

使用multi-paxos实现日志同步应用
paxos
说multi-paxos之前先简要说一下paxos
paxos是在多个成员之间对某个值(提议)达成一致的一致性协议。这个值可以是任何东西。比如多个成员之间进行选主,那么这个值就是主的身份。在把multi-paxos协议应用在日志同步中时,这个值就是一条日志。网上讲paxos的文章已经很多了,这里简要说明一下。
paxos分为prepare和accept两个阶段。协议中有两个主要的角色,proposer和acceptor。
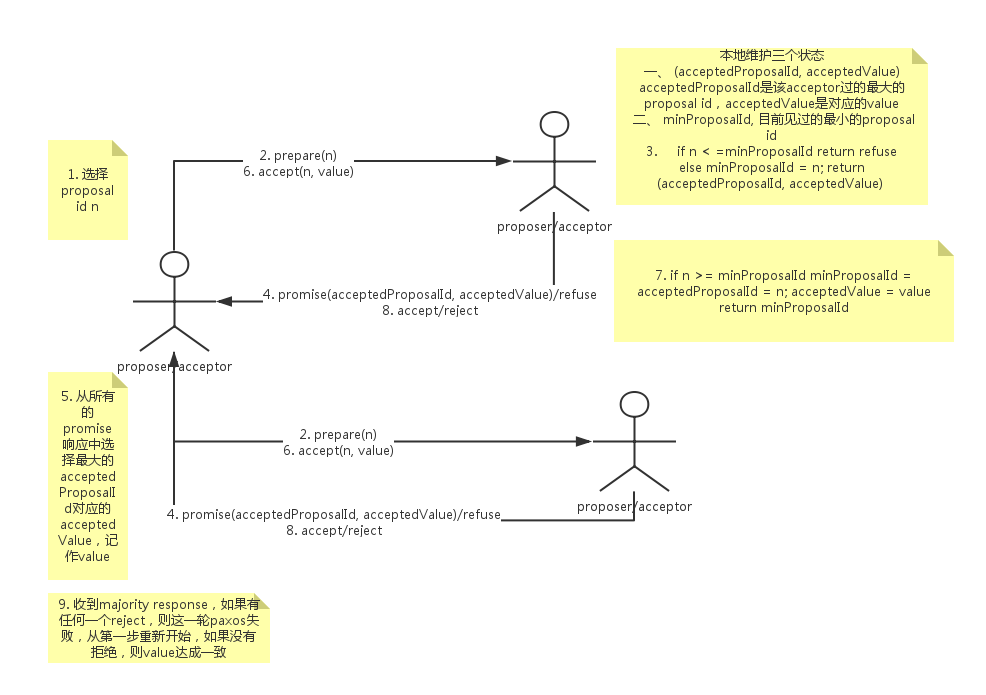
value被majority accept之前,每个acceptor可以accept多个不同的值。但是,一旦一个value被majority accept(即value达成一致),那么这个value就不会变了。因为prepare阶段会将该value给找出来,随后accept阶段会使用这个value,后续的所有的提案都会选择这个value。
需要注意的是,每个阶段都是收到majority的响应后即开始处理。并且由于机器会宕机,acceptor需要对acceptedProposalID, acceptedValue和minProposal进行持久化。
从流程中可以看出prepare有两个作用:
- 大的proposal id会block未完成的小的proposal id达成一致的过程,所以为了减少无效的prepare请求,每次都选择比自己以往见过的proposal id更大的id。
- 一旦某个value达成一致,那么后续的prepare都会找到这个value作为accept阶段的值
可以看出,一次paxos达成一致至少需要两次网络交互。
multi-paxos
paxos是对一个值达成一致,multi-paxos是运行多个paxos instance来对多个值达成一致,每个paxos instance对一个值达成一致。在一个支持多写并且强一致性的系统中,每个节点都可以接收客户端的写请求,生成redo日志然后开始一个paxos instance的prepare和accept过程。这里的问题是每条redo日志到底对应哪个paxos instance。
在日志同步应用中,用log id来区分不同的paxos instance。每条日志都由一个id唯一标示,这个log id标识一个paxos instance,这个paxos instance达成一致,即对应的日志内容达成一致,即majority的成员accept了这个日志内容。在一个由N个机器(每个机器既承担proposer也承担acceptor角色)组成的集群(通常叫做paxos group)中,每个proposer都可以产生redo日志并且进行paxos instance,那么每条redo日志到底使用哪个log id? 显然,每个proposer都会选择自己知道的还没有达成一致的最小的log id来作为这次日志的log id,然后运行paxos协议,显然,多个proposer可能会选择同一个log id(最典型的场景就是空集群启动的情况下),最终,只有一个proposer能够成功,那么其他的proposer就需要选择更大的未达成一致的log id来运行paxos。显然,这种冲突是非常严重的,会有很多的proposer成功不了进而选择更大的log id来运行paxos。
在真实的系统中,比如chubby, spanner,都会在paxos group中选择一个成员作为leader,只有leader能够propose日志,这样,prepare阶段就不会存在冲突,相当于对整个log文件做了一次prepare,后面这些日志都可以选用同一个proposal id。这样的话,每条日志只需要一次网络交互就能达成一致。回顾一下文章开头提到paxos中需要每个成员需要记录3个值,minProposal,acceptedProposal,acceptedValue,其中后面两个值可以直接记录在log中,而第一个值minProposal可以单独存在一个文件中。由于这里后面的日志都可以选用同一个proposal id,显然,在大部分时间内,minProposal都不需要改变。这正是multi-paxos的精髓
选主
对于paxos来说,主的身份无所谓,主不需要像raft那样拥有最全的已经commit的日志。所以选主算法无所谓,比如大家都给机器ip最大的机器投票,或者给日志最多的投票,或者干脆直接运行一次paxos,值的内容就是主的身份。显然,由于对新主的身份无限制,那么,新主很有可能没有某些已经达成一致的日志,这个时候,就需要将这些已达成一致的日志拉过来,另外,新主也有可能没有某些还未达成一致的日志。如下图所示:
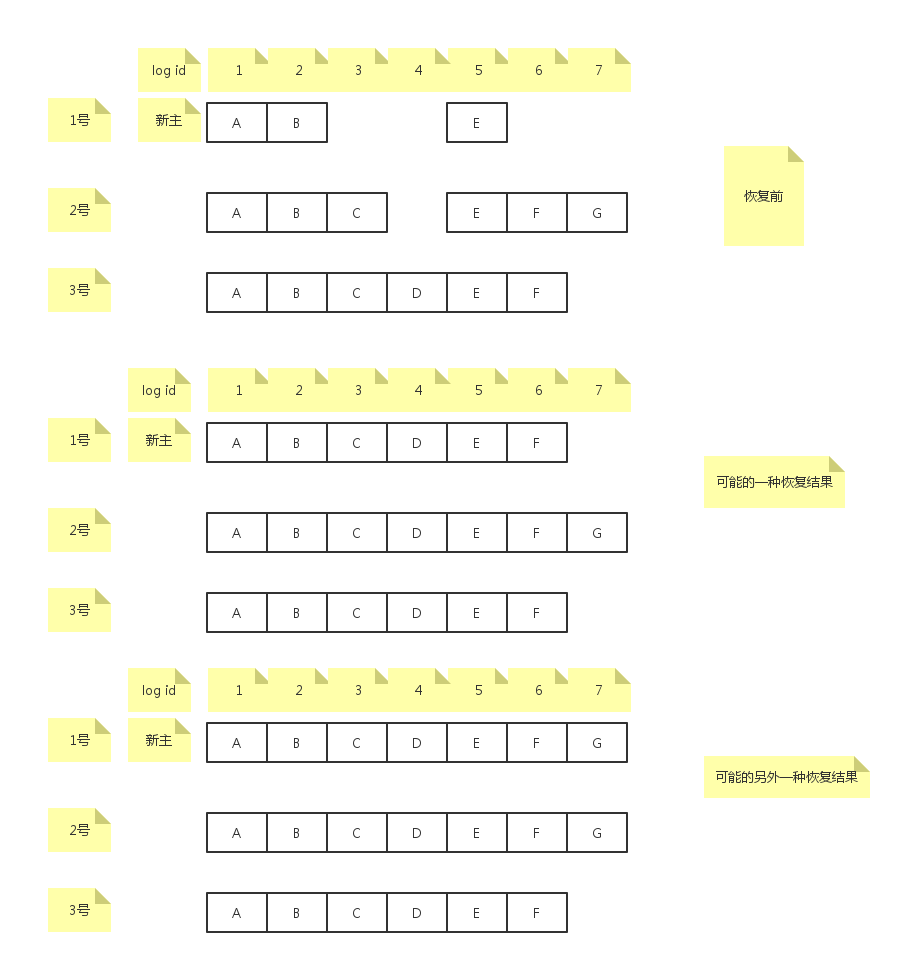
图中,恢复之前,log id等于3的日志C已经在多数派上达成了一致,但是在新主上没有。比如log id等于4的日志D在多数派上没有达成一致,在新主上也没有。
恢复
新主向所有成员发送查询最大log id的请求,收到majority的响应后,选择最大的log id作为日志恢复的结束点。图中,如果收到的majority不包括2号成员,那么log id=6为恢复结束点。如果收到的majority包括2号成员,那么log id=7为恢复结束点。这里取majority的意义在于恢复结束点包含任何的majority达成一致的日志。拿到log id后,从头开始扫描日志,对于每条日志都运行paxos协议确认一次:如果日志之前已经达成一致了,比如日志A,B,C,E,F,那么再次运行paxos的prepare阶段会把日志内容找出来作为accept阶段的值,不影响结果。如果日志之前并没有达成一致,比如日志D,那么当返回的majority中包含3号成员时,D会被选出来当作accept阶段的值,当返回的majority中不包含3号成员时,那么D实际上不会被选出,这时主可以选择一个dummy日志作为accept阶段的值。
恢复优化
可以看出,如果日志非常多,每次重启后都要对每条日志做一次paxos,那么恢复时间可想而知。在上面的例子中,A,B,E已经达成一致,做了无用功。paxos协议中,只有主即proposer知道哪些日志达成了一致,acceptor不知道,那么很容易想到的一个优化就是proposer将已经达成一致的日志id告诉其他acceptor,acceptor写一条确认日志到日志文件中。后续重启的时候,扫描本地日志只要发现对应的确认日志就知道这条日志已经达成多数派,不需要重新使用paxos进行确认了。这种做法有一个问题,考虑如下场景:
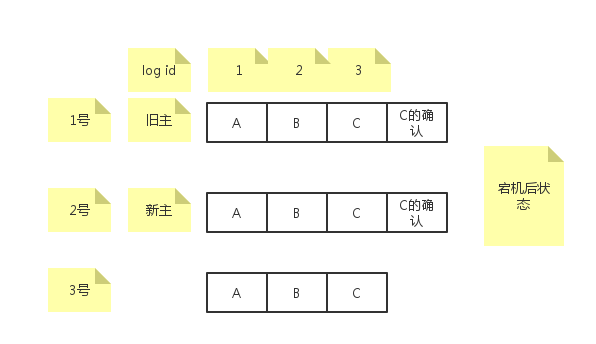
旧主成功的给自己和2号成员发送了确认日志,但是没有给3号成员发送成功旧挂了,然后2号成员被选为新主,那么新主不会对log id=3的日志重新运行paxos,因为本机已经存在确认日志。这样的话,3号成员就回放log id=3的日志到上层了。解决这个问题的做法就是followers需要主动的向主询问日志到底有没有达成一致,如果有,则自己补充确认日志。
回放
宕机重启后,对未达成一致的日志重新运行paxos时,如log id=4的日志,如果返回的majority中不包含3号成员,那么日志D不会被找出来,这样就需要将3号成员的log id=4日志置未一条无操作的日志记作NOP日志,D最终也就不会形成多数派。由于multi-paxos允许日志乱序接收,并且日志的长度几乎都不一样,所以在磁盘上log id是乱序的,所以从物理上说,每个成员的日志不是一模一样的。那么要把log id=4的日志覆盖写成NOP日志也就比较麻烦,需要为每条日志维护索引。实现上可以不覆盖写,直接append一条log id=4的NOP日志到日志文件,这样没有问题,因为回放的时候只会回放能找到确认日志的日志到上层应用中。
成员变更
multi-paxos处理成员变更比较简单,规定第i条日志参与paxos同步的时候,其成员组是第i-k条日志包含的成员组(每条日志里面都包含成员组)。
multi-paxos协议之外
multi-paxos只是保证大家对日志达成一致。但是具体multi-paxos运用到真实的系统中时,从应用层面上看,可能会出现一些诡异的问题。考虑如下场景:
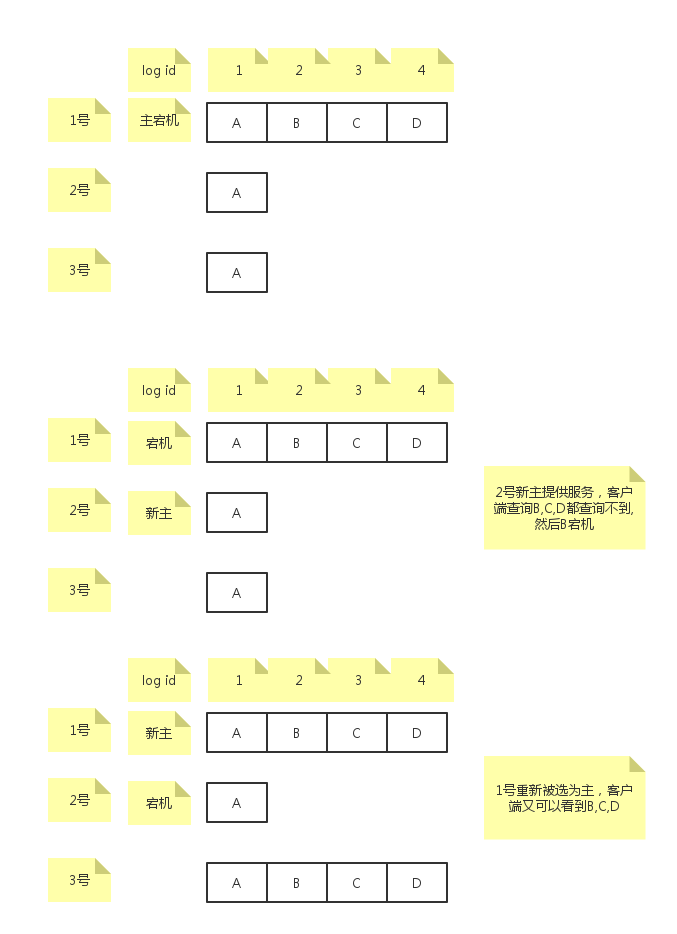
如图,1号主写了A,B,C,D,其中B,C,D没有形成多数派,然后A宕机了,2号被选为了主,客户端过来读不到B,C,D,然后B没写任何东西,就挂了,这个时候,A起来后重新被选为主,对B,C,D重新运行paxos,把B,C,D达成了一致,这个时候客户端再次过来读,又能读到B,C,D了。对于multi-paxos本身来说,并没有什么不对的地方,但是上层应用的语义出现了问题:曾经读不到的东西,什么都没做,又能读到了。
解决这个问题的方法是通过主提供服务之前必须成功写入一条start working日志来解决。如下图:
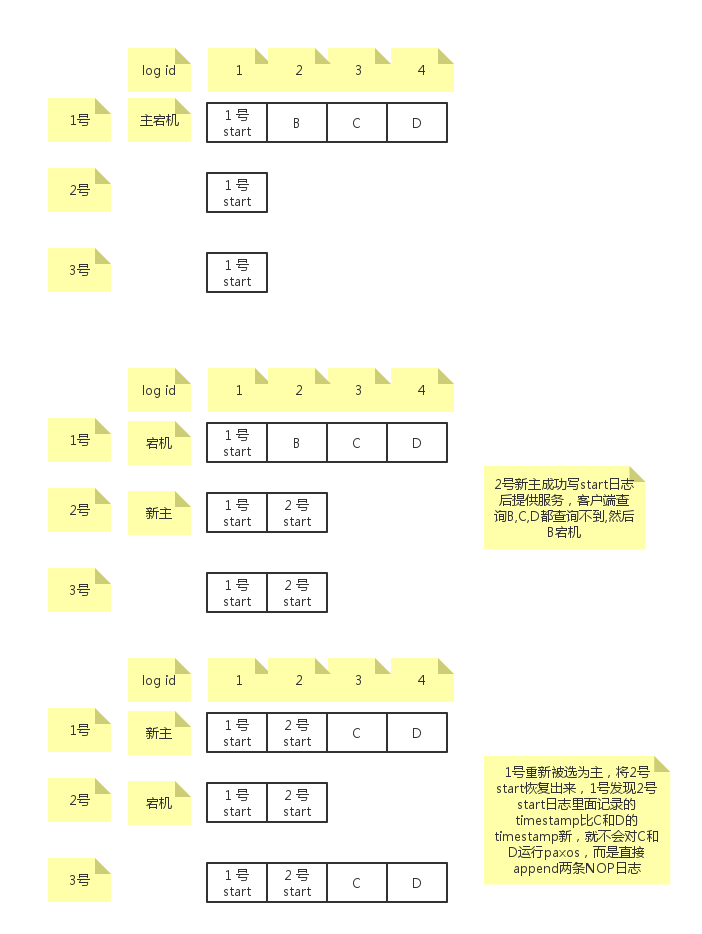
如图,每个成员成为主提供服务之前都要首先写一条start working日志,只有达成多数派才能提供服务。1号在重新成为主之后,通过对log id=2的日志运行paxos,将2号start日志恢复了出来,然后对C和D运行paxos恢复出来后,后续回放的时候,如果发现后面日志中带有的timestamp(其实时leader上任时间)比start working带有的timestamp更小,那么就不回放到上层。随后客户端来读仍然读不到B,C,D,前后保持一致。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号