

CUDA基本概念
CUDA计算模型
CUDA中计算分为两部分,串行部分在Host上执行,即CPU,而并行部分在Device上执行,即GPU。
相比传统的C语言,CUDA增加了一些扩展,包括了库和关键字。
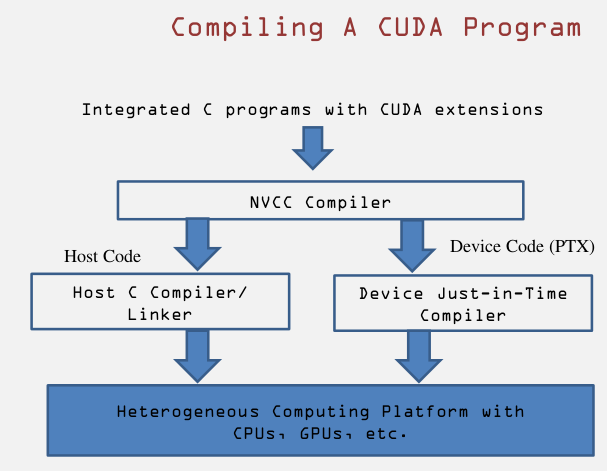
CUDA代码提交给NVCC编译器,该编译器将代码分为Host代码和Device代码两部分。
Host代码即为原本的C语言,交由GCC,ICC或其他的编译器处理;
Device代码部分交给一个称为实时(Just in time)编译器的组件,在给代码运行之前编译。Device code编译成类似java的字节码文件,称为PTX,然后生成ISA运行在GPU上面,或者协处理上面。
Device上的并行线程阵列
并行线程阵列由Grid——Block——Thread三级结构组成,如下图所示:
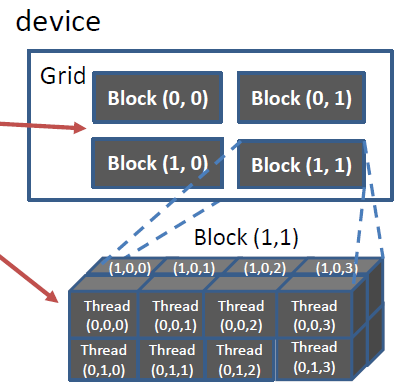
每一个Grid中包含N个Block,每一个Block中包含N个Thread。
这里需要提到SPMD概念:SPMD,即Single Program Multiple Data,指相同的程序处理不同的数据。在Device端执行的线程即属于此类型,每个Grid中的所有线程执行相同的程序(共享PC和IR指针)。但是这些线程需要从共享的存储中取得自身的数据,这样就需要一种数据定位机制。CUDA的定位公式如下:
i = blockIdx.x * blockDim.x + threadIdx.x
bllockIdx标识Block,blockDim为Block在该维度上的大小,threadIdx为在Block内部线程的标识。
注意到后缀的.x,这是因为CUDA的线程阵列可以是多维的(如上图),blockIdx和threadIdx最多可以达到3维。这能够为处理图像和空间数据提供极大的便利。
Device上的内存模型
Device上的内存模型如下图所示:
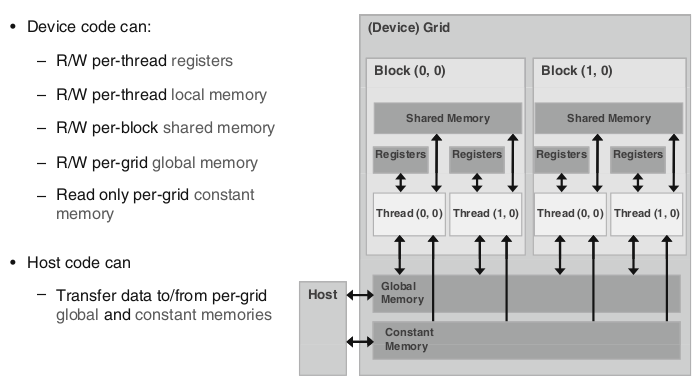
每个 thread 都有自己的一份 register 和 local memory 的空间。
同一个 block 中的每个thread 则有共享的一份 share memory。
此外,所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、 texture memory。
不同的 grid 则有各自的 globalmemory、constant memory 和 texture memory
每个Grid有一个共享的存储,其中每个线程有自己的寄存器。Host代码负责分配Grid中的共享内存空间,以及数据在Host、Device之间的传输。Device代码则只与共享内存、本地寄存器交互。
函数标识
CUDA的函数分为三种:

注意都是双下划线。其中的__global__函数即为C代码中调用Device上计算的入口。
__host__函数为传统的C函数,也是默认的函数类型。之所以增加这一标识的原因是有时候可能__device__和__host__共同使用,这时可以让编译器知道,需要编译两个版本的函数。
