
Lucene基础(1)
下一篇: Lucene基础(2)
一、Lucene介绍
http://www.kailing.pub/index/columns/colid/16.html
Documentation: http://lucene.apache.org/core/5_5_2/index.html
API: http://lucene.apache.org/core/5_5_2/core/overview-summary.html
按照官网的说法:Lucene is a Java full-text search engine. Lucene is not a complete application, but rather a code library and API that can easily be used to add search capabilities to applications.
全文搜索引擎组件,维基百科,lucene通常不会单独使用,一般会使用solr或者是elasticsearch,由于es中使用的版本是5.以下演示都是5.
为什么需要搜索引擎?MySQL这样的RDBMS并不适合用来做全文索引,假设要对一个网站的日志进行行为分析,这个数据规模并不适合放入MySQL中,即使可以放入MySQL中,MySQL无论是使用LIKE %%还是使用MyISAM fulltext的方案都不是很适合。
而搜索引擎技术就是解决方案。通过关键字搜索文档的技术,但是搜索算法非常复杂,一般非搜索方向的程序需要大量时间去掌握搜索算法也不太合适,Lucene的作用就是将复杂的搜索算法封装成相对而言非常简易使用的API。
原文链接:http://www.kailing.pub/article/index/arcid/72.html,非常详细。
全文检索大体分为2个过程: 索引创建(indexing)搜索(search).
1.1 反向索引结构
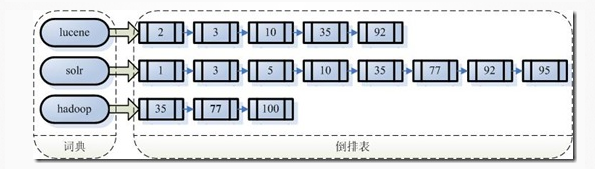
假设有100篇文档,编号从1到100,上面则是索引大致的结构。如果要搜索包含lucene和solr的关键字,则找出2者交集即可。
1.2 创建索引过程
第一步,通过IO读取文件至内存,得到文档Document
第二步,将Document传给分词组件(TOKENIZER)
将分档切分为单词
去除标点符号
去除stop word
经过分词之后得到的结果称为词元"Token"
第三步:将Token传递给语言处理组件LINGUISTIC PROCESSOR,对TOKEN进一步处理(以英语为例)
统一变为小写
将单词缩减为词根形式,例如"cars"->"car",这种操作称为stemming
将单词变为词根形式,例如"drove"->"drive",这种操作称为lemmatization
(注意stemming和Lemmatization的形式转换不同,因此实现算法也很不同)
经过linguistic processor处理的结果成为词(Term)
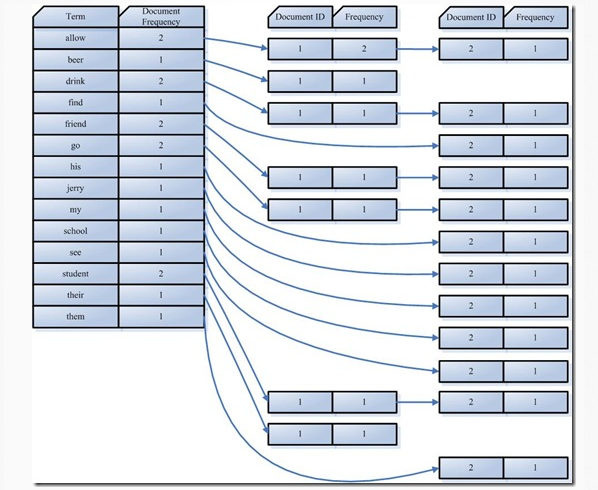
第四步: 将得到的词传递给索引组件(INDEXER)。
利用得到的Term创建一个字典。
对字典按照字母进行排序
合并相同的词(Term)成为倒排(Posing List)链表。
1.3 搜索过程
step 1 用户输入查询语句
查询语句也是有一定语法的,例如SQL,而在全文索引中根据实现不同而语法不同,不过最基本的有AND OR NOT...
step 2 对查询进行词法分析,语法分析以及语言处理
1. 词法分析用来识别单词和关键字.
例如用户输入Lucene AND learned NOT hadoop。分析时候,得到单词lucene, learned hadoop,关键字有AND NOT
2. 词法分词根据查询语句的语法规则生成一棵语法树
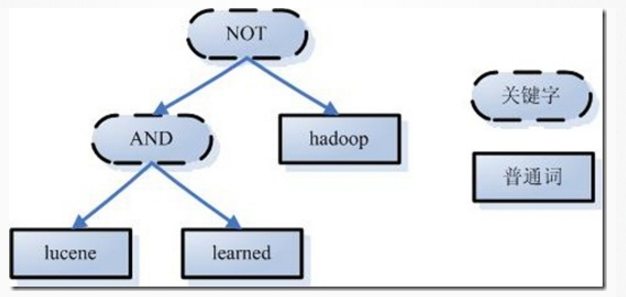
3. 语言处理,对语法树进行语言处理,和之前的linguistic processor处理几乎相同
step 3 根据索引,得到符合语法树的文档。
- 首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表。
- 其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
- 然后,将此链表与hadoop的文档链表进行差操作,去除包含hadoop的文档,从而得到既包含lucene又包含learn而且不包含hadoop的文档链表。
- 此文档链表就是我们要找的文档。
step 4 根据结果文档按照相关性进行排序
非常复杂,略
step 5 返回结果
二、Lucene Hello World
maven依赖
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>5.5.3</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>5.5.3</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>5.5.3</version> </dependency>
创建索引:
public class Indexer { public IndexWriter writer; /** * 实例化写索引 */ public Indexer(String indexDir)throws Exception{ Analyzer analyzer=new StandardAnalyzer();//分词器 IndexWriterConfig writerConfig=new IndexWriterConfig(analyzer);//写索引配置 //Directory ramDirectory= new RAMDirectory();//索引写的内存 Directory directory= FSDirectory.open(Paths.get(indexDir));//索引存储磁盘位置 writer=new IndexWriter(directory,writerConfig);//实例化一个写索引 } /** * 关闭写索引 * @throws Exception */ public void close()throws Exception{ writer.close(); } /** * 添加指定目录的所有文件的索引 * @param dataDir * @return * @throws Exception */ public int index(String dataDir)throws Exception{ File[] files=new File(dataDir).listFiles();//得到指定目录的文档数组 for(File file:files){ indexFile(file); } return writer.numDocs(); } public void indexFile(File file)throws Exception{ System.out.println("索引文件:"+file.getCanonicalPath());//打印索引到的文件路径信息 Document document=getDocument(file);//得到一个文档信息,相对一个表记录 writer.addDocument(document);//写入到索引,相当于插入一个表记录 } /** * 返回一个文档记录 * @param file * @return * @throws Exception */ public Document getDocument(File file)throws Exception{ Document document=new Document();//实例化一个文档 document.add(new TextField("context",new FileReader(file)));//添加一个文档信息,相当于一个数据库表字段 document.add(new TextField("fileName",file.getName(), Field.Store.YES));//添加文档的名字属性 document.add(new TextField("filePath",file.getCanonicalPath(),Field.Store.YES));//添加文档的路径属性 return document; } public static void main(String []ages){ String indexDir="G:\\projects-helloworld\\lucene\\src\\main\\resources\\LuceneIndex"; String dataDir="G:\\projects-helloworld\\lucene\\src\\main\\resources\\LuceneTestData"; Indexer indexer=null; int indexSum=0; try { indexer=new Indexer(indexDir); indexSum= indexer.index(dataDir); System.out.printf("完成"+indexSum+"个文件的索引"); }catch (Exception e){ e.printStackTrace(); }finally { try { indexer.close(); }catch (Exception e){ e.printStackTrace(); } } } }
使用索引进行查询
public class Searcher { public static void search(String indexDir,String q)throws Exception{ Directory dir= FSDirectory.open(Paths.get(indexDir));//索引地址 IndexReader reader= DirectoryReader.open(dir);//读索引 IndexSearcher is=new IndexSearcher(reader); Analyzer analyzer=new StandardAnalyzer(); // 标准分词器 QueryParser parser=new QueryParser("context", analyzer);//指定查询Document的某个属性 Query query=parser.parse(q);//指定查询索引内容,对应某个分词 TopDocs hits=is.search(query, 10);//执行搜索 System.out.println("匹配 "+q+"查询到"+hits.totalHits+"个记录"); for(ScoreDoc scoreDoc:hits.scoreDocs){ Document doc=is.doc(scoreDoc.doc); System.out.println(doc.get("fileName"));//打印Document的fileName属性 } reader.close(); } public static void main(String[] args) { String indexDir="G:\\projects-helloworld\\lucene\\src\\main\\resources\\LuceneIndex"; String q="file"; try { search(indexDir,q); } catch (Exception e) { e.printStackTrace(); } } }
三、关于Luke
Lucene常用工具,github地址:https://github.com/DmitryKey/luke/tree/pivot-luke-5.5.0
一个纯maven项目,使用mvn install生成jar既可以使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号