celsius); # 将结尾的换行符去掉
# 判断输入的格式是否为$number$space$unit
if ($celsius =~ m/^([-+]?[0-9]+(\.[0-9]+))? *([Cc])$/) { # m means 尝试进行正则表达式匹配,
# 如果, $number和$unit之间还有可能包括tab, 那么判断语句改为下式
# if ($celsius =~ m/^([-+]?[0-9]+(\.[0-9]+))?[ \t]*([Cc])$/) {
# =~ 说明正则表达式的对象是$reply
print "The number is $1, the unit is $3\n"; # group从左向右, 按照出现(的顺序进行编号
} else {
print "not matched\n";
}
上面的匹配行为中, 我们没有使用到$2, 那么有没有什么更好的方法将$2从group中排除掉, 量$3成为$2呢? 可以采用符号(?: ):
$celsius =~ m/^([-+]?[0-9]+(?:\.[0-9]*)?)[ \t]*([Cc])$/
5.4 常用特殊字符, 匹配等
\t -> a tab character \n -> a newline character \r -> a carriage-return character \s -> matches any "whitespace" character (space, tab, newline, formfeed, and such) \S -> anything not \s \w -> [a-zA-Z0-9_] (useful as in \w+, ostensibly to match a word) \W -> anything not \w \d -> [0-9] \D -> anything not \d \b -> 位置匹配, start of word and end of word (?: ) -> the matched is not added to group (?= ) -> 位置匹配, lookahead (toward the right), the subregex comes next (?! ) -> 位置匹配, successful if can not match to the left (?<= ) -> 位置匹配, lookbehind (toward the left), this position is after the subregex (?<! ) -> 位置匹配, successful if can not match to the right m/../i -> i means case-insensitive
5.5 匹配后进行替换
usage: s/regex/replacement/ for example: $var =~ s/\bJeff\b/Jeffrey/i; # 将Jeff单词替换为Jeffrey, 并且不区分大小写 for example: $var =~ s/\bJeff\b/Jeffrey/g; # g means将$var中出现的所有Jeff单词都替换为Jeffrey
下面给出一个问题, 如果某些导出的文件中的数字是很多位的, 如8.235897920, 这样并不方便读者进行阅读, 那么如何通过匹配以及替换的方式将多位小数转变位适当位数的小数呢, 如两位.
number regex: (\.\d\d)?\d* implement: $price =~ s/(\.\d\d)?\d*/$1/g
5.6 一些例子
5.6.1 位置信息匹配
- 仅匹配特殊字符的一部分, 如仅匹配Jeffrey中的Jeff, 而不匹配单纯的Jeff
(?=Jeffrey)Jeff, (?=Jeffrey)用来确定确实存在Jeffrey, 并指定J前的位置. 并且位置信息的匹配要在具体内容匹配之前, 也就是说regex: Jeff(?=Jeffrey), 不能实现上述的匹配
- 将漏加的"'"添加上, 如本来应该是Jame's, 却写成了James, 用下面几种方式进行实现:
s/\bJames\b/Jame's/g s/\bJeff(?=s\b)/Jeff'/g s/(?<=\bJame)(?=s\b)/'/g
- 在一长整数中添加分隔的逗号, 使得数字更加易读. 如, 123456789, 改成1,2345,6789
s/(?<=\d)(?=(\d{4})+\b)/,/g; # (?<=\d) 说明添加逗号的位置的左边必须有个数字 # (?=(\d{4})+\b) 说明从单词的边界开始往左边数, 每隔4个数字, 添加一个逗号
5.6.2 文本文档转换为html格式
undef $/;
$text = <>;
$text =~ s/&/&/g; # make the basic html...
$text =~ s/</</g; # ...characters &, <, and >...
$text =~ s/>/>/g; # ...HTML safe.
# 下面使用了perl正则表达式中一个神奇的字符/m
# 在一般情况下^, 和 $表达的意思如下:
# ^: 匹配一个变量的第一个位置
# $: 匹配一个变量的最后一个位置
# 加了一个/m后, ^和$表示的意思将发生变化:
# ^: 匹配一行的第一个位置
# $: 匹配一行的最后一个位置
# 而$text变量的内容为: 一行内容+换行符+加下一行内容+...
# 因此想要将每一空行转变为<p>需用/m
$text =~ s/^\s*$/<p>/mg; # 将空行转变为<p>
# 将email地址转变成links
# 这里使用了另一种书写方式s{regex}{replacement}gix
# 此时regex中可以使用空格, 注释语言使得regex更加的易读
# 结尾x的作用是忽略regex中多余的空格符,
# 值得注意的是, 它并不能忽略replacement中的空格项
$text =~ s{
\b
# Capture the address to $1
(
\w[-.\w]* # 用户名匹配, \w = [a-zA-Z0-9_]
\@ # 由于@在perl语言中有其他意思, 因此需要用转义字符进行转换
[-a-z0-9]+(\.[-a-z0-9]+)*\.(com|edu|info|others) # 域名, 此处others表示其他类似com, edu的内容
)
\b
}{<a href="mailto:$1">$1</a>}gix;
# Turn HTTP URLs into links ...
$text =~ s{
\b
(
http:// [-a-z0-9]+(\.[-a-z0-9]+)*\.(com|edu|others) \b # hostname
(
/ [-a-z0-9_:\@&?=+,.!/~*'%\$]* # 可选择的路径
(?<![.,?!]) # 匹配的最后位置, 不能在[.,?!]的后面
)?
)
}{<a href="$1">$1</a>}gix;
print $text;
5.7 一些元字符的缩写
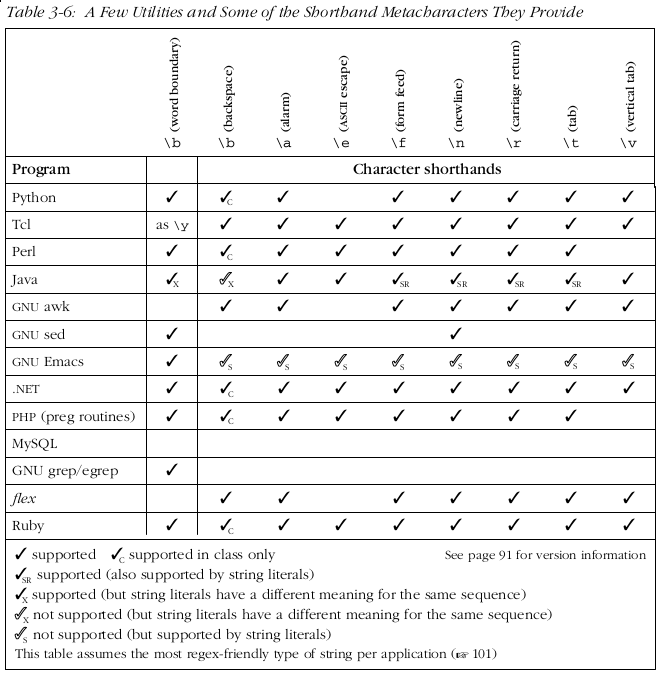
一些元字符的缩写
5.8 Excape Character, 转义字符
转义字符标志着一个字符序列中出现在它之后的后续几个字符采取一种替代解释.
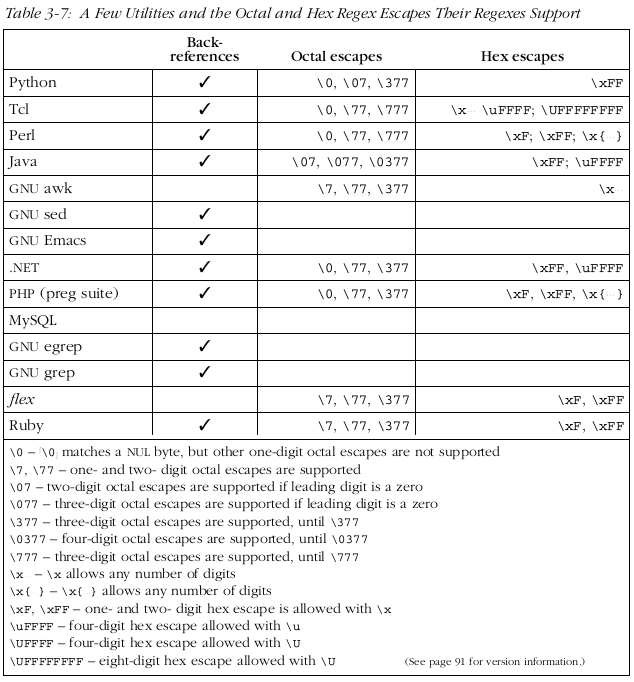
5.9 字符类和字符类相似的结构
5.9.1 常见字符集合: [a-z] and [^a-z]
一般在8位的系统中, [^LMNOP]表示的意思为[\x00-KQ-\xFF], 但是字符系统为Unicode的时候, 最大值将会超出\xFF, 此时它表示的范围将包括出了LMNOP以外的所有字符(the tens of thousands).
5.9.2 dot字符
一般表示匹配除了换行符以外的所有字符. 以下情况需要注意:
- 在某些的Unicode字符系统中, 如java regex package, dot一般不匹配unicode的行结尾字符
- 在match mode, 它的含意会发生变化
- 在基于POSIX标准的语言中, 并不匹配NUL, 尽管主流的脚本语言都允许在文本中出现NULLs, 并且能够匹配它们.
5.9.3 结合字符序列的Unicode: \X
\X支持匹配由多个Unicode编码组成的字符, 并且能够匹配换行符和其他Unicode行结尾符. 类似与".".
5.9.4 字符集缩写
\d: 数字[0-9], 在一些Unicode工具中为所有的Unicode数字
\D: [^\d]
\w: [0-9a-zA-Z_], 在某些工具中没有包括下划线. 如果, 支持unicode, \w通常表示为
所有的英文字母, 重要的例外, java.util.regex and PCRE, \w都表示[a-zA-Z0-9_]
\s: ascii-only系统中, [ \f\n\r\t\v]. 在unicode系统中, 有些时候还包括U+0085, \p{Z}
5.9.5 Unicode特性, 字符系统, 区块
很多unicode系统中, 经常通过"\p{quality}"来匹配包含某种特性的字符, 用"\P{quality}"来匹配不包含某种特性的字符.
Unicode的特性主要如下:

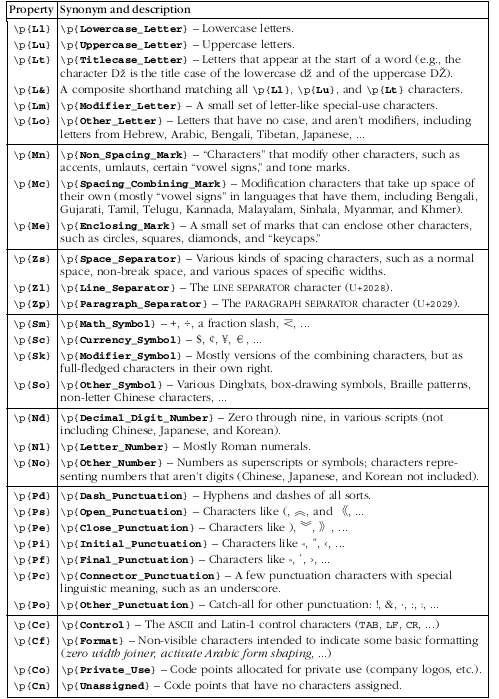
不同的字符系统的匹配, 比如匹配中文字符, \p{Han}, 区块与字符系统的匹配类似
5.10 位置信息匹配
5.10.1 一行或是字符串开始与结束的位置的匹配
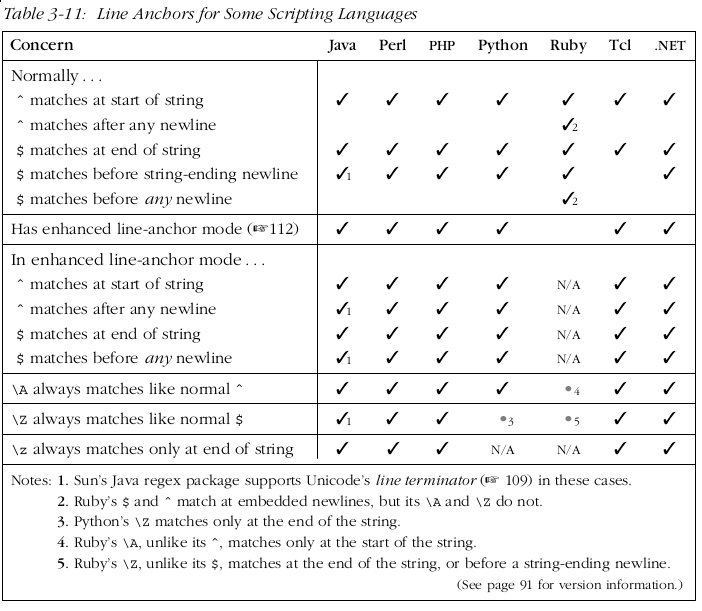
5.10.2 上次匹配的后面的位置, 以及这次匹配开始的位置: \G
5.10.3 匹配字符边界
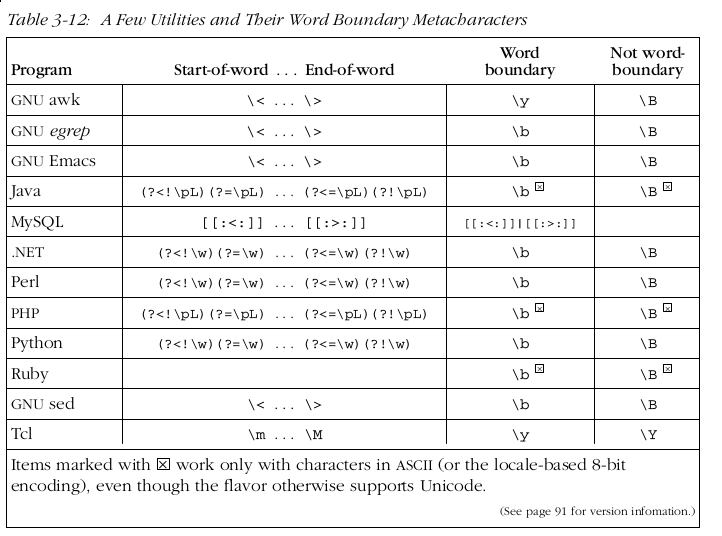
5.11 Grouping, Capturing, Conditionals, and Control
- 利用()进行分组
- 利用\1, \2获取不同组的信息
- (?: )忽略当前组合,
- 利用"|", 进行选择
- 利用(?if then | else) 进行条件选择
- 利用*, +, ?, {num, num}进行贪婪匹配
- 利用*?, +?, ??, {num, num}?进行非贪婪匹配
作者: grassofsky
出处: http://www.cnblogs.com/grass-and-moon
本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 原文链接 如有问题, 可邮件(grass-of-sky@163.com)咨询.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号