
基于haar特征的Adaboost人脸检测技术
基于haar特征的Adaboost人脸检测技术
本文主要是对使用haar+Adabbost进行人脸检测的一些原理进行说明,主要是快找工作了,督促自己复习下~~
一、AdaBoost算法原理
AdaBoost算法是一种迭代的算法,对于一组训练集,通过改变其中每个样本的分布概率,而得到不同的训练集Si,对于每一个Si进行训练从而得到一个弱分类器Hi,再将这些若分类器根据不同的权值组合起来,就得到了强分类器。
第一次的时候,每个样本都是均匀分布,通过训练得到分类器H0,在该训练集中,分类正确的,就降低其分布概率;分类错误的,就提高其分布概率,这样得到的新的训练集S1就主要是针对不太好分类的样本了。再使用S1进行训练,得到分类器H1,依次迭代下去……,设迭代此外为T,则得到T个分类器。
对于每个分类器的权值,其分类准确性越高,权值越高。
二、Haar特征
2.1 特征样子
就是一些矩形特征的模板,在viola&Jones的论文中,有下面这五种
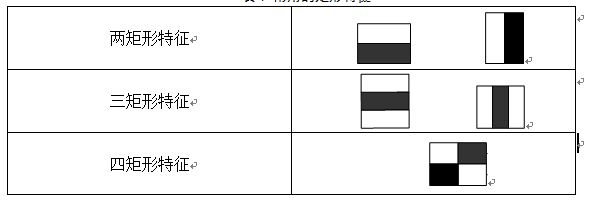
在opencv中的方法中,有下面这14种,

2.2 特种的个数
对于一个给定的24X24的窗口,根据不同的位置,以及不同的缩放,可以产生超过160,000个特征。

2.3 特征计算方法——积分图
有点类似于动态规划的思想,一次计算,多次使用
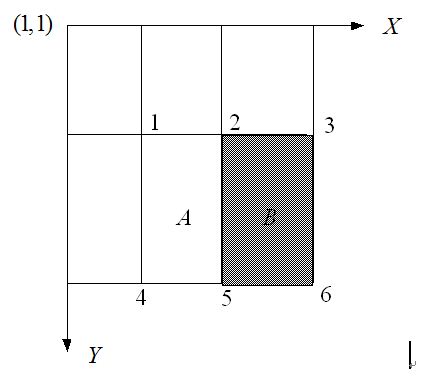
对应于两矩形特征2,矩阵A的值可以用i(5)+ii(1)-ii(4)-ii(2)表示,矩阵B的值用ii(6)+ii(2)-ii(3)-ii(5)表示
根据定义,haar特征的值为白色矩形减去黑色矩形的值。
三、选取弱分类器
一个弱分类器,实际上就是在这160,000+的特征中选取一个特征,用这个特征能够区分出人脸or非人脸,且错误率最低。
现在有人脸样本2000张,非人脸样本4000张,这些样本都经过了归一化,大小都是24X24的图像。那么,对于160,000+中的任一特征fi,我们计算该特征在这2000人脸样本、4000非人脸样本上的值,这样就得到6000个特征值。将这些特征值排序,然后选取一个最佳的特征值,在该特征值下,对于特征fi来说,样本的加权错误率最低。选择160,000+个特征中,错误率最低的特征,用来判断人脸,这就是一个弱分类器,同时用此分类器对样本进行分类,并更新样本的权重。
具体过程如下:
1. 归一化权重:

2、对于每一个特征f,训练一个弱分类器h;计算所以特征的加权错误率εf,

3、选取具有最小错误率εf的弱分类器hi
4、调整权重

四、级联成强分类器

五、检测
检测过程中,通过不断的调整检测窗口的位置、比例,来找到人脸。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号