


7.OpenACC
OpenACC:
openacc 可以用于fortran, c 和 c++程序,可以运行在CPU或者GPU设备.
openacc的代码就是在原有的C语言基础上进行修改,通过添加:
compiler directives 编译器指令(pragmas): #pragma 来标示.
cuda 中有 __syncthreads()来进行线程同步,目前的OpenAcc还没有线程同步机制.
OpenAcc device model

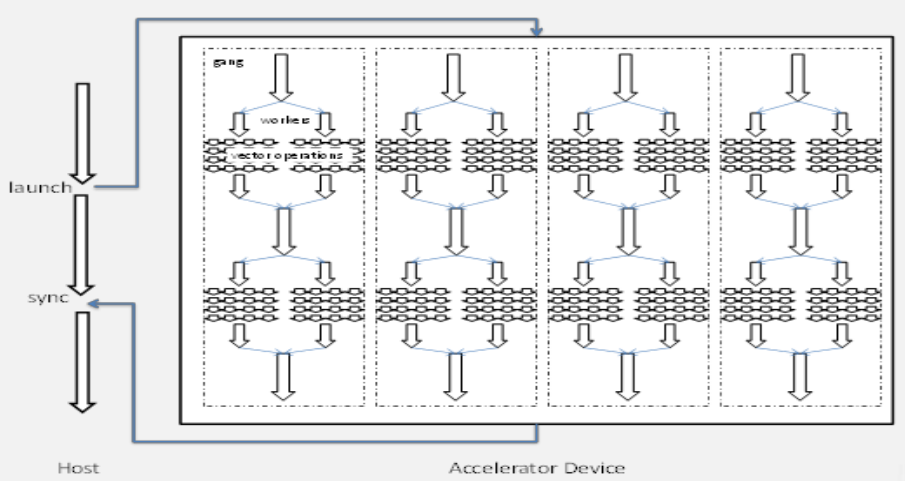
OpenAcc excute model
parallel loops
下面地一段代码和第二段代码是等效的,在OpenAcc中一个parallel区域有一个单个loop组成.
#pragma acc parallel loop copyin(M[0:Mh*Mw]) copyin(N[0:Mw*Nw]) copyout(P[0:Mh*Nw]) for (int i=0; i<Mh; i++) { ... } is equivalent to: #pragma acc parallel copyin(M[0:Mh*Mw]) copyin(N[0:Mw*Nw]) copyout(P[0:Mh*Nw]) { #pragma acc loop for (int i=0; i<Mh; i++) { ... } } }
copyin对应拷贝内存从host到device,
copyout对应拷贝内存从device到host
gangs and workers
gangs可以类比成cuda的block,
workers可以类比成thread
#pragma acc parallel num_gangs(1024) num_workers(32) { #pragma acc loop gang for (int i=0; i<2048; i++) { #pragma acc loop worker for (int j=0; j<512; j++) { foo(i,j); } } }
这段代码会分配: 1024*32 = 32K 个thread, 这两个循环题一共是执行2048*512 = 1M, 所以每个thread执行foo()函数 1M/32K = 32 次.
再看另外一个代码:
#pragma acc parallel copyout(a) num_gangs(1024) num_workers(32) { a = 23; }
这段代码会分配1023*32个thread,每个gang=1024, 对于每个gang来说执行a =23 是冗余的,只需要执行一次即可.再看下面的例子:
#pragma acc parallel num_gangs(32) { Statement 1; #pragma acc loop gang for (int i=0; i<n; i++) { Statement 2; } Statement 3; #pragma acc loop gang for (int i=0; i<m; i++) { Statement 4; } Statement 5; if (condition) Statement 6; }
gang有32个,statement2的循环次数是n,statement4循环次数是m, 最终到底分配多少个thread取决于编译器,有可能m>n,则分配m个,当然实际情况可能更加复杂,
statement1, 3, 5,6 对于32gang来说是冗余的,情况和上面的相同,可以看出OpenAcc中的冗余是对于gang来说的,下面的这种写法可以消除这种冗余:
#pragma acc parallel num_gangs(1) num_workers(32) { Statement 1; #pragma acc loop gang for (int i=0; i<n; i++) { Statement 2; } Statement 3; #pragma acc loop gang for (int i=0; i<m; i++) { Statement 4; } Statement 5; if (condition) Statement 6; }
kernel regions
#pragma acc kernels { #pragma acc loop num_gangs(1024) for (int i=0; i<2048; i++) { a[i] = b[i]; } #pragma acc loop num_gangs(512) for (int j=0; j<2048; j++) { c[j] = a[j]*2; } for (int k=0; k<2048; k++) { d[k] = c[k]; } }
这段代码和前面的代码比较起来,区别是 acc kernel, 而前面的代码用的是acc parallel.
Kernel 结构主要是描述程序员的意图: 当前程序适合并行,编译器根据这个描述会有非常灵活的表现,
而parallel则是规定,规定编译器必须把下面的代码段并行操作.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号