

爬取纵横中文网点击榜
1.打开所要爬取的网站:http://www.zongheng.com/rank/details.html?rt=5&d=1(纵横中文网点击榜)
2.打开网页源代码,找到需要的标签进行爬取:

3.导入数据库,编写代码:
import requests#引入requests库下载网页
from bs4 import BeautifulSoup#BeautifulSoup解析网页
import pandas as pd#引入pandas数据可视化
url="http://www.zongheng.com/rank/details.html?rt=5&d=1"#纵横中文网点击榜
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/69.0.3497.100 Safari/537.36'}#伪装爬虫
r=requests.get(url)#请求网站
r.encoding=r.apparent_encoding#对页面内容进行重新编码
x=r.text#获取源代码
soup=BeautifulSoup(x,'lxml')#构造Soup的对象
print(soup.prettify())#显示网站结构
c=[]#创建一个空列表
p=[]#创建一个空列表
for i in soup.find_all(class_="rank_d_b_name"):#for语句查找标签
c.append(i.get_text().strip())
for l in soup.find_all(class_="rank_d_b_ticket"):#for语句查找标签
p.append(l.get_text().strip())
data=[c,p]
print(data)
w=pd.DataFrame(data,index=["书名","点击数"])
print(w.T)#将所得数据进行可视化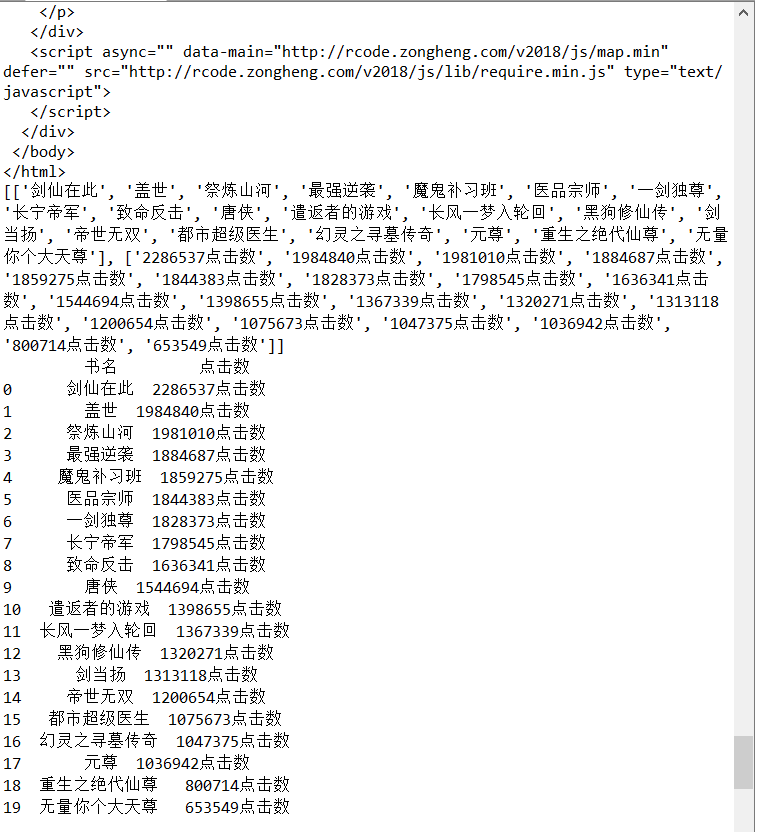

 浙公网安备 33010602011771号
浙公网安备 33010602011771号