


(原)Ring loss Convex Feature Normalization for Face Recognition
转载请注明出处:
http://www.cnblogs.com/darkknightzh/p/8858998.html
论文:
Ring loss: Convex Feature Normalization for Face Recognition
https://arxiv.org/abs/1803.00130v1
理解的不对的地方请见谅
Ring loss将特征限制到缩放后的单位圆上,同时能保持凸性,来得到更稳健的特征。
该损失函数作为辅助的损失,结合Softmax或者A-softmax等损失函数,来学习到特征的模,因而唯一的超参数就是ring loss的权重。论文中在权重为0.01时效果最好。
论文中指出,arcface,cosface等在训练时,损失函数之前将特征进行了归一化,但网络实际上并未学习到归一化的特征。如下图所示,a为训练样本的特征分布,b为测试样本的特征分布,训练样本特征均集中在一定的夹角范围内。但是对于测试样本中模比较小的,其变化范围比较大。

令F为深度模型,x为输入图像,则F(x)为特征。可优化下面的损失函数:
$\min {{L}_{s}}(F(x))\text{ s}\text{.t}\text{. }{{\left\| F(x) \right\|}_{2}}=R$
R为归一化后特征的模。由于模的等式限制,导致实际上该损失函数是非凸的(这句话不太确定怎么翻译,反正是非凸)。
因而Ring loss定义如下:
${{L}_{R}}=\frac{\lambda }{2m}\sum\limits_{i=1}^{m}{{{({{\left\| F({{x}_{i}}) \right\|}_{2}}-R)}^{2}}}$
相应的梯度计算如下:
$\frac{\partial {{L}_{R}}}{\partial R}=-\frac{\lambda }{m}\sum\limits_{i=1}^{m}{({{\left\| F({{x}_{i}}) \right\|}_{2}}-R)}$
$\frac{\partial {{L}_{R}}}{\partial F({{x}_{i}})}=\frac{\lambda }{m}(1-\frac{R}{{{\left\| F({{x}_{i}}) \right\|}_{2}}})F({{x}_{i}})$
上式中R为特征模的长度,类似于cosface及arcface中使用到的s,只不过s是提前设定的(将特征的模归一化,并放大到该值),如30,而此处的R是通过训练学到的。m为batchsize, 为Ring loss的权重。实际使用时,可以结合softmax loss/A-softmax loss。Softmax/A-softmax loss为主损失函数,Ring loss为辅助损失函数。论文中 为0.01时,训练效果最好。
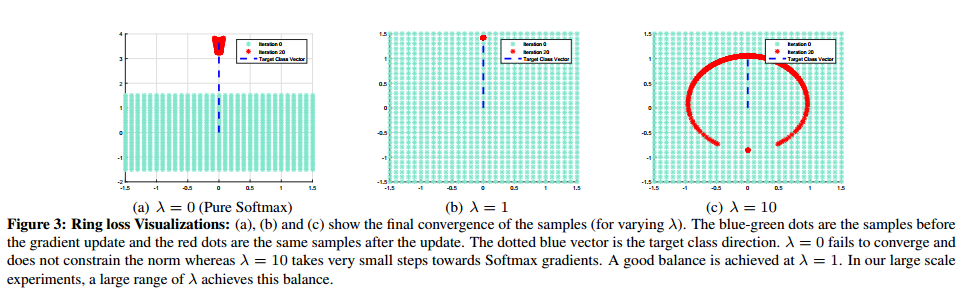
下图是一个简单的例子,其中绿色点为初始化的点,蓝色的为目标类别,红色的为经过20次训练后,特征的分布。a为使用softmax的结果;b为使用ring loss,权重为1;c为使用ring loss,权重为10。可见,使用softmax后,特征收敛到比较大的范围。由于使用ring loss时,设置的特征模长为1,因而b能收敛到比较合理的位置(特征较集中)。当权重太大时,softmax起的作用很小,导致特征收敛到单位圆上,如c所示。因而需要合理的权重来平衡辅助损失函数ring loss和主损失函数。
论文中在MsCeleb1M(31000人,3.5M图像)上训练64层的resnet网络,性能比较好。
我这边在pytorch中进行了实现,初始化时R为0-30之间的随机数,在casia上训练resnet20的网络,效果稍微好于直接使用softmax训练后的模型(softmax的dir78%,ring loss的dir:不到80%。这两个模型均使用了batchnorm,否则dir没有这么高。。。)。
posted on 2018-04-16 22:34 darkknightzh 阅读(1659) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号