


ccie service provider 学习笔记 6 组播
2023-04-09 13:13
Video 76
重点在组播vpn上


如何识别网络类型是ptp还是广播型?通过接口的二层封装协议,ex: ppp和hdlc。
在ptp的网络中,只有两台设备,不需要mac地址。不管是用ppp还是hdlc封装,帧头里都没有mac地址。如果我想给对方发送数据帧的话,只需要从这个if上发送出去就ok了。mac属于物理地址,用于唯一标识一台设备 。
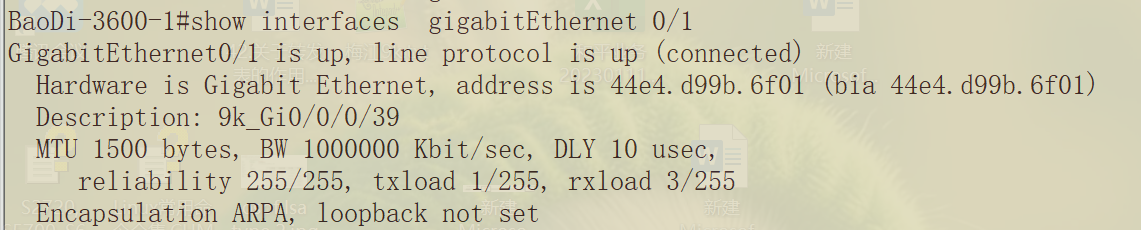
广播网络(可理解为点到多点,多点到多点),802.3和ethernet 2,以太网的封装就是ethernet 2.而在cisco设备上show interface,显示接口的封装协议是arpa=ethernet 2
在广播类型的网络中,因为一个链路连接了多台设备,就需要mac地址来唯一标识一台设备。所以说mac只存在于广播类型网络中-因为要实现广播类型网络内的点到点的互通。
二层广播地址-全f;三层广播地址-全255。3层广播地址还分为全局广播地址和定向广播地址(只是发给一个网段内的所有设备)
想要保证数据只发送1份,同时保证可以选择谁接收数据-使用组播
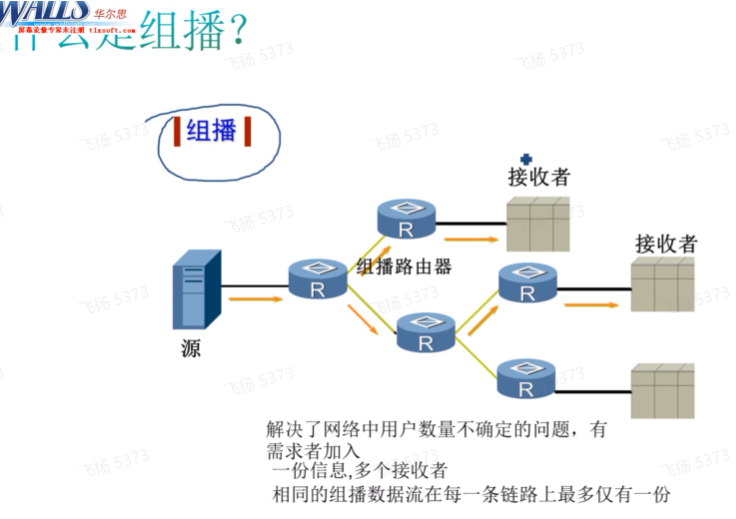
接收者想接收这份数据,必须要提前加入到组中。后期是向这个组播地址(DIP)去发送数据,而只有在这个组播组中的成员才能接收到数据。有了组播之后就可以实现精准的数据传输。
组播的优劣
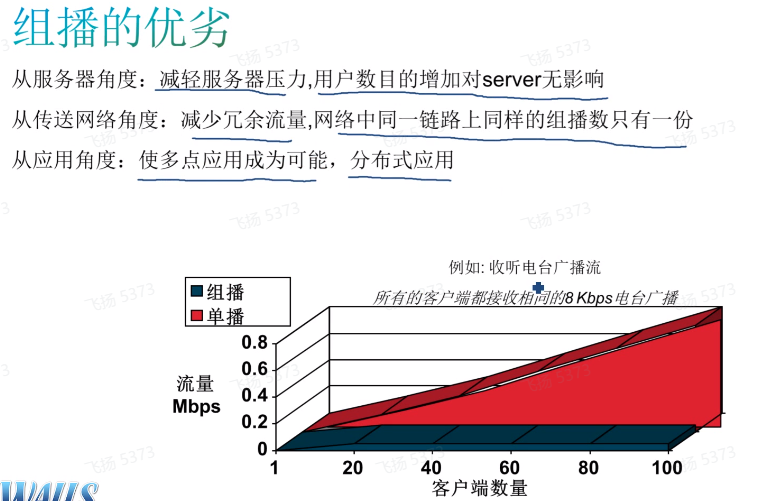
分布式应用,指可以多个接收者同时接收数据,更多应用在iptv上,证券交易所的实时数据变化
组播的劣势在于网络设计上,网络设计可能导致组播流量的延时增加或者丢包。
sp上组播部署的话,主要用在iptv。(广电应用在直播ip化上)当前cisco和华为的视频会议用的不是组播,因为组播是需要运营商来帮你去转发组播流量,但sp现在并不会帮客户转发组播流量。(但是sp要转发我自己的组播业务流量,如iptv)

TCP在丢包会进行重传,重传虽然可以保证数据的可靠性,但会带来带宽的重复利用。如果tcp里有大量丢包的话,就需要把数据进行大面积的重传,会导致数据的重复发送,而带来带宽的下降。//保证可靠性,但是降低效率。
组播的业务都是基于实时应用的,ex音频或者视频业务,这种类型的业务除非丢包太多,延时太大,才会影响到业务。udp会导致端口的拥塞,如果组播的带宽超过了端口的带宽,就会造成端口的拥塞,并且udp没有慢启动机制。
so在实际使用中,需要计算好组播流量由多大,再去预留相应的带宽。另外针对实时应用,需要进行优先转发-需要保证50ms的转发延时,这样就需要为组播业务打上不同的优先级,在端口拥塞时,优先转发高优先级的实时组播业务。
-----------------------------------------------------------------------


ABC是单播ipv4的主类地址,d是组播地址,e是实验地址范围
A段地址范围中,0是保留地址,用于代表所有网段。而127是环回测试地址,可以通过这个地址测试你的tcp/ip协议栈是否正常。
在pc cmd下ping 127.0.0.1正常通(这个127整个网段里的所有地址都可以ping通的-用于回环测试),是说明网卡的上层协议栈是正常的,而不是测试网卡是否正常-网卡上有如下很多协议栈,只有安装正确了才可能ping通
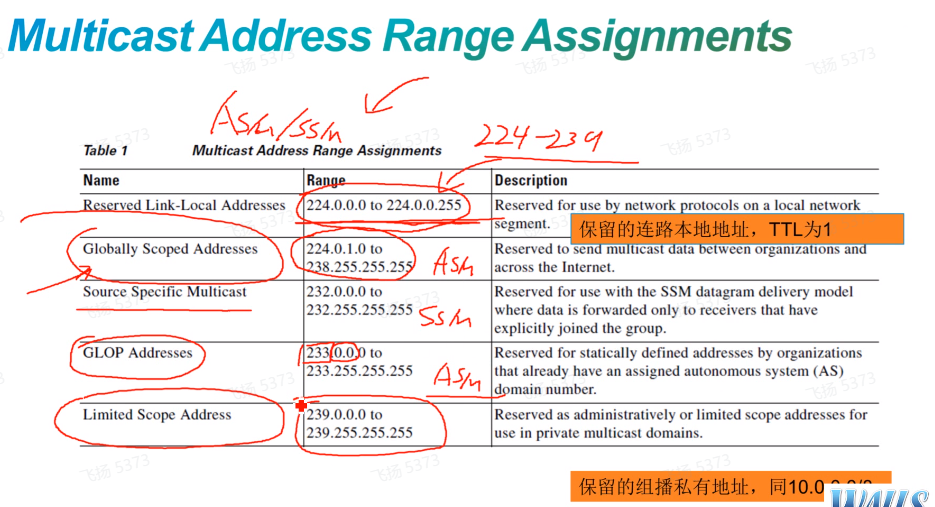
组播地址范围的细分:
asm和ssm称为组播模型。Asm-任意的组播源都能向这个组播组提供流量;ssm在加组时指定你想要接受流量的组播源地址
第一段地址范围,永久组播地址用于路由协议预留
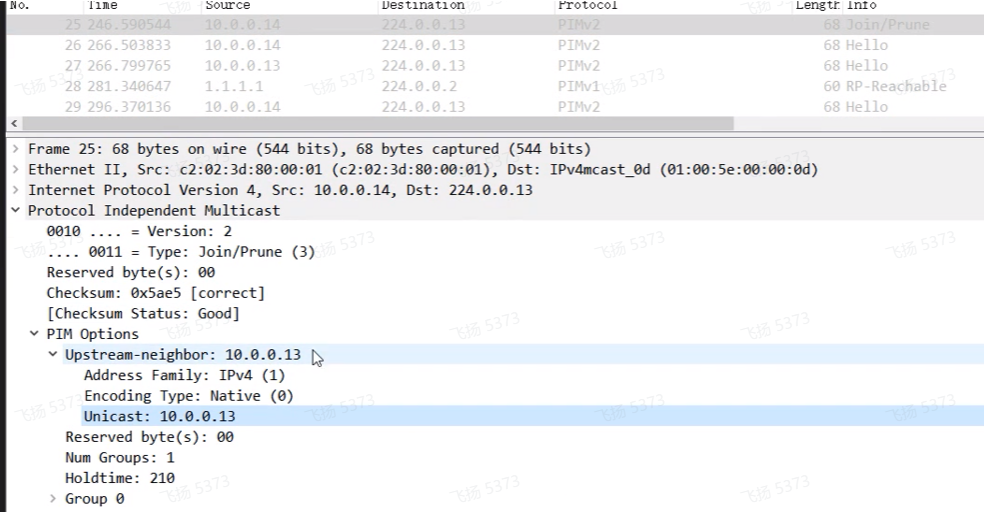
2/3/4都是临时组播地址
Glop address,可以在地址内嵌入bgp的as no,中间两个字节(0.0)适用于映射bgp的as no。因为其只能映射两字节,就只能用于2B的as no
Limited scope address 属于保留地址范围,类似于私网地址

周知的组播地址,0.5/6 属于ospf,0.9是rip,10是eigrp。
以上ip报文在发送时,都会将ttl设置为1-因为这种组播的主要作用就是同一个网段内的组播发现/使用,是不会跨网段的

在组播地址里每一个地址都可以代表一个组,没有网络位和主机位的概念。网络位和主机位的区分主要用在单播地址上-因为在广播网络里,有两个特殊的地址需要保留,1是主机位全0,1是主机位全1。全0代表这个网段,而全1代表这个子网全部的设备-定向广播地址。

233地址,利用中间的2B来映射bgp的as no

第二节 组播mac地址


买的这个mac地址,oui部分就是01005e,然后老板把第25b 为1 的部分拿走,只为组播留下了01005e0…的23b,28(ipv4组播ip的28bit变换位)-23(组播mac变化位)=5位,造成2的5次方32个ipv4地址映射到同一个组播mac(把28个bit映射为23个bit会造成最前面5gbit的丢失)
Ipv6中解决了该问题,ipv6组播地址只用到了前16个bit,即3333::开头的,来代表ipv6的组播ip,把后面32b用来映射ipv6的组播地址。在ipv6中group的长度正好是32位,而mac也是剩余了32位,就可以保证ipv6地址和mac地址之间1:1的映射关系(如下图:)
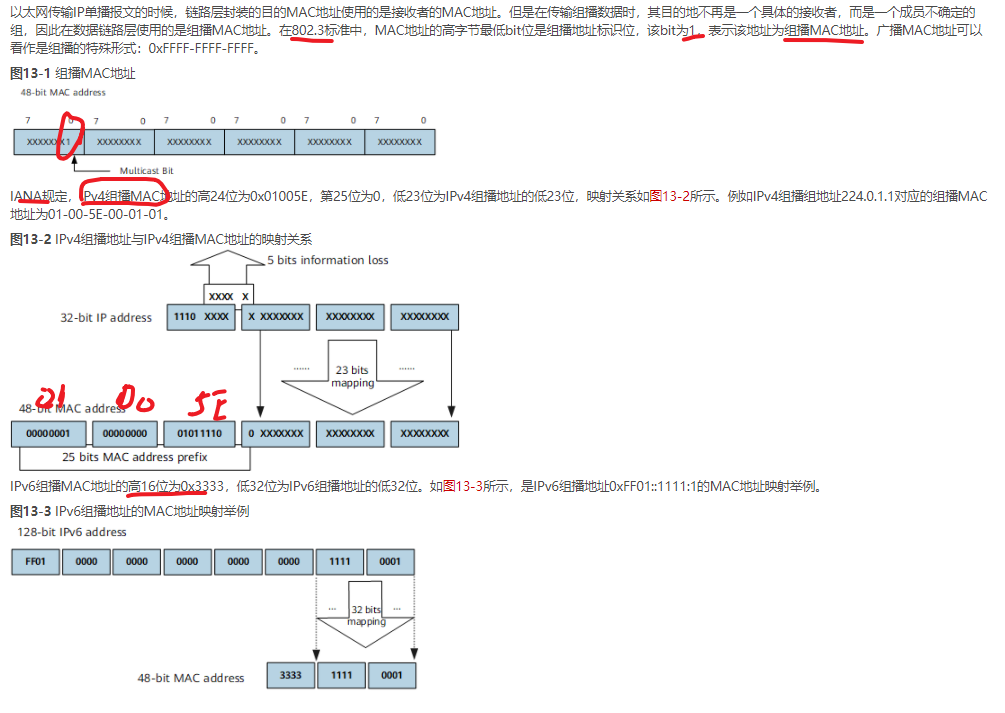
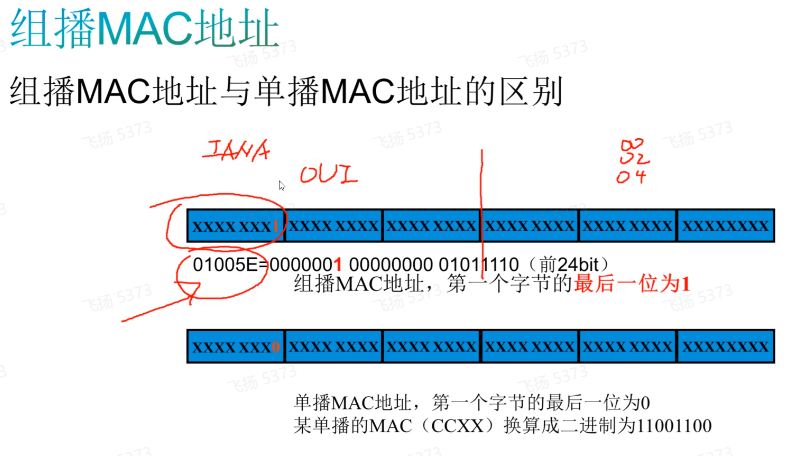
oui部分需要向iana申请,各厂商之间是不同的

01005e只是代表从ipv4组播ip所映射的组播mac地址(即Ipv组播mac地址),并不是说所有的组播mac都是01005e。比如01-80-c2-00-00-00:这个前3B就代表了stp。如下二层协议是通过二层组播进行传递的:stp,ldp,cdp。
----------------------------------------------------------
2023-04-09 20:39
Video 77
第三章 组播分发树

就是spt和rpt树(看,就是组播路由表)
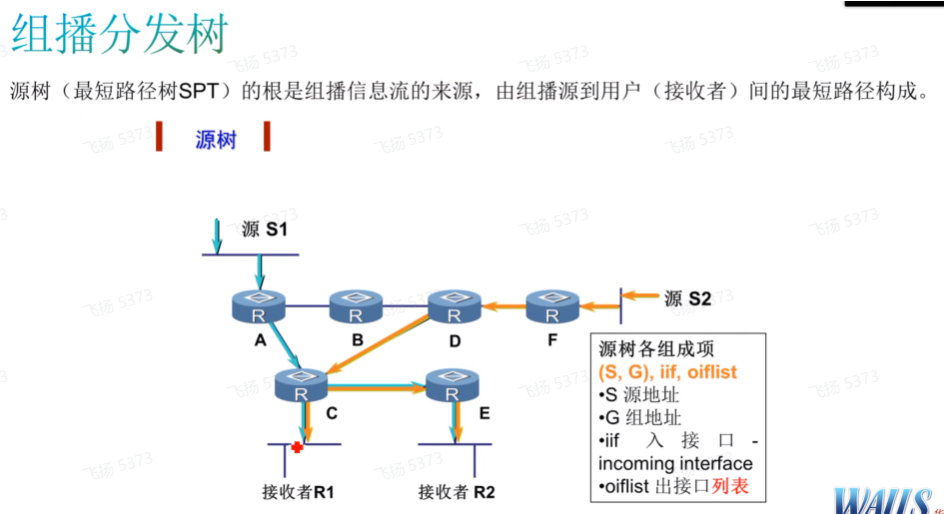
源树:指接收者到达组播源的最短路径树。上图的两个接收者会分别计算自己到达组播源的最短路径,然后通过最短路径来接收组播流量。
Iif-incoming if(接收组播流量的if);oiflist-outgoing if list(发出组播流量的if)
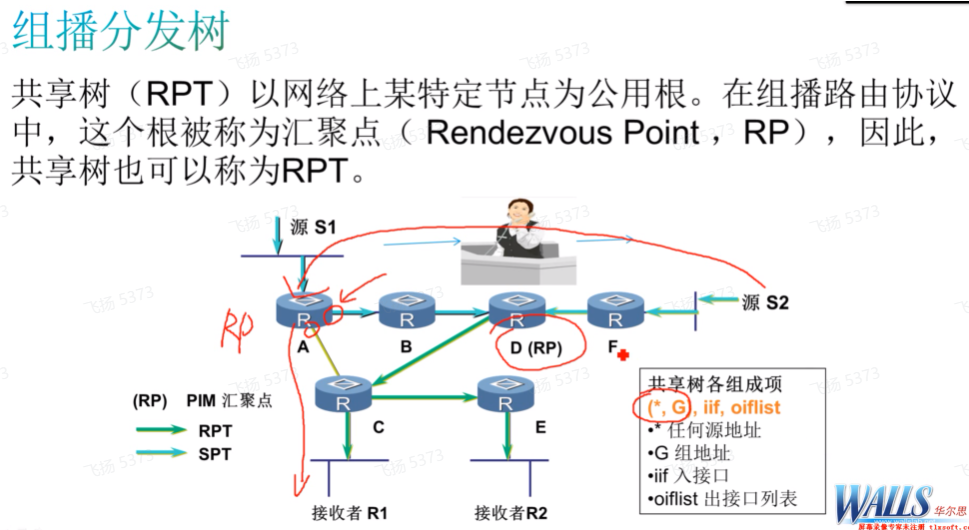
rpt主要用在pim-sm的网络中 ,*代表任意源。(该网络中接收者较少,需要用到拉的方式。同时需要构建从rp到接收者的spt树)
而pim-dm网络中接收者较多,需要用到推的方式,直接构建spt树

---------------------------------------------------------------------------------------------------------
第四章
组播数据的转发

在转发组播数据时,为了避免组播流量的环路,需要使用反向路径的检查,即rpf检查-针对组播源进行检查。
在pim中,可以在多个位置进行rpf检查。ex在接收到组播流量后,通过rpf检查来确定接收组播流量的接口和到达组播源的出接口是否是同一个,如果是同一个则组播流量才有效,如果不是一个则丢弃,通过该方式避免了组播流量转发环路问题;rp,在配置rp时,会有动态rp的分配方式,在这种场景中需要针对bsr和rp进行rpf检查(本质就是通过rpf选路原则计算到达rp、bsr、组播源的上游pim邻居和up if)。即 rpf检查不光是用在组播流量上,针对其他一些检查也会用到rpf检查
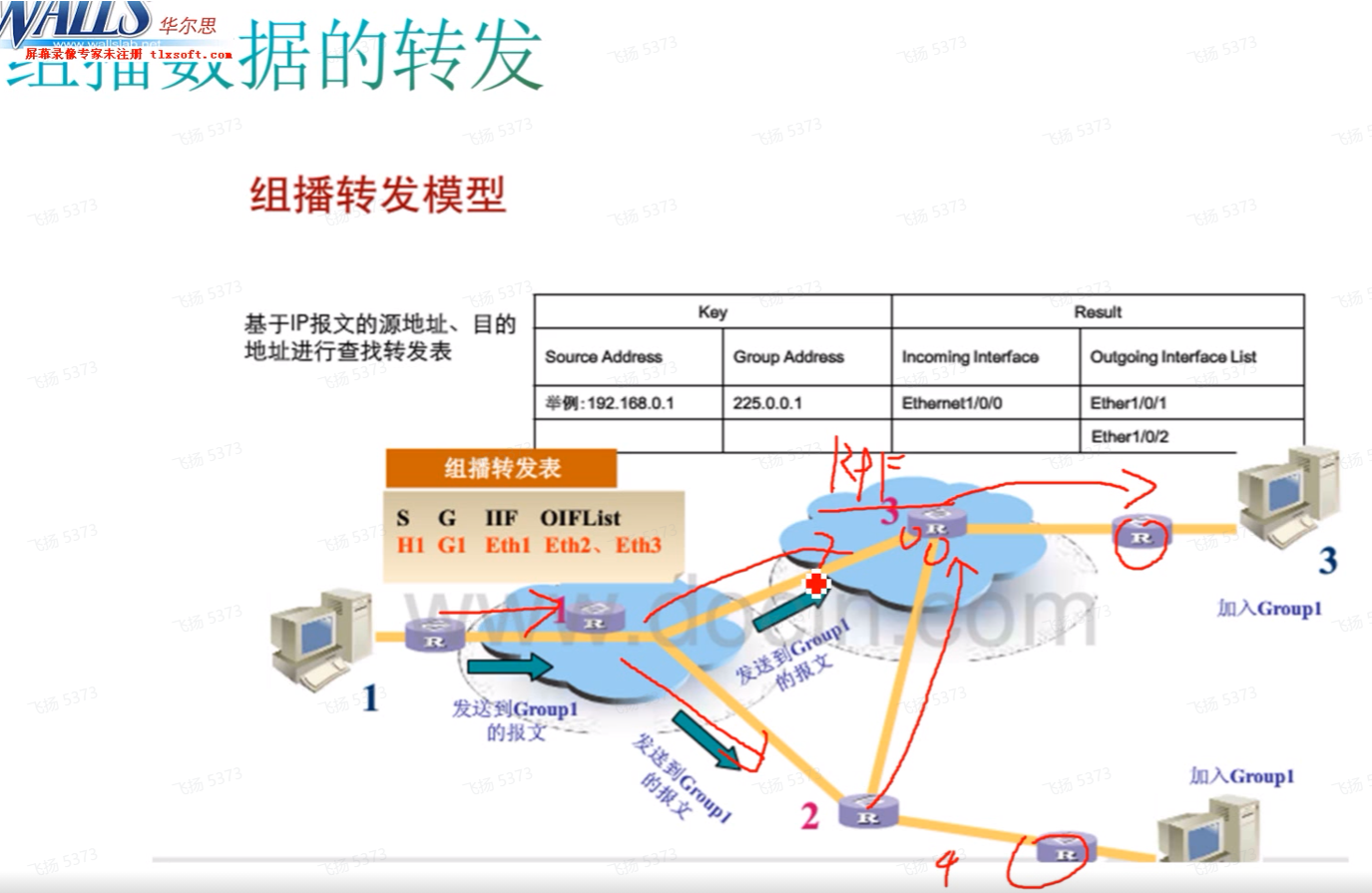
上图3从1和2都收到组播流量,就会针对这个组播源进行rpf检查-接收组播流量的入接口=到达组播源的出接口,流量可以正常接收并进行转发,否则则丢弃。

通过rpf检查:1可以避免组播流量环路的问题;2.避免组播流量重复的问题。rpf检查顺序详细版见下:

mbgp是一个独立的地址族,只是用于组播路由选路的。
cisco的eigrp可以实现非等价负载分担。就算在两条路由条目的metric值不一样,也可以通过非等价负载分担的方式实现负载分担。在这种场景就需要比较metric值,越小越优。
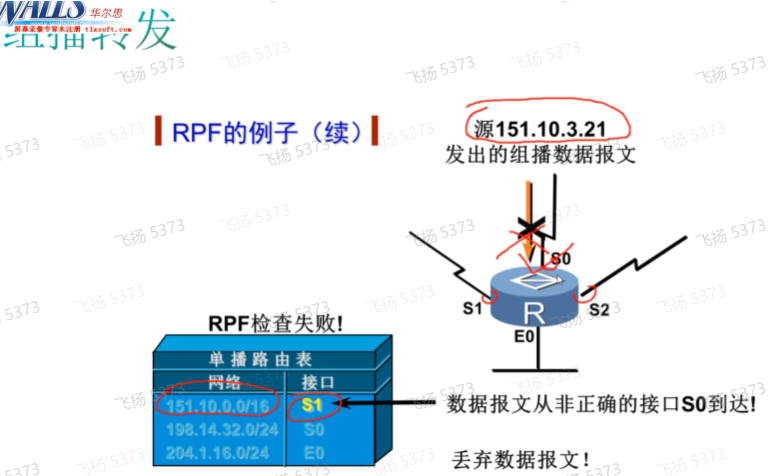
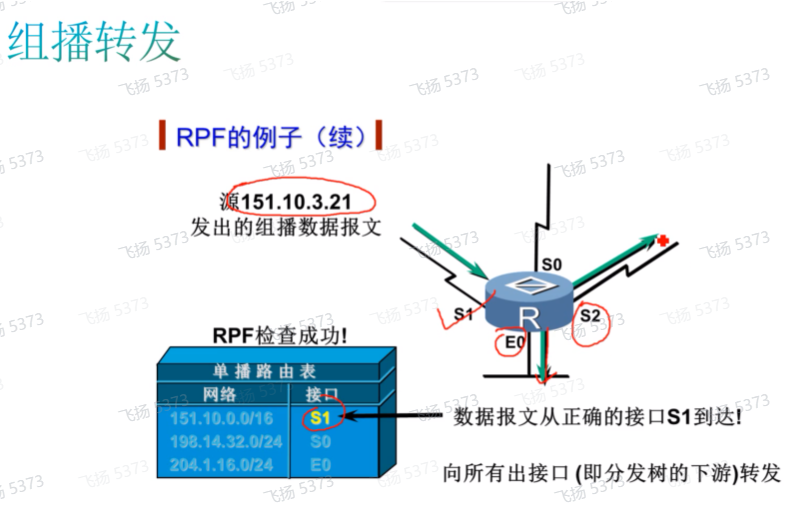
组播基础部分里最重要的就是rpf的检查顺序
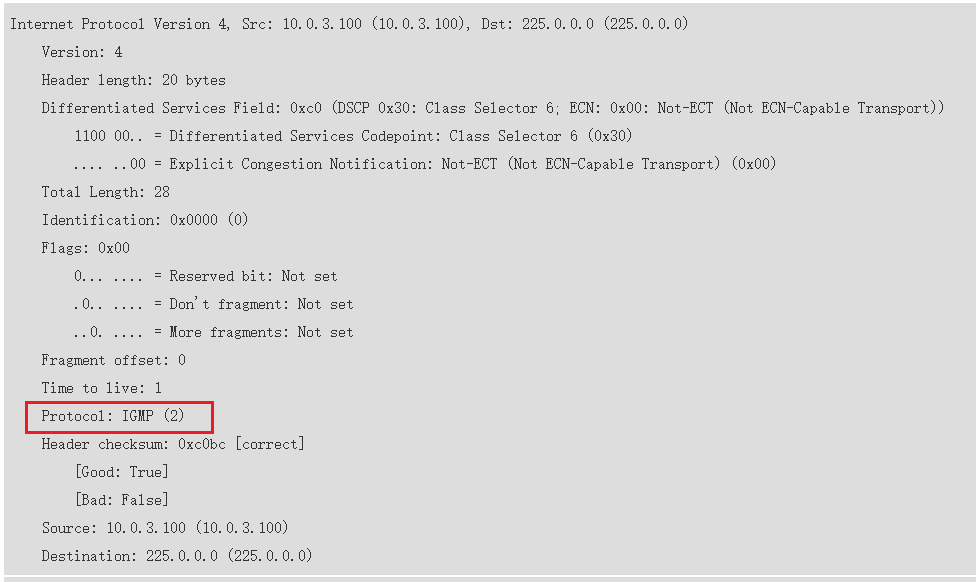
igmp协议原理,protocol id为2//icmp为1
构建组播转发表项所需要的协议
ping本质就是icmp,在ping的时候,是向对方发送icmp 的request,对方接收到只会回复icmp的response,通过这种收发的方式来确定源宿之间的连通性。Protocol id 为1
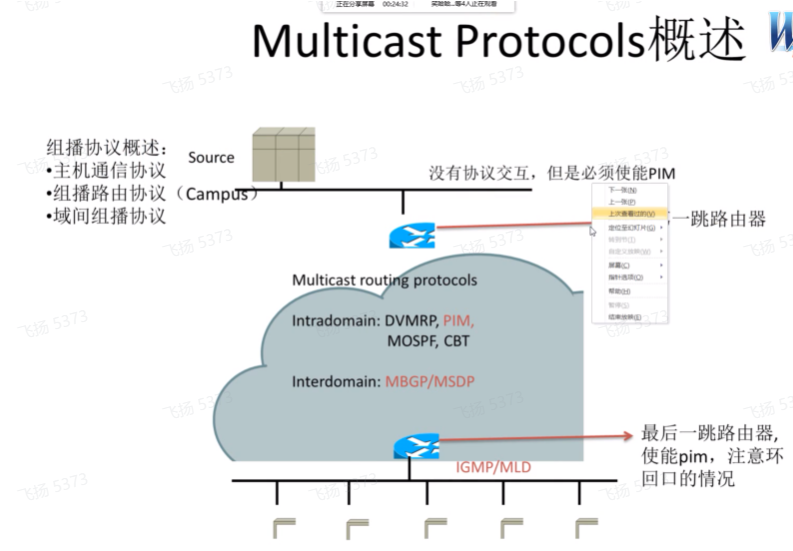
连接客户的路由器称为叶路由器-leaf router,连接组播源的路由器称为firs hop-router。叶路由器和接收者之间需要运行协议,进行加组(引出igmp协议)。
Ipv6中使用mld协议进行主机加组,multicast listener discovery。
只有叶路由器知道有哪些接收者,需要接收哪些组播流量。叶路由器和组播源是不通的,只有第一跳路由器才知道组播源是谁。想要在第一跳路由器和叶路由器之间转发组播流量,需要在两者沿途经过的路由器上配置一种协议,来构建从第一跳路由器到叶路由器之间的组播转发表项。
域内-同一个组播域内:可以部署上图dvmrp、pim…。类型6的lsa是用在mospf中。dvmrp属于距离矢量的组播路由协议,类似rip,通过距离矢量的方式构建跳数最短的组播转发路径。
pim的目的是构建组播转发表项,其转发路径的建立依赖于底层igp协议,需要通过igp协议来计算从fh r到达leaf r的最短路径。协议无关-指底层的igp可以用isis、rip都可以。
在组播跨域场景中,需要用到msdp:组播源发现协议,实现跨组播域源信息的通告。在不同的组播域有不同的rp,在不同的rp上需要交互组播源的信息,来实现跨组播域的流量转发。上图的mbgp写错了(即mbgp不能实现跨域的组播通信),mbgp通告的路由,只是用于组播rpf路由检查/组播路由选路(//这就是rpf的第二个功能)

cbt已经不用了

sfm还是属于asm,只不过相当加了acl进行过滤。

Igmp v1

Query-叶路由器通过查询报文,定期查询这个组播组是否还有成员存在。通过query来维护叶路由器和接收者之间的组关系。未使用的8b在v2中被使用
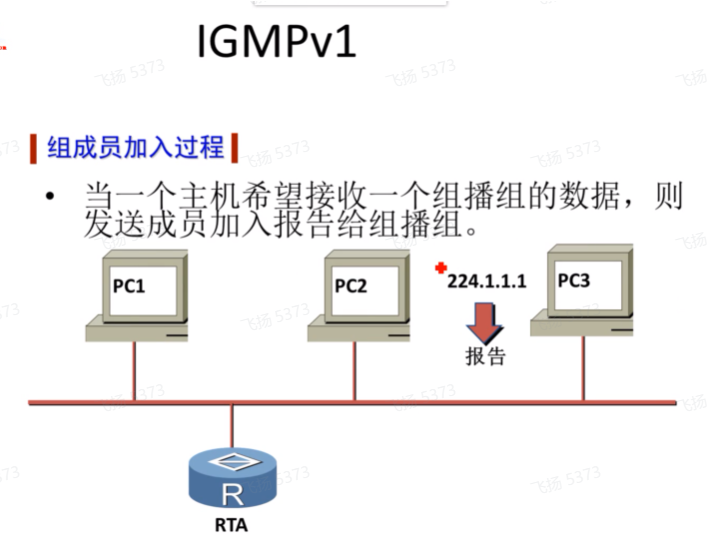
report报文内填充的组地址即为要加入的组地址224.1.1.1,前封装的ip头部的dip是加组的地址224.1.1.1,而不是224.0.0.2(所有开启组播功能的路由器 )。引出组成员报告抑制功能。
叶路由器在收到report报文后,如果该if开启了igmp功能且版本要高于报文的igmp版本,都是可以分析报文的(除了v3),然后在本地维护一个组播的表项(不是组播路由表,而是igmp组播表-在这个表项中会维护这个组和接收者之间的关系)
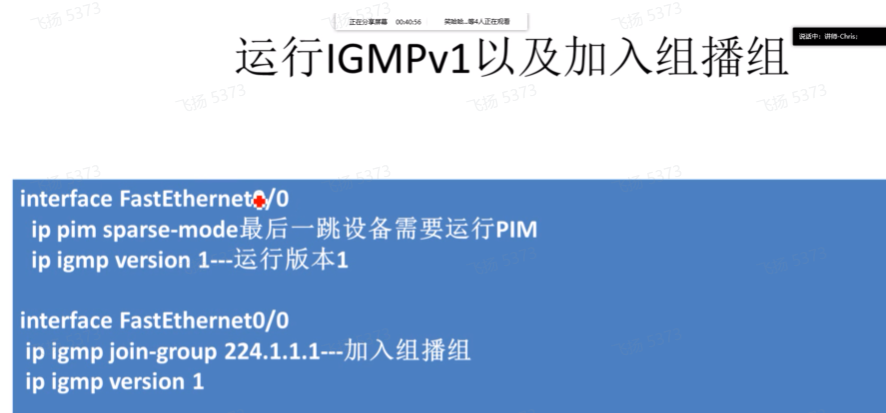
上面是叶路由器配置的,下面是在接收者配置。
上图把叶路由器同时作为了接收者和叶路由器使用
如果上图不配置pim,则不影响igmp,相应的功能还是可以实现。但这个接口不能作为组播路由的出接口来使用,so这个必须要开的,//华三就不是这样,下联口不需要配置pim
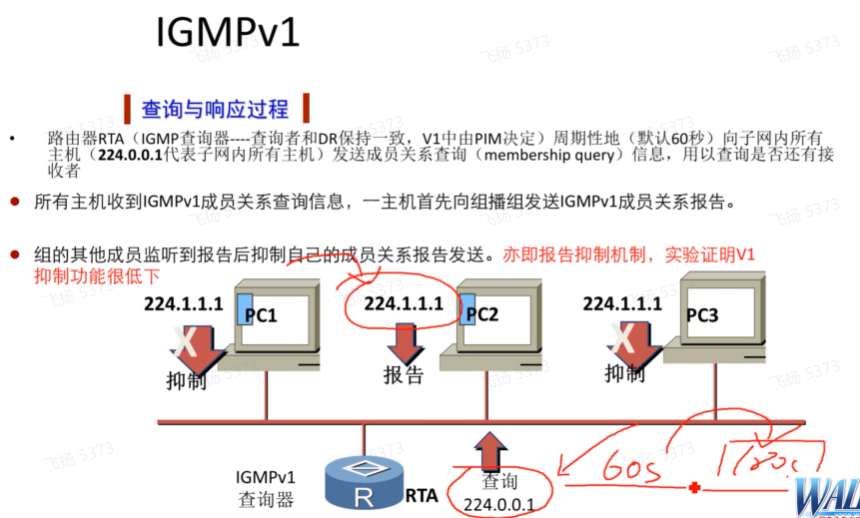
接收者发送的组成员报告封装的ip头部的dip为要加入的组播组地址。叶路由器会周期性60s发送通用组查询(cisco时间写死了,holdtime为3*hello=180s,其他厂商没有),目的:查询这个组播组中是否还有接收者存在,如果180s内我发送了3次通用组查询,都没有收report报文,则认为该组没有任何成员了,删除该组。
路由器维护igmp组关系的老化时间是180s

dr在pim-sm中的作用,就是由谁来转发组播流量。如果在pim-dm中,dr只是用于igm v1 的查询者来用
Last reporter:这个组是由谁最后一次加组的

组成员报告的ip头部封装的dip使用需要加入的组播组地址,是为了实现组成员之间的抑制功能
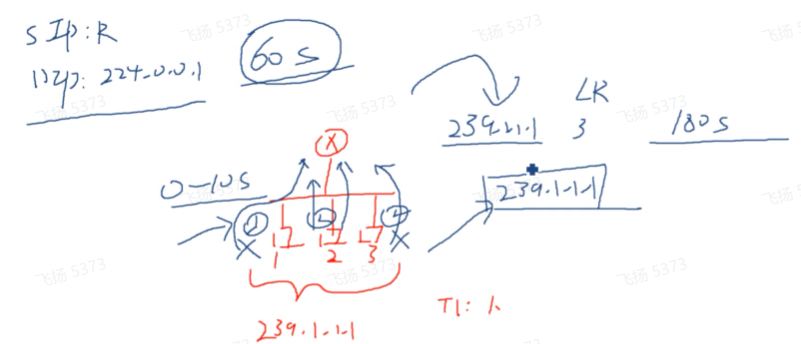
在接收者首次加组时,都会发送report报文。路由器会每隔60s发送一次query报文(通用组查询-发给所有组的,dip就是224.0.0.1),通过其来维护组关系。3台设备在同一个组内,且都会接收到通用组查询,如果都回复-没有必要(路由器只关心这个组播组有没有人,不关心你有几个)
成员在接收到通用组查询后,先起一个定时器随机计算个时间(0-10s之间),然后发送report进行响应--说明所有接收者并不是同一时间回复report,他们之间存在时间差。1/2/3接收者最先超时的人,会先回复report,如果这个report的dip是224.0.0.2,就只会是路由器可以收到,其他接收者收到后也会丢-因为这个地址不是我的,其他接收者定时器超时还是会回复report报文,这就无法起到抑制的功能。
而如果dip是要加的组地址,其他接收者在收到后,因为都在这个组内,就会分析该报文,判断是igmp的report报文,已经有人告诉路由器这个广播网内需要该组播组的流量了,这就存在report报文的抑制功能。
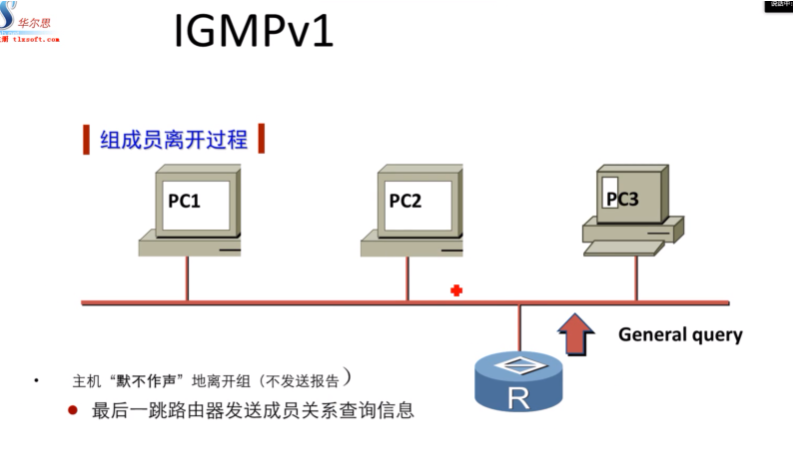
后期组成员不想再接收组播流量,就不会再回复report报文了。在igmp v1中,接收者离组,并不会主动告诉路由器。路由器只能通过60s查询是否还有组成员。3倍hello,这就有个180s内,路由器还认为该组还有人,就会继续向该组转发组播流量-浪费带宽和性能。

--------------------------------------------------------
2023-04-10 14:09
Video 78
Igmpv2
Igmpv1的问题,接收者被动离组,造成路由器仍需发送组播流,直到180s超时 -引出v2

V1和v2的组成员报告版本不一致

默认为10s,v1在回复report报文之前,先启动定时器(0-10s随机)。而v2是可以设置这个响应时间范围的:如下

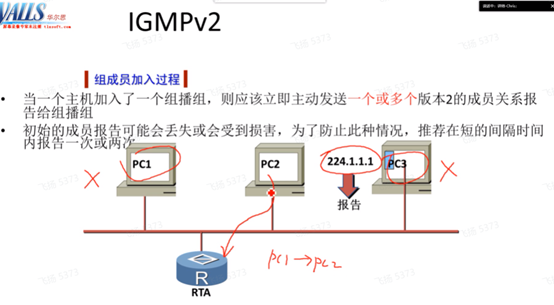
封装的目标ip为需要加组的地址
在叶路由器每隔60s发送一次通用组查询,定时器先老化的主机先回复report,使得叶路由器上记录的last reporter进行修改。
在last report(我发送了report肯定知道)而离组时要发离组报文(因为别人的report报文被我抑制了)。非last reporter离组时不会发送离组报文,因为他不是last reporter,并且收到了其他接收者发送的report-证明这个组里不光自己存在
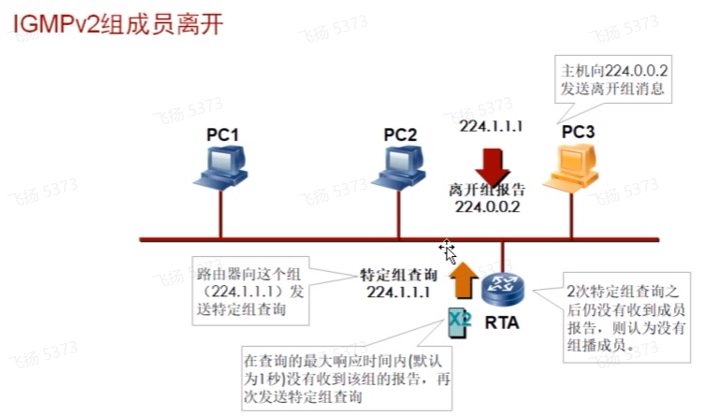
在接收到离组报文后(组地址为离组的地址,dip是 224.0.0.2-所有开启组播协议的路由器),为了避免误删,路由器会进行指定组查询(组地址为组地址,dip为224.0.0.1-所有设备),并把特定组查询报文的max response timer默认的10s,改为1s-加速让接收者回复report。且特定组查询默认会连续发送两次-为了保证可靠性,避免因拥塞导致的丢包。这个数值叫健壮系数,也可以改。
接收者在接收到指定组查询后,会在本地启动定时器,0-1s内取值,计时器到期后就会向路由器回复report,如果路由器能接收到report,就说明这个组里还有接收者,路由器需要继续维护组关系。如果在发送两个特定组查询后,都没有收到任何的report,就说明组里已经没有人了,就将组删掉。V2里只需2s就可能知道组里还有没有其他人。V1需要180s
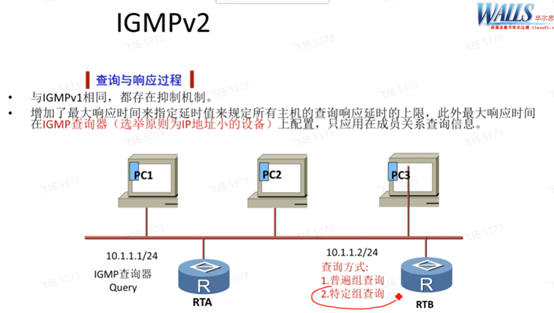
上图的情况就是需要确定由谁来发送查询报文(在同一个广播网中,存在多台组播路由器的情况下)。V1是没有查询器选举机制的,是使用pim的dr来充当igmp的查询者使用。

由查询者进行通用组查询,而非查询者会监听查询者的状态,有一个老化时间

非查询者上也会维护组关系(避免查询者挂了之后,非查询者不知道有哪些接收者存在,无法转发组播流量)。 Group hold time-组的老化时间,所以非查询者查询查询者的老化时间要小于组的老化时间,能够先发现查询者挂了,然后马上发送query,来更新组的老化时间,来维护组关系,这样就能实现流量的平滑切换。
接收者只有在第一次加组时,以及收到query时才会发送report
--------------------------------------------------------------------------------------------
2023-04-11 13:10
Video 79
cisco的关于v3的介绍少,so使用华为的文档
如果中间互联的交换机开了igmp snooping后,则成员报文抑制功能会被自动关闭。因开启snooping之后,sw上成员端口状态的保持时间,是通过这个端口收到report后才会去更新的保活时间,如果存在抑制机制,就会造成成员端口因接收不到report报文,而被老化,接收者接收不到组播流量
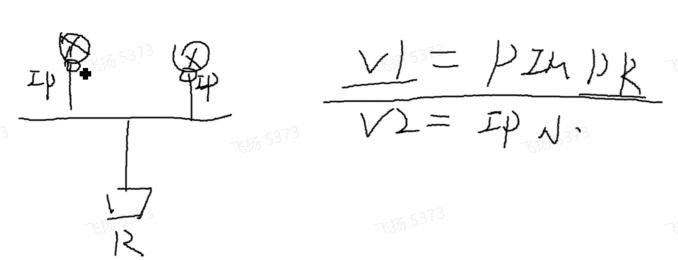
Igmpv2的问题:在上述场景中,不能让两台路由器都去发送查询报文,需要选举出igmp查询者。V1使用pim dr的选举机制:先比较dr的优先级,默认pim dr优先级是1,如果pim dr优先级一样则比较接口的ip地址,越大越优。V2就引入了igmp查询器选举机制,比较发送igmp通用组查询的ip地址,越小越优。选举出来后,只有查询者才会定期发送通用组查询。通用组查询默认60s发送一次,非查询者会监听查询者的状态,且非查询者也可以收到report报文,会在本地创建并维护igmp组关系。
监听查询器故障的发现时间,需通过以下第一个公式

上面第二个公式是igmp组的最大老化时间。这两个时间的设置是合理的,避免组已经被老化了,但还没发现监听者故障。So 监听查询者的老化时间一定要小于组的老化时间。
在v2中可以在接口下配置通用组查询间隔、最大响应时间啥的。但如果两端配置的参数不一样,一样会出现问题
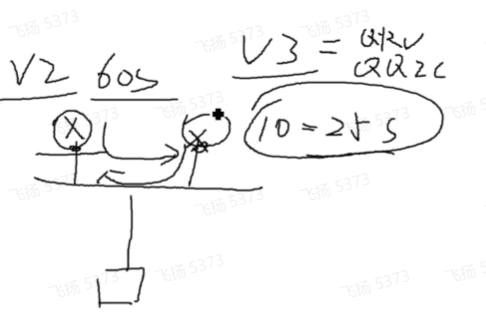
for ex:在右侧将非查询者if下的通用组查询间隔由60改为10,则监听查询器的故障时间就变为25s。此时左面的查询者60s发送一次,而非查询者计算查询者的老化时间只有25s,会认为超时,判断自己是查询者,发送查询报文。当收到对方的查询报文后,再进行选举,又成为非查询器,继续等,在这种情况下会出现在一个时间段内会出现两个查询者,不行。
上述问题在v2中,无法避免,因v2传递的igmp报文里不包含查询的间隔时间和健壮系数-而这两个参数主要是用于非查询者生成和维护查询者的老化时间的。
这个问题在v3中得到了解决,v3在传递报文时,不仅可以指定源组,还会携带两个新的参数,qrv(本地配置到 健壮系数)和qqic(本地接口配置的通用组查询间隔),则这样非查询者收到v3的igmp报文后,可以通过报文中携带的参数来计算我维护查询者的老化时间,就避免了v2的问题
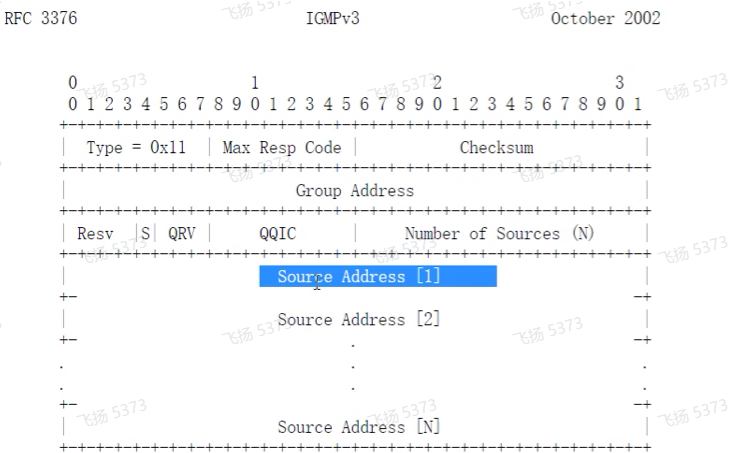
Igmp v3 的报文结构

V3支持ssm的组播模型
组播流量转发模型分为asm(任意源,接收者在加组时不需要指定组播源的信息,只需要接收这个组播组的信息,组播流是哪个源发的,我不关心)/ssm(需要同时指定接收的组播组和组播源)。ssm可以让组播网络更加的简单。
pim分两种模式sm dm,其模式和组播的转发模型没有关系
dm用在接收者分散,较多的场景,通过推的方式;而sm用在组播网络较大,但接收者较少的场景,通过拉的方式来转发组播流量(在sm中需要指定一个rp,不管哪个组播组的流量都需要先发给rp,rp接收到之后再根据本地存在的组播转发表去转发给接收者)。so所有叶路由器在收到igmp报文,就需要向rp发送*,g join,让rp知道在这个设备上有接收者需要接收某个组播组的流量,后面组播源会将流量直接发送给rp,由rp再发送给需要组播流的接收者。在sm里会同时存在spt和rpt,组播转发的方式就是属于拉的方式。
在asm里需要指定rp的,只有rp才同时知道组播源和接收者的存在-搞得网络就比较复杂,组播的转发路径也不是最优的:流量-rp-接收者,同时会增加组播转发延时。同时在以下场景中会增加网络的复杂度
ssm简化组播网络ex:msdp协议:组播源发现协议,用在多个as里实现组播的跨域功能。ex:as1里存在接收者,as2内存在组播源。因接收者和组播源不在同一个as,接收者只会向as内的rp发送信息,但rp之间不能做到消息互通,就不能实现跨域组播的转发,so需要利用msdp在rp之间互相通告rp这个组播源的信息,来实现跨域组播的互通-导致组播网络复杂。
但有了sm后,就不需要rp和msdp,因为接收者在加组时已经指定了组播源,叶路由器在收到报告后,就能知道组播源是谁,叶路由器就可以直接向组播源发起s,g的join,直接构建源-叶路由器的最短路径树,这样即便是跨域,只要保证叶路由器到达组播源的路由可达,并且沿路的设备上都开启pim就可以了,所以说ssm可以让网络更加的简单,so ssm才是为了组播网络部署的关键模型。ssm的地址范围为:232.0.0.0-232.255.255.255(完整的组播范围 224-239,且239是保留的组播私有地址)
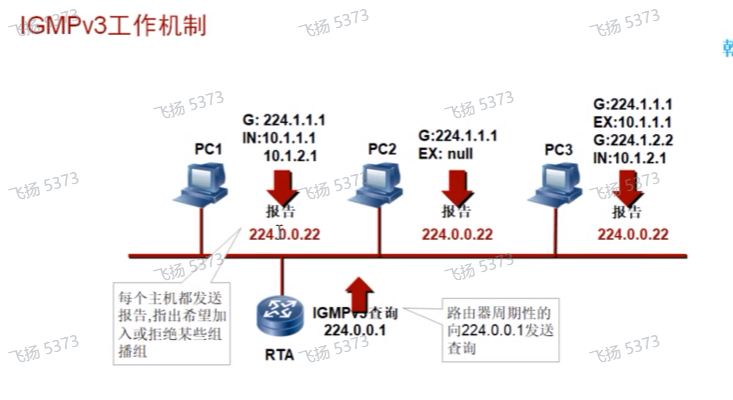
Igmp v3的组成员报告,并不是向v1和v2是发给需要加入的组的(dip),而是发给特定的组:224.0.0.2-只有叶路由器会监听这个组地址,那在v3里就不存在组成员报告的抑制机制,其他的组成员,即便能收到报文,但因为其不在哪个组里,也不会去分析组播组的报文,so在v3里并不存在成员报告的抑制机制
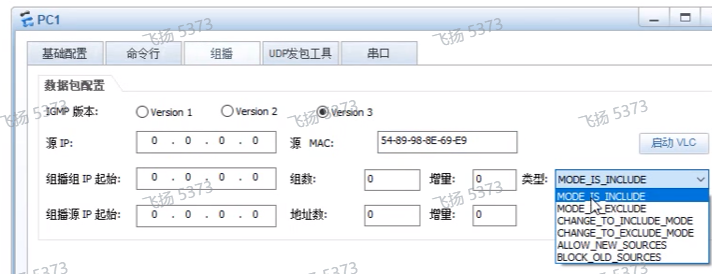
V3的成员报告中,需要区分加组的方式,一共6种方式
Change to include:用于之前是exclude,改为include的
allow:在组里添加新的组成员
block:删除组成员。因igmp v3没有离组报文,这个就相当于离组了。叶路由器在收到该报文后,会在删除这个源之前,发送一个指定源组查询(查询指定源和组里是否还有其他的成员存在),如果有就继续保留这个源信息,如果没有就把这个源删除。
推荐查看rfc以及华为的文档
未来的组播部署,应该是igmpv3+ssm。在ipv6网络中,是mld(v1=igmp v2,v2=igmp v3)+pim。
但并没有mld的报文,其功能是通过icmp v6来实现发送mld的报文。在ipv6中,很多的功能都是通过icmpv6来实现的
igmp-snooping:
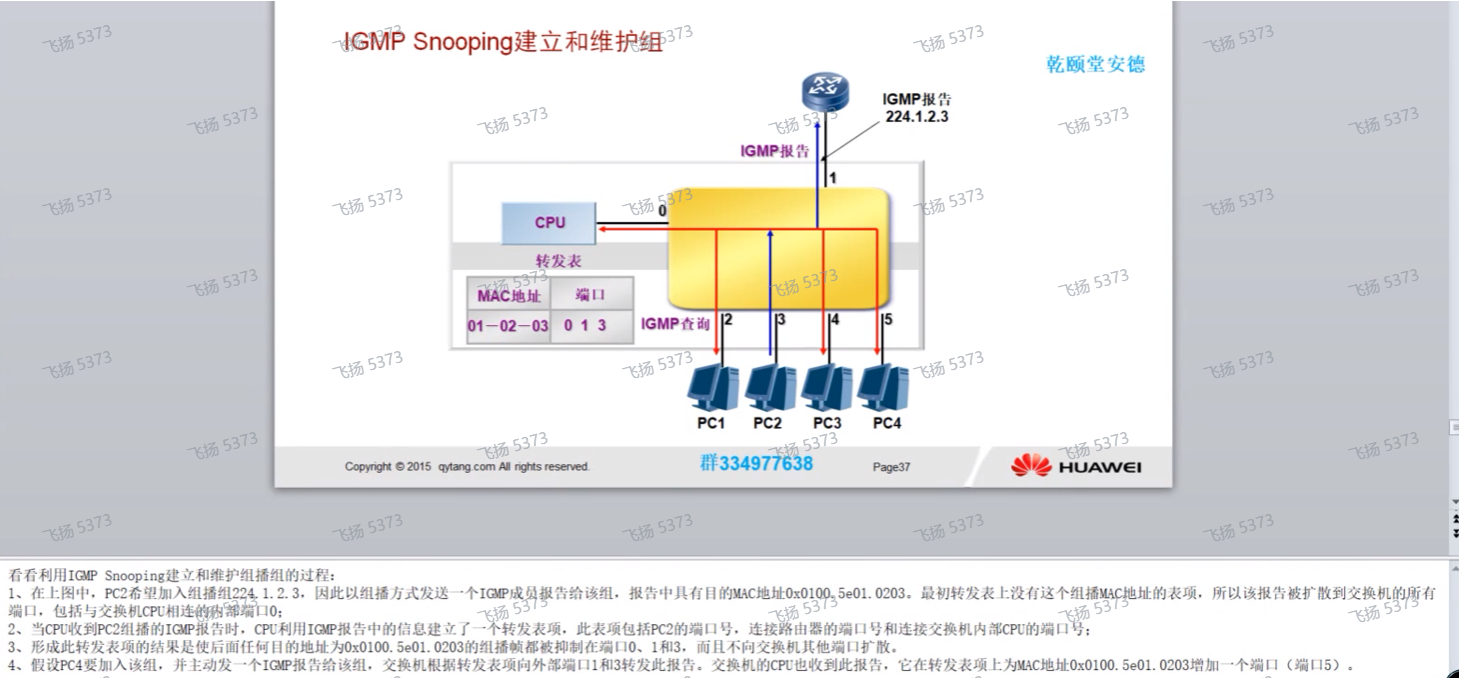
这个自己check一下文档,igmp snooping共有几种方案:igmp snooping,igmp snooping proxy和igmp proxy,应用于不同的场景。sw使用前两者,如果配置snooping,则sw只是做透传;配置proxy之后,才会同时具备组播接收者和路由器的角色,会代替路由器向接收者发送查询报文,同时代替接收者想路由器发送report报文。proxy的作用是为了减轻路由器的压力。比如有主机离组情况,则proxy可以替代路由器直接发送指定组查询,如果收到mr报文,就证明组播组里还有接收者,就不需要通知路由器了.
igmp proxy:在一些简单的树型网络拓扑中,与用户网段直接相邻的组播交换机上并不需要运行复杂的组播路由协议(如PIM),而透传主机IGMP报文又会导致上游接入设备管理太多用户。此时可以通过在与用户网段直接相邻的组播交换机上配置IGMP Proxy(IGMP代理)功能,使其收集下游用户的IGMP成员报告/离开信息,将成员报告/离开信息汇聚后代理下游主机统一上送给接入设备,并维护组成员关系,基于组成员关系进行组播转发。在上游接入设备看来,配置了IGMP Proxy功能的组播交换机就是一台主机。
在IGMP代理设备的上游接口上配置IGMP Proxy功能,在下游接口上配置IGMP功能。
cisco对应的技术叫cgmp-cisco的组管理协议(需要在路由器和交换机开启),让路由器来分析成员加入的组地址,然后路由器会把组信息通过cgmp报文发送给sw,sw在根据cgmp通告的报文,为这个组播mac地址生成一个mac地址转发表项,通过这种方式实现组播流量的转发-而非泛洪。但其依赖于路由器去分析,sw才能实现组播表项接力的功能,其本身没有分析igmp报文的能力。而igmp snooping,只要sw开启,就能分析igmp报文,就能根据igmp报文中携带的组播mac地址和组播组地址(32:1的映射组播mac地址)来构建组播mac地址表,通过这个来转发组播流量
-------------------------------------------------------------------------------
2023-04-16 13:21
Video 80
想去了解协议的标准实现,需要查看rfc
Pim-dm基本就不用了

iptv中,电视就是接收者,每个频道就是组播组。挡在换频道/调频时,就相当于接收者发送mld或者igmp报文,加入到不同的组播组里,就可以看到相应的视频画面。
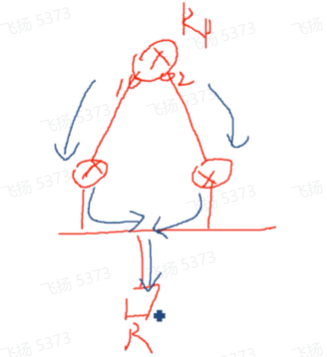
上图的情况,并不会形成环路,但会存在针对该组播流量重复的问题。
在一个广播网络里面,有多台这个叶路器的情况下,并不是有两台路由器全部都向 r p 去发送一个(*,g)的join,那如果全部都发的话,那最终 r p 会根据这个组播的路由表项来转发组播流量,会发现在这个组里面存在两个out if 。
比如上图1口和2口,流量会到达1和2两台路由器,因为下联是一个广播网络,那这样接收者会收到两份组播流量,同时组播流量也会被其他叶路由器接收到(//因为叶路由器接收到组播流量会进行rpf检查,检查不通过就丢弃),不会成环的,无非就是在这里会存在组播流量重复的问题,这种不可行。so在pim的sm模型下,需要在广播网内选举一个pim 的dr,最终由dr向rp发送(*,g)的join(构建RPT树),这样这个组播组只有一个出接口,就会避免接收者能接收到重复的流量。
上述为pim-dr在pim-sm中的作用,这是在叶路由器广播网接入上面的场景中。
在连接源的设备上也需要dr
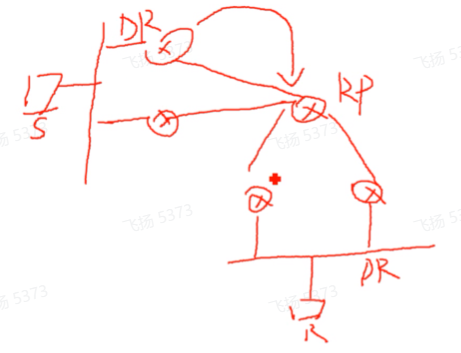
在pim-sm模型中,第一跳路由器在收到组播源发送的组播流量后,需要向rp发送注册报文-封装成单播报文发送给rp,但是这个注册报文由哪台第一跳路由器发送?就需要选出源端dr,由源端dr来发送。
spt会在pim-sm的两种场景下建立
在收到组播源发送的组播流后,如果在 r p 上面有对应的组播组的存在,会转发组播流量,同时向组播源发送一个(s,g) 的join,由 r p 到组播源去建立一个最短路径树;2.叶路由器由rpt切换为spt(之前的rpt路径非最优,会增加转发延时(实时业务对转发延时要求在50ms内),为保证组播转发的最短路径,就需要在叶路由器上开启spt的切换功能),当组播流量超过阈值,叶路由器就会向组播源发送(s,g)的join,构建从源到叶路由器的最短路径树。
叶路由器在切换到spt之后,仍需同时维护rpt,因为要保证spt故障后,还可以切回到rpt


rpf的检查方式在所有厂商都是两种:ad(cisco称为ad,华为称为优先级);掩码长度。

urpf用于单播
上图组播源的部分可以替换为bsr,候选rp。mbgp,是单独的组播地址簇,其通告的路由条目只能用于组播路由的选路 。
第四条:在华为路由表里,不可能存在掩码长度相同,但metric不同的路由条目。这种情况路由表只会保留一条metric小的。而在cisco中有些协议支持非等价负载分担-实现掩码长度相同,但metric不同的负载,ex eigrp,bgp也可以,那在这种场景要用于组播路由选路时,就需要match 这个metric。接收到组播流量后就进行rpf检查,判断接收流量的入接口=到达组播源的出接口,即转发组播流量,如果不是则丢弃。通过该方式可以避免组播流量的转发环路.
默认比较的是优先级即AD(ad是cisco的叫法,优先级是华为的叫法),在cisco中想要更改rpf的检查方式为掩码长度,还需要配置一条特殊的命令行。

这个是pim的机制,不分sm和dm的
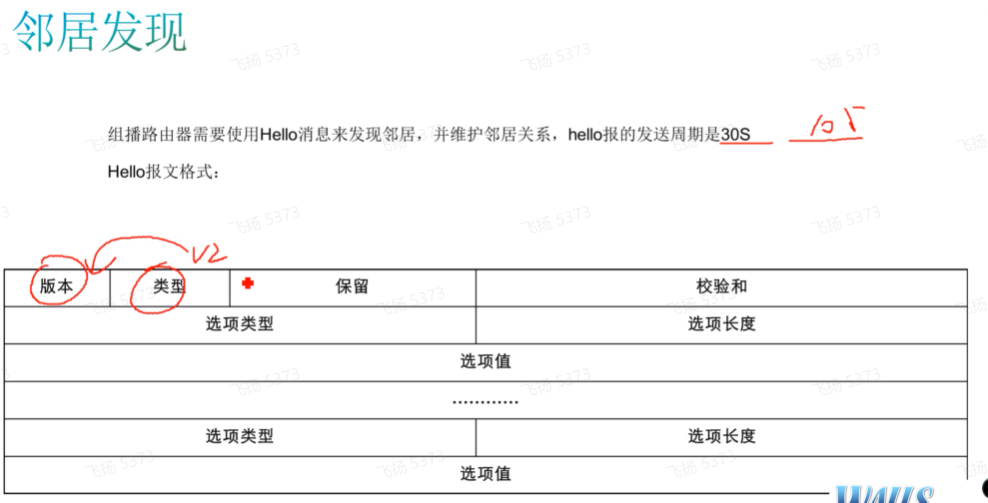
Pim 的hold time是3.5倍的hello,105s,当前使用的版本是v2,类型来标识不同的报文,ex这里是hello报文
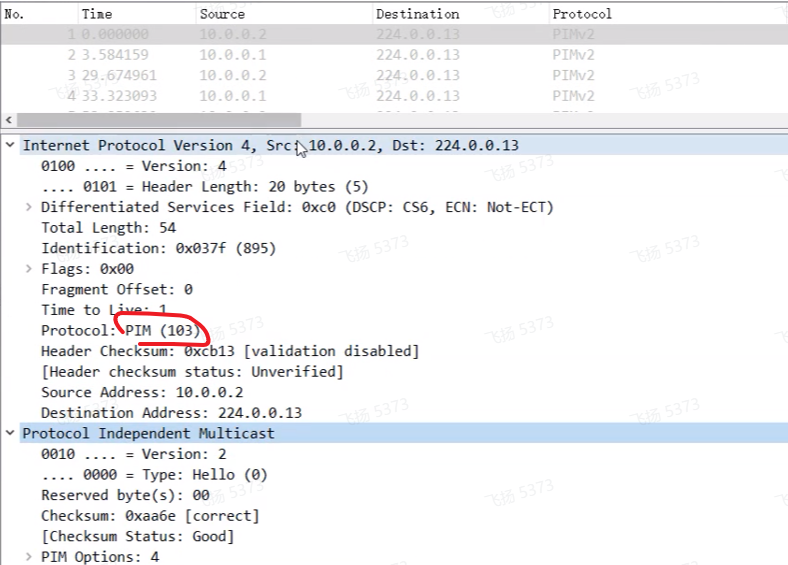
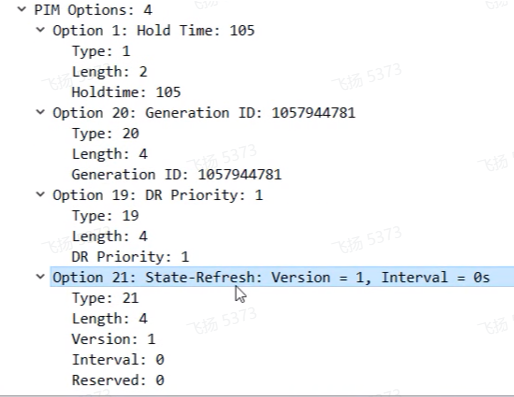
State-refresh只是用到pim-dm中,只是用于刷新状态的
pim的报文也是基于ip转发的
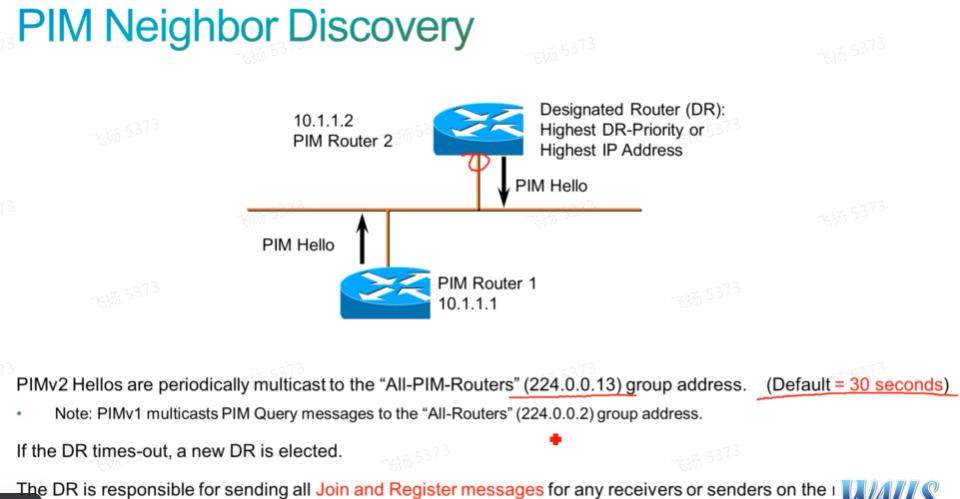
pim的邻居发现也是基于组播来发现的,类似于ospf,只不过pim发送的组播组地址是224.0.0.13。只要if开启pim-sm/dm,都会向224.0.0.13这个组发送hello,发现直连的邻居关系。pim里只支持直连邻居关系的建立。 .2只代表路由器,.1包括所有设备,比如还有pc。在广播网中,还需要选举出dr

显示dr-则本端就是dr,显示s-本端是standby或s开启state refresh功能。在ts中,可以通过show ip pim int查看有哪些接口开启了pim。

xr配置举例:在multicast routing视图下,ipv4单播地址族下,接口enable-接口下开启组播的路由转发功能(想要在接口下开启pim的话,还需要在router pim下 add ipv4 un 下 int才可以,见后面的配置xr上的dr选举)。Router pim中的配置,主要用于rp的自动选举。
最后一条,在xe设备上(即普通的ios),还需要配置上面的命令,才能开启组播的功能。xr是不需要开启的。
第二节 dr选举

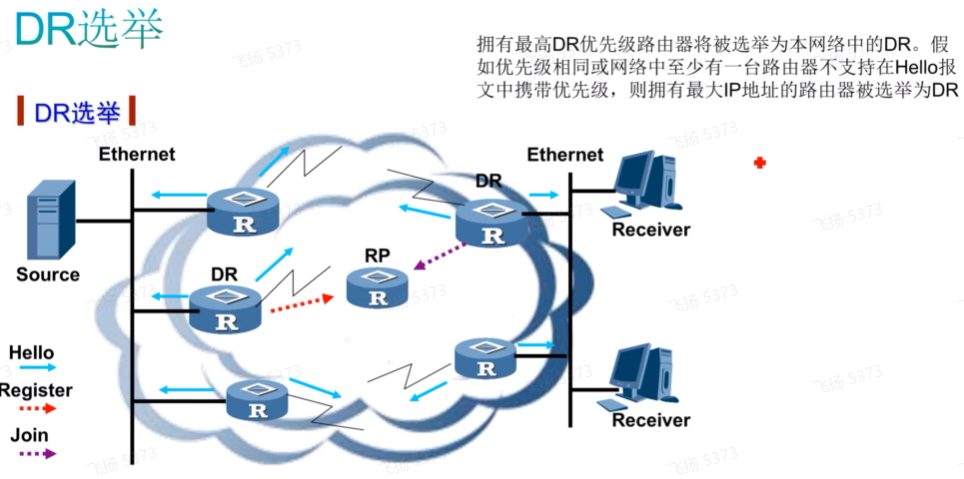

接口下开启pim的命令如上
第三节 rp发现

在pim-sm网络中需要配置rp的:1.静态指定(在设备上配置静态rp就行了。部署时要考虑哪些路由器需要配置静态rp:在rpt树里的所有设备都需要配置,ex 叶路由-rp及之间经过的路由器。从rp到达组播源的spt树上有哪些需要配置:第一跳路由器需要配置(//因fh要向rp发送源注册报文),而中间的中转设备不需要配置,并且需要保证第一跳和中间的路由器到达rp是路由可达的,如果不可达,可能导致rpf检查失败,就不能继续转发流量);
2.动态选举:auto-rp:cisco私有协议;boot-strap公有协议,本质也是一种pim的报文类型,通过pim报文实现了rp的动态选举。这个更优,不仅是一个开源的协议,而且选举机制要优于auto-rp。
第四节 共享树的形成
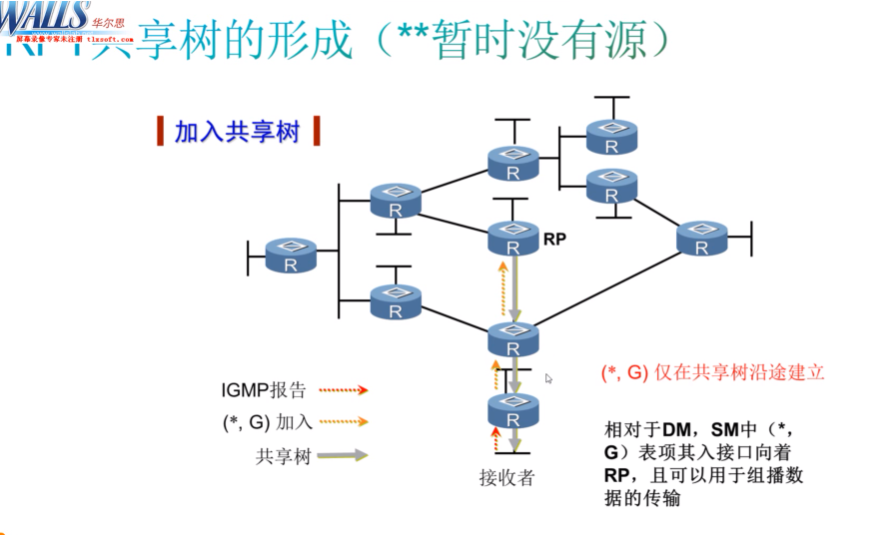
在pim-sm中,首先需要在叶路由器和rp之间建立rpt。流程如下:接收者发送一个igmp 的report报文,叶路由器收到后,经过分析report报文,就能知道接收者要加到哪个组播组里,叶路由器会在本地建立一个igmp的组关系,同时会在组里标识这个接收者就是last reporter。由于叶路由器已经知道了接收者的存在,并且知道其要加入的组播组,就会向rp发送(*,G)的join-因接收者在加组时并没有指定组播源,在igmp v1和2中,接收者在加组时,并不需要指定组播源,so在叶路由器上创建组播条目时,是没有组播源信息,而只有组播组信息。而在v3中,需要发送(s,g)的join,这就不需要向rp发送,而直接向组播源发送。
因接收者在发送报告时没有指定源,所以在叶路由器上会创建一个(*,G)的组播路由表,并向rp发送(*,g)的join。但在向rp发送之前,还需要针对rp的地址进行rpf检查,这个检查的目的是找到到达rp的出接口,ex设备有多个接口可以到达rp,最终只会选择一个接口发送*,G的join//找到如何到达rp
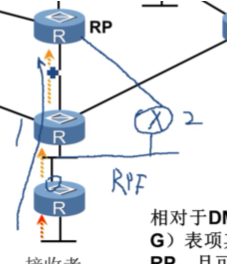
此场景下,叶路由器在通过rpf检查,发现可以通过两个下一跳都到达rp,最终需要选择一条路。假如最终选择1,就会沿着选路的路径发送(*,g) join。(*,g)的join报文本身是通过pim报文-组播的方式来转发的,如果通过组播方式转发这个报文,那这个报文在广播网转发时,会同时被1和2两台设备收到,1和2在收到后都会把(*,g)的join发给rp么?这两台设备都会在本地创建*,g的组播路由表项么?由于是一个广播网,那这个报文从广播网上发出去,会被其他的设备接收到,那其他设备接收到应该怎么处理?
*,g join里有upstream nei-用来标识自己的上游邻居,后面填充的地址就是通过rpf检查最终得到的出接口邻居的ip地址。计算出出接口,就可以查看该接口上上联的邻居ip地址。在show ip pim nei时,可以看到邻居的ip地址和邻居对应的出接口。而通过rpf检查时,就可以找到到达这个rp的出接口,然后可以看到这个出接口所连的邻居ip是什么。会把这个ip地址放到upstream nei里。对应上图广播网的情况。
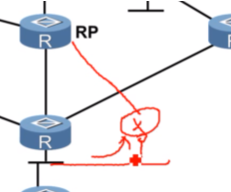
叶路由器到达rp是通过一个广播网多路径可达,如果叶路由器计算出是走左边,那右边的设备也会收到*,g的join,但由于这个报文里携带的up nei并不是我接口的ip地址,就说明这个报文不是给我的,就会丢弃。so在这里,只有左边的设备会在本地生成*,g的转发表项,并把报文继续转发给rp,而右边哪台设备收到也会丢弃,在本地也不会创建*,g的转发表。这里是通过 upstream nei来标识,这个join报文应该由谁来处理。这样就可以在叶路由器和rp之间建立一颗spt,但现在还没有流量,只是通过这种*,g的join方式,让rp知道了这个组播组里有接收者,但还没有流量过来,so在这张图里,只是建立了一个共享树,暂时没有源。

pim的join报文(和prune是一个报文),不管是在pim-dm或sm都会存在
报文中的flag位需要理解,S,G的join就没有wc的置位。rp位置位,说明该join或prune报文是发给rp的
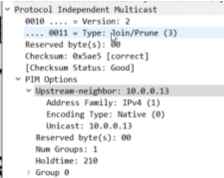
join和prune是同一个type
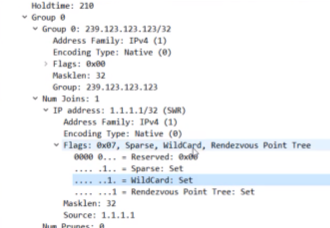
报文是来自于共享树,是发给rp的,sm。joins和prunes看里面的内容来确认是join还是prune
组播源的注册

看后面的注册流程就行了
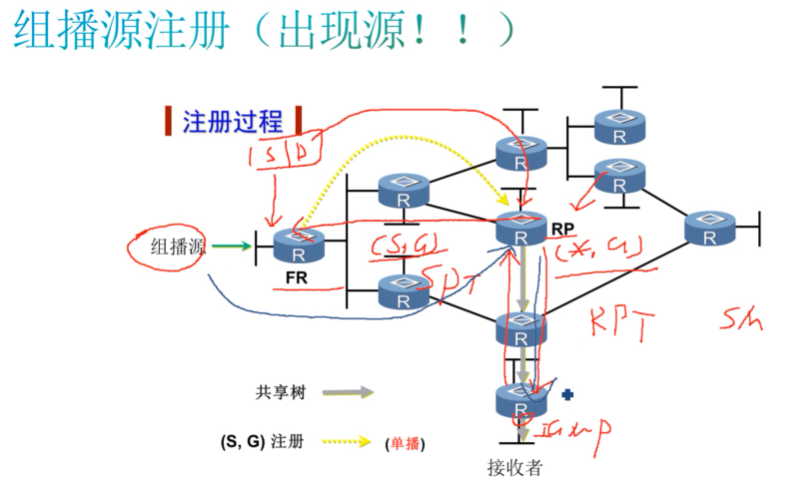
当前已经在接收者和rp之间建立了rpt树,接收者需要告诉rp我需要接收哪个组播组的流,其过程是通过与接收者连接的叶路由器来完成的(接收者只是个接收组播流量的终端)。告诉rp-因为在pim-sm中,只有rp来进行流量的转发,所有的组播流量都会被先发到rp,如果rp不知道这个组播组存在,就不能继续转发组播流量。so需要先让rp知道这个网络里存在这个组播组的接收者存在。
第二步,组播源开始发送组播流,组播流到达fh后,fr 会将这个组播报文封装为单播报文(就是在组播报文前加上一层单播报文的头部),这个报文的sip是fr的ip地址,而dip是rp。所以之前需要在fr上配置静态rp-让fr知道静态rp是谁。rp在收到后,需要解封装,去掉单播头部,查看组播报文的源地址和组地址是是谁,然后rp需要判断我接收到的这个组播流量是否需要转发。判断依据通过这个注册报文里所携带的组播组地址,来查看本地的组播路由表。之前如果有接收者需要接收这个组播组的流量,就需要提前告诉rp,在rp上就会形成到达这个组的*,g表项,如果本地有*,g的表项的话,就是可以匹配上,说明在网络里有接收者需要接收这个组播组的流量,那rp就需要沿着rpt将数据帧转发给接收者。同时已确认网络里有接收者需要接收组播流量,那我就需要让rp向组播源发送S,g的join,来建立一条组播源到达rp的转发路径。//这个是在rp接收到组播流量后才建立的
so在pim-sm中,有两颗树组成。组播源到rp的spt+rp到叶路由的rpt。通过两棵树来完成组播流量的转发。这种是在rp上有对应的*,g表项,rp才会向组播源发送S,g的join来进行流量的引流。
如果rp上没有*,g的表项,就意味着rpt里没有接收者要接收这个组播组的流量,则rp不会继续转发给接收者,如果继续转发则完全是浪费带宽。so在rp上面,如果找不到匹配的*,g表项,就会忽略到注册报文。虽然会忽略,但同样会在本地为这个组播流量生成一个s,g的表项。因:现在虽然没有接收者,但是后面如果有接收者需要接收这个组播组流量的话,而我本地不知道组播源存在的话,接收者是不能接收到组播流量的。如果我能提前为我能接收到的组播流生成一个S,g的表项,一旦有接收者需要接收组播流量的话,那我可以按之前生成的表项向组播源发送s,g的join,吧流量引过来。So 我需要提前维护一个s,g的表,知道源的存在,这样可以实现一个接收者需要接收组播流量时,我可以进行一个快速的建立,把流量引过来。如果在rp不创建S,g,那只有在fr第二次发送注册报文才会知道。但fr频繁的向rp发送注册报文也是一种攻击,同时也是浪费带宽。你每发送一次,都需要我的控制层面处理一次,如果发的很频繁,那就相当于攻击了。在这种情况下,rp不仅会在本地建立一个s,g的表项来维护组播源的信息,同时会主动向fr发送注册停止报文,告知其fr 你先别发注册报文了,我本地也没有接收者,不会像你发送s,g的join的。fr在接收者注册停止报文后,会启动一个定时器(默认60s,可以更改),其在hold时间内,不会向rp发送注册报文,等超时再去发送。而rp如果本地还没有这个接收者的话,还会向fr发送注册停止报文,如此循环。这样就可以避免fr频繁的向rp发送注册报文。
上述方式有一个缺陷,60s内rp收不到fr发送的注册报文。加入在holding的时间,组播源出现了问题,不再发送组播流量,但rp是不知道的。但在这60s内正好有接收者需要接收组播流量,那rp因为在本地的组播路由表里有s,g的表项,那rp会主动向组播源发送s,g的join,但实际上这个组播源已经不发送组播流了。因为fr并不会告诉rp组播源有问题。这种场景就会用到probe报文。目的是在fr处于holding状态时,rp会每隔一段时间向其发送probe报文,问fr,组播源有没有问题,如果源有问题,我就把这个S,g的表项删掉就ok了。probe主要是用于探测组播源的状态。
同时在该场景中,fr如果感知不到组播源发送的组播流,也会停止发送注册报文,只有在不断收到组播源发送的流量后,才会发送注册报文-这也是用于检查组播源的一种方式。
第六节 spt切换
本质就是为了避免接收者和组播源之间的次优路经问题,转发延时过大-iptv没法看。在实时业务中(语音、视频),要求端到端(源到接收者)的转发延时要小于50ms。如果大了,可能视频卡顿,唇音不同步。
接收者直接向组播源发送S,g的join,建立从源到接收者的spt。但这个工作是由叶路由器完成,因接收者只是终端设备,用来接收组播流量。
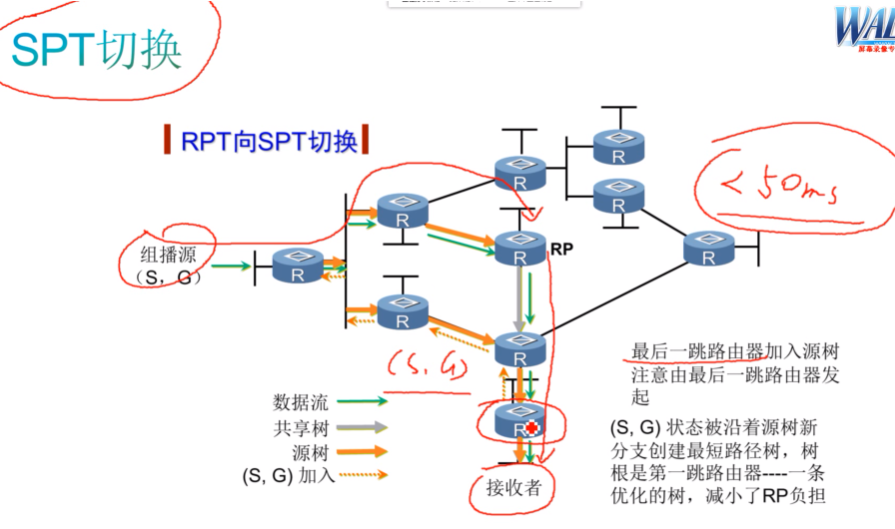
在叶路由器上配置一个切换的阈值,如果流量的大小超过了这个阈值,就切换到spt。如果小于这个阈值,则切换回rpt。
切换后的问题,叶路由器需要建立到达组播源的spt,之前的到达rp的rpt还存在。那这样就意味着,同一份组播流量既来自于从源到达叶路由器的spt,也来自rp到达叶路由器的rpt,这样流量会出现两份,不行的。So 一旦叶路由器切换到spt后,就需要把rp上rpt剪枝掉,就需要向rp发送S,g的prune,*,g是继续要保持的(//因为rp已经知道组播源了,这里应该只是删除(s,g)的outgoing if)。一般情况下,在prune或join报文里只会单独包含一种,只有在一种特殊的情况,就是spt切换后,叶路由器在向rp发送prune报文的时候,会在一个报文里同时标识prune和join-在pim里称为原子报文(指同时包含prune和join)。因为这个报文都是发送给rp的,但是prune和join是发送给不同表项的,prune是用于S,g的,join是用于*,g的。保留*,g的原因:一旦叶路由器到达组播源的spt故障,就无法接收到组播流量,那就留一条后路,从rp接收。如果把*,g 也prune掉,rp就会认为表项里没有任何接收者了,就不需要再接收组播源发送的组播流了,然后rp就会继续把到达组播源的S,g prune掉,备路就没了。此时再想回切,转发路径的重新建立需要时间(重新建立rpt和spt),spt回到rpt切换会很长。so需要告诉rp,你不需要给我转发s,g的流量,但是*,g的表项要保留。
rp上针对1个组,是同时存在两个表项的,其在转发组播流量时,会优先使用S,g(可理解 S,g就是单播路由里的明细路由,而*,g就是默认路由),只有在没有S,g的情况下才会沿着*,g转发。叶路由器在向rp发送s,g的prune,就会把s,g上的接口给prune掉,流量就不会转发给接收者,但*,g表项还是维护的
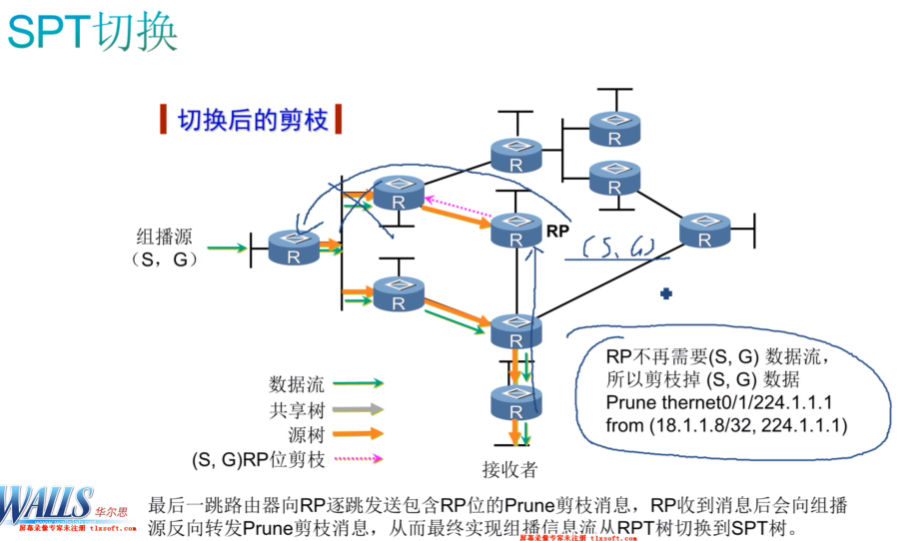
当发送一个S,g的prune给rp,则rp针对这个S,g表项已经没有出接口-相当于没有接收者接收组播流量。如果出接口为空,则rp会向组播源发送S,g的prune,把从rp-组播源的spt干掉,详见后面。但rp到达接收者的rpt还是保持,用于回切。这是正确的,当(S,G)上已经没有接收者,就说明不需要这个组播流量,那在rp-组播源之间也需要把这个spt修剪掉,不然rp收到组播源发送的组播流量,也会丢弃,没啥意义。那rp就主动告知组播源你不要给我发了,向其发送(S,G)prune和(*,G)join,来剪枝到rp-组播源的spt但还会维护接收者-rp的 rpt。//这个pim-sm spt切换后的剪枝流程,由叶路由器向rp发原子报文(s,g)prune和(*,g)join,那rp接收到之后该原子报文后,删除(S,g)对应的出接口,但是到达组播源的spt是保留的?而因为又收到了接收者发来的(*,G)join,就继续维护到达接收者的rpt树,以便于接收者-组播源的spt故障后流量的回切。那假如说接收者-组播源的spt挂了,需要切回spt+rpt,因为rp上这两颗树在叶路由器切换到源的spt后是一直保留着的,叶路由器只需要重新向rp发送(S,G)join就行了?那如果最后这个组没有任何接收者了,rp为了后期有人加组能快速转发组播流量,则rp仍会维护到达组播源的spt,只不过向fh router周期性发送注册停止报文?上述分析正确。




组播流量只能来自于incoming if,来自非这个接口的组播流量会被全部丢弃。

*,g incoming if为空,说明其本身就是rp。
因为是同一个组播组,S,g会直接使用*,G的 outgoing list。
在普通pim中,一个接口不可能同时存在作为出接口和入接口使用。而在双向pim中,这个设备同时可以作为接收者和组播源,就会存在一个接口同时作为出接口和入接口的情况,但用的很少



msdp在多区域部署的时候,跟bgp还是有关联性的。
-----------------------------------------------------------------组播终结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号