
文本分类学习 (五) 机器学习SVM的前奏-特征提取(卡方检验续集)
前言:
上一篇比较详细的介绍了卡方检验和卡方分布。这篇我们就实际操刀,找到一些训练集,正所谓纸上得来终觉浅,绝知此事要躬行。然而我在躬行的时候,发现了卡方检验对于文本分类来说应该把公式再变形一般,那样就完美了。
目录:
- 文本分类学习(一)开篇
- 文本分类学习(二)文本表示
- 文本分类学习(三)特征权重(TF/IDF)和特征提取
- 文本分类学习(四)特征选择之卡方检验
- 文本分类学习(五)机器学习SVM的前奏-特征提取(卡方检验续集)
一,回顾卡方检验
1.公式一:
先回顾一下卡方检验:
卡方检验:事先做一个假设,计算由有假设得来的理论值于实际观察值之间的偏差来推断这个假设是否成立,公式:
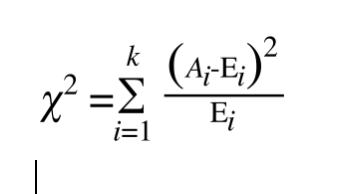
2.四表格的卡方检验公式:
卡方检验对于文本分类:每个词对于每个类别,使用四表格的形式,计算该词对于该类是否有较大的影响,公式:

二,训练集的准备
我选择了复旦语料库中的历史篇:469篇
每篇的格式大多如下:


【 文献号 】1-1408 【原文出处】科技日报 【原刊地名】京 【原刊期号】19960825 【原刊页号】⑵ 【分 类 号】K91 【分 类 名】中国地理 【 作 者 】于希贤 【复印期号】199610 【 标 题 】历史上中国地理环境的几次突变 【 正 文 】 在人类历史时期,特别是有文字记载的近几千年来地理环境有没有变化?有多大变化?是怎样变化的?这是人们普遍关心的问题,也是学 术界长期争论不休的问题之一。 以气候而言,古代欧洲亚里士多德相信寒冷而多雨的气候是周期循环的。此后19世纪至20世纪初,德国的汉恩和法国的阿拉哥为代表 ,倡导气候不变论。直至本世纪70年代,把地理环境的变化仅误认为是一种单纯的“缓慢的渐进作用”。甚至认为不因人的活动,自然环境 的变化是非常微小的。 事实上,有史时代人类生活的地理环境,不仅有其相对缓慢变化的平静时期,也有其激烈动荡的突变时期。 地理环境中自然灾异的群发性和集中突发性形成了地理环境的突变。如火山喷发、地震山崩、海浸海退、大雨洪水、江河泛滥、干旱螟蝗 、瘟疫肆虐、大雪奇寒、生物聚集、变迁和大规模迁徙,奇特的天文现象(太阳黑子、流星雨等),这样一些灾异在近几千年来有时出现多而 集中,这就是突变期;有时出现少而分散,这是渐变期。 根据历史文献记载和考古及历史地理野外调查,初步至少提出以下一些灾变期。 大约距今4000年前后有洪水灾变期。 在中国、欧洲和中近东的许多民族如巴比伦、波斯、印度等都广泛地有洪水灾变的记载和传说。《尚书·尧典》首记其事“汤汤怀山襄陵 ,浩浩滔天”。《孟子·滕文公》说:“昔尧之时,天下犹未平,洪水横流,泛滥于天下……”。当今的考古发掘与上述记述相吻合。距今4 000年前后,黄河下游曾大改道。洪水发生的地域正是《禹贡》九州中的兖州、豫州和徐州。考古学家俞伟超教授研究说:中国北方的龙山 文化和江浙一带的良渚文化一度都达到了相当高度的文明。“距今4000年之时,情况忽然大变。龙山文化变为岳石文化,良渚文化也突然 变为马桥、湖熟文化。……时代虽然前后相接、文化面貌却缺乏紧密的承袭关系。……岳石与马桥、湖熟诸文化遗址分布密度、居址的面积、 乃至文化本身的产生、生活水平,又皆远远低于龙山、良渚文化”。他指出“这是因为生产、生活环境发生了巨大变化,族群人口大为减少, 文化处于低落时期的遗存。”据此,他推断说:“4000多年以前我国曾发生一次延续若干年的洪水大灾难,应该是历史事实。” 距今2100多年前,我国逐步进入另一次灾变时期,其高潮是公元2年至57年间。 西汉末年曾发生了渤海海湾西岸大海浸。《汉书·沟洫志》记载“河入勃海……海水溢西南出,浸九百里,九河之地已为东海所渐矣”。 宋代的学者认为自碣石以西现今整个勃海湾在此之前全是陆地。谭其骧教授研究认为“其海浸范围当今渤海湾4米等高线以下”。今天津、黄 骅、宁海一带有几十处文化遗址,它们不是东周、西汉时期,就是隋唐时期。其间独缺失东汉魏晋南北朝时期的文化遗址。笔者在武清县雍奴 故城遗址上发现海相地层。在西汉泉州故城遗址上已湮没2米深淤泥。当时确有大海浸。海浸之前的许多村落、城市被海相地层压置。至公元 6世纪海水退出,又才有新的村落与文化层。当中独缺失公元1—5世纪的人类活动痕迹。 《汉书·五行志》载,“汉成帝和平元年(前28)三月己未(14日)日出黄,有黑气大如钱,居日中央”,这条记载是世界上公认的 太阳黑子活动的最早记录。此黑子之大,为后世罕见。 公元11年黄河在今河北大名决口泛滥,祸及河东数郡。这次水灾延续了60年。至公元70年才由王景领导的数十万民工治好。据邓云 特统计,这57年中共发生9次特大蝗灾,8次特大水灾,3次特大瘟疾,致使“死者十之七八”。公元2年全国人口5900多万,至公元 57年全国人口仅有2100多万,减少了3800多万。 公元9—12世纪的寒冷灾变期。 赫连勃勃的夏国首都统万城(今陕西横山西北)原先是一片“临广泽而带清流”的美丽城市。至公元882年已“堆沙高及城堞”。又过 100年已“深在沙漠”之中了。公元925年两汉大水,户口流亡者十之四五。938年定州大旱民多流散。943年春夏旱,秋冬水。蝗 大起,东自海滨,西抵陇坻,南逾江淮,北至幽冀,原野山谷,城郭庐舍皆满,竹木俱尽,……民馁者数十万口,流亡不可胜数。朱熹统计, 有史以来黄河大决16次,其中五代半个世纪内,就占了9次,至北宋尤甚。 16—17世纪寒冷灾变期。 长白山主峰白头山两次喷发过。黑龙江德都火山1720年前后也喷发过。云南腾冲打鹰山在1611年前后也喷发过。公元1555年 陕西、山西、河南同时大地震。此期水灾、旱灾很多,尤以大雪奇寒为甚。1616年黄山连续积雪达130多天,河南嵩山1623年“雪 深道绝”。太华山泓谷至阴历三月初三还“层冰积雪,状满谷间”。1628年福建顺昌于阴历三月十九还“群峰积雪,有如环玉”。163 3年阴历八月初六日五台山仍“滴水皆冰”“阴崖悬冰数百丈”。依据种种资料证实,此冷期“摆动范围”远比竺可桢确定的±2℃为大,冬 半年当较今冷6—8℃左右。 明末灾异的群发性与突发性,使当时官员金士衡在“邸报”中总结说:“举报重极大之灾,至怪至异之事,毕集于一时”。 总之,从有史时代地理环境几千年的变异来看,一方面要正视地理环境的突变,灾异群的出现会给人类社会造成明显甚至是重大的影响。 地理环境的变化参与了人类历史发展演化的进程。另一方面也应当看到地理环境几千年来的灾变,并没有造成“世界末日”。科学的态度是从 查清历史事实中,使人们有一个清醒的认识和恰当的选取对策。 (作者系北京大学地理系教授、中国地理学会历史地理专业委员会副主任)*
自己爬了博客园的博客:420篇
选择一篇贴出来:
Redis特性和应用场景 Redis特性 速度快 Redis使用标准C编写实现,而且将所有数据加载到内存中,所以速度非常快。官方提供的数据表明,在一个普通的Linux机器上,Redis读写速度分别达到81000/s和110000/s。 数据结构 可以将Redis看做“数据结构服务器”。目前,Redis支持5种数据结构。 持久化 由于所有数据保持在内存中,所以对数据的更新将异步地保存到磁盘上,Redis提供了一些策略来保存数据,比如根据时间或更新次数。数据超过内存,使用swap,保证数据; memcacache不能持久化,mongo是部分在内存; 自动操作 Redis对不同数据类型的操作是自动的,因此设置或增加key值,从一个集合中增加或删除一个元素都能安全的操作。 支持多种语言 Redis支持多种语言,诸如Ruby,Python, Twisted Python, PHP, Erlang, Tcl, Perl, Lua, Java, Scala, Clojure等。 主-从复制 Redis支持简单而快速的主-从复制。 官方提供了一个数据,Slave在21秒即完成了对Amazon网站10Gkey set的复制。 Sharding 很容易将数据分布到多个Redis实例中,但这主要看该语言是否支持。目前支持Sharding功能的语言只有PHP、Ruby和Scala。 1. redis数据使用方式 redis 的作者antirez曾笑称其为一个数据结构服务器(data structures server),redis的所有功能就是将数据以其固有的几种结构保存,并提供给用户操作这几种结构的接口。我们可以想象我们在各种语言中的那些固有数据类型及其操作。 Redis的几种使用方式 Strings Hashs Lists Sets Sorted Sets Pub/Sub Redis的七种特性以及适合的应用场景: 1.1. Strings Strings 数据结构是简单的key-value类型,value其实不仅是String,也可以是数字。使用Strings类型,完全实现目前 Memcached 的功能,并且效率更高。还可以享受Redis的定时持久化,操作日志及 Replication等功能。除了提供与 Memcached 一样的get、set、incr、decr 等操作外,Redis还提供了下面一些操作: 获取字符串长度 strlen 往字符串append内容 append 设置和获取字符串的某一段内容 setrange getrange 设置及获取字符串的某一位getrange 批量设置一系列字符串的内容 String是最简单的数据类型,一个key对应一个Value,String是二进制安全的。它可以包含任何数据,图片或者其他序列化后的对象 方法 说明 特性 set 设置key对应的的值为String类型的value get 获取对应key对应的String的值,如果不存在返回nil setnx 设置可以为对应的值为String类型的value,如果key存在返回0不覆盖,不存在返回1 nx的意思为not exist Set the value of a key, only if the key does not exist setex 置key对应的值为String类型的value,并指定此键值对应的有效期 SETEX key seconds value 例:setex mykey 10 你好 setrange 设置key的value的子字符串 setrange key 位置 替换的内容 如果替换内容没有原value长,则原value剩余的内容将被保留 mset 一次设置多个key的值,成功返回ok,失败返回0,要成功都成功,要不成功全部失败。 mset key1 内容一 key2 内容二 msetnx 一次设置多个key的值,成功返回ok,失败返回0,不覆盖已经存在的值,要成功都成功,要失败都失败。 getset 设置key的值并返回key的旧值 getset key newValuse getrange 获取key对应的value子字符串 getrange key 0 5 //获取前6个字符 mget 批量获取 mget key1 key2 key3 //没有设置则返回空 incr 对key的值做增加操作,并返回新的值 +1 incrby 对可以的value加指定的值, key如果不存在会设置key并value为0 incrby key1 5 //对key1的值加5 decr 对key的值做减减操作 -1 decrby 对key的值减去指定值 append 给指定key的字符串追加value,返回新的字符串长度 strlen 取指定key的value值的长度 1.2. Hashs 在Memcached中,我们经常将一些结构化的信息打包成hashmap,在客户端序列化后存储为一个字符串的值,比如用户的昵称、年龄、性别、积分等,这时候在需要修改其中某一项时,通常需要将所有值取出反序列化后,修改某一项的值,再序列化存储回去。这样不仅增大了开销,也不适用于一些可能并发操作的场合(比如两个并发的操作都需要修改积分)。而Redis的Hash结构可以使你像在数据库中Update一个属性一样只修改某一项属性值。 它是一个String类型的field和value的映射表,它的添加和删除都是平均的,hash特别适合用于存储对象,对于将对象存储成字符串而言,hash会占用更少的内存,并且可以更方便的存取整个对象. 它和java的HashMap完全类似 方法 说明 特性 hset 设置一个hash 的field为指定值,如果key不存在则先创建 hset tab ke1 val1 hget 获取某个hash的某个field值 hget tab ke1 hsetnx 类似string只是操作的是hash hmset 批量设置hash的内容 hmget 获取hash表的全部key值 Hmget key field1 field2 hincrby 给hash表的某个字段增加值 hexists 判断hash表中某个key是否存在 hlen 返回hash表中的key数量 hdel 删除指定hash表的某个键值对 hkeys 返回hash表中所有的key hvals 返回hash表中所有的value hgetall 获取hash表中所有key和value 1.3. Lists Lists 就是链表,略有数据结构知识的人都应该能理解其结构。使用Lists结构,我们可以轻松地实现最新消息排行等功能。Lists的另一个应用就是消息队列,可以利用Lists的PUSH操作,将任务存在Lists中,然后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作Lists中某一段的api,你可以直接查询,删除Lists中某一段的元素。 Redis的list是每个子元素都是String类型的双向链表,可以通过push和pop操作从列表的头部或者尾部添加或者删除元素,这样List即可以作为栈,也可以作为队列。 方法 说明 特性 lpush 在key所对应的list头部添加一个元素 l的意思是left rpush 在key说对应的list尾部添加一个元素 r的意思是right lrange 显示list里面的内容 lrange 0 -1 //全部显示 linsert 在key对应的list linsert mylist before one myvalue lset 设置list中指定下标元素的值 lset mylist index myvalue lrem 从key对应的list中删除n个和value相同的元素,结果返回影响元素的个数,n<0从尾部开始删除,n=0全删除 lrem mylist count "value" ltrim 保留指定key范围内的数据,返回ok成功 ltrim mylist 0 3 //0-3是保留的范围 lpop 从list的头部删除一个元素,并返回该删除的元素 rpop 从list的尾部弹出一个元素,并返回该删除的元素 rpoplpush 从第一个list的尾部元素异常元素并添加到第二个list的头部 rpoplpush mylistA mylistB lindex 返回list位置的元素 lindex mylist 3 llen 返回list中元素的个数 llen mylist 1.4. Sets Sets 就是一个集合,集合的概念就是一堆不重复值的组合。利用Redis提供的Sets数据结构,可以存储一些集合性的数据。 案例: 在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。 Set是集合,是String类型的无序集合,set是通过hashtable实现的,概念和数学中个的集合基本类似,可以交集,并集,差集等等,set中的元素是没有顺序的。 方法 说明 特性 sadd 向名称为key的set中添加元素,返回影响元素的个数,0为失败,1为成功 sadd myset value smembers 查看集合中所有的成员 smebers myset srem 删除集合的一个元素 srem myset two spop 随机返回并删除set中一个元素 spop myset sdiff 返回所有set与第一个set的差集 sdiff myset1 myset2 sdiffstore 比较差集并且存储到另一个set中,返回1代表成功 sdiffstore setstoreSet mySet1 myset2 sinter 返回所有给定集合的交集 sinter myset1 mysert2 //1集合和2集合的交集 sinterstore 返回给定集合的交集并存储到另一个集合 sinterstore desset myset1 myset2 //存到desset集合中 sunion 返回所有给定集合的并集 sunion set1 set2 sunionstore 返回所有的并集并且存储到另一个集合中,返回影响的元素个数 sunionstore destSet myset1 myset2 smove 把第一个集合的元素移动到第二个集合中 smove myset myset 你好 scard 返回集合中元素的个数 scard myset1 sismember 测试某个元素是否在集合中,返回0是不是,大于0是存在 sismember mykey1 你好 srandmember 随机返回个集合中的元素 srandmemeber myset1 1.5. Sorted Sets 和Sets相比,Sorted Sets增加了一个权重参数score,使得集合中的元素能够按score进行有序排列,比如一个存储全班同学成绩的Sorted Sets,其集合value可以是同学的学号,而score就可以是其考试得分,这样在数据插入集合的时候,就已经进行了天然的排序。 案例: 可以用Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。 Zset类型 它是set的一个升级版本,在set的基础上增加了顺序,这一属性在添加修改元素时可以指定,每次指定后,zset会自动按新的值调整顺序。 方法 说明 特性 zadd 向zset中添加元素member,score 用于排序,如果元素存在,则更新其顺序,返回0代表没添加成功 ZADD key score member zadd myset 3 itim zrange 取出集合中的元素 zrange myset 0 -1 withscores//显示序号 by index zrem 删除名称为key的zset中的元素member zrem myset itim zincrby 修改元素的排序,如果元素不存在则添加该元素,且排序的score值为增加值 zincrby myzset score itim zrank 返回元素在集合中的排序位置,就是索引值 zrank myzset itim //itim在集合中的位置 zrevrank 返回从大到小的排序索引值,就是逆序位置 zrevrangk myzset itim//逆序的位置 zrevrange 返回集合中从大到小排序(降序)的,索引start到end的所有元素 zrevrange myzset 0 -1 //逆序后的元素 zrangebyscore 根据排序索引的scores来返回元素 zrangebyscore myzset 1 3 withscores// zcount 返回集合中给定区间的数量 zcount myzset 2 4 //集合中2-4索引元素的个数 zcard 返回集合中所有元素的个数 zcard myzset //返回所有元素的个数 zremrangebyrank 删除集合中排序在给定区间的所有元素(按索引删除) zremrangebyrank myzset 2 3 // zremrangebyscore 删除集合中在给定排序区间的元素 (按顺序删除) zremrangebyscore myzset 2 5 // 1.6. Pub/Sub Pub/Sub 从字面上理解就是发布(Publish)与订阅(Subscribe),在Redis中,你可以设定对某一个key值进行消息发布及消息订阅,当一个key值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作实时消息系统,比如普通的即时聊天,群聊等功能。 案例: Qlocenter 下发策略 2. redis数据存储 redis的存储分为内存存储、磁盘存储和log文件三部分,配置文件中有三个参数对其进行配置。 l save seconds updates save配置,指出在多长时间内,有多少次更新操作,就将数据同步到数据文件。这个可以多个条件配合,比如默认配置文件中的设置,就设置了三个条件。 l appendonly yes/no appendonly配置,指出是否在每次更新操作后进行日志记录,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为redis本身同步数据文件是按上面的save条件来同步的,所以有的数据会在一段时间内只存在于内存中。 l appendfsync no/always/everysec appendfsync配置,no表示等操作系统进行数据缓存同步到磁盘,always表示每次更新操作后手动调用fsync()将数据写到磁盘,everysec表示每秒同步一次。 redis使用了两种文件格式:全量数据和增量请求。 全量数据格式是把内存中的数据写入磁盘,便于下次读取文件进行加载; 增量请求文件则是把内存中的数据序列化为操作请求,用于读取文件进行replay得到数据,序列化的操作包括SET、RPUSH、SADD、ZADD。 redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化。redis支持两种持久化方式,一种是 Snapshotting(快照)也是默认方式,另一种是Append-only file(缩写aof)的方式。下面分别介绍Snapshotting(RDB方式) 快照是默认的持久化方式。这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。可以通过配置设置自动做快照持久 化的方式。我们可以配置redis在n秒内如果超过m个key被修改就自动做快照,下面是默认的快照保存配置save 900 1 #900秒内如果超过1个key被修改,则发起快照保存save 300 10 #300秒内容如超过10个key被修改,则发起快照保存save 60 10000下面介绍详细的快照保存过程1.redis调用fork,现在有了子进程和父进程。2. 父进程继续处理client请求,子进程负责将内存内容写入到临时文件。由于os的写时复制机制(copy on write)父子进程会共享相同的物理页面,当父进程处理写请求时os会为父进程要修改的页面创建副本,而不是写共享的页面。所以子进程的地址空间内的数 据是fork时刻整个数据库的一个快照。3.当子进程将快照写入临时文件完毕后,用临时文件替换原来的快照文件,然后子进程退出。client 也可以使用save或者bgsave命令通知redis做一次快照持久化。save操作是在主线程中保存快照的,由于redis是用一个主线程来处理所有 client的请求,这种方式会阻塞所有client请求。所以不推荐使用。另一点需要注意的是,每次快照持久化都是将内存数据完整写入到磁盘一次,并不 是增量的只同步脏数据。如果数据量大的话,而且写操作比较多,必然会引起大量的磁盘io操作,可能会严重影响性能。另外由于快照方式是在一定间隔时间做一次的,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。如果应用要求不能丢失任何修改的话,可以采用aof持久化方式。下面介绍Append-only file(AOF方式) aof 比快照方式有更好的持久化性,是由于在使用aof持久化方式时,redis会将每一个收到的写命令都通过write函数追加到文件中(默认是 appendonly.aof)。当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。当然由于os会在内核中缓存 write做的修改,所以可能不是立即写到磁盘上。这样aof方式的持久化也还是有可能会丢失部分修改。不过我们可以通过配置文件告诉redis我们想要 通过fsync函数强制os写入到磁盘的时机。有三种方式如下(默认是:每秒fsync一次)appendonly yes //启用aof持久化方式# appendfsync always //每次收到写命令就立即强制写入磁盘,最慢的,但是保证完全的持久化,不推荐使用appendfsync everysec //每秒钟强制写入磁盘一次,在性能和持久化方面做了很好的折中,推荐# appendfsync no //完全依赖os,性能最好,持久化没保证aof 的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100就够了。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。收到此命令redis将使用与快照类似的方式将内存中的数据 以命令的方式保存到临时文件中,最后替换原来的文件。具体过程如下1. redis调用fork ,现在有父子两个进程2. 子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令3. 父进程继续处理client请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题。4. 当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。5. 现在父进程可以使用临时文件替换老的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。 需要注意到是重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。 3. 主从复制 redis主从复制配置和使用都非常简单。 通过主从复制可以允许多个slave server拥有和master server相同的数据库副本。下面是关于redis主从复制的一些特点 l master可以有多个slave l 除了多个slave连到相同的master外,slave也可以连接其他slave形成图状结构 l 主从复制不会阻塞master。也就是说当一个或多个slave与master进行初次同步数据时,master可以继续处理client发来的请求。相反slave在初次同步数据时则会阻塞不能处理client的请求。 l 主从复制可以用来提高系统的可伸缩性,我们可以用多个slave 专门用于client的读请求,比如sort操作可以使用slave来处理。也可以用来做简单的数据冗余 l 可以在master禁用数据持久化,只需要注释掉master 配置文件中的所有save配置,然后只在slave上配置数据持久化。 主从复制的过程 当设置好slave服务器后,slave会建立和master的连接,然后发送sync命令。无论是第一次同步建立的连接还是连接断开后的重新连 接,master都会启动一个后台进程,将数据库快照保存到文件中,同时master主进程会开始收集新的写命令并缓存起来。后台进程完成写文件后,master就发送文件给slave,slave将文件保存到磁盘上,然后加载到内存恢复数据库快照到slave上。接着master就会把缓存的命 令转发给slave。而且后续master收到的写命令都会通过开始建立的连接发送给slave。从master到slave的同步数据的命令和从 client发送的命令使用相同的协议格式。当master和slave的连接断开时slave可以自动重新建立连接。如果master同时收到多个 slave发来的同步连接命令,只会使用启动一个进程来写数据库镜像,然后发送给所有slave。 4. Redis应用场景 毫无疑问,Redis开创了一种新的数据存储思路,使用Redis,我们不用在面对功能单调的数据库时,把精力放在如何把大象放进冰箱这样的问题上,而是利用Redis灵活多变的数据结构和数据操作,为不同的大象构建不同的冰箱。 Redis比较适合的一些应用场景,NoSQLFan简单列举在这里,供大家一览: 1.7.1.取最新N个数据的操作 记录前N个最新登陆的用户Id列表,超出的范围可以从数据库中获得。 //把当前登录人添加到链表里 ret = r.lpush("login:last_login_times", uid) //保持链表只有N位 ret = redis.ltrim("login:last_login_times", 0, N-1) //获得前N个最新登陆的用户Id列表 last_login_list = r.lrange("login:last_login_times", 0, N-1) 比如sina微博: 在Redis中我们的最新微博ID使用了常驻缓存,这是一直更新的。但是我们做了限制不能超过5000个ID,因此我们的获取ID函数会一直询问Redis。只有在start/count参数超出了这个范围的时候,才需要去访问数据库。 我们的系统不会像传统方式那样“刷新”缓存,Redis实例中的信息永远是一致的。SQL数据库(或是硬盘上的其他类型数据库)只是在用户需要获取“很远”的数据时才会被触发,而主页或第一个评论页是不会麻烦到硬盘上的数据库了。 1.7.2.排行榜应用,取TOP N操作 这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。 //将登录次数和用户统一存储在一个sorted set里 zadd login:login_times 5 1 zadd login:login_times 1 2 zadd login:login_times 2 3 ZADD key score member //当用户登录时,对该用户的登录次数自增1 ret = r.zincrby("login:login_times", 1, uid) //那么如何获得登录次数最多的用户呢,逆序排列取得排名前N的用户 ret = r.zrevrange("login:login_times", 0, N-1) ZREVRANGE key start stop [WITHSCORES] 另一个很普遍的需求是各种数据库的数据并非存储在内存中,因此在按得分排序以及实时更新这些几乎每秒钟都需要更新的功能上数据库的性能不够理想。 典型的比如那些在线游戏的排行榜,比如一个Facebook的游戏,根据得分你通常想要: - 列出前100名高分选手 - 列出某用户当前的全球排名 这些操作对于Redis来说小菜一碟,即使你有几百万个用户,每分钟都会有几百万个新的得分。 模式是这样的,每次获得新得分时,我们用这样的代码: ZADD leaderboard <score> <username> 你可能用userID来取代username,这取决于你是怎么设计的。 得到前100名高分用户很简单:ZREVRANGE leaderboard 0 99。 用户的全球排名也相似,只需要:ZRANK leaderboard <username>。 ZRANK key member Determine the index of a member in a sorted set 1.7.3.需要精准设定过期时间的应用 比如你可以把上面说到的sorted set的score值设置成过期时间的时间戳,那么就可以简单地通过过期时间排序,定时清除过期数据了,不仅是清除Redis中的过期数据,你完全可以把Redis里这个过期时间当成是对数据库中数据的索引,用Redis来找出哪些数据需要过期删除,然后再精准地从数据库中删除相应的记录。 1.7.4.获取某段时间所有数据去重值 这个使用Redis的set数据结构最合适了,只需要不断地将数据往set中扔就行了,set意为集合,所以会自动排重。 1.7.5.Pub/Sub构建实时消息系统 Redis的Pub/Sub系统可以构建实时的消息系统 比如很多用Pub/Sub构建的实时聊天系统的例子。 1.7.6.消息队列系统 使用list可以构建队列系统,使用sorted set甚至可以构建有优先级的队列系统。 比如:将Redis用作日志收集器 实际上还是一个队列,多个端点将日志信息写入Redis,然后一个worker统一将所有日志写到磁盘。 1.7.7. 缓存 性能优于Memcached,数据结构更多样化。 1.7.8.范围查找 比如:有一个IP范围对应地址的列表,现在需要给出一个IP的情况下,迅速的查找到这个IP在哪个范围,也就是要判断此IP的所有地。 例如:查询IP是否存在的问题; ADSM,查询IP是否在其他分组中存在。写json文件 sadd向名称为key的set中添加元素,返回影响元素的个数,0为失败,1为成功 例如:有下面两个范围,10-20和30-40 · A_start 10, A_end 20 · B_start 30, B_end 40 我们将这两个范围的起始位置存在Redis的Sorted Sets数据结构中,基本范围起始值作为score,范围名加start和end为其value值: redis 127.0.0.1:6379> zadd ranges 10 A_start (integer) 1 redis 127.0.0.1:6379> zadd ranges 20 A_end (integer) 1 redis 127.0.0.1:6379> zadd ranges 30 B_start (integer) 1 redis 127.0.0.1:6379> zadd ranges 40 B_end (integer) 1 这样数据在插入Sorted Sets后,相当于是将这些起始位置按顺序排列好了。 现在我需要查找15这个值在哪一个范围中,只需要进行如下的zrangbyscore查找: redis 127.0.0.1:6379> zrangebyscore ranges (15 +inf LIMIT 0 1 1) "A_end" 这个命令的意思是在Sorted Sets中查找大于15的第一个值。(+inf在Redis中表示正无穷大,15前面的括号表示>15而非>=15) 查找的结果是A_end,由于所有值是按顺序排列的,所以可以判定15是在A_start到A_end区间上,也就是说15是在A这个范围里。至此大功告成。 当然,如果你查找到的是一个start,比如咱们用25,执行下面的命令 redis 127.0.0.1:6379> zrangebyscore ranges (25 +inf LIMIT 0 1 1) "B_start" 返回结果表明其下一个节点是一个start节点,也就是说25这个值不处在任何start和end之间,不属于任何范围。 11.存储社交关系 Sina实例 l hash sets: 关注列表, 粉丝列表, 双向关注列表(key-value(field), 排序) l string(counter): 微博数, 粉丝数, ...(避免了select count(*) from ...) l sort sets(自动排序): TopN, 热门微博等, 自动排序 l lists(queue): push/sub新提醒,... 12.交集,并集,差集:(Set) //book表存储book名称 set book:1:name ”The Ruby Programming Language” set book:2:name ”Ruby on rail” set book:3:name ”Programming Erlang” //tag表使用集合来存储数据,因为集合擅长求交集、并集 sadd tag:ruby 1 sadd tag:ruby 2 sadd tag:web 2 sadd tag:erlang 3 //即属于ruby又属于web的书? inter_list = redis.sinter("tag.web", "tag:ruby") //即属于ruby,但不属于web的书? inter_list = redis.sdiff("tag.ruby", "tag:web") //属于ruby和属于web的书的合集? inter_list = redis.sunion("tag.ruby", "tag:web") 5. Redis Tools 1.8. 实用命令 l Keys * : 返回所有的key,* 可使用正则表达式查询 l Type key :返回key的类型(string ,zset ,list) l Select 1 : 选择第一个数据库;默认0-15个数据库;默认是第0个数据库库中 l Dbsize : 当前数据库中的key的个数 l Monitor : 监控收到的请求 1.9. phpRedisAdmin 类似phpmyadmin是一个PHP的MySQL WEB管理工具,是一个PHP的Redis WEB管理工具。 图例: 1.10. RedBridge: 为Redis提供HTTP API及连接池功能 RedBridge 是一款基于Redis的 HTTP API。使用LUA直接跟Redis交互,对Redis的连接实现连接池。(类似数据库的存储过程) 高效的实现复杂的业务逻辑。 特性介绍 RedBridge 具有以下特征: 1. 使用C+epoll 编写的Web Server,支持HTTP GET操作 2. 连接池,连接句柄复用,提高跟Redis连接效率 3. 部分类库使用Redis的代码,更加的稳定 4. 使用LUA直接调用Redis命令,实现一次性数据交互实现 复杂的业务逻辑。不需要多次数据交互 5. 服务模型采用单进程,双线程模式 6. 配置文件采用Lua 语法,容易读取和书写 7. RedBridge发布前,还没有类似的开源项目 转自 heoo 的 Redis特性和应用场景
这里就要抛出一个问题来:机器学习:你到底需要多少训练数据,尤其是SVM?
我这里训练集加起来才889篇,可以明确的是这些训练集是肯定不够的,理论上来说训练集应该越多越好,但是其分类想过应该是一个越来越平缓的曲线,这个貌似应该研究起来也是一个不少篇幅的内容。
三,开始特征提取吧!
接下来就开始机器学习第一步也是最重要的一步,也是最麻烦的一步吧,事实上自己要做的工作就是这一步。毕竟后面的训练只要用前辈们已经不断完善的分类算法和工具了,我选择的是SVM算法和libsvm工具包。
再声明一下,我是利用卡方检验对需要进行二分类的文本进行特征选择,已达到降维的目的,最终要得到的是能够代表每个类别的特征集合,和一个总的特征词典。当然在这个工程中,我们也会看到每个词对于一个文本重要性的规律。
1.分词工具
第一步:选择分词工具对训练集进行分词
我选择的分词工具是JIEba分词,而我使用的语言是C# ,关于.net core版本的JIEba分词可以在这篇博文里面找到:
http://www.cnblogs.com/dacc123/p/8431369.html
利用JIEba分词工具,我们才能进行后面的计算词频,词的文档频率,词的四表格值,词的卡方值χ2 。这里还是把自己的代码贴出来吧,如果有需要的话我会整理在GitHub上。
2.计算词频
第二步:计算词频
相信大家都会写,我把自己代码贴出来以供参考,代码中多用了Dictionary 数据结构,对了分词之前,咱们应该有一份比较全的停用词表。插一句:对于文本分类来说停用词越多越好,对于搜索引擎来说就不是这样了。
1800多个停用词
! " # $ % & ' ( ) * + , - -- . .. ... ...... ................... ./ .一 .数 .日 / // 0 1 2 3 4 5 6 7 8 9 : :// :: ; < = > >> ? @ A Lex [ \ ] ^ _ ` exp sub sup | } ~ ~~~~ · × ××× Δ Ψ γ μ φ φ. В — —— ——— ‘ ’ ’‘ “ ” ”, … …… …………………………………………………③ ′∈ ′| ℃ Ⅲ ↑ → ∈[ ∪φ∈ ≈ ① ② ②c ③ ③] ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ── ■ ▲ 、 。 〈 〉 《 》 》), 」 『 』 【 】 〔 〕 〕〔 ㈧ 一 一. 一一 一下 一个 一些 一何 一切 一则 一则通过 一天 一定 一方面 一旦 一时 一来 一样 一次 一片 一番 一直 一致 一般 一起 一转眼 一边 一面 七 万一 三 三天两头 三番两次 三番五次 上 上下 上升 上去 上来 上述 上面 下 下列 下去 下来 下面 不 不一 不下 不久 不了 不亦乐乎 不仅 不仅...而且 不仅仅 不仅仅是 不会 不但 不但...而且 不光 不免 不再 不力 不单 不变 不只 不可 不可开交 不可抗拒 不同 不外 不外乎 不够 不大 不如 不妨 不定 不对 不少 不尽 不尽然 不巧 不已 不常 不得 不得不 不得了 不得已 不必 不怎么 不怕 不惟 不成 不拘 不择手段 不敢 不料 不断 不日 不时 不是 不曾 不止 不止一次 不比 不消 不满 不然 不然的话 不特 不独 不由得 不知不觉 不管 不管怎样 不经意 不胜 不能 不能不 不至于 不若 不要 不论 不起 不足 不过 不迭 不问 不限 与 与其 与其说 与否 与此同时 专门 且 且不说 且说 两者 严格 严重 个 个人 个别 中小 中间 丰富 串行 临 临到 为 为主 为了 为什么 为什麽 为何 为止 为此 为着 主张 主要 举凡 举行 乃 乃至 乃至于 么 之 之一 之前 之后 之後 之所以 之类 乌乎 乎 乒 乘 乘势 乘机 乘胜 乘虚 乘隙 九 也 也好 也就是说 也是 也罢 了 了解 争取 二 二来 二话不说 二话没说 于 于是 于是乎 云云 云尔 互 互相 五 些 交口 亦 产生 亲口 亲手 亲眼 亲自 亲身 人 人人 人们 人家 人民 什么 什么样 什麽 仅 仅仅 今 今后 今天 今年 今後 介于 仍 仍旧 仍然 从 从不 从严 从中 从事 从今以后 从优 从古到今 从古至今 从头 从宽 从小 从新 从无到有 从早到晚 从未 从来 从此 从此以后 从而 从轻 从速 从重 他 他人 他们 他是 他的 代替 以 以上 以下 以为 以便 以免 以前 以及 以后 以外 以後 以故 以期 以来 以至 以至于 以致 们 任 任何 任凭 任务 企图 伙同 会 伟大 传 传说 传闻 似乎 似的 但 但凡 但愿 但是 何 何乐而不为 何以 何况 何处 何妨 何尝 何必 何时 何止 何苦 何须 余外 作为 你 你们 你是 你的 使 使得 使用 例如 依 依据 依照 依靠 便 便于 促进 保持 保管 保险 俺 俺们 倍加 倍感 倒不如 倒不如说 倒是 倘 倘使 倘或 倘然 倘若 借 借以 借此 假使 假如 假若 偏偏 做到 偶尔 偶而 傥然 像 儿 允许 元/吨 充其极 充其量 充分 先不先 先后 先後 先生 光 光是 全体 全力 全年 全然 全身心 全部 全都 全面 八 八成 公然 六 兮 共 共同 共总 关于 其 其一 其中 其二 其他 其余 其后 其它 其实 其次 具体 具体地说 具体来说 具体说来 具有 兼之 内 再 再其次 再则 再有 再次 再者 再者说 再说 冒 冲 决不 决定 决非 况且 准备 凑巧 凝神 几 几乎 几度 几时 几番 几经 凡 凡是 凭 凭借 出 出于 出去 出来 出现 分别 分头 分期 分期分批 切 切不可 切切 切勿 切莫 则 则甚 刚 刚好 刚巧 刚才 初 别 别人 别处 别是 别的 别管 别说 到 到了儿 到处 到头 到头来 到底 到目前为止 前后 前此 前者 前进 前面 加上 加之 加以 加入 加强 动不动 动辄 勃然 匆匆 十分 千 千万 千万千万 半 单 单单 单纯 即 即令 即使 即便 即刻 即如 即将 即或 即是说 即若 却 却不 历 原来 去 又 又及 及 及其 及时 及至 双方 反之 反之亦然 反之则 反倒 反倒是 反应 反手 反映 反而 反过来 反过来说 取得 取道 受到 变成 古来 另 另一个 另一方面 另外 另悉 另方面 另行 只 只当 只怕 只是 只有 只消 只要 只限 叫 叫做 召开 叮咚 叮当 可 可以 可好 可是 可能 可见 各 各个 各人 各位 各地 各式 各种 各级 各自 合理 同 同一 同时 同样 后 后来 后者 后面 向 向使 向着 吓 吗 否则 吧 吧哒 吱 呀 呃 呆呆地 呐 呕 呗 呜 呜呼 呢 周围 呵 呵呵 呸 呼哧 呼啦 咋 和 咚 咦 咧 咱 咱们 咳 哇 哈 哈哈 哉 哎 哎呀 哎哟 哗 哗啦 哟 哦 哩 哪 哪个 哪些 哪儿 哪天 哪年 哪怕 哪样 哪边 哪里 哼 哼唷 唉 唯有 啊 啊呀 啊哈 啊哟 啐 啥 啦 啪达 啷当 喀 喂 喏 喔唷 喽 嗡 嗡嗡 嗬 嗯 嗳 嘎 嘎嘎 嘎登 嘘 嘛 嘻 嘿 嘿嘿 四 因 因为 因了 因此 因着 因而 固 固然 在 在下 在于 地 均 坚决 坚持 基于 基本 基本上 处在 处处 处理 复杂 多 多么 多亏 多多 多多少少 多多益善 多少 多年前 多年来 多数 多次 够瞧的 大 大不了 大举 大事 大体 大体上 大凡 大力 大多 大多数 大大 大家 大张旗鼓 大批 大抵 大概 大略 大约 大致 大都 大量 大面儿上 失去 奇 奈 奋勇 她 她们 她是 她的 好 好在 好的 好象 如 如上 如上所述 如下 如今 如何 如其 如前所述 如同 如常 如是 如期 如果 如次 如此 如此等等 如若 始而 姑且 存在 存心 孰料 孰知 宁 宁可 宁愿 宁肯 它 它们 它们的 它是 它的 安全 完全 完成 定 实现 实际 宣布 容易 密切 对 对于 对应 对待 对方 对比 将 将才 将要 将近 小 少数 尔 尔后 尔尔 尔等 尚且 尤其 就 就地 就是 就是了 就是说 就此 就算 就要 尽 尽可能 尽如人意 尽心尽力 尽心竭力 尽快 尽早 尽然 尽管 尽管如此 尽量 局外 居然 届时 属于 屡 屡屡 屡次 屡次三番 岂 岂但 岂止 岂非 川流不息 左右 巨大 巩固 差一点 差不多 己 已 已矣 已经 巴 巴巴 带 帮助 常 常常 常言说 常言说得好 常言道 平素 年复一年 并 并不 并不是 并且 并排 并无 并没 并没有 并肩 并非 广大 广泛 应当 应用 应该 庶乎 庶几 开外 开始 开展 引起 弗 弹指之间 强烈 强调 归 归根到底 归根结底 归齐 当 当下 当中 当儿 当前 当即 当口儿 当地 当场 当头 当庭 当时 当然 当真 当着 形成 彻夜 彻底 彼 彼时 彼此 往 往往 待 待到 很 很多 很少 後来 後面 得 得了 得出 得到 得天独厚 得起 心里 必 必定 必将 必然 必要 必须 快 快要 忽地 忽然 怎 怎么 怎么办 怎么样 怎奈 怎样 怎麽 怕 急匆匆 怪 怪不得 总之 总是 总的来看 总的来说 总的说来 总结 总而言之 恍然 恐怕 恰似 恰好 恰如 恰巧 恰恰 恰恰相反 恰逢 您 您们 您是 惟其 惯常 意思 愤然 愿意 慢说 成为 成年 成年累月 成心 我 我们 我是 我的 或 或则 或多或少 或是 或曰 或者 或许 战斗 截然 截至 所 所以 所在 所幸 所有 所谓 才 才能 扑通 打 打从 打开天窗说亮话 扩大 把 抑或 抽冷子 拦腰 拿 按 按时 按期 按照 按理 按说 挨个 挨家挨户 挨次 挨着 挨门挨户 挨门逐户 换句话说 换言之 据 据实 据悉 据我所知 据此 据称 据说 掌握 接下来 接着 接著 接连不断 放量 故 故意 故此 故而 敞开儿 敢 敢于 敢情 数/ 整个 断然 方 方便 方才 方能 方面 旁人 无 无宁 无法 无论 既 既...又 既往 既是 既然 日复一日 日渐 日益 日臻 日见 时候 昂然 明显 明确 是 是不是 是以 是否 是的 显然 显著 普通 普遍 暗中 暗地里 暗自 更 更为 更加 更进一步 曾 曾经 替 替代 最 最后 最大 最好 最後 最近 最高 有 有些 有关 有利 有力 有及 有所 有效 有时 有点 有的 有的是 有着 有著 望 朝 朝着 末##末 本 本人 本地 本着 本身 权时 来 来不及 来得及 来看 来着 来自 来讲 来说 极 极为 极了 极其 极力 极大 极度 极端 构成 果然 果真 某 某个 某些 某某 根据 根本 格外 梆 概 次第 欢迎 欤 正值 正在 正如 正巧 正常 正是 此 此中 此后 此地 此处 此外 此时 此次 此间 殆 毋宁 每 每个 每天 每年 每当 每时每刻 每每 每逢 比 比及 比如 比如说 比方 比照 比起 比较 毕竟 毫不 毫无 毫无例外 毫无保留地 汝 沙沙 没 没奈何 没有 沿 沿着 注意 活 深入 清楚 满 满足 漫说 焉 然 然则 然后 然後 然而 照 照着 牢牢 特别是 特殊 特点 犹且 犹自 独 独自 猛然 猛然间 率尔 率然 现代 现在 理应 理当 理该 瑟瑟 甚且 甚么 甚或 甚而 甚至 甚至于 用 用来 甫 甭 由 由于 由是 由此 由此可见 略 略为 略加 略微 白 白白 的 的确 的话 皆可 目前 直到 直接 相似 相信 相反 相同 相对 相对而言 相应 相当 相等 省得 看 看上去 看出 看到 看来 看样子 看看 看见 看起来 真是 真正 眨眼 着 着呢 矣 矣乎 矣哉 知道 砰 确定 碰巧 社会主义 离 种 积极 移动 究竟 穷年累月 突出 突然 窃 立 立刻 立即 立地 立时 立马 竟 竟然 竟而 第 第二 等 等到 等等 策略地 简直 简而言之 简言之 管 类如 粗 精光 紧接着 累年 累次 纯 纯粹 纵 纵令 纵使 纵然 练习 组成 经 经常 经过 结合 结果 给 绝 绝不 绝对 绝非 绝顶 继之 继后 继续 继而 维持 综上所述 缕缕 罢了 老 老大 老是 老老实实 考虑 者 而 而且 而况 而又 而后 而外 而已 而是 而言 而论 联系 联袂 背地里 背靠背 能 能否 能够 腾 自 自个儿 自从 自各儿 自后 自家 自己 自打 自身 臭 至 至于 至今 至若 致 般的 良好 若 若夫 若是 若果 若非 范围 莫 莫不 莫不然 莫如 莫若 莫非 获得 藉以 虽 虽则 虽然 虽说 蛮 行为 行动 表明 表示 被 要 要不 要不是 要不然 要么 要是 要求 见 规定 觉得 譬喻 譬如 认为 认真 认识 让 许多 论 论说 设使 设或 设若 诚如 诚然 话说 该 该当 说明 说来 说说 请勿 诸 诸位 诸如 谁 谁人 谁料 谁知 谨 豁然 贼死 赖以 赶 赶快 赶早不赶晚 起 起先 起初 起头 起来 起见 起首 趁 趁便 趁势 趁早 趁机 趁热 趁着 越是 距 跟 路经 转动 转变 转贴 轰然 较 较为 较之 较比 边 达到 达旦 迄 迅速 过 过于 过去 过来 运用 近 近几年来 近年来 近来 还 还是 还有 还要 这 这一来 这个 这么 这么些 这么样 这么点儿 这些 这会儿 这儿 这就是说 这时 这样 这次 这点 这种 这般 这边 这里 这麽 进入 进去 进来 进步 进而 进行 连 连同 连声 连日 连日来 连袂 连连 迟早 迫于 适应 适当 适用 逐步 逐渐 通常 通过 造成 逢 遇到 遭到 遵循 遵照 避免 那 那个 那么 那么些 那么样 那些 那会儿 那儿 那时 那末 那样 那般 那边 那里 那麽 部分 都 鄙人 采取 里面 重大 重新 重要 鉴于 针对 长期以来 长此下去 长线 长话短说 问题 间或 防止 阿 附近 陈年 限制 陡然 除 除了 除却 除去 除外 除开 除此 除此之外 除此以外 除此而外 除非 随 随后 随时 随着 随著 隔夜 隔日 难得 难怪 难说 难道 难道说 集中 零 需要 非但 非常 非徒 非得 非特 非独 靠 顶多 顷 顷刻 顷刻之间 顷刻间 顺 顺着 顿时 颇 风雨无阻 饱 首先 马上 高低 高兴 默然 默默地 齐 ︿ ! # $ % & ' ( ) )÷(1- )、 * + +ξ ++ , ,也 - -β -- -[*]- . / 0 0:2 1 1. 12% 2 2.3% 3 4 5 5:0 6 7 8 9 : ; < <± <Δ <λ <φ << = =″ =☆ =( =- =[ ={ > >λ ? @ A LI R.L. ZXFITL [ [①①] [①②] [①③] [①④] [①⑤] [①⑥] [①⑦] [①⑧] [①⑨] [①A] [①B] [①C] [①D] [①E] [①] [①a] [①c] [①d] [①e] [①f] [①g] [①h] [①i] [①o] [② [②①] [②②] [②③] [②④ [②⑤] [②⑥] [②⑦] [②⑧] [②⑩] [②B] [②G] [②] [②a] [②b] [②c] [②d] [②e] [②f] [②g] [②h] [②i] [②j] [③①] [③⑩] [③F] [③] [③a] [③b] [③c] [③d] [③e] [③g] [③h] [④] [④a] [④b] [④c] [④d] [④e] [⑤] [⑤]] [⑤a] [⑤b] [⑤d] [⑤e] [⑤f] [⑥] [⑦] [⑧] [⑨] [⑩] [*] [- [] ] ]∧′=[ ][ _ a] b] c] e] f] ng昉 { {- | } }> ~ ~± ~+ ¥ a b c d e f g h i j k l m n o p q r s t u v w x y z
计算词频代码:
public void ReadText() { rd = File.OpenText("./stopwords.txt"); string s = ""; while ((s = rd.ReadLine()) != null) { if (s == null) continue; if (!stopwords.ContainsKey(s)) stopwords.Add(s, 1); } Console.WriteLine("*******读取停用词完毕"); rd.Close(); } //计算词频,url1地址是放入训练集的文件夹,url2地址是存放计算词频结果的文件 public void WriteText(string url1, string url2) { DirectoryInfo folder = new DirectoryInfo(url1); foreach (FileInfo file in folder.GetFiles("*.txt")) { rd = File.OpenText(file.FullName); string s = ""; System.Console.WriteLine("**************开始读取数据..."); while ((s = rd.ReadLine()) != null) { var segment = segmenter.Cut(s, false, false); foreach (var x in segment) { if (stopwords.ContainsKey(x)) continue; if (!keys.ContainsKey(x)) keys.Add(x, 1); else keys[x]++; } } } System.Console.WriteLine("**************读取完毕,计算词频并插入..."); wt = new StreamWriter(url2, true); //wt = File.AppendText(url2); var dicSort = from objDic in keys orderby objDic.Value descending select objDic; foreach (KeyValuePair<string, int> kvp in dicSort) { wt.WriteLine(kvp.Key + " " + kvp.Value.ToString()); } System.Console.WriteLine("**************插入完毕..."); wt.Flush(); rd.Close(); wt.Close(); }
经过一顿操作:
历史类: 计算机博客类:

选择词频排名前30的词,来看看,排名靠前的词乍一看好像貌似是那么回事,这也是有时候你只用词频这一个属性来分类文本,发现效果也不是那么差。仔细看一下:
历史类:“标”,“题”,“年”....等等,计算机博客类:“中”,“时”,等等这些词总是那么的刺眼,我们需要把这些冒充上来的词给去掉。
忘了说下,计算机博客类的词的个数是:21503个;历史类的词的个数是:68912个,由于自己找的训练集不是那么好所以两种类的词差别有点大。。
词的个数这么多,如果用词频排序的词表来当做特征集,是不是效果不能到达最好,而且维度太大了。
3.文档频率DF
前面提到过一个名词:文档频率DF ,也就是一个词在多少个文档中出现过,对于那些文档频率十分低的词,我们叫做生僻词,这些词有可能词频很高,比如一个人写博客:“我是大牛,我是大牛,我是大牛.....”循环了几千次,那么“大牛”这个词就很靠前了,然而他只出现过在一篇博客里,所以我们可以把这些生僻词去掉。我也统计了两个类别中的生僻词,发现一大半都是DF为1,2的词。这里也就不贴代码和统计结果了,因为我们不需要取出文档频率低的词,为什么呢?因为有卡方检验啊,这个十分强大的机器,是肯定会帮我们过滤掉DF极低的词,所以咱们直奔卡方检验,看看是不是可以验证自己的猜想。(而统计DF的值恰恰帮助了我们计算卡方检验)
4.卡方检验 一
根据上一篇博客中的公式,对于每个词,我们需要计算四个值,A,B,C,D。
再解释一下,以“大牛”和计算机博客类为例子:A 包含“大牛”属于计算机博客的文档个数,B 包含“大牛”不属于计算机博客的文档个数,C 不包含“大牛”属于计算机博客类的文档个数,D 不包含“大牛”不属于计算机的文档个数。
看起来很繁琐,其实只要有了上一步统计的DF表,那就很容易了。以计算机博客类为例子:
BlogDF 表示计算机博客类的词的文档频率表,HistoryDF表示历史类的词的文档频率表
那么A的值自然就是BlogDF的值 B的值: forearch BlogDF if(HistoryDF[x]!=0) B[x] = HistoryDF[x]; else B[x] = 0; C 和D 的值自然就是: foreach C,D C[x] = 计算机总文档数-A[x] D[x] = 计算机总文档数-B[x]
代码如下:比较简陋没有收拾
public static Dictionary<string, int> keysA = new Dictionary<string, int>(); public static Dictionary<string, int> keysB = new Dictionary<string, int>(); public static Dictionary<string, int> keys2 = new Dictionary<string, int>(); public static Dictionary<string, int> keysC = new Dictionary<string, int>(); public static Dictionary<string, int> keysD = new Dictionary<string, int>(); public static Dictionary<string, double> result = new Dictionary<string, double>(); public static Dictionary<string, int> stopwords = new Dictionary<string, int>(); public static System.IO.StreamReader rd; public static System.IO.StreamWriter wt; public JiebaSegmenter segmenter = new JiebaSegmenter(); //属于类别一训练集的个数 public static int category1=0; //属于类别而训练集的个数 public static int category2=0; //先读取记录 public void ReadText(string url,string url2) { rd = File.OpenText("./stopwords.txt"); string s = ""; while ((s = rd.ReadLine()) != null) { if (s == null) continue; if (!stopwords.ContainsKey(s)) stopwords.Add(s, 1); } Console.WriteLine("*******读取停用词完毕"); rd.Close(); rd = File.OpenText(url); s = ""; while ((s = rd.ReadLine()) != null) { string s1 = ""; string s2 = ""; int tag = 0; int l = s.Length; for (int i = 0; i < l; i++) { if (s[i] == ' ') { tag = 1; continue; } if (tag == 0) { s1 += s[i]; } else s2 += s[i]; } keysA.Add(s1, Int32.Parse(s2)); } rd.Close(); rd = File.OpenText(url2); s = ""; while ((s = rd.ReadLine()) != null) { string s1 = ""; string s2 = ""; int tag = 0; int l = s.Length; for (int i = 0; i < l; i++) { if (s[i] == ' ') { tag = 1; continue; } if (tag == 0) { s1 += s[i]; } else s2 += s[i]; } keys2.Add(s1, Int32.Parse(s2)); } rd.Close(); Console.WriteLine("*******加载旧记录完毕"); foreach(var x in keysA) { if(keys2.ContainsKey(x.Key)) keysB.Add(x.Key,keys2[x.Key]); else keysB.Add(x.Key,0); } } //写入特征 public void WriteText(string url1, string url2,string url3,string url4) { DirectoryInfo folder = new DirectoryInfo(url1); foreach (FileInfo file in folder.GetFiles("*.txt")) { category1++; } DirectoryInfo folder2 = new DirectoryInfo(url2); foreach (FileInfo file in folder2.GetFiles("*.txt")) { category2++; } foreach(var x in keysA) { keysC.Add(x.Key,category1-keysA[x.Key]); keysD.Add(x.Key,category2-keysB[x.Key]); } ComputeChi(); if(!File.Exists(url3)) { FileStream fs = File.Create(url3); fs.Close(); } if(!File.Exists(url4)) { FileStream fs = File.Create(url4); fs.Close(); } System.Console.WriteLine("**************读取完毕,计算A,B,C,D并插入..."); wt = new StreamWriter(url3, false); //wt = File.AppendText(url2); var dicSort = from objDic in keysA orderby objDic.Value descending select objDic; foreach (KeyValuePair<string, int> kvp in dicSort) { wt.WriteLine(kvp.Key + " " + kvp.Value.ToString()+" "+keysB[kvp.Key]+" "+keysC[kvp.Key]+" "+keysD[kvp.Key]); } System.Console.WriteLine("**************插入完毕..."); wt.Flush(); System.Console.WriteLine("**************读取完毕,计算卡方检验并插入..."); wt = new StreamWriter(url4, false); //wt = File.AppendText(url2); var dicSort2 = from objDic in result orderby objDic.Value descending select objDic; foreach (KeyValuePair<string, double> kvp in dicSort2) { wt.WriteLine(kvp.Key + " " + kvp.Value.ToString()); } System.Console.WriteLine("**************插入完毕..."); wt.Flush(); rd.Close(); wt.Close(); } public static void ComputeChi() { foreach(var x in keysA) { result.Add(x.Key,(double)((double)(category1+category2)*((double)keysA[x.Key]*keysD[x.Key]-(double)keysB[x.Key]*keysC[x.Key])*((double)keysA[x.Key]*keysD[x.Key]-(double)keysB[x.Key]*keysC[x.Key]))/ ((double)(keysA[x.Key]+keysB[x.Key])*(double)(keysC[x.Key]+keysD[x.Key])*(double)(keysA[x.Key]+keysC[x.Key])*(double)(keysB[x.Key]+keysD[x.Key]))); } }
于是兴高采烈的看看我们的强大的卡方检验得到的值,以计算机类:为了做对比,左边是词频排名,右边的是卡方检验排名

顿时傻眼了,为什么卡方检验 之后,词的排名变成这样了?“历史”,“中国”,“发展”,貌似是代表的历史了,难道自己代码写错了?仔细排查发现代码并没有写错,这些词也确实在计算机博客类别的文档里出现过。可是为什么这些词的排名如此之高?
查找这些的A,B,C,D值,以“标”为例
| 属于计算机类博客 | 不属于计算机类博客(属于历史类) | |
| 包含“标” | A:3 | B:443 |
| 不包含“标” | C:417 | D:26 |
根据公式,计算出来的值确实是780多,而标的词频只有:3!!。翻看历史类别的卡方值也是780多,这个“标”这么全能吗?(实际上两个类别的公共词的卡方值都是一样的,观察公式和ABCD的值就可以发现了)
我们再回顾一开始的卡方检验:我们假设某个词对于文档是不是某个类别是没有影响的,而不是某个词是不是能代表某个类别,那么“标”这个词虽然对计算机博客类几乎没有一点代表性,但是你看看之前的词频表,“标”在历史类中的词频排名非常靠前。到这里就应该清楚了“标”这个词,卡方检验认为“标”这个词对历史类别的影响很大,当一个文档出现“标”那么可以很大一部分确定他是历史类别,不是计算机博客类别,所以“标”对于文档不是计算机类别还是有很大影响力的,自然排名靠前。这里就有一个疑问了,为什么“标”这种词可以很好的代表历史?这个后面再提,这也是前面说过的卡方检验的低词频性缺陷。
5.卡方检验二
所以眼前这个酷似历史的卡方检验排名表,是否可以作为计算机博客类的特征集合呢?答案是肯定的,这些排名靠前的词对于判断一个文档是否属于计算机博客类别相当有说服力。 但是这样的排名表,我看着真的不是很喜欢。
于是我就做了点小动作。我们回顾一下卡方检验公式推导过程,

为了防止正负相互抵消,所以我们采用了平方和。然后在二分类问题中,这个正负其实是很有意义的,不应该就这么被和谐掉。我们看看“标”的四格表
| 属于计算机类博客 | 不属于计算机类博客(属于历史类) | |
| 包含“标” | A:3 | B:443 |
| 不包含“标” | C:417 | D:26 |
A和D的值很小,B和C的值很大,这就告诉了我们一个信息含有“标”很大可能是历史类,很小可能是计算机类,在计算过程中:
以计算A的观察值和理论值的偏差为例(约等于):
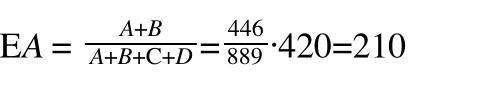
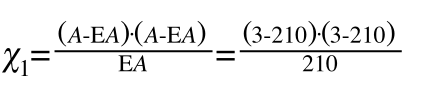
实际上这个偏差应该是负的,3-210应该是负数,我们使用平方和才变成为正的,所以我们不使用平方和而是使用(E-A)*|(E-A)|
偏差为负表示啥呢,表示这个词能够否定文本属于该类文档(语气重了一点),为正表示这个词能够肯定文本属于该类文档。
| 属于计算机类博客 | 不属于计算机类博客(属于历史类) | |
| 包含“标” | A:3 EA:210 | B:443 EB:235 |
| 不包含“标” | C:417 EC : 209 | D:26 ED:233 |
推广到四个值,发现实际上B的偏差值是正的 443-235是正数嘛,实际上对于B我们应该取负数,同理C应该去负数。对于B,C在计算结果之后加上一个负数
这样算出来的标就是-780多。为什么呢?因为B是包含“标”属于历史类,对于计算机类说是反例,同理C也是,所以要取反,正变负,负变正。
这样我们可以想象,如果用符号表示卡方值的大小,那么卡方检验得到的值应该是类似于正态分布:
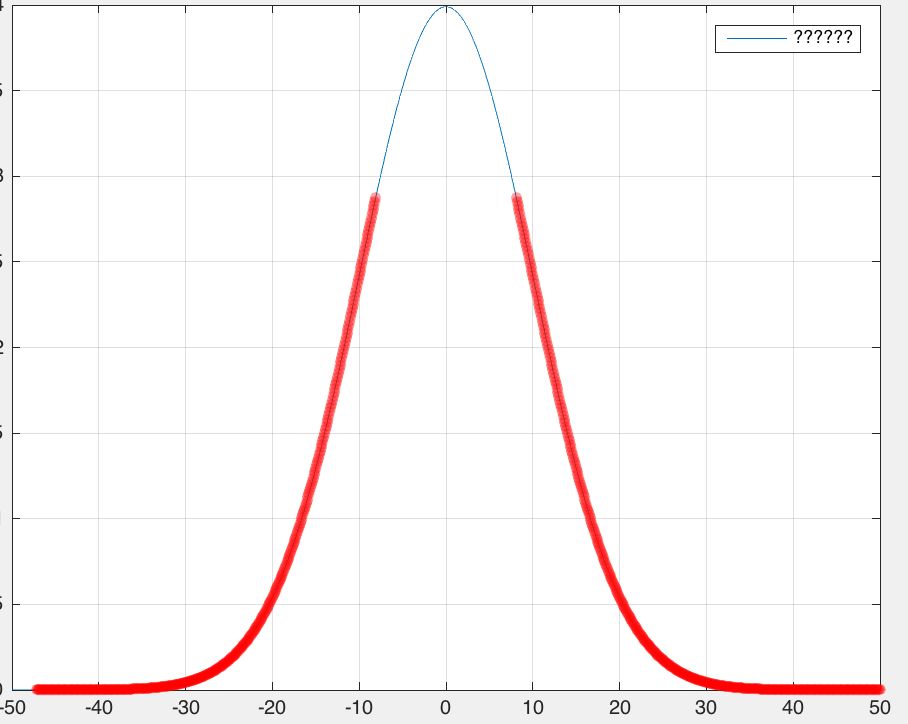
越靠近0的词越没有用,离0越远的词我们就越关注。那么这个具体的阀值是什么?还记得在卡方分布中说过的那个拒绝域吗?

3.84,对就是他了。你别看上面的图+3.84 和-3.84之间距离很短,但是这么短的距离中包含的词可多着呢,我的数据集中,大概三分之二的词都集中在-3.84到+3.84之间
于是在这个有符号的卡方检验指导下,我们变更公式!(对于四格表而言哦,也就是对于二分类而言哦)
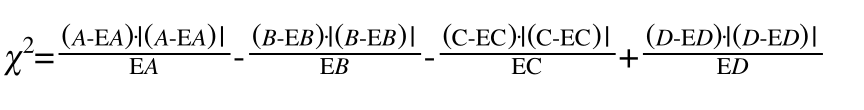
根据此公式,我们修改代码
//计算观察值A的偏差 符号为+ double EA = (double)(keysA[x.Key]+keysB[x.Key])*(double)(keysA[x.Key]+keysC[x.Key])/(double)(category1+category2); double a = (double)(keysA[x.Key]-EA)*System.Math.Abs((double)(keysA[x.Key]-EA))/EA; //计算观察值B的偏差 符号为- double EB = (double)(keysA[x.Key]+keysB[x.Key])*(double)(keysB[x.Key]+keysD[x.Key])/(double)(category1+category2); double b = -1*(double)(keysB[x.Key]-EB)*System.Math.Abs((double)(keysB[x.Key]-EB))/EB; //计算观察值C的偏差 符号为- double EC = (double)(keysC[x.Key]+keysD[x.Key])*(double)(keysA[x.Key]+keysC[x.Key])/(double)(category1+category2); double c = -1*(double)(keysC[x.Key]-EC)*System.Math.Abs((double)(keysC[x.Key]-EC))/EC; //计算观察值D的偏差 符号为+ double ED = (double)(keysC[x.Key]+keysD[x.Key])*(double)(keysB[x.Key]+keysD[x.Key])/(double)(category1+category2); double d = (double)(keysD[x.Key]-ED)*System.Math.Abs((double)(keysD[x.Key]-ED))/ED; result.Add(x.Key,a+b+c+d);
得到一个新的卡方检验表,以计算机类别,同样和词频作对比

乍一看,卡方检验的效果确实不错,仔细一看,嗯还是效果很好。哈哈哈。“中”这个词终于消失了。果然名不虚传 ,卡方检验确实是一个好东西
6.卡方检验的低词频性
再看看历史类的:

哎呀,这个“标”,“期” ....等等,真是差强人意。看看之前的文本范例,我们就明白了
【 文献号 】1-1 【原文出处】历史研究 【原刊地名】京 【原刊期号】199602 【原刊页号】5-25 【分 类 号】K1 【分 类 名】历史学 【 作 者 】林甘泉 【复印期号】199607 【 标 题 】二十世纪中国历史学回顾 二十世纪的中国历史学 【 正 文 】
每一篇都有一个“标题”,“文献号”等等,因为卡方检验本来就是忽视了词频的,这次个每篇文章只出现一次的词,反而重要性排第一去了。所以我们就需要结合词频信息,对卡方检验再次来改造。具体应该怎么权衡卡方检验和词频的值呢?一时间我也没有想到好的方法。可以将卡方检验排名靠前的词,词频小于等于文档数,或者小于等于文档数2倍的词都去掉。
7.卡方检验的神奇
再来看看卡方检验排名表的后半部分,左边计算机博客类,右边历史类!

可以看到,这些历史类排名最后的是不是很像是计算机博客类的词语?这些距离0很远的词,是论证文章不属于历史类的词语,也验证了上面的正态分布的猜想。两个类别正好倒过来了,十分对称,十分完美。绝知此事要躬行,躬行之后的感觉果然不同呀。
其实具体实验的时候才发现,词汇这个组成文章的基本成分,在众多文本之间有太多规律,太多巧妙的地方值得去挖掘了,这也是自然语言处理的魅力了吧。
再次回到之前的文档频率DF,我们说文档频率DF低的不用处理,卡方检验会帮我处理,看看结果,这里截两张图:
第一个参数是卡方检验的值,第二个值是文档频率DF

果然这些DF十分低的词都被分配到了0周围,坚决的和0站在一起,坚决的要被淘汰掉。
四,结语
那么经过前面的步骤,的确得到了可以代表两个类的特征集合,将两个特征集合距离0的距离大于3.84的特征(就是词啦)取一个并集,那么就是一个特征词典了。我们可以想象,历史类和计算机博客类的文本向量如果映射在这个词典上,他们分布是不同的,而SVM正是解决中在高维空间(也就是向量维度很高),把两类向量进行分类,如果线性不可分,SVM会使用核函数,映射到更高的维度使其变成线性可分。具体的原理这里也不细究。可见在SVM之前,将文本变成向量的过程是一个非常重要的步骤。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号