


多线程技术点-JDK并发包-线程池-分而治之:Fork/Join框架
分而治之
一个非常有效地处理大量数据的方法。著名的MapReduce也是采取分而治之的思想。简单来说,就是如果你要处理1000个数据,但是你并不具备处理1000个数据的能力,那么你可以只处理其中的10个,然后分阶段处理100次,将100次的结果进行合并,那就是最终想要的对原始1000个数据的处理结果。
Fork/Join框架
Java中通过使用fork()后系统多了一个执行分支(线程),索引需要等待这个执行分支执行完毕,才有可能得到最终结果,因此join就表示等待。
如果毫无顾忌地使用fork()开启线程进行处理,那么很有可能导致系统开启过多的线程而严重影响性能。所有JDK提供了一个ForkJoinPool线程池,对于fork()方法并不急着开启线程,而是提交给ForkJoinPool线程池处理,以节省系统资源。
ForkJoinPool线程池
流程图

注:由于线程池的优化,提交的任务和线程数量并不是一对一的关系。在绝大多数情况,一个物理线程实际上是需要处理多个逻辑任务的。因此,每个线程必然需要拥有一个任务队列。因此在实际执行过程中,可能遇到这种情况:线程A已经把自己的任务都执行完成了,而线程B还有一堆任务等着处理,此时,线程A就会"帮助"线程B,从线程B的任务队列中拿一个任务过来处理,尽可能地达到平衡。如下图,显示了这种互相帮助的精神。值得注意的是,当线程师徒帮助别人时,总是从任务队列底部开始拿数据,而线程试图执行自己的任务时,则是从相反的顶部开始拿,因此这种行为有利于避免数据竞争。

ForkJoinPool重要的方法
/** * 参数中的ForkJoinTask任务就是支持fork()分解以及join()等待的任务 * ForkJoinTask有两个重要的子类,RecuriveAction额RecuriveTask,分别表示没有返回值的任务和有返回值的任务。 * @param task 待提交任务接口类 * @return */ public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task)
图解
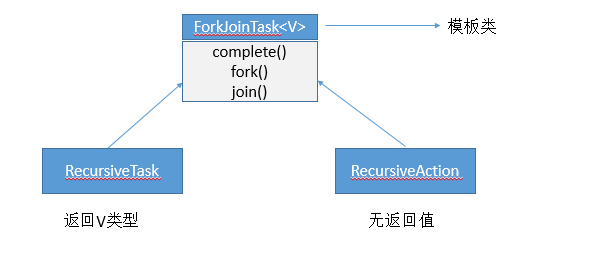
例子
package com.dsd.jdk.executor.forkjoin; import java.util.ArrayList; import java.util.List; import java.util.concurrent.ExecutionException; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.ForkJoinTask; import java.util.concurrent.RecursiveTask; /** * 有返回值的任务 * @author daishengda * */ public class CountTask extends RecursiveTask<Long>{ /** * */ private static final long serialVersionUID = -8569760326589318177L; private static final int THRESHOLD = 10000; private long start; private long end; public CountTask(long start, long end) { this.start = start; this.end = end; } /** * THRESHOLD设置了任务分解的规模,也就是需要求和的总数大于THRESHOLD个,那么任务就需要再次分解,否则可以直接执行, * 如果任务可以直接执行,那么直接进行求和并返回结果;否则,就对任务再次分解。 * 每次分解是将原有任务划分成100个等规模的小任务,并使用fork()提交子任务。之后等待所有的子任务结束,并通过join()将结果求和。 */ @Override public Long compute() { long sum = 0; boolean canCompute = (end - start) < THRESHOLD; if(canCompute) { for (long i = start; i <= end; i++) { sum += i; } } else { //分成100个小任务 long step = (start + end) / 100; List<CountTask> subTasks = new ArrayList<CountTask>(); long pos = start; for (int i = 0; i < 100; i++) { long lastOne = pos+step; if(lastOne > end) lastOne = end; CountTask subTask = new CountTask(pos, lastOne); pos += step+1; subTasks.add(subTask); subTask.fork(); } for (CountTask t : subTasks) { sum += t.join(); } } return sum; } public static void main(String[] args) { ForkJoinPool forkJoinPool = new ForkJoinPool(); /** * 构造一个计算1到200000求和的任务。将任务提交给线程池ForkJoinPool * 线程池会返回一个有返回值的任务 */ CountTask task = new CountTask(0L, 200000L); ForkJoinTask<Long> result = forkJoinPool.submit(task); try { //通过get()方法可以得到最终结果,如果任务没有结束,那么主线程就会在get()方法阻塞等待 long res = result.get(); System.out.println("sum="+res); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } }
注:如果任务的划分层次很深,一直得不到返回,那么可能出现两种情况:1、系统内的线程数量越积越多,导致性能严重下降。2、函数的调用层次变得很深,最终导致栈溢出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号