
一次聊天,谈到了死锁的解决、可重入锁等等,突然发现这些离自己很远,只有一些读书时的概念涌入脑海,但各自的应用场景怎么都无法想出。痛定思痛,决定看看concurrent包里涉及并发的类及各自的应用场景。
第一类:原子操作类的atomic包,里面包含了
1)布尔类型的AtomicBoolean
2)整型AtomicInteger、AtomicIntegerArray、AtomicIntegerFieldUpdater
3)长整型AtomicLong、AtomicLongArray、AtomicLongFieldUpdater
4)引用型AtomicMarkableReference、AtomicReference、AtomicReferenceArray、AtomicReferenceFieldUpdater、AtomicStampedReference
5)累加器DoubleAccumulator、DoubleAdder、LongAccumulator、LongAdder、Striped64
java.util.concurrent.atomic原子操作类包
这个包里面提供了一组原子变量类。其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。实际上是借助硬件的相关指令来实现的,不会阻塞线程(或者说只是在硬件级别上阻塞了)。可以对基本数据、数组中的基本数据、对类中的基本数据进行操作。原子变量类相当于一种泛化的volatile变量,能够支持原子的和有条件的读-改-写操作。
java.util.concurrent.atomic中的类可以分成4组:
- 标量类(Scalar):AtomicBoolean,AtomicInteger,AtomicLong,AtomicReference
- 数组类:AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray
- 更新器类:AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater
- 复合变量类:AtomicMarkableReference,AtomicStampedReference
第一组AtomicBoolean,AtomicInteger,AtomicLong,AtomicReference这四种基本类型用来处理布尔,整数,长整数,对象四种数据,其内部实现不是简单的使用synchronized,而是一个更为高效的方式CAS (compare and swap) + volatile和native方法,从而避免了synchronized的高开销,执行效率大为提升。如AtomicInteger的实现片断为:
- 构造函数(两个构造函数)
- 默认的构造函数:初始化的数据分别是false,0,0,null
- 带参构造函数:参数为初始化的数据
- set( )和get( )方法:可以原子地设定和获取atomic的数据。类似于volatile,保证数据会在主存中设置或读取
- void set()和void lazySet():set设置为给定值,直接修改原始值;lazySet延时设置变量值,这个等价于set()方法,但是由于字段是volatile类型的,因此次字段的修改会比普通字段(非volatile字段)有稍微的性能延时(尽管可以忽略),所以如果不是想立即读取设置的新值,允许在“后台”修改值,那么此方法就很有用。
- getAndSet( )方法
- 原子的将变量设定为新数据,同时返回先前的旧数据
- 其本质是get( )操作,然后做set( )操作。尽管这2个操作都是atomic,但是他们合并在一起的时候,就不是atomic。在Java的源程序的级别上,如果不依赖synchronized的机制来完成这个工作,是不可能的。只有依靠native方法才可以。
public final int getAndSet(int newValue) { for (;;) { int current = get(); if (compareAndSet(current, newValue)) return current; } }
- compareAndSet( ) 和weakCompareAndSet( )方法
- 这 两个方法都是conditional modifier方法。这2个方法接受2个参数,一个是期望数据(expected),一个是新数据(new);如果atomic里面的数据和期望数据一 致,则将新数据设定给atomic的数据,返回true,表明成功;否则就不设定,并返回false。JSR规范中说:以原子方式读取和有条件地写入变量但不 创建任何 happen-before 排序,因此不提供与除 weakCompareAndSet 目标外任何变量以前或后续读取或写入操作有关的任何保证。大意就是说调用weakCompareAndSet时并不能保证不存在happen- before的发生(也就是可能存在指令重排序导致此操作失败)。但是从Java源码来看,其实此方法并没有实现JSR规范的要求,最后效果和 compareAndSet是等效的,都调用了unsafe.compareAndSwapInt()完成操作。
- 对于 AtomicInteger、AtomicLong还提供了一些特别的方法。
getAndIncrement( ):以原子方式将当前值加 1,相当于线程安全的i++操作。
incrementAndGet( ):以原子方式将当前值加 1, 相当于线程安全的++i操作。
getAndDecrement( ):以原子方式将当前值减 1, 相当于线程安全的i--操作。
decrementAndGet ( ):以原子方式将当前值减 1,相当于线程安全的--i操作。
addAndGet( ): 以原子方式将给定值与当前值相加, 实际上就是等于线程安全的i =i+delta操作。
getAndAdd( ):以原子方式将给定值与当前值相加, 相当于线程安全的t=i;i+=delta;return t;操作。
以实现一些加法,减法原子操作。(注意 --i、++i不是原子操作,其中包含有3个操作步骤:第一步,读取i;第二步,加1或减1;第三步:写回内存)
使用AtomicReference创建线程安全的堆栈
package thread; import java.util.concurrent.atomic.AtomicReference; public class ConcurrentStack<T> { private AtomicReference<Node<T>> stacks = new AtomicReference<Node<T>>(); public T push(T e) { Node<T> oldNode, newNode; for (;;) { // 这里的处理非常的特别,也是必须如此的。 oldNode = stacks.get(); newNode = new Node<T>(e, oldNode); if (stacks.compareAndSet(oldNode, newNode)) { return e; } } } public T pop() { Node<T> oldNode, newNode; for (;;) { oldNode = stacks.get(); newNode = oldNode.next; if (stacks.compareAndSet(oldNode, newNode)) { return oldNode.object; } } } private static final class Node<T> { private T object; private Node<T> next; private Node(T object, Node<T> next) { this.object = object; this.next = next; } } }
虽然原子的标量类扩展了Number类,但并没有扩展一些基本类型的包装类,如Integer或Long,事实上他们也不能扩展:基本类型的包装类是不可以修改的,而原子变量类是可以修改的。在原子变量类中没有重新定义hashCode或equals方法,每个实例都是不同的,他们也不宜用做基于散列容器中的键值。
第二组AtomicIntegerArray,AtomicLongArray还有AtomicReferenceArray类进一步扩展了原子操作,对这些类型的数组提供了支持。这些类在为其数组元素提供 volatile 访问语义方面也引人注目,这对于普通数组来说是不受支持的。
他们内部并不是像AtomicInteger一样维持一个valatile变量,而是全部由native方法实现,如下
AtomicIntegerArray的实现片断:
private static final Unsafe unsafe = Unsafe.getUnsafe(); private static final int base = unsafe.arrayBaseOffset(int[].class); private static final int scale = unsafe.arrayIndexScale(int[].class); private final int[] array; public final int get(int i) { return unsafe.getIntVolatile(array, rawIndex(i)); } public final void set(int i, int newValue) { unsafe.putIntVolatile(array, rawIndex(i), newValue); }
第三组AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater基于反射的实用工具,可以对指定类的指定 volatile 字段进行原子更新。API非常简单,但是也是有一些约束:
(1)字段必须是volatile类型的
(2)字段的描述类型(修饰符public/protected/default/private)是与调用者与操作对象字段的关系一致。也就是说 调用者能够直接操作对象字段,那么就可以反射进行原子操作。但是对于父类的字段,子类是不能直接操作的,尽管子类可以访问父类的字段。
(3)只能是实例变量,不能是类变量,也就是说不能加static关键字。
(4)只能是可修改变量,不能使final变量,因为final的语义就是不可修改。实际上final的语义和volatile是有冲突的,这两个关键字不能同时存在。
(5)对于AtomicIntegerFieldUpdater 和AtomicLongFieldUpdater 只能修改int/long类型的字段,不能修改其包装类型(Integer/Long)。如果要修改包装类型就需要使用AtomicReferenceFieldUpdater 。
netty5.0中类ChannelOutboundBuffer统计发送的字节总数,由于使用volatile变量已经不能满足,所以使用AtomicIntegerFieldUpdater 来实现的,看下面代码:
第二类:锁的类包,里面包含了
排他锁:AbstractOwnableSynchronizer、AbstractQueuedLongSynchronizer、AbstractQueuedSynchronizer
读写锁、可重入锁:ReadWriteLock、ReentrantLock、Lock、ReentrantReadWriteLock(隐式包含读锁和写锁)、Condition、LockSupport
混合锁:StampedLock
condition相似于对象的监控方法object#wait()、object#notify、object#notifyAll,但不同之处在于:通过和任意Lock的实现类联合使用,Condition对每个对象提供了多个等待-设置功能。
此时Lock代替了synchronized方法和模块,condition代替了对象的监控方法。
Condition通常也称作Condition队列或者condition变量,它提供了一种方法,使一个线程能够暂停执行(wait方法),当别的线程的状态condition为true时可以激活此线程。由于不同线程共享的状态信息必须受到保护,因此Condition具有一些锁的形式。等待一个condition的关键属性是自动释放关联的锁并且暂停当前线程,类似于object.wait。
Conditon示例内部绑定了一个锁,获取一个特定锁的实例的Condition实例可以通过lock#newCondition方法得到。
举个condition的示例,先看一下生产者和消费者模式常规代码:
/** * 生产指定数量的产品 * * @param neednum */ public synchronized void produce(int neednum) { //测试是否需要生产 while (neednum + curnum > max_size) { System.out.println("要生产的产品数量" + neednum + "超过剩余库存量" + (max_size - curnum) + ",暂时不能执行生产任务!"); try { //当前的生产线程等待 wait(); } catch (InterruptedException e) { e.printStackTrace(); } } //满足生产条件,则进行生产,这里简单的更改当前库存量 curnum += neednum; System.out.println("已经生产了" + neednum + "个产品,现仓储量为" + curnum); //唤醒在此对象监视器上等待的所有线程 notifyAll(); } /** * 消费指定数量的产品 * * @param neednum */ public synchronized void consume(int neednum) { //测试是否可消费 while (curnum < neednum) { try { //当前的生产线程等待 wait(); } catch (InterruptedException e) { e.printStackTrace(); } } //满足消费条件,则进行消费,这里简单的更改当前库存量 curnum -= neednum; System.out.println("已经消费了" + neednum + "个产品,现仓储量为" + curnum); //唤醒在此对象监视器上等待的所有线程 notifyAll(); }
我们希望保证生产者的produce线程和消费者的consume线程有不同的等待--设置,这样,当buffer中的项目或者空间可用时,我们只需要每次只通知一个单线程就可以了。优化只要使用两个Condition实例即可(略有改动):
class BoundedBuffer { final Lock lock = new ReentrantLock(); final Condition notFull = lock.newCondition(); final Condition notEmpty = lock.newCondition(); final Object[] items = new Object[100]; int putptr, takeptr, count; public void produce(Object x) throws InterruptedException { lock.lock(); try { while (count == items.length) notFull.await(); items[putptr] = x; if (++putptr == items.length) putptr = 0; ++count; notEmpty.signal(); } finally { lock.unlock(); } } public Object consume() throws InterruptedException { lock.lock(); try { while (count == 0) notEmpty.await(); Object x = items[takeptr]; if (++takeptr == items.length) takeptr = 0; --count; notFull.signal(); return x; } finally { lock.unlock(); } } }
java.util.concurrent.ArrayBlockingQueue提供了上述功能,因此没有必要实现这个示例的类。
Condition实现类可以提供和对象监控方法不同的行为和语义,例如保证通知的顺序,或者当执行通知时不要求保持一个锁。若condition实现类提供了上述特定的语义,那么实现类必须以文档的形式声明这些语义。
ReentrantReadWriteLock的读锁与写锁
读锁是排写锁操作的,读锁不排读锁操作,多个读锁可以并发不阻塞。在读锁获取和读锁释放之前,写锁并不能被任何线程获取。多个读锁同时作用期间,试图获取写锁的线程都处于等待状态,当最后一个读锁释放后,试图获取写锁的线程才有机会获取写锁。
写锁是排写锁,排读锁操作的。当一个线程获取到写锁之后,其他试图获取写锁和试图获取读锁的线程都处于等待状态,直到写锁被释放。
同时,写锁中是可以获取读锁,但是读锁中是无法获取写锁的。
下面的是java的ReentrantReadWriteLock官方示例,来解读一下吧。
class CachedData { Object data; volatile boolean cacheValid; final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock(); void processCachedData() { rwl.readLock().lock();// @1 if (!cacheValid) { // Must release read lock before acquiring write lock rwl.readLock().unlock(); // @3 rwl.writeLock().lock(); // @2 try { // Recheck state because another thread might have // acquired write lock and changed state before we did. if (!cacheValid) { data = ... cacheValid = true; } // Downgrade by acquiring read lock before releasing write lock rwl.readLock().lock(); //@4 } finally { rwl.writeLock().unlock(); // Unlock write, still hold read @5 } } try { use(data); } finally { rwl.readLock().unlock(); // 6 } }
当ABC三个线程同时进入到processcachedData()方法,同时都会得到读锁,然后获取cachevalid,然后走到3位置释放读锁,同时,假设A线程获取到写锁,所以BC线程就无法获取到写锁,这个时候进来的D线程就会停留在1位置而无法获取读锁。A线程继续往下走,判断到cachevalid还是false,就会继续走下去。为什么这个地方会还有一次判断,上面注释很清楚,A线程写完之后,BC线程获取到写锁,如果不再次进行判断,就会写入新的数据了,就不再是同步锁了。所以这个地方有一个新的判断。回到A线程,A线程继续进行操作,到达4之后,获取到读锁,这个地方api官方解释就是,写锁要释放的时候,必须先降级成读锁,这样其他在等待写锁的比如BC,就不会获取到写锁了。然后释放写锁,这就是写锁的降级,释放写锁之后,因为还持有读锁,所以BC线程无法获取到写锁,只有在A线程执行到6的时候,BC线程才会拿到写锁,进行判断,就会发现数据已经有了,释放写锁,释放读锁。
读写锁能够有效的在读操作明显大于写操作的需求中完成高效率的运转。
第三类:并发数据结构,包含了array、linkedList、set、map、list、queue等并发数据结构,包含如下:
阻塞数据结构:ArrayBlockingQueue、BlockingDeque、BlockingQueue、LinkedBlockingDeque、LinkedBlockingQueue、PriorityBlockingQueue、
并发数据结构:ConcurrentHashMap、ConcurrentLinkedDeque、ConcurrentLinkedQueue、ConcurrentMap、ConcurrentNavigableMap、ConcurrentSkipListMap、ConcurrentSkipListSet
第四类:同步器 ,这部分主要是对线程集合的管理的实现,有Semaphore,CyclicBarrier, CountDownLatch,Exchanger等一些类。
Semaphore
类 java.util.concurrent.Semaphore 提供了一个计数信号量,从概念上讲,信号量维护了一个许可集。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release()添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore只对可用许可的号码进行计数,并采取相应的行动。
Semaphore 通常用于限制可以访问某些资源(物理或逻辑的)的线程数目。 示例如下:
import java.util.*;import java.util.concurrent.*; public class SemApp { public static void main(String[] args) { Runnable limitedCall = new Runnable() { final Random rand = new Random(); final Semaphore available = new Semaphore(3); int count = 0; public void run() { int time = rand.nextInt(15); int num = count++; try { available.acquire(); System.out.println("Executing " + "long-running action for " + time + " seconds... #" + num); Thread.sleep(time * 1000); System.out.println("Done with #" + num + "!"); available.release(); } catch (InterruptedException intEx) { intEx.printStackTrace(); } } }; for (int i=0; i<10; i++) new Thread(limitedCall).start(); } }
即使本例中的 10 个线程都在运行(您可以对运行 SemApp 的 Java 进程执行 jstack 来验证),但只有 3 个线程是活跃的。在一个信号计数器释放之前,其他 7 个线程都处于空闲状态。(实际上,Semaphore 类支持一次获取和释放多个 permit,但这不适用于本场景。)
CyclicBarrier
java.util.concurrent.CyclicBarrier 一个同步辅助类,它允许 (common barrier point),在在涉及一组固定大小的线程的程序中,这些线程必须不时地互相等待,此时 CyclicBarrier 很有用。一组线程互相等待,直到到达某个公共屏障点。因为该 barrier 在释放等待线程后可以重用,所以称它为循环的 barrier。
需要所有的子任务都完成时,才执行主任务,这个时候就可以选择使用CyclicBarrier。赛跑时,等待所有人都准备好时,才起跑:
public class CyclicBarrierTest { public static void main(String[] args) throws IOException, InterruptedException { //如果将参数改为4,但是下面只加入了3个选手,这永远等待下去 //Waits until all parties have invoked await on this barrier. CyclicBarrier barrier = new CyclicBarrier(3); ExecutorService executor = Executors.newFixedThreadPool(3); executor.submit(new Thread(new Runner(barrier, "1号选手"))); executor.submit(new Thread(new Runner(barrier, "2号选手"))); executor.submit(new Thread(new Runner(barrier, "3号选手"))); executor.shutdown(); } } class Runner implements Runnable { // 一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point) private CyclicBarrier barrier; private String name; public Runner(CyclicBarrier barrier, String name) { super(); this.barrier = barrier; this.name = name; } @Override public void run() { try { Thread.sleep(1000 * (new Random()).nextInt(8)); System.out.println(name + " 准备好了..."); // barrier的await方法,在所有参与者都已经在此 barrier 上调用 await 方法之前,将一直等待。 barrier.await(); } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } System.out.println(name + " 起跑!"); } }
输出结果:
3号选手 准备好了... 2号选手 准备好了... 1号选手 准备好了... 1号选手 起跑! 2号选手 起跑! 3号选手 起跑!
CountDownLatch
类 java.util.concurrent.CountDownLatch 是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。 用给定的数字作为计数器初始化 CountDownLatch。一个线程调用 await()方法后,在当前计数到达零之前,会一直受阻塞。其他线程调用 countDown() 方法,会使计数器递减,所以,计数器的值为 0 后,会释放所有等待的线程。其他后续的 await 调用都将立即返回。
这种现象只出现一次,因为计数无法被重置。如果需要重置计数,请考虑使用 CyclicBarrier。
CountDownLatch 作为一个通用同步工具,有很多用途。使用“ 1 ”初始化的
CountDownLatch 用作一个简单的开/关锁存器,或入口:在通过调用 countDown() 的线程
打开入口前,所有调用 await 的线程都一直在入口处等待。用 N 初始化的 CountDownLatch
可以使一个线程在 N 个线程完成某项操作之前一直等待,或者使其在某项操作完成 N 次之前一直等待。
此类持有所有空闲线程,直到满足特定条件,这时它将会一次释放所有这些线程。
清单 2. CountDownLatch:让我们去赛马吧!
import java.util.*;
import java.util.concurrent.*;
class Race
{
private Random rand = new Random();
private int distance = rand.nextInt(250);
private CountDownLatch start;
private CountDownLatch finish;
private List<String> horses = new ArrayList<String>();
public Race(String... names)
{
this.horses.addAll(Arrays.asList(names));
}
public void run()
throws InterruptedException
{
System.out.println("And the horses are stepping up to the gate...");
final CountDownLatch start = new CountDownLatch(1);
final CountDownLatch finish = new CountDownLatch(horses.size());
final List<String> places =
Collections.synchronizedList(new ArrayList<String>());
for (final String h : horses)
{
new Thread(new Runnable() {
public void run() {
try
{
System.out.println(h +
" stepping up to the gate...");
start.await();
int traveled = 0;
while (traveled < distance)
{
// In a 0-2 second period of time....
Thread.sleep(rand.nextInt(3) * 1000);
// ... a horse travels 0-14 lengths
traveled += rand.nextInt(15);
System.out.println(h +
" advanced to " + traveled + "!");
}
finish.countDown();
System.out.println(h +
" crossed the finish!");
places.add(h);
}
catch (InterruptedException intEx)
{
System.out.println("ABORTING RACE!!!");
intEx.printStackTrace();
}
}
}).start();
}
System.out.println("And... they're off!");
start.countDown();
finish.await();
System.out.println("And we have our winners!");
System.out.println(places.get(0) + " took the gold...");
System.out.println(places.get(1) + " got the silver...");
System.out.println("and " + places.get(2) + " took home the bronze.");
}
}
public class CDLApp
{
public static void main(String[] args)
throws InterruptedException, java.io.IOException
{
System.out.println("Prepping...");
Race r = new Race(
"Beverly Takes a Bath",
"RockerHorse",
"Phineas",
"Ferb",
"Tin Cup",
"I'm Faster Than a Monkey",
"Glue Factory Reject"
);
System.out.println("It's a race of " + r.getDistance() + " lengths");
System.out.println("Press Enter to run the race....");
System.in.read();
r.run();
}
}
注意,CountDownLatch 有两个用途:首先,它同时释放所有线程,模拟马赛的起点,但随后会设置一个门闩模拟马赛的终点。这样,“主” 线程就可以输出结果。 为了让马赛有更多的输出注释,可以在赛场的 “转弯处” 和 “半程” 点,比如赛马跨过跑道的四分之一、二分之一和四分之三线时,添加 CountDownLatch。
Exchanger
类 java.util.concurrent.Exchanger 提供了一个同步点,在这个同步点,一对线程可以交换
数据。每个线程通过 exchange()方法的入口提供数据给他的伙伴线程,并接收他的伙伴线程
提供的数据,并返回。
线程间可以用 Exchanger 来交换数据。当两个线程通过 Exchanger 交互了对象,这个交换对于两个线程来说都是安全的。
Future 和 FutureTask
接口 public interface Future<V> 表示异步计算的结果。它提供了检查计算是否完成的方法,
以等待计算的完成,并调用get()获取计算的结果。
FutureTask 类是 Future 的一个实现, 并实现了Runnable ,所以可通过 Executor(线程池) 来执行。
也可传递给Thread对象执行。
如果在主线程中需要执行比较耗时的操作时,但又不想阻塞主线程时,可以把这些作业交给
Future 对象在后台完成,当主线程将来需要时,就可以通过 Future 对象获得后台作业的计算结果或者执行状态。
第五类:线程管理,
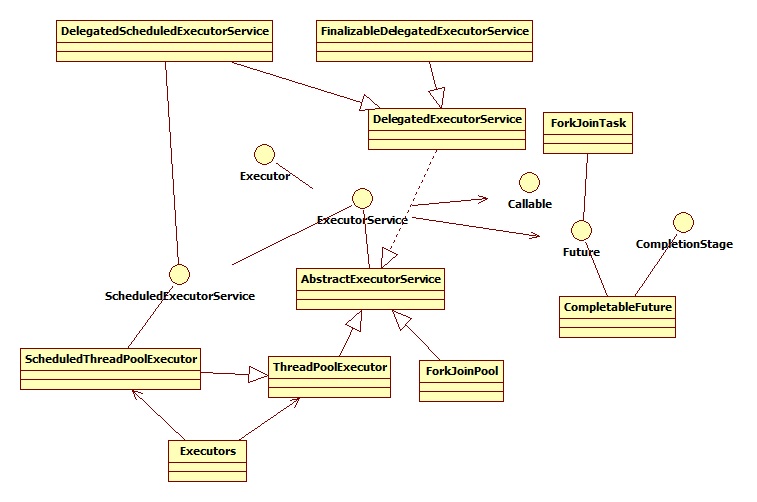
- Executor是总的接口,用来执行Runnable任务;
- ExecutorService是Executor的扩展接口,主要扩展了执行Runnable或Callable任务的方式,及shutdown的方法;
- ScheduledExecutorService是ExecutorService的扩展接口,主要扩展了可以用任务调度的形式(延迟或定期)执行Runnable或Callable任务;
- AbstractExecutorService是ExecutorService接口的实现类,是抽象类,提供一些默认的执行Runnable或Callable任务的方法;
- ThreadPoolExecutor是AbstractExecutorService的子类,是线程池的实现;
- ScheduledThreadPoolExecutor是ThreadPoolExecutor的子类,实现ScheduledExecutorService接口,基于线程池模式的多任务调度,是Timer工具类的高性能版;
- Callable与Future是Runnable的另外的形式,用来异步获取任务执行结果;
- 最后,Executors是工具类,用于创建上述各种实例。
Q&A
Synchronization vs volatile
Synchronization supports mutual exclusion and visibility. In contrast, the volatile keyword only supports visibility.
参考文献:
【1】http://niub.iteye.com/blog/1787639
【2】http://www.ibm.com/developerworks/cn/java/j-5things5.html
【3】http://www.itzhai.com/
【4】http://chenzehe.iteye.com/blog/1759884
【5】http://www.javaworld.com/article/2078809/java-concurrency/java-concurrency-java-101-the-next-generation-java-concurrency-without-the-pain-part-1.html
【6】http://www.javaworld.com/article/2078848/java-concurrency/java-concurrency-java-101-the-next-generation-java-concurrency-without-the-pain-part-2.html
【7】http://gaozp.github.io/tec/2015/03/17/reentrantreadwritelock.html

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号