
图解kubernetes调度器抢占流程与算法设计
抢占调度是分布式调度中一种常见的设计,其核心目标是当不能为高优先级的任务分配资源的时候,会通过抢占低优先级的任务来进行高优先级的调度,本文主要学习k8s的抢占调度以及里面的一些有趣的算法
1. 抢占调度设计
1.1 抢占原理
抢占调度原理其实很简单就是通过高优先级的pod抢占低优先级的pod资源,从而满足高优先pod的调度
1.2 中断预算
在kubernetes中为了保证服务尽可能的高可用,设计PDB(PodDisruptionBudget)其核心目标就是在保证对应pod在指定的数量,主要是为了保证服务的可用性,在进行抢占的过程中,应尽可能遵守该设计,尽量不去抢占有PDB的资源,避免因为抢占导致服务的不可用
1.3 优先级反转
优先级反转是信号量里面的一种机制即因为低优先级任务的运行阻塞高优先级的任务运行
在k8s中抢占调度是通过高优先级抢占低优先级pod,如果高优先级pod依赖低优先级pod, 则会因为依赖问题,导致优先级失效,所以应该尽可能减少高优先级pod对低优先级的pod的依赖, 后面进行筛选源码分析时可以看到
1.4 抢占选择算法
抢占选择算法是指的通过抢占部分节点后,如何从被抢占的node数组中筛选出一个node节点,目前k8s中主要实现了5个算法
1.4.1 最少违反PDB
即最少违反PDB规则
1.4.2 最高优先级最小优先
比较所有node的最高优先级的pod,找到优先级最低的node
1.4.3 优先级总和最低优先
计算每个node上面的被抢占的pod优先级之和,选择优先级和最低的节点
1.4.4 最少抢占数量优先
计算需要抢占的节点数量最少的节点优先
1.4.5 最近更新节点优先
比较每个node中被驱逐的pod中最早启动的pod的启动时间,最近启动的pod的节点,会被选择
2. 源码设计
2.1 抢占核心流程
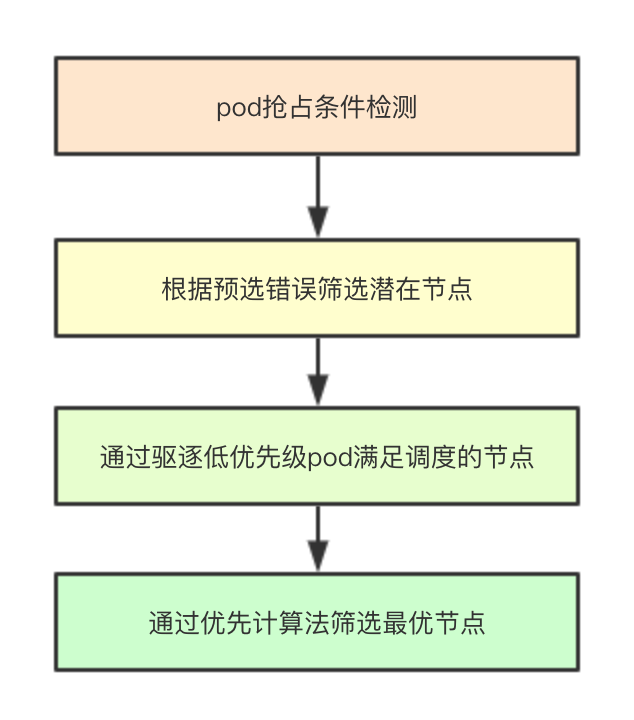
抢占的流程主要是通过Preempt来实现,其针对预选失败的节点来进行驱逐某些低优先级的pod来满足高优先级pod
func (g *genericScheduler) Preempt(pluginContext *framework.PluginContext, pod *v1.Pod, scheduleErr error) (*v1.Node, []*v1.Pod, []*v1.Pod, error) {
// 只允许预选失败的pod进行重试
fitError, ok := scheduleErr.(*FitError)
if !ok || fitError == nil {
return nil, nil, nil, nil
}
// 是否允许抢占其他提议的pod
if !podEligibleToPreemptOthers(pod, g.nodeInfoSnapshot.NodeInfoMap, g.enableNonPreempting) {
klog.V(5).Infof("Pod %v/%v is not eligible for more preemption.", pod.Namespace, pod.Name)
return nil, nil, nil, nil
}
// 获取当前集群中的所有node
allNodes := g.cache.ListNodes()
if len(allNodes) == 0 {
return nil, nil, nil, ErrNoNodesAvailable
}
// 初步筛选潜在的可以进行抢占操作的node
potentialNodes := nodesWherePreemptionMightHelp(allNodes, fitError)
if len(potentialNodes) == 0 {
klog.V(3).Infof("Preemption will not help schedule pod %v/%v on any node.", pod.Namespace, pod.Name)
// In this case, we should clean-up any existing nominated node name of the pod.
return nil, nil, []*v1.Pod{pod}, nil
}
// 获取所有pdb
pdbs, err := g.pdbLister.List(labels.Everything())
if err != nil {
return nil, nil, nil, err
}
// 针对之前初步筛选的node尝试进行抢占和预选操作,返回结果中包含所有可以通过抢占低优先级pod完成pod调度的node节点与抢占的pod
nodeToVictims, err := g.selectNodesForPreemption(pluginContext, pod, g.nodeInfoSnapshot.NodeInfoMap, potentialNodes, g.predicates,
g.predicateMetaProducer, g.schedulingQueue, pdbs)
if err != nil {
return nil, nil, nil, err
}
// 调用extenders进行再一轮的筛选
nodeToVictims, err = g.processPreemptionWithExtenders(pod, nodeToVictims)
if err != nil {
return nil, nil, nil, err
}
// 从筛选结果中选择最适合抢占的node
candidateNode := pickOneNodeForPreemption(nodeToVictims)
if candidateNode == nil {
return nil, nil, nil, nil
}
// 如果candidateNode不为nil,则找到一个最优的执行抢占操作的node, 返回低优先的提议的pod
// 还有抢占的pod和当前节点
nominatedPods := g.getLowerPriorityNominatedPods(pod, candidateNode.Name)
if nodeInfo, ok := g.nodeInfoSnapshot.NodeInfoMap[candidateNode.Name]; ok {
return nodeInfo.Node(), nodeToVictims[candidateNode].Pods, nominatedPods, nil
}
return nil, nil, nil, fmt.Errorf(
"preemption failed: the target node %s has been deleted from scheduler cache",
candidateNode.Name)
}
2.2 抢占条件检测
如果发现需要执行抢占的pod有提名的node并且对应node上面存在比自己优先级低的pod正在进行删除, 则不允许进行抢占
func podEligibleToPreemptOthers(pod *v1.Pod, nodeNameToInfo map[string]*schedulernodeinfo.NodeInfo, enableNonPreempting bool) bool {
if enableNonPreempting && pod.Spec.PreemptionPolicy != nil && *pod.Spec.PreemptionPolicy == v1.PreemptNever {
klog.V(5).Infof("Pod %v/%v is not eligible for preemption because it has a preemptionPolicy of %v", pod.Namespace, pod.Name, v1.PreemptNever)
return false
}
nomNodeName := pod.Status.NominatedNodeName
if len(nomNodeName) > 0 {
if nodeInfo, found := nodeNameToInfo[nomNodeName]; found {
podPriority := util.GetPodPriority(pod)
for _, p := range nodeInfo.Pods() {
if p.DeletionTimestamp != nil && util.GetPodPriority(p) < podPriority {
// 正在终止的优先级低于当前pod的pod就不会进行抢占
return false
}
}
}
}
return true
}
2.3 筛选潜在节点

每个node在预选阶段都会进行一个标记,标记当前node执行预选失败的原因,筛选潜在节点主要是根据对应的错误来进行筛选,如果不是不可解决的预选错误,则该node节点就可以参与接下来的抢占阶段
func nodesWherePreemptionMightHelp(nodes []*v1.Node, fitErr *FitError) []*v1.Node {
potentialNodes := []*v1.Node{}
// 根据预选阶段的错误原因,如果不存在无法解决的错误,则这些node可能在接下来的抢占流程中被使用
for _, node := range nodes {
if fitErr.FilteredNodesStatuses[node.Name].Code() == framework.UnschedulableAndUnresolvable {
continue
}
failedPredicates, _ := fitErr.FailedPredicates[node.Name]
if !unresolvablePredicateExists(failedPredicates) {
// 如果我们发现并不是不可解决的调度错误的时候,就讲这个节点加入到这里
// 可能通过后续的调整会让这些node重新满足
klog.V(3).Infof("Node %v is a potential node for preemption.", node.Name)
potentialNodes = append(potentialNodes, node)
}
}
return potentialNodes
}
不可通过调整的预选失败原因
var unresolvablePredicateFailureErrors = map[predicates.PredicateFailureReason]struct{}{
predicates.ErrNodeSelectorNotMatch: {},
predicates.ErrPodAffinityRulesNotMatch: {},
predicates.ErrPodNotMatchHostName: {},
predicates.ErrTaintsTolerationsNotMatch: {},
predicates.ErrNodeLabelPresenceViolated: {},
// 省略大部分,感兴趣的可以自己关注下
}
2.4 并行筛选节点
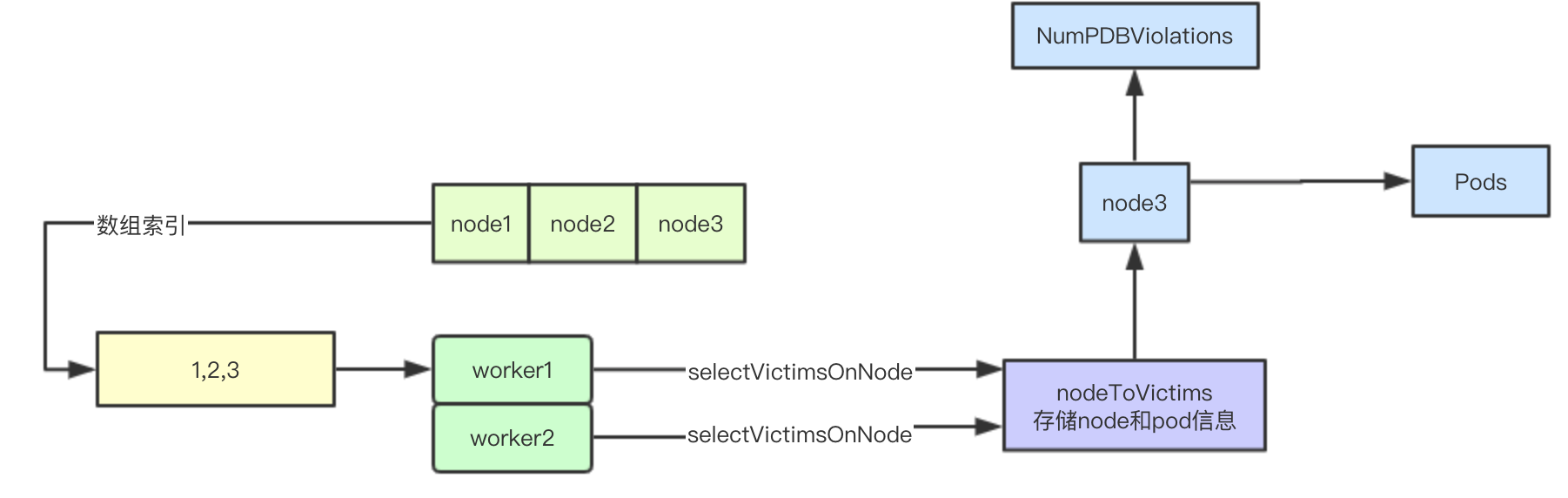
筛选抢占节点主要是并行对之前筛选潜在node进行尝试,通过驱逐低优先级pod满足高优先级pod调度,最终会筛选一批可以通过抢占来满足pod调度需要的节点, 其核心实现时通过selectVictimsOnNode来进行检测,继续往下看
func (g *genericScheduler) selectNodesForPreemption(
pluginContext *framework.PluginContext,
pod *v1.Pod,
nodeNameToInfo map[string]*schedulernodeinfo.NodeInfo,
potentialNodes []*v1.Node,
fitPredicates map[string]predicates.FitPredicate,
metadataProducer predicates.PredicateMetadataProducer,
queue internalqueue.SchedulingQueue,
pdbs []*policy.PodDisruptionBudget,
) (map[*v1.Node]*schedulerapi.Victims, error) {
nodeToVictims := map[*v1.Node]*schedulerapi.Victims{}
var resultLock sync.Mutex
// We can use the same metadata producer for all nodes.
meta := metadataProducer(pod, nodeNameToInfo)
checkNode := func(i int) {
nodeName := potentialNodes[i].Name
var metaCopy predicates.PredicateMetadata
if meta != nil {
metaCopy = meta.ShallowCopy()
}
pods, numPDBViolations, fits := g.selectVictimsOnNode(pluginContext, pod, metaCopy, nodeNameToInfo[nodeName], fitPredicates, queue, pdbs)
if fits {
resultLock.Lock()
victims := schedulerapi.Victims{
Pods: pods,
NumPDBViolations: numPDBViolations,
}
nodeToVictims[potentialNodes[i]] = &victims
resultLock.Unlock()
}
}
workqueue.ParallelizeUntil(context.TODO(), 16, len(potentialNodes), checkNode)
return nodeToVictims, nil
}
2.5 单点筛选流程
selectVictimsOnNode即单点筛选流程是针对单个node来指向具体的驱逐抢占决策的流程, 其核心流程如下
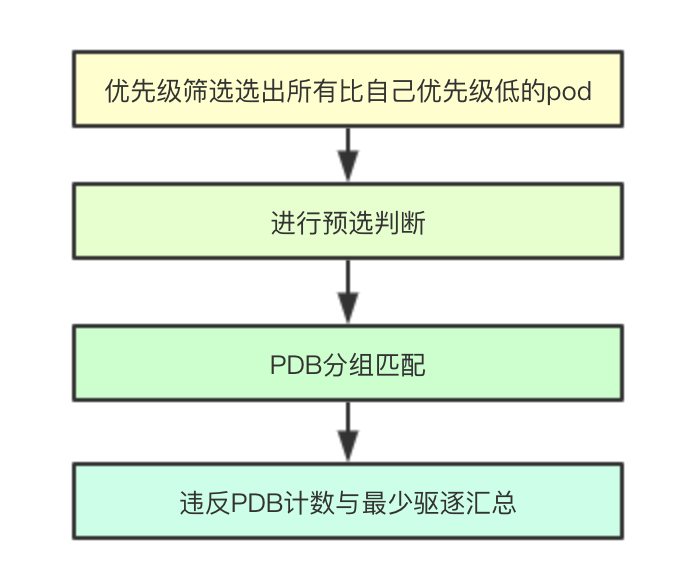
2.5.1 优先级筛选
优先级筛选首先会对当前node上面的所有节点进行优先级排序,移除所有比当前pod低的pod
potentialVictims := util.SortableList{CompFunc: util.MoreImportantPod}
nodeInfoCopy := nodeInfo.Clone()
removePod := func(rp *v1.Pod) {
nodeInfoCopy.RemovePod(rp)
if meta != nil {
meta.RemovePod(rp, nodeInfoCopy.Node())
}
}
addPod := func(ap *v1.Pod) {
nodeInfoCopy.AddPod(ap)
if meta != nil {
meta.AddPod(ap, nodeInfoCopy)
}
}
podPriority := util.GetPodPriority(pod)
for _, p := range nodeInfoCopy.Pods() {
if util.GetPodPriority(p) < podPriority {
// 移除所有优先级比自己低的pod
potentialVictims.Items = append(potentialVictims.Items, p)
removePod(p)
}
}
2.5.2 预选判断
对移除所有优先级比自己的pod之后,会尝试进行预选流程,如果发现预选流程失败,则当前node即使通过移除所有比自己优先级低的pod也不能满足调度需求,则就进行下一个node判断
if fits, _, _, err := g.podFitsOnNode(pluginContext, pod, meta, nodeInfoCopy, fitPredicates, queue, false); !fits {
if err != nil {
klog.Warningf("Encountered error while selecting victims on node %v: %v", nodeInfo.Node().Name, err)
}
return nil, 0, false
}
2.5.3 PDB分组与分组算法
PDB分组就是对当前节点上筛选出来的低优先级pod按照是否有PDB匹配来进行分组,分为违反PDB和未违反PDB的两组
violatingVictims, nonViolatingVictims := filterPodsWithPDBViolation(potentialVictims.Items, pdbs)
分组算法其实也不难,只需要遍历所有的pdb和pod就可以得到最终的分组
func filterPodsWithPDBViolation(pods []interface{}, pdbs []*policy.PodDisruptionBudget) (violatingPods, nonViolatingPods []*v1.Pod) {
for _, obj := range pods {
pod := obj.(*v1.Pod)
pdbForPodIsViolated := false
// A pod with no labels will not match any PDB. So, no need to check.
if len(pod.Labels) != 0 {
for _, pdb := range pdbs {
if pdb.Namespace != pod.Namespace {
continue
}
selector, err := metav1.LabelSelectorAsSelector(pdb.Spec.Selector)
if err != nil {
continue
}
// A PDB with a nil or empty selector matches nothing.
if selector.Empty() || !selector.Matches(labels.Set(pod.Labels)) {
continue
}
// We have found a matching PDB.
if pdb.Status.PodDisruptionsAllowed <= 0 {
pdbForPodIsViolated = true
break
}
}
}
if pdbForPodIsViolated {
violatingPods = append(violatingPods, pod)
} else {
nonViolatingPods = append(nonViolatingPods, pod)
}
}
return violatingPods, nonViolatingPods
}
2.5.4 违反PDB计数与最少驱逐汇总
会分别对违反PDB和不违反的pod集合来进行reprievePod检测,如果加入当前pod后,不能满足预选筛选流程,则该pod则必须被进行移除加入到victims中, 同时如果是违反PDB的pod则需要进行违反pdb计数numViolatingVictim
reprievePod := func(p *v1.Pod) bool {
// 我们首先将pod加入到meta中
addPod(p)
fits, _, _, _ := g.podFitsOnNode(pluginContext, pod, meta, nodeInfoCopy, fitPredicates, queue, false)
//
if !fits {
// 如果我们加入了pod然后导致了预选不成功,则这个pod必须给移除
removePod(p)
victims = append(victims, p) // 添加到我们需要移除的列表里面
klog.V(5).Infof("Pod %v/%v is a potential preemption victim on node %v.", p.Namespace, p.Name, nodeInfo.Node().Name)
}
return fits
}
for _, p := range violatingVictims {
if !reprievePod(p) {
numViolatingVictim++
}
}
// Now we try to reprieve non-violating victims.
for _, p := range nonViolatingVictims {
// 尝试移除未违反pdb的pod
reprievePod(p)
}
return victims, numViolatingVictim, true
2.6 筛选最优抢占
最优筛选主要是通过pickOneNodeForPreemption实现,其中筛选数据存储结构主要是通过重用minNodes1和minNodes2两段内存来进行实现,这两个node数组分别配有两个计数器lenNodes1和lenNodes2, 针对具有相同优先级、相同数量的node,每增加一个会进行一次计数器累加, 核心算法流程如下
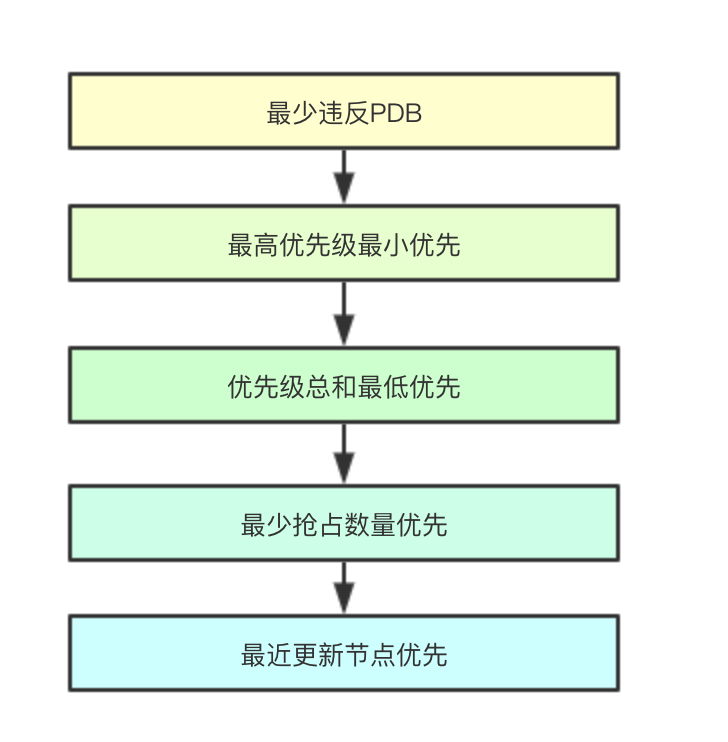
2.6.1 最少违反PDB
最少违反PDB是根据前面统计的违反PDB的计数统计,找到最少违反的node,如果是单个node则直接返回筛选结束
minNumPDBViolatingPods := math.MaxInt32
var minNodes1 []*v1.Node
lenNodes1 := 0
for node, victims := range nodesToVictims {
if len(victims.Pods) == 0 {
// 如果发现一个noed不需要任何抢占,则返回它
return node
}
numPDBViolatingPods := victims.NumPDBViolations
if numPDBViolatingPods < minNumPDBViolatingPods {
// 如果小于最小pdb数量, 如果数量发生变化,就重置
minNumPDBViolatingPods = numPDBViolatingPods
minNodes1 = nil
lenNodes1 = 0
}
if numPDBViolatingPods == minNumPDBViolatingPods {
// 多个相同的node会进行追加,并累加计数器
minNodes1 = append(minNodes1, node)
lenNodes1++
}
}
if lenNodes1 == 1 {
return minNodes1[0]
}
2.6.2 最高优先级最小优先
最高优先级最小优先是指通过对比多个node的最高优先级的pod,优先级最低的那个node被选中,如果多个则进行下一个算法
minHighestPriority := int32(math.MaxInt32)
var minNodes2 = make([]*v1.Node, lenNodes1)
lenNodes2 := 0
for i := 0; i < lenNodes1; i++ {
node := minNodes1[i]
victims := nodesToVictims[node]
// highestPodPriority is the highest priority among the victims on this node.
// 返回优先级最高的pod
highestPodPriority := util.GetPodPriority(victims.Pods[0])
if highestPodPriority < minHighestPriority {
// 重置状态
minHighestPriority = highestPodPriority
lenNodes2 = 0
}
if highestPodPriority == minHighestPriority {
// 如果优先级相等则加入进去
minNodes2[lenNodes2] = node
lenNodes2++
}
}
if lenNodes2 == 1 {
return minNodes2[0]
}
2.6.3 优先级总和最低优先
统计每个node上的所有被抢占的pod的优先级的总和,然后在多个node之间进行比较,优先级总和最低的节点被选中
minSumPriorities := int64(math.MaxInt64)
lenNodes1 = 0
for i := 0; i < lenNodes2; i++ {
var sumPriorities int64
node := minNodes2[i]
// 统计所有优先级
for _, pod := range nodesToVictims[node].Pods {
sumPriorities += int64(util.GetPodPriority(pod)) + int64(math.MaxInt32+1)
}
if sumPriorities < minSumPriorities {
minSumPriorities = sumPriorities
lenNodes1 = 0
}
if sumPriorities == minSumPriorities {
minNodes1[lenNodes1] = node
lenNodes1++
}
}
// 最少优先级的node
if lenNodes1 == 1 {
return minNodes1[0]
}
2.6.4 最少抢占数量优先
最少抢占数量优先即统计每个node被抢占的节点数量,数量最少得被选中
minNumPods := math.MaxInt32
lenNodes2 = 0
for i := 0; i < lenNodes1; i++ {
node := minNodes1[i]
numPods := len(nodesToVictims[node].Pods)
if numPods < minNumPods {
minNumPods = numPods
lenNodes2 = 0
}
if numPods == minNumPods {
minNodes2[lenNodes2] = node
lenNodes2++
}
}
// 最少节点数量
if lenNodes2 == 1 {
return minNodes2[0]
}
2.6.5 最近更新节点优先
该算法会筛选每个node驱逐的pod中优先级最高的pod的最早更新时间(其实就是说这个pod早就被创建了),然后在多个node之间进行比较,如果谁上面的时间越新(即这个node上的pod可能是最近被调度上去的),则就选中这个节点
latestStartTime := util.GetEarliestPodStartTime(nodesToVictims[minNodes2[0]])
if latestStartTime == nil {
// If the earliest start time of all pods on the 1st node is nil, just return it,
// which is not expected to happen.
// 如果第一个节点上所有pod的最早开始时间为零,那么返回它
klog.Errorf("earliestStartTime is nil for node %s. Should not reach here.", minNodes2[0])
return minNodes2[0]
}
nodeToReturn := minNodes2[0]
for i := 1; i < lenNodes2; i++ {
node := minNodes2[i]
// Get earliest start time of all pods on the current node.
// 获取当前node最早启动时间
earliestStartTimeOnNode := util.GetEarliestPodStartTime(nodesToVictims[node])
if earliestStartTimeOnNode == nil {
klog.Errorf("earliestStartTime is nil for node %s. Should not reach here.", node)
continue
}
if earliestStartTimeOnNode.After(latestStartTime.Time) {
latestStartTime = earliestStartTimeOnNode
nodeToReturn = node
}
}
return nodeToReturn
阅读总结
因为是纯的算法流程,并没有复杂的数据结构,大家看看就好,调度器的设计可能就看到这了,后面把之前的都串起来,算是一个总结,如果有兴趣我就再看看 SchedulerExtender和framework的设计, 其实学习scheduler调度器部分只是因为自己对分布式调度这块比较好奇,而且自己有运维开发的经验,这对pod调度类似场景并不陌生,看起来总的来说相对容易一点,而且我只分析了核心的数据结构和算法,还有几个阶段,为了避免陷入对kubenretes一些复杂逻辑的处理,我都尽量简化逻辑,就是希望即时不去看k8s scheduler的代码,也能有所收获
微信号:baxiaoshi2020
关注公告号阅读更多源码分析文章
更多文章关注 www.sreguide.com
本文由博客一文多发平台 OpenWrite 发布



 浙公网安备 33010602011771号
浙公网安备 33010602011771号