Python爬虫 #013 Selenium常用操作
selenium常用于自动化测试,其解析标签可以使用xpath语法,selector语法,还有自身的用法,以及对浏览器进行一些操作。
目录
1. 分析标签
-
要爬取的网址:http://www.baidu.com
-
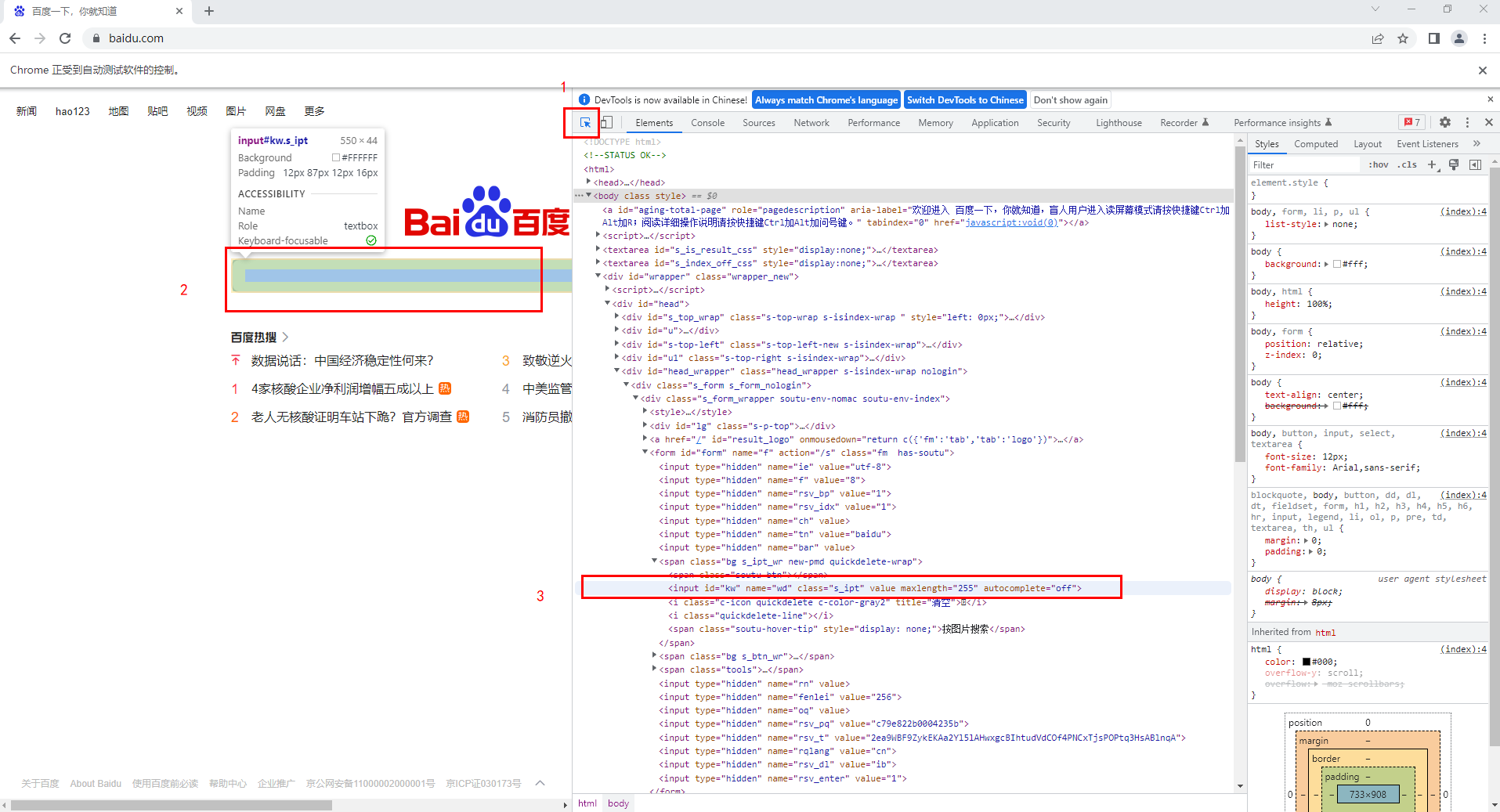
通过属性(也叫审查元素)查看标签属性,选中1号区激活选择箭头,点击2号区后,网页自动高亮此部分代码(3号区)
通过观察可得知该标签input id="kw",name="wd",class="s_ipt"
2. 解析标签
-
根据上面的分析,我们得知标签的一些属性:
input id="kw",name="wd",class="s_ipt" -
implicitly_wait(): 为隐式等待,程序的运行非常快,如果当前网络延迟较高,网页还没加载出来,就直接解析标签会报错。implicitly_wait(10):表示最多等待10秒再执行下一句。
from selenium import webdriver
# 启动浏览器,访问网址
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
# 隐式等待10秒
implicitly_wait(10)
# 通过id方式定位
driver.find_element_by_id("kw")
# 通过name方式定位
driver.find_element_by_name("wd")
# 通过tag name方式定位
driver.find_element_by_tag_name("input")
# 通过class name方式定位
driver.find_element_by_class_name("s_ipt")
# 通过selector方式定位
driver.find_element_by_css_selector("#kw")
# 通过xpath方式定位
driver.find_element_by_xpath("//input[@id='kw']")
# 等待3秒,关闭浏览器
time.sleep(3)
driver.quit()
3. 常用的自动化操作
| 方法 | 功能 |
|---|---|
| driver.maximize_window() | 窗口最大化 |
| driver.minimize_window() | 窗口最小化 |
| driver.set_window_size(w,h) | 设置窗口宽,高 |
| driver.forword() | 前进 |
| driver.back() | 后退 |
| driver.save_screenshot(path) | 截屏,保存到path |
| driver.close() | 关闭当前页面 |
| driver.quit() | 关闭所有页面 |
| driver.save_screenshot(path) | 截屏,并保存到path |
| driver.send_keys(str) | 往输入框填写数据 |
| driver.click() | 点击标签 |
4. 案例
4.1 截屏并保存
from selenium import webdriver
url = 'https://www.baidu.com/'
# 如果驱动程序在python根目录,可以省略路径
driver = webdriver.Chrome()
driver.get(url)
# 窗口最大化
driver.maximize_window()
# 截屏并保存
driver.save_screenshot('1.png')
# 关闭所有页面
driver.quit()
4.2 输入并搜索
from selenium import webdriver
import time
url = 'https://www.taobao.com/'
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(10)
# 找到搜索框并输入数据(mac)
driver.find_element_by_xpath('//input[@id="q"]').send_keys('mac')
# 找到搜索按钮,并点击
driver.find_element_by_xpath('//button[@class="btn-search tb-bg"]').click()
time.sleep(3)
driver.close()
4.3 多页面操作
from selenium import webdriver
import time
url = 'https://www.douban.com/'
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(10)
# 通过链接属性中的文字内容定位标签
book = driver.find_element_by_link_text('豆瓣读书').click()
time.sleep(3)
# 获取窗口数量,得到列表
windows = driver.window_handles
print(windows)
# 切换到第二个窗口
driver._switch_to.window(windows[1])
# 解析第二个页面的数据(如果不切换,还停留在上一个页面,下面的解析可能会报错)
music = driver.find_element_by_xpath('//*[@id="db-global-nav"]/div/div[3]/ul/li[4]/a')
print(music)
music.click()
driver.quit()
time.sleep(2)
4.4 浏览器滚动条操作
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://www.douban.com/')
driver.implicitly_wait(10)
# 最大化窗口
driver.maximize_window()
time.sleep(2)
# 滚动到底部
driver.execute_script("document.documentElement.scrollTop=10000")
time.sleep(2)
# 滚动到顶部
driver.execute_script("document.documentElement.scrollTop=0")
time.sleep(2)
# scrollTo(x,y) 横向移动到x,纵向移动到y。若浏览器没有横向/纵向滚动条,则设置不会生效
driver.execute_script("window.scrollTo(200,500)")
time.sleep(2)
# 解析元素
ele = driver.find_element_by_xpath('//*[@id="anony-time"]/div/div[1]/h2/a')
time.sleep(2)
# 移动到元素的‘低端’与当前窗口的‘底部’对齐
driver.execute_script("arguments[0].scrollIntoView(false)", ele)
time.sleep(2)
# 移动到元素的“顶端”与当前窗口的“顶部”对齐
driver.execute_script("arguments[0].scrollIntoView(true)", ele)
time.sleep(2)
driver.quit()
5. 添加浏览器设置
- selenium是直接对浏览器进行控制的,在控制前可以对浏览器进行一些属性设置,如静音设置,添加代理(请求头 / ip代理)等
5.1 静音设置
- 当浏览器浏览的页面含有视频时,可以设置静音,使得视频播放没有声音。示例中需手动播放视频
from selenium import webdriver
from selenium.webdriver import ChromeOptions
import time
url = 'http://news.mtime.com/2020/03/08/1601614.html'
# 添加设置:取消页面内的声音
options = ChromeOptions()
options.add_argument('--mute-audio')
driver = webdriver.Chrome(options = options)
driver.get(url)
driver.implicitly_wait(10)
time.sleep(30)
driver.close()
5.2 设置代理
- 由于selenium更新,示例中添加ip代理的方法已经不适用
from selenium import webdriver
# 该网址能查看访问的ip,请求头
url = 'http://httpbin.org/ip'
# url = 'http://httpbin.org/user-agent'
# 这里的请求头不是键值对!
headers = ("Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20")
options = webdriver.ChromeOptions()
# ip代理需有效,否则浏览器显示网络连接超时!
options.add_argument("--proxy-server=http://106.60.70.243:80")
options.add_argument('user-agent=%s'%headers)
driver = webdriver.Chrome(chrome_options=options)
driver.get(url)
driver.implicitly_wait(10)
6. selenium 行为链
- 有些网站可能会在浏览器做一些验证行为是否符合人类的行为的反爬虫手段,这时候我们就可以使用行为链来模拟人的操作。行为链有更多复杂操作,比如双击,右键等
- 其他操作
- click_and_hold(element):点击但不松开鼠标。
- context_click(element):右键点击。
- double_click(element):双击。
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
# 定义两个元素标签
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
# 先把driver放入ActionChains()中生成一个新的对象
actions = ActionChains(driver)
# 将鼠标移动至inputTag标签上
actions.move_to_element(inputTag)
# 向inputTag标签发送关键词
actions.send_keys_to_element(inputTag, 'python')
# 将鼠标移动至submitTag标签上
actions.move_to_element(submitTag)
# 执行点击事件
actions.click()
# 行为链执行
actions.perform()
本文来自博客园,作者:{枫_Null},转载请注明原文链接:https://www.cnblogs.com/fengNull/articles/16629583.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号