
【建模应用】PLS偏最小二乘回归原理与应用
出处:http://www.cnblogs.com/duye/p/9031511.html
1.回归
”回归“一词来源于对父母身高对于子女身高影响的研究。有人对父母的身高与子女身高做统计,发现除了父母高则子女普遍高的常识性结论外,子女的身高总是“趋向”于人类平均身高,最早“回归”一词就来源于此,即子女的身高总是回归于人类平均身高。
现代意义上的回归,是研究因变量对自变量的依赖关系的一种统计分析方法,目的是通过自变量的给定值来估计或预测因变量的均值。它可用于预测、时间序列建模以及发现各种变量之间的因果关系。简单地说,回归就是去分析因变量与自变量之间的关系,从而为分析数据、预测数据提供科学的、合理的方法。
2.回归的方法
目前常用的回归方法有以下几种:
- 多元线性回归:入门练习常见,但用在模型上基本无用,因为多个变量之间难免有复杂的相关性,多元线性回归不能处理多个自变量之间的“糅合”性。
- 逻辑回归:当预测的是1/0时使用。 这也是机器学习中的一种常用二分类方法。
- 主成分回归:类似于主成分分析,将具有相关性的多维变量降维到互不相关的少数几维变量上,可以处理变量之间具有相关性的情况。
- 岭回归:同上,但方法不同。
-
偏最小二乘回归:当数据量小,甚至比变量维数还小,而相关性又比较大时使用,这个方法甚至优于主成分回归。
3.回归的检验
建模是最重要的,但好的回归模型是需要检验的,否则你的模型就会显得“苍白无力”。回归结果好与坏,应该怎么检验呢?从以下几方入手:
- 自变量与因变量是否具有预期的关系。如果有非常不符合逻辑的系数,我们就应该考虑剔除它了。
- 自变量对模型是否有帮助。如果自变量的系数为零(或非常接近零),我们认为这个自变量对模型没有帮助,统计检验就用来计算系数为零的概率。如果统计检验返回一个小概率值(p值),则表示系数为零的概率很小。如果概率小于0.05,汇总报告上概率(Probability)旁边的一个星号(*)表示相关自变量对模型非常重要。换句话说,其系数在95%置信度上具有统计显著性。
- 残差是否有空间聚类。残差在空间上应该是随机分布的,而不应该出现聚类。
- 模型是否出现了倾向性。如果我们正确的构建了回归分析模型,那么模型的残差会符合完美的正态分布,其图形为钟形曲线。
- 自变量中是否存在冗余。建模的过程中,应尽量去选择表示各个不同方面的自变量,也就是尽量避免传达相同或相似信息的自变量。 评估模型的性能。评估矫R2值,有时还要加上修正的Akaike信息准则/Akaike's information criterion (AIC),效果是否好。
偏最小二乘回归
1.偏最小二乘回归的思想:
一般来说,能用主成分分析就能用偏最小二乘。偏最小二乘集成了主成分分析、典型相关分析、线性回归分析的优点。在普通多元线形回归的应用中,我们常受到许多限制。 最典型的问题就是:自变量之间的多重相关性。并且有的时候样例很少,甚至比变量的维度还少,变量之间又存在多重相关性。偏最小二乘回归就是为解决这些棘手的问题而生的。
举个例子,比如现在,有一堆因素(X1,X2,...Xn)(这是自变量),这些因素可以导致(Y1,Y2,...Yn)(这是因变量),给的样例很少,而我们又完全不清楚自变量之间、因变量之间存在的关系,这时问自变量与因变量之间到底是一个什么关系?这就是偏最小二乘要解决的问题。
2.偏最小二乘回归建模原理:
设有 q个因变量{y1,…,yq}和p自变量{x1,…,xp}。为了研究因变量和自变量的统计关系,我们观测了n个样本点,由此构成了自变量与因变量的数据表X={x1,…,xp}和.Y={y1,…,yp}。偏最小二乘回归分别在X与Y中提取出成分t1和u1(也就是说, t1是x1,x2,…,xq的线形组合, u1是y1,y2,…,yp的线形组合).在提取这两个成分时,为了回归分析的需要,有下列两个要求:
(1) t1和u1应尽可能大地携带他们各自数据表中的变异信息;
(2) t1与u1的相关程度能够达到最大。
这两个要求表明,t1和u1应尽可能好的代表数据表X和Y,同时自变量的成分t1对因变量的成分u1又有最强的解释能力。
在第一个成分t1和u1被提取后,偏最小二乘回归分别实施X对t1的回归以及 Y对u1的回归。如果回归方程已经达到满意的精度,则算法终止;否则,将利用 X被t1解释后的残余信息以及Y 被t2解释后的残余信息进行第二轮的成分提取。如此往复,直到能达到一个较满意的精度为止。若最终对 X共提取了 m个成分t1,t2,…,tm,偏最小二乘回归将通过实施yk对t1,t2,…,tm的回归,然后再表达成yk关于原变量X1,X2,…,Xq的回归方程,k=1,2,…,p。
3.推导偏最小二乘回归:
为了彻底理解偏最小二乘回归,我建议下面的步骤你都亲自推导一遍。相信经过下面的推导,能让你对偏最小二乘有一个更加清晰的认识。
-
step1:数据说明与标准化
数据矩阵E0,F0,其中E0为自变量矩阵,每一行是一个样例,每一列代表了一个维度的变量;F0是因变量矩阵,解释同E0。
数据标准化即,要将数据中心化,方法是每个样本都做如下操作:减去一个维度变量的均值除以该维度的标准差。以下设E0,F0都为标准化了的数据。即:自变量经标准化处理后的数据矩阵记为E0(n*m),因变量经标准化处理后的数据矩阵记为F0(n*p)。
-
step2:求符合要求的主成分(☆)
即求自变量与因变量的第一对主成分t1和u1,根据主成分原理,要求t1与u1的方差达到最大,这是因为:方差最大则表示的信息就越多。另一方面,又要求t1对u1有最大的解释能力,由典型相关分析的思路知,t1与u1的相关度达到最大值。
因此,综合上述两点,我们只要要求t1与u1的协方差达到最大,即:
Cov(t1,u1) –> max
而且,t1是X的线性组合,那么权重系数设为W1,即t1 = E0W1,同理,u1是Y的线性组合,u1 = F0C1。同时又要求,W1与C1同为单位向量,问题的数学表达式为:
max <E0w1,F0c1>
S.T.
||W1|| = 1;
||c1|| = 1
这就是一个条件极值的问题,你可以采用拉格朗日方法求解(如果你还有兴趣,可以查阅高数课本,当然,你也可以直接看结论,这里我只给出结论,推导省略,实际上推导并不影响你理解)。
通过拉格朗日求解,知w1就是矩阵E0‘F0F0’E0的对应于最大特征值的特征向量,c1就是矩阵F0’E0E0’F0对应于最大特征值的最大特征向量,均单位化。
有了权系数w1,c1,自然可以求得主成分t1,u1。至此,第一对主成分完成。
-
step3:建立主成分与原自变量、因变量之间的回归(☆)
建立E0,F0对t1,u1的三个回归方程,如下:

式中,回归系数向量是:

而E1,F*1,F1分别是三个回归方程的残差矩阵.
-
step4:继续求主成分,直到满足要求
用残差矩阵E1和F1取代E0和F0,然后,求第二个轴w2和c2以及第二个成分t2,u2,有

重新执行step3。直到求出所有主成分或者满足要求(后面说明)。
-
step5:推导因变量之于自变量的回归表达式(☆)
如此经过step3-step4反复,若E0的秩为A,则可以求出:

由于t1….tA都可以表示E01,E02….E0q的线性组合,那么就自然还原成下面的形式:
![]()
Fak为残差矩阵Fa的第k列。这样,就求出了回归方程。
-
step6:检验-交叉有效性(☆)
这是最后一步,也是非常重要的一步。下面要讨论的问题是在现有的数据表下,如何确定更好的回归方程。在许多情形下,偏最小二乘回归方程并不需要选用全部的成分进行回归建模,而是可以象在主成分分析一样,采用截尾的方式选择前m 个成分,仅用这m 个后续的成分就可以得到一个预测性较好的模型。事实上,如果后续的成分已经不能为解释因变量提供更有意义的信息时,采用过多的成分只会破坏对统计趋势的认识,引导错误的预测结论。
下面的问题是怎样来确定所应提取的成分个数。
在偏最小二乘回归建模中,究竟应该选取多少个成分为宜,这可通过考察增加一个新的成分后,能否对模型的预测功能有明显的改进来考虑。采用类似于抽样测试法的工作方式,把所有n个样本点分成两部分:第一部分除去某个样本点i的所有样本点集合(共含n-1个样本点),用这部分样本点并使用h个成分拟合一个回归方程;第二部分是把刚才被排除的样本点i代入前面拟合的回归方程,得到yj在样本点i上的拟合值![]() 。对于每一个i=1,2,…,n,重复上述测试,则可以定义yj的预测误差平方和为PRESShj。有:
。对于每一个i=1,2,…,n,重复上述测试,则可以定义yj的预测误差平方和为PRESShj。有:

定义Y 的预测误差平方和为PRESSh,有

显然,如果回归方程的稳健性不好,误差就很大,它对样本点的变动就会十分敏感,这种扰动误差的作用,就会加大PRESSh的值。
另外,再采用所有的样本点,拟合含h 个成分的回归方程。这是,记第i个样本点的预测值为![]() ,则可以记yj的误差平方和为SShj,有
,则可以记yj的误差平方和为SShj,有

定义Y的误差平方和为SSh,有

定义称为交叉有效性,对于每一个变量yk,定义

对于全部因变量Y,成分th交叉有效性定义为

用交叉有效性测量成分th对预测模型精度的边际贡献有如下两个尺度。
(1) 当![]() 时, th成分的边际贡献是显著的。显而易见,
时, th成分的边际贡献是显著的。显而易见,![]() 是完全等价的决策原则。
是完全等价的决策原则。
(2) 对于k=1,2,…,q,至少有一个k,使得![]() 。这时增加成分th,至少使一个因变量yk的预测模型得到显著的改善,因此,也可以考虑增加成分th是明显有益的。
。这时增加成分th,至少使一个因变量yk的预测模型得到显著的改善,因此,也可以考虑增加成分th是明显有益的。
实现偏最小二乘回归算法步骤:
上面推导了偏最小二乘回归,分析了其中的原理。为了使得在实际应用中更加快速的使用偏最小二乘回归,在此,贴上实现偏最小二乘法实现的简洁步骤,需说明的是,下面算法来自司守奎老师《数学建模算法与应用》一书,该书推导过程跨度大,个人认为不适合新手直接阅读,建议你在理解了上述第二部分后再去阅读此书“偏最小二乘回归”章节,定会有更加高层次的认识。步骤如下:

四、MATLAB实例以及实现
有必要贴出偏最小二乘的简单建模应用,并用matlab去是实现之,你可以按照上述步骤,通过基本的运算如求矩阵特征值等,来实现,也可以使用matlab工具箱方法实现之,下面给出的依旧是一个来自司守奎老师书本上的案例:
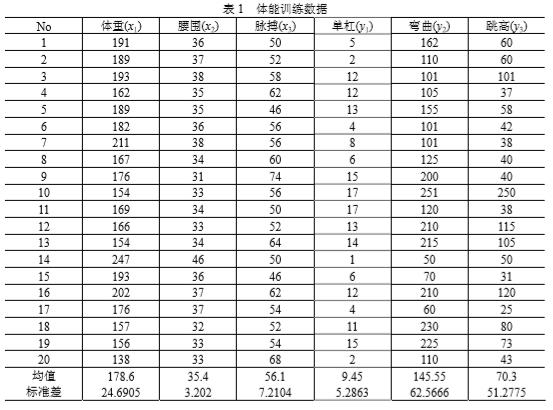
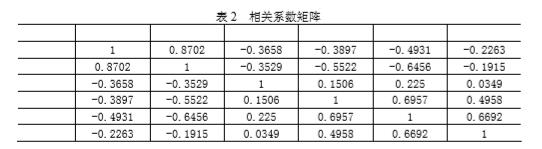
例:采用兰纳胡德(Linnerud)给出的关于体能训练的数据进行偏小二乘回归建 模。在这个数据系统中被测的样本点,是某健身俱乐部的 20 位中年男子。被测变量分 为两组。第一组是身体特征指标 X ,包括:体重、腰围、脉搏。第二组变量是训练结果指标Y ,包括:单杠、弯曲、跳高。原始数据见表 1。 表 2 给出了这 6 个变量的简单相关系数矩阵。从相关系数矩阵可以看出,体重与 腰围是正相关的;体重、腰围与脉搏负相关;而在单杠、弯曲与跳高之间是正相关的。 从两组变量间的关系看,单杠、弯曲和跳高的训练成绩与体重、腰围负相关,与脉搏正相关。
可以利用如下的MATLAB程序:
1 clc,clear
2 load pz.txt %原始数据存放在纯文本文件 pz.txt 中
3 mu=mean(pz);sig=std(pz); %求均值和标准差
4 rr=corrcoef(pz); %求相关系数矩阵
5 data=zscore(pz); %数据标准化,变量记做 X*和 Y*
6 n=3;m=3; %n 是自变量的个数,m 是因变量的个数
7 x0=pz(:,1:n);y0=pz(:,n+1:end); %原始的自变量和因变量数据
8 e0=data(:,1:n);f0=data(:,n+1:end); %标准化后的自变量和因变量数据
9 -679-
10 num=size(e0,1);%求样本点的个数
11 chg=eye(n); %w 到 w*变换矩阵的初始化
12 for i=1:n
13 %以下计算 w,w*和 t 的得分向量,
14 matrix=e0'*f0*f0'*e0;
15 [vec,val]=eig(matrix); %求特征值和特征向量
16 val=diag(val); %提出对角线元素,即提出特征值
17 [val,ind]=sort(val,'descend');
18 w(:,i)=vec(:,ind(1)); %提出最大特征值对应的特征向量
19 w_star(:,i)=chg*w(:,i); %计算 w*的取值
20 t(:,i)=e0*w(:,i); %计算成分 ti 的得分
21 alpha=e0'*t(:,i)/(t(:,i)'*t(:,i)); %计算 alpha_i
22 chg=chg*(eye(n)-w(:,i)*alpha'); %计算 w 到 w*的变换矩阵
23 e=e0-t(:,i)*alpha'; %计算残差矩阵
24 e0=e;
25 %以下计算 ss(i)的值
26 beta=t\f0; %求回归方程的系数,数据标准化,没有常数项
27 cancha=f0-t*beta; %求残差矩阵
28 ss(i)=sum(sum(cancha.^2)); %求误差平方和
29 %以下计算 press(i)
30 for j=1:num
31 t1=t(:,1:i);f1=f0;
32 she_t=t1(j,:);she_f=f1(j,:); %把舍去的第 j 个样本点保存起来
33 t1(j,:)=[];f1(j,:)=[]; %删除第 j 个观测值
34 beta1=[t1,ones(num-1,1)]\f1; %求回归分析的系数,这里带有常数项
35 cancha=she_f-she_t*beta1(1:end-1,:)-beta1(end,:); %求残差向量
36 press_i(j)=sum(cancha.^2); %求误差平方和
37 end
38 press(i)=sum(press_i);
39 Q_h2(1)=1;
40 if i>1, Q_h2(i)=1-press(i)/ss(i-1); end
41 if Q_h2(i)<0.0975
42 fprintf('提出的成分个数 r=%d',i); break
43 end
44 end
45 beta_z=t\f0; %求 Y*关于 t 的回归系数
46 xishu=w_star*beta_z; %求 Y*关于 X*的回归系数,每一列是一个回归方程
47 mu_x=mu(1:n);mu_y=mu(n+1:end); %提出自变量和因变量的均值
48 sig_x=sig(1:n);sig_y=sig(n+1:end); %提出自变量和因变量的标准差
49 ch0=mu_y-(mu_x./sig_x*xishu).*sig_y; %计算原始数据回归方程的常数项
50 for i=1:m
51 xish(:,i)=xishu(:,i)./sig_x'*sig_y(i); %计算原始数据回归方程的系数
52 end
53 sol=[ch0;xish] %显示回归方程的系数,每一列是一个方程,每一列的第一个数是常数项
54 save mydata x0 y0 num xishu ch0 xish
求解过程如下:

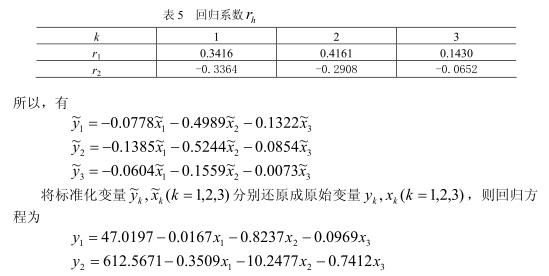

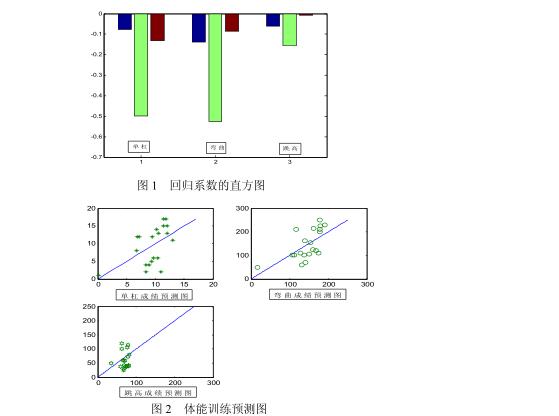
至此,偏最小二乘回归推导以及案例讲解完毕,通过第二部分可以了解片最小二乘回归的原理,这是论文正确写作的保证,参考第三部分可以使得你在具体应用中快速实现之,这是正确求解的保证。
参考:
《数学建模算法与引用》司守奎老师
pdf下载链接:
http://vdisk.weibo.com/s/t0L2pU6fgiP9L?category_id=0&parents_ref=t0L2pU6fgiPav

