卷积神经网络(CNN)
1. 影像辨识分类 Image Classfication
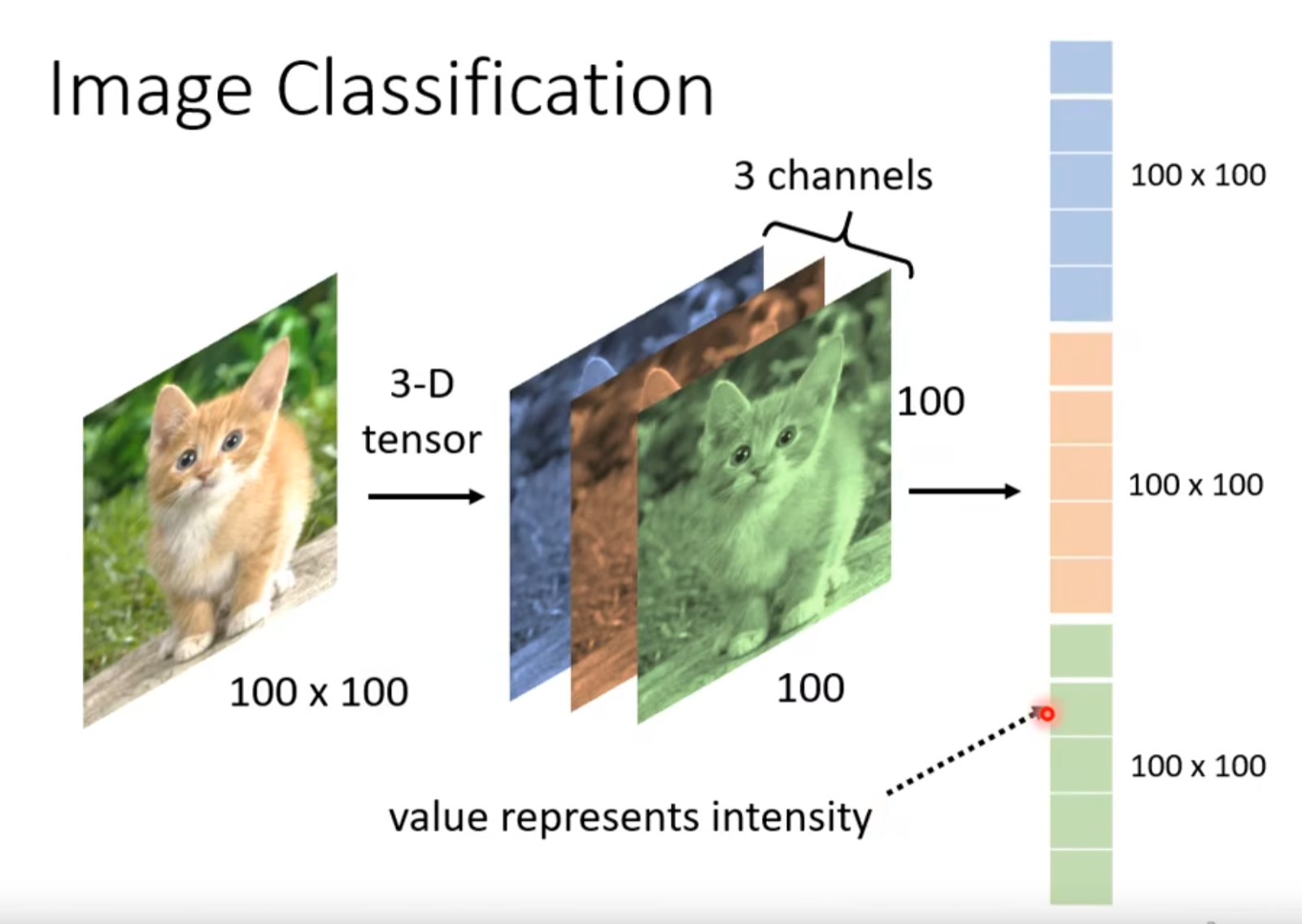
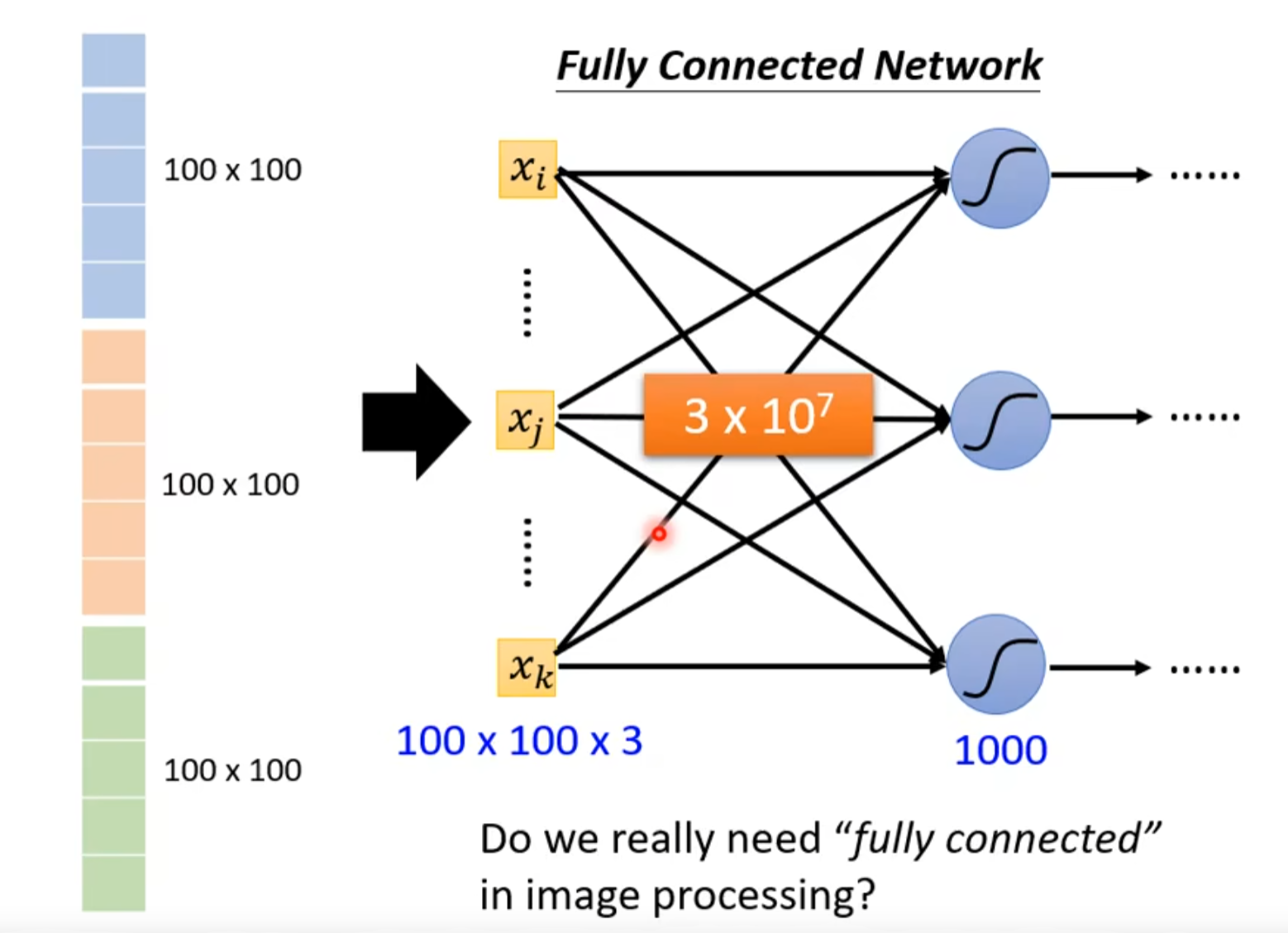
- 参数越多,弹性越大,过拟合概率也大,所以我们是否真的需要这么多参数?
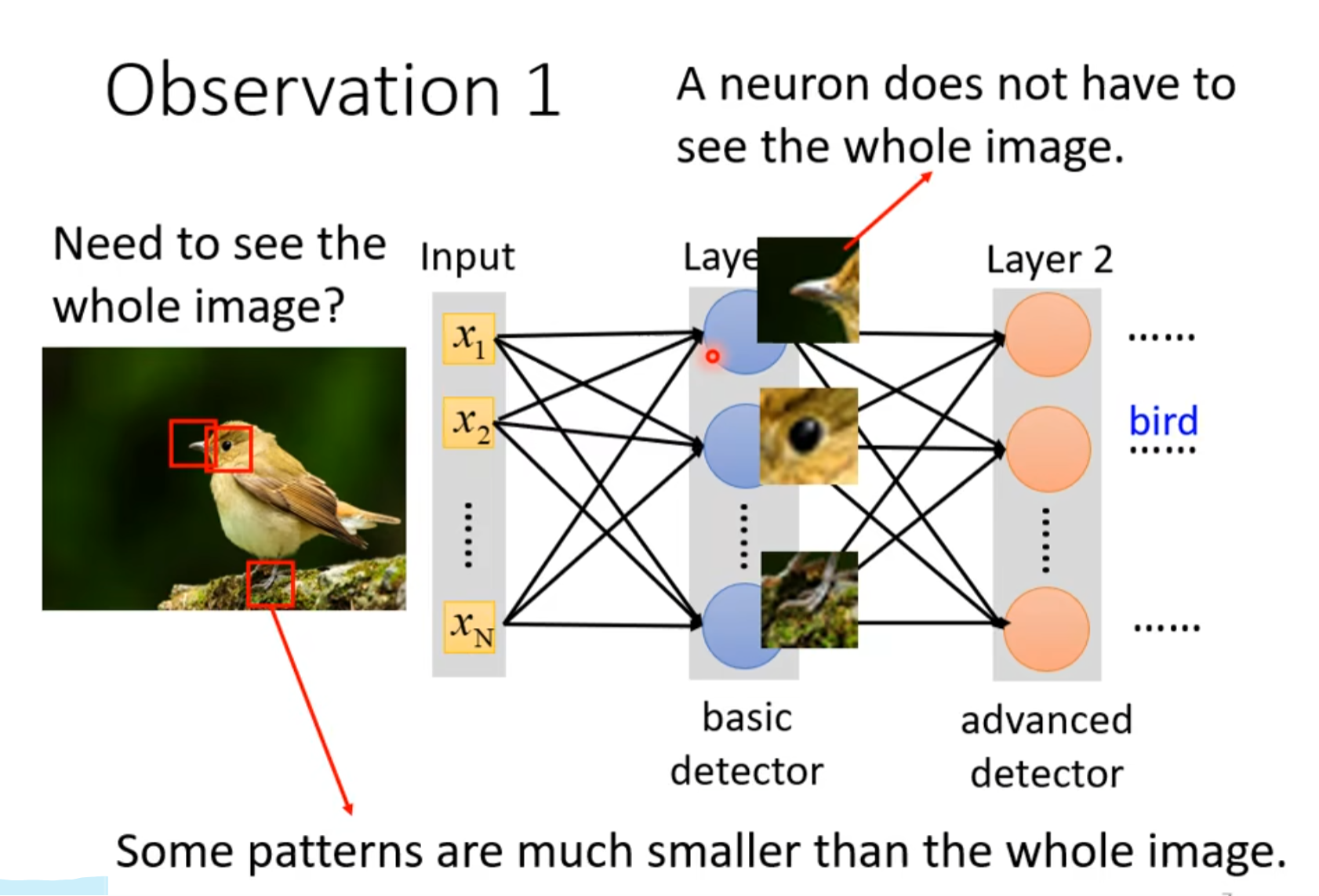
1.1 观察1
- 寻找一些重要的pattern很关键
- 故可以简化,使用感受野识别特定的区域
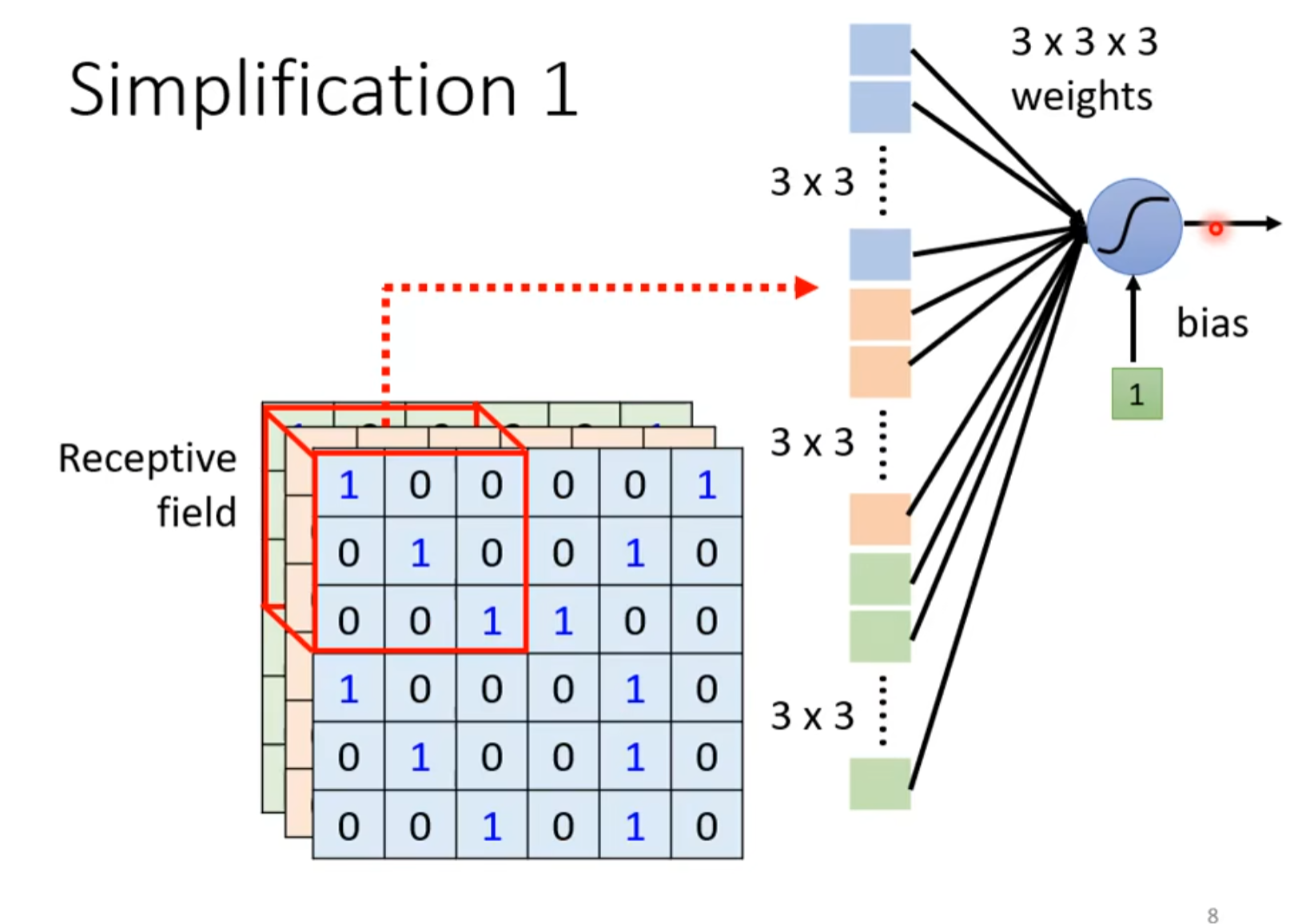
- 感受野可以任意设计,最经典的设计如下图,一般kernel size指长✖宽,因为通常包括所有channel
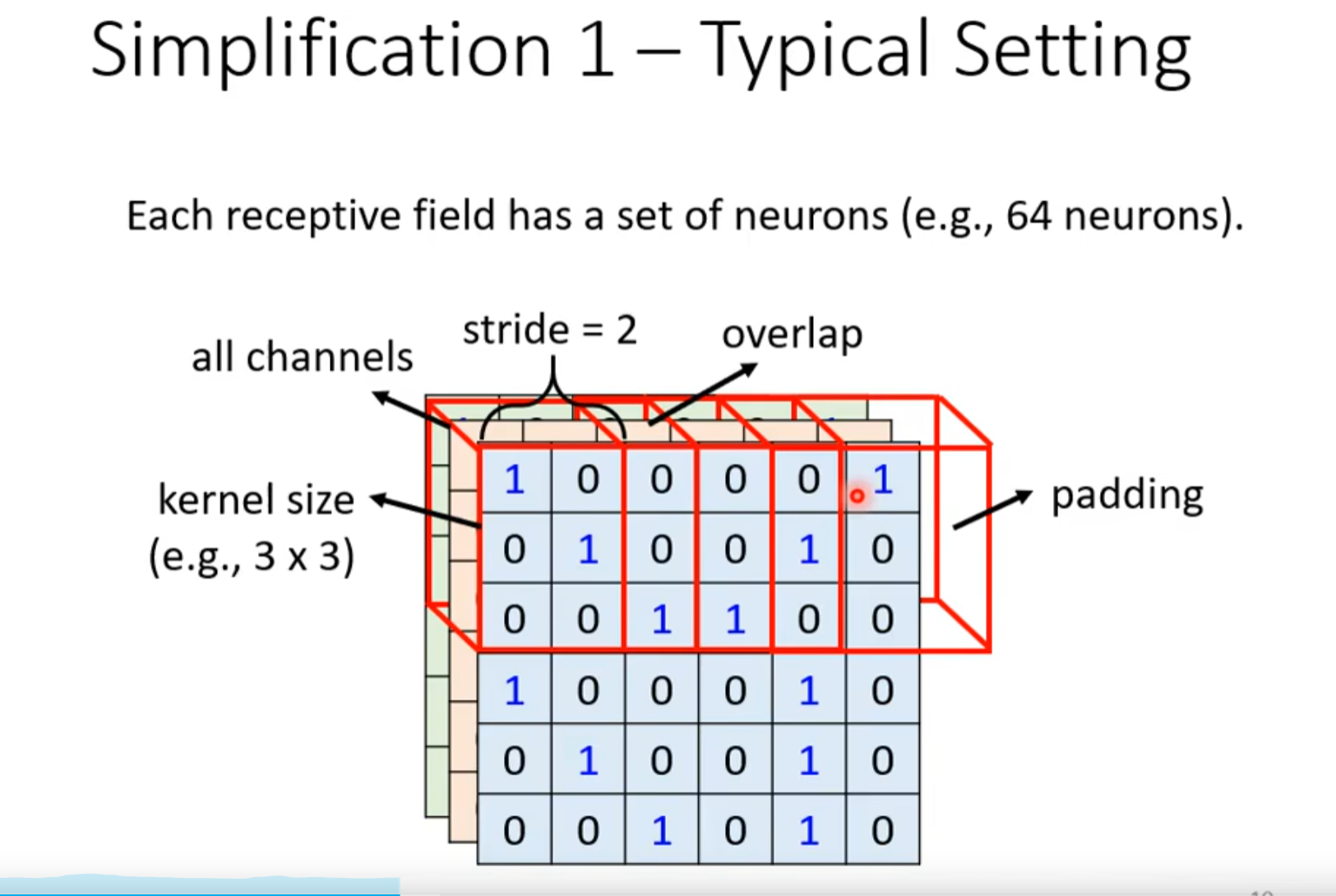
- 移动范围为stride,但是如果超出范围,使用padding
1.2 观察2
- 相同的pattern可能会出现在不同的区域,但是这些侦测鸟嘴的感受野应该是一样的,但是守备的范围不一样
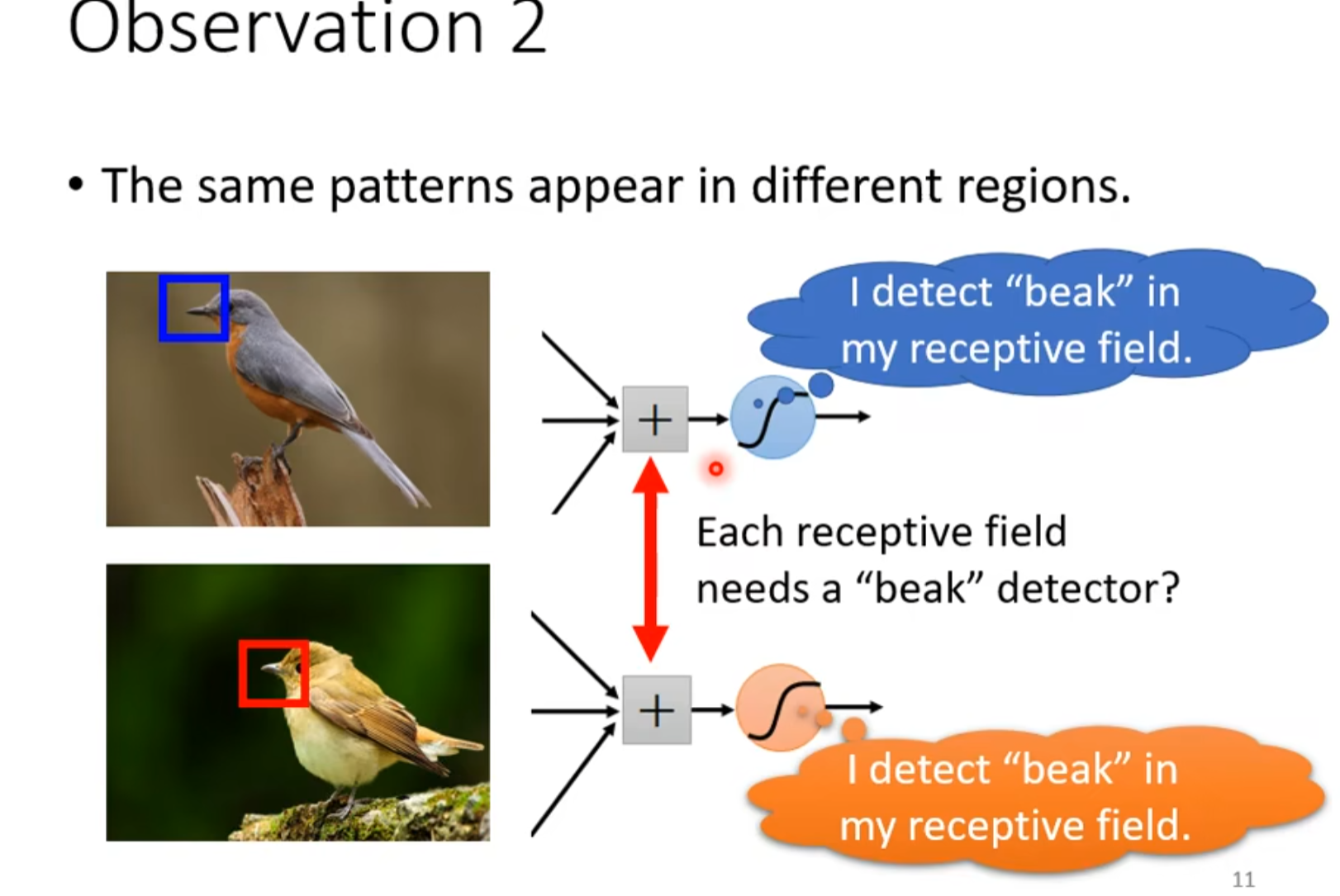
- 所以可以使用共享参数的方法减少参数
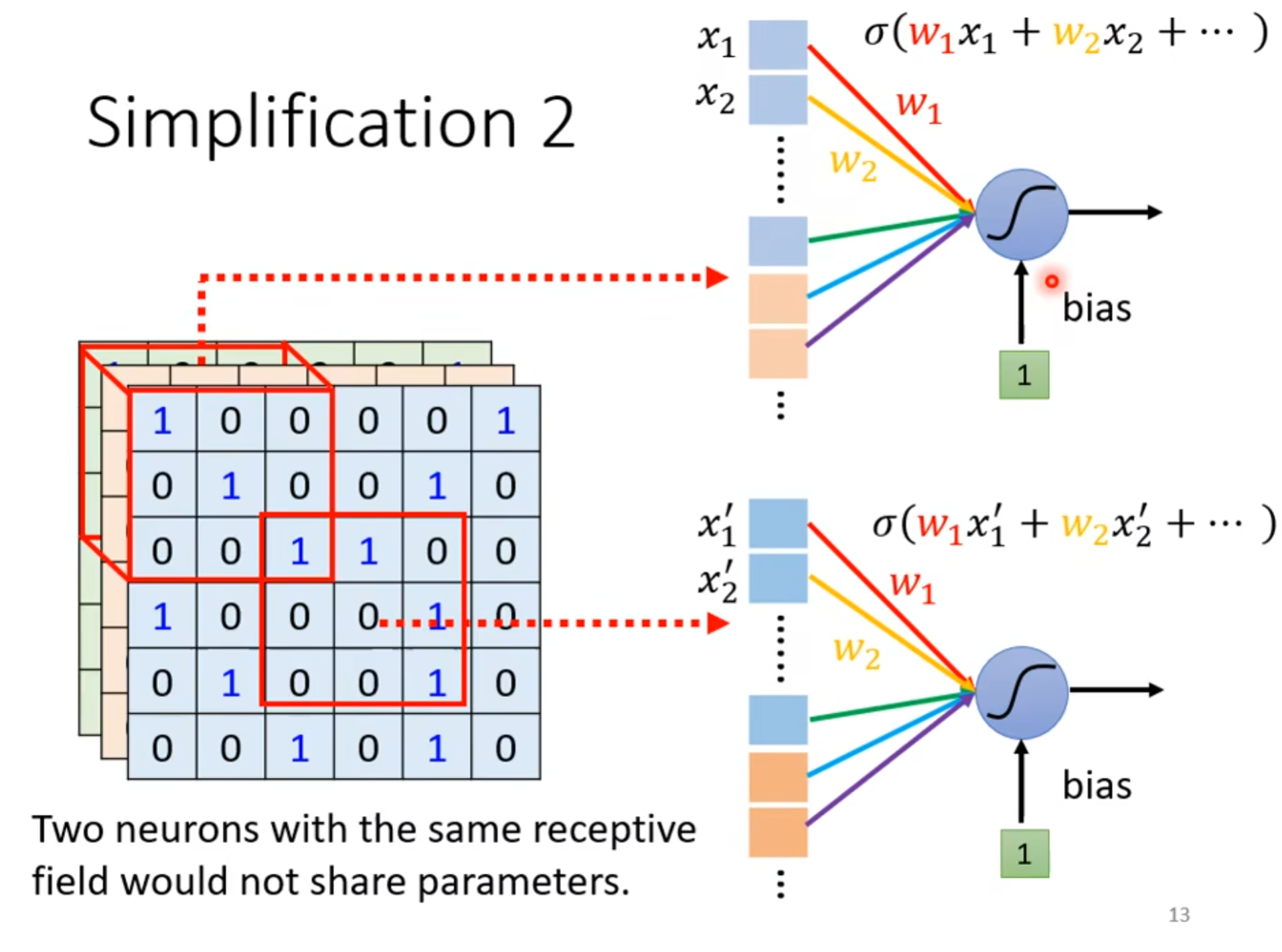
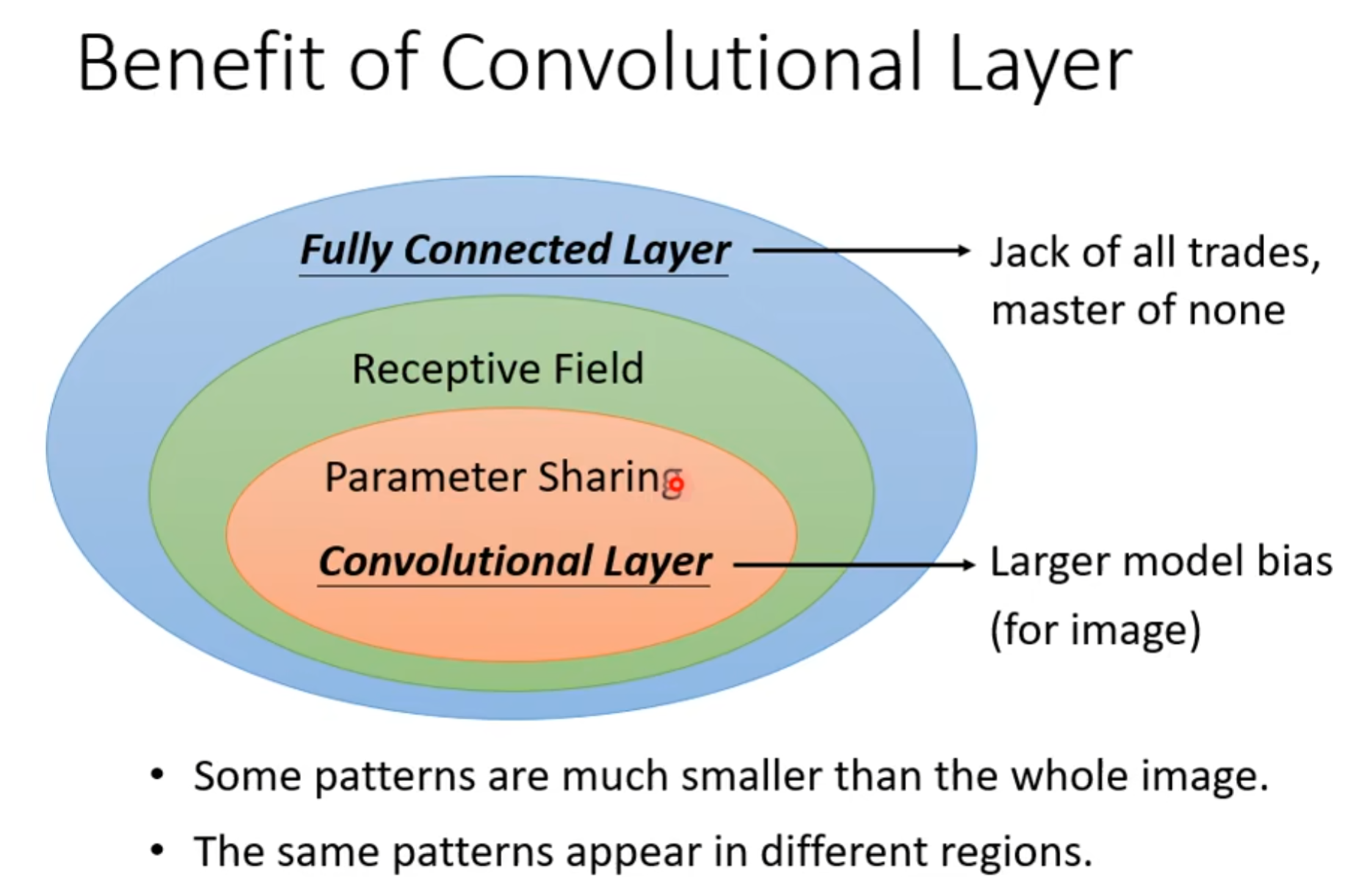
- CNN = Receptive Field + Parameter Sharing
1.3 观察3
- 将大图片缩小

- 使用MAX Pooling,选择较大范围中的最大值作为代表
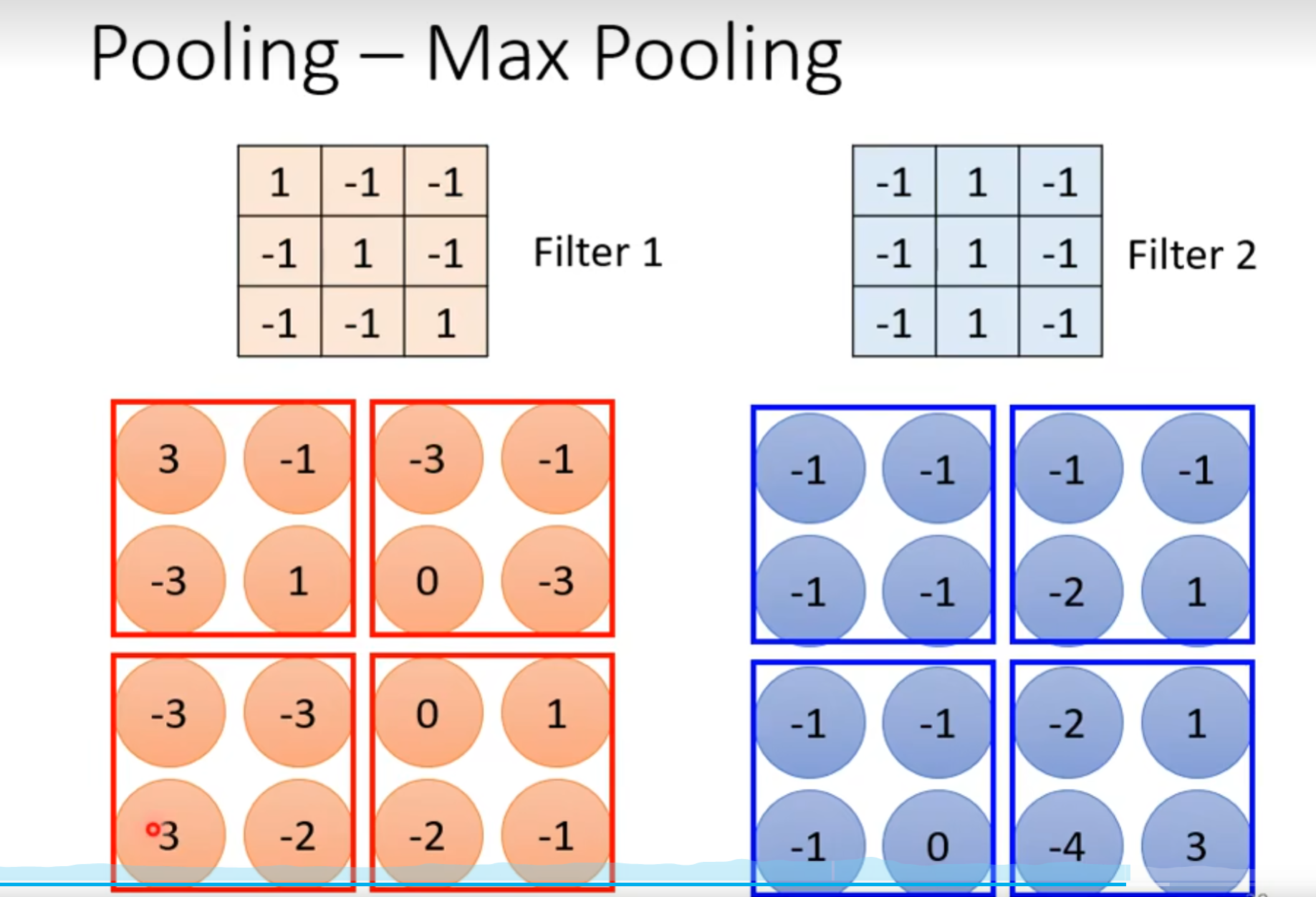
- 在当今计算算力充足的情况下,Pooling可有可无
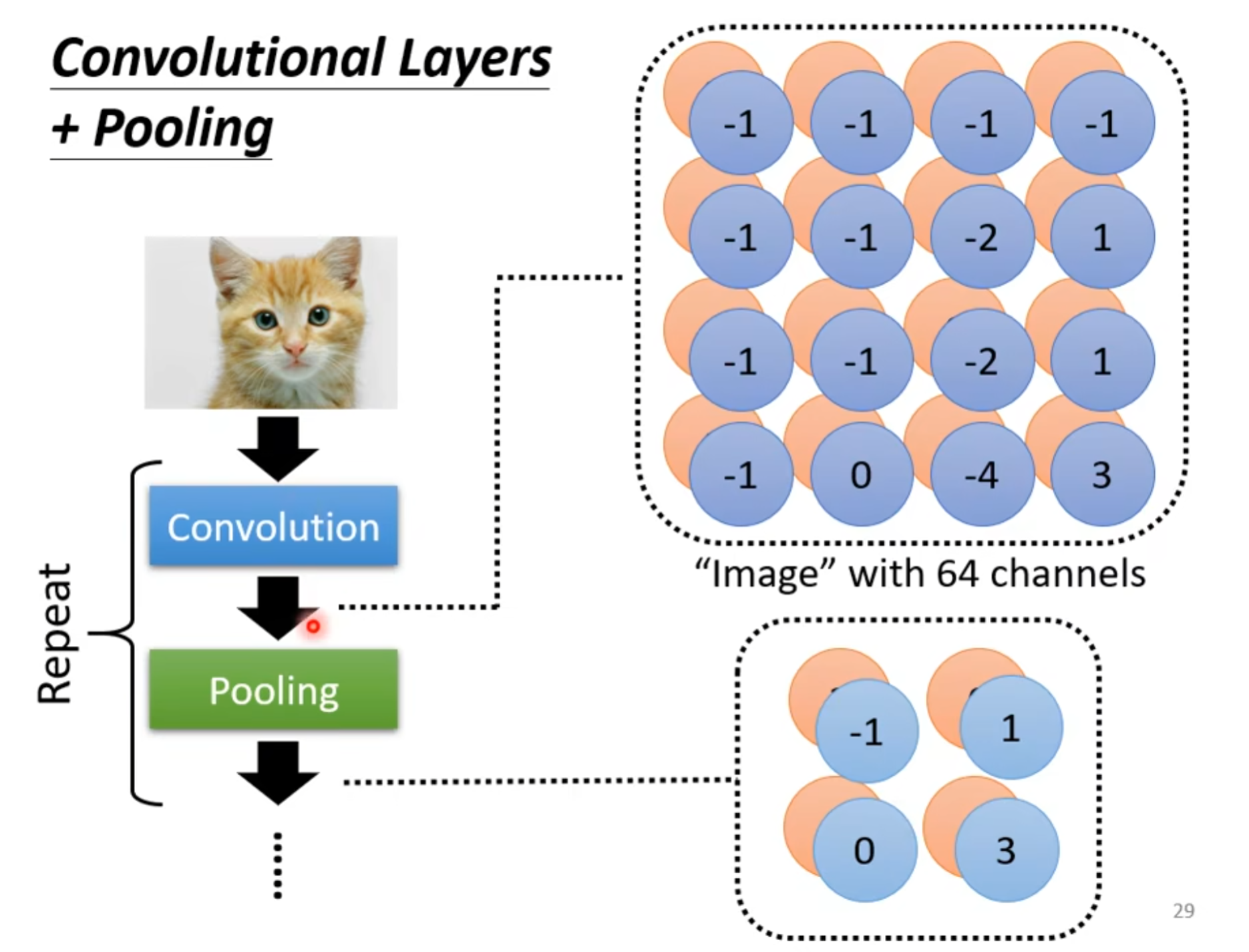
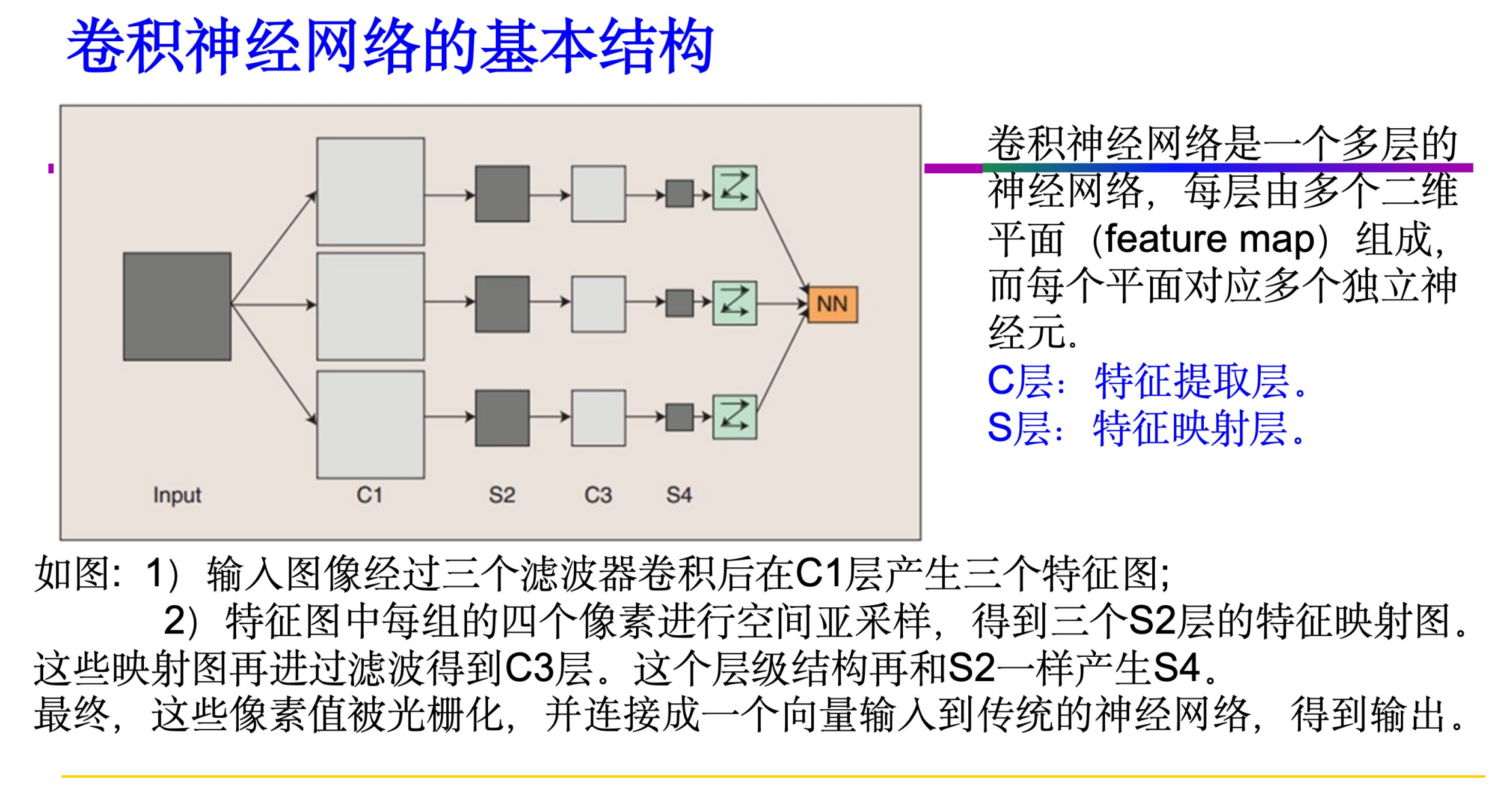
2. 卷积神经网络(CNN)简介
-
CNN(Convolutional Neutral Network,CNN)是一种常见的深度学习架构,受生物自然视觉认识机制启发而来
-
早期由于缺乏训练数据和计算能力,要在不产生过拟合的情况下训练高性能卷积神经网络很困难,近年来大规模标记数据和GPU的发展,使得卷积神经网络研究涌现并取得一流结果
-
著名CNN框架:AlexNet、ZFNet、VGGNet、GoogleNet、ResNet
-
卷积处理过程可以看作是多个卷积核分别对图像的不同区域作用的结果
3. CNN特点
- 可以当作是一个分类器,也可以看作是一种特征提取方式(把中间某一层的输出当作数据的一种特征表示)
- CNN能够得出原始图像的有效表征,意味着CNN能经极少的预处理,识别视觉上面的规律
- 基于大规模的数据,少量数据无法将参数训练充分
- CNN 对于scaling和rotation泛化能力弱的(可能单纯放大图片就会导致CNN失效),所以需要data augmentation(数据增强),对于能够处理这个问题的网络架构可以用Spatial Transformer Layer
4. CNN与BP
4.1 相同点
- CNN是人工神经网络的一种,是一种前馈神经网络,与BP类似,都采用了前向传播计算输出值,反向传播调整权重和偏置
4.2 不同点
-
CNN与标准的BP最大的不同是:CNN中相邻层之间的神经单元并不是全连接,而是部分连接,也就是某个神经单元的感知区域来自于上层的部分神经单元,而不是像BP那样与所有的神经单元相连接
-
整个CNN网络结构搭建好以后,训练只用按照多层神经网络那样训练即可,其中的权值更新策略都是一致的。所以总体来说,卷积神经网络与普通的多层神经网络,就是结构上不同。
-
卷积神经网络多了特征提取层与降维层,他们之间结点的连结方式是部分连结,多个连结线共享权重。而多层神经网络前后两层之间结点是全连结。除了这以外,权值更新、训练、识别都是一致的。
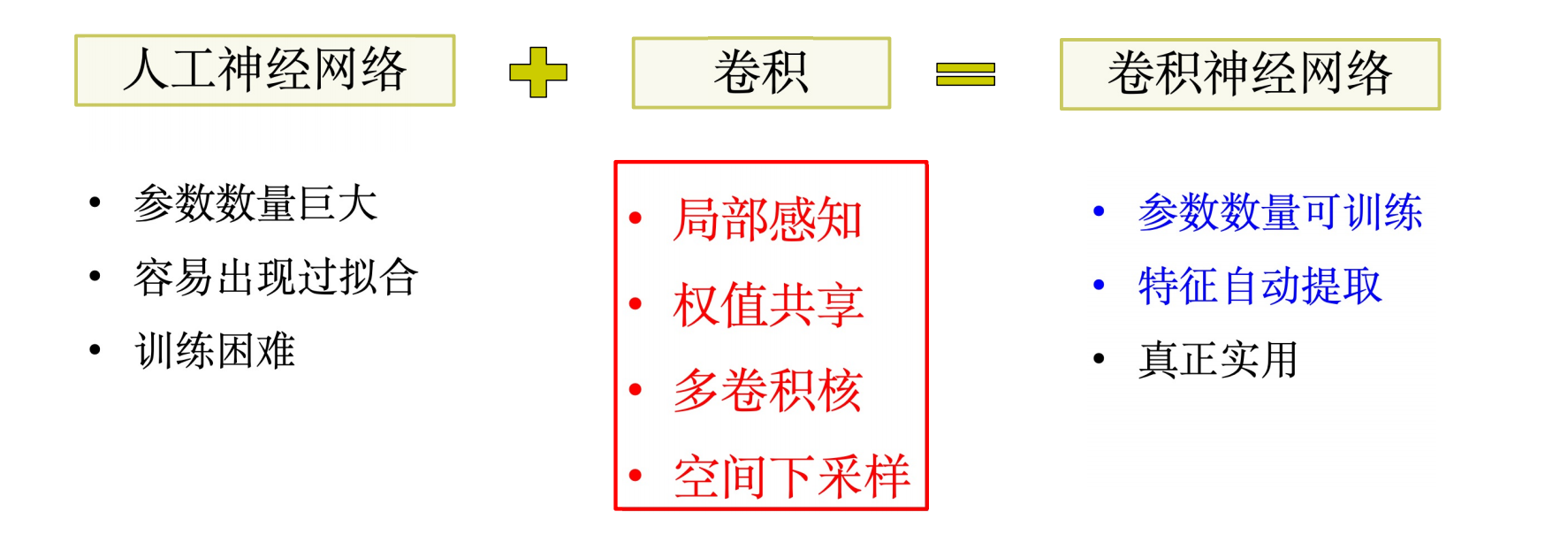
5. 卷积神经网络的核心思想
局部感知、权值共享、多卷积核、空间下采样
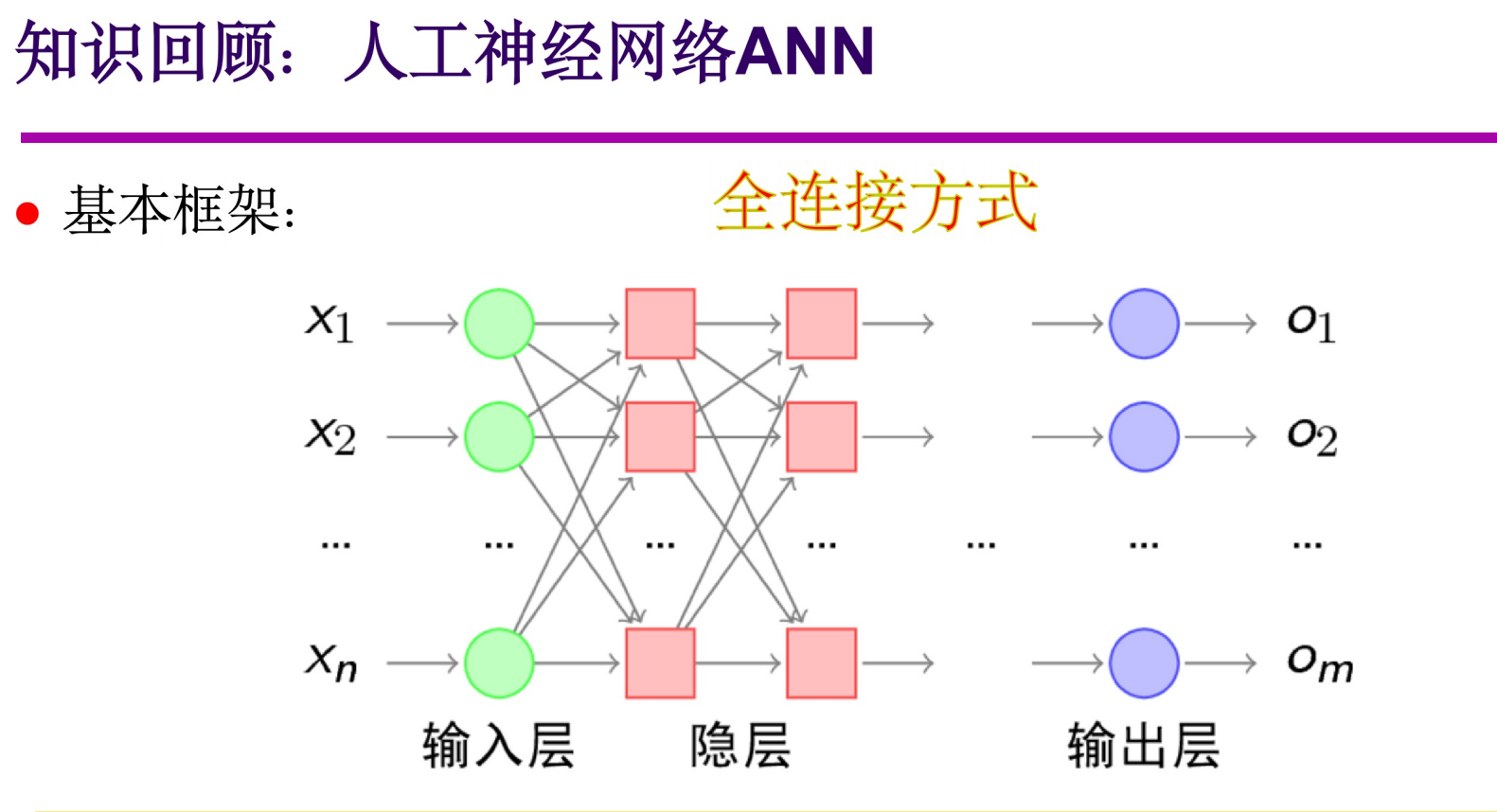
5.1 人工神经网络ANN

5.2 图像卷积运算
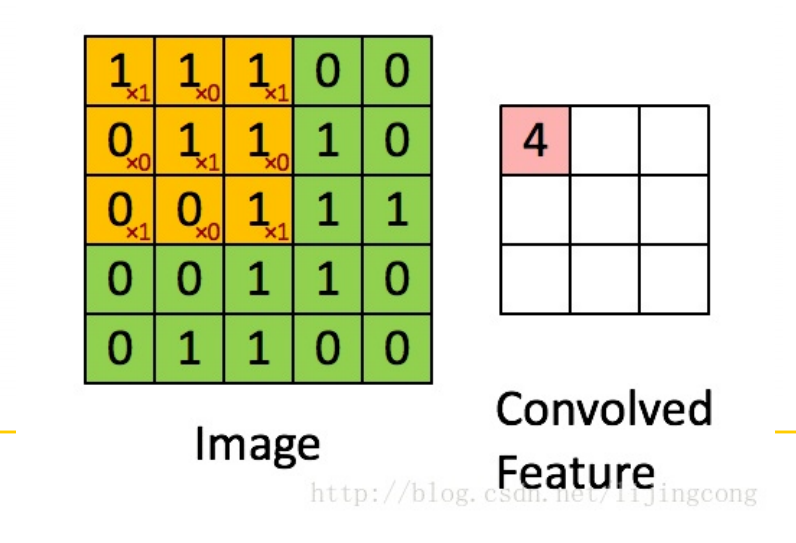
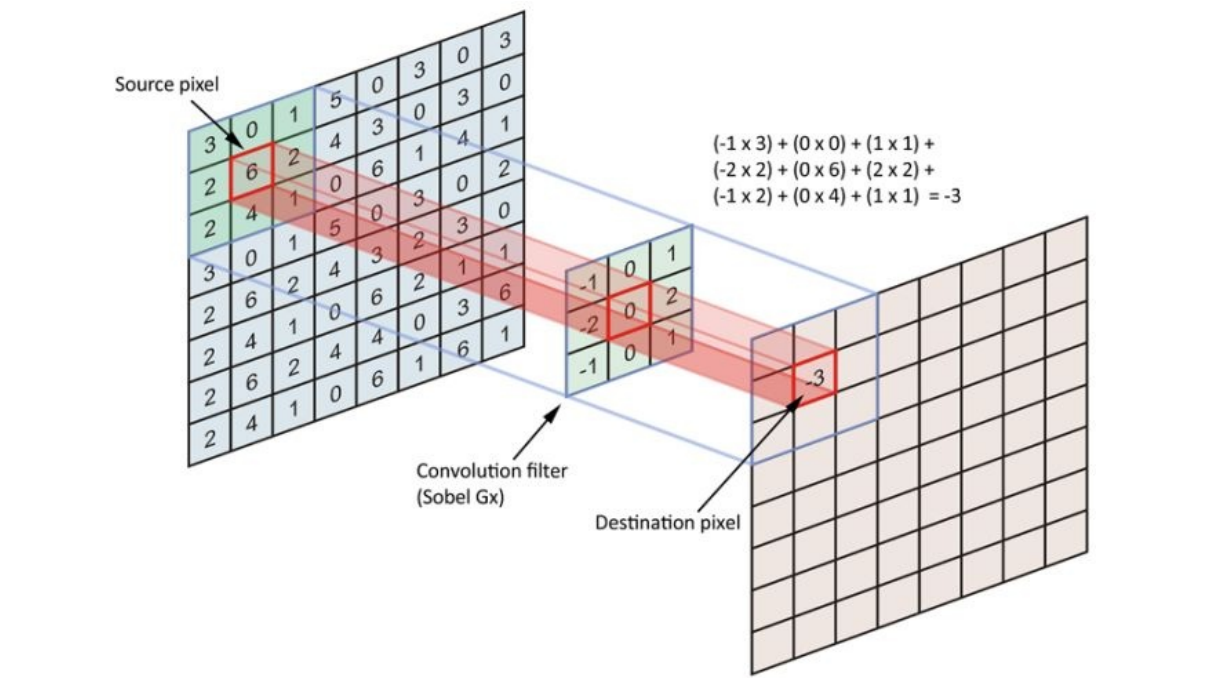
- 卷积运算:提取图像局部的统计特性。可以看作是加权求和的过程,使图像区域中的每个像素分别与卷积核的每个元素对应相乘,所有乘积之和作为区域中心像素的新值
- 卷积核:是一个权矩阵,该矩阵与图像局部区域大小相同,其行、列*一般都是奇数, 3 * 3, 5 * 5, 11 * 11……
- 边界问题
- 忽略边界像素,即处理后的图像将丢掉这些像素
- 保留原边界像素,即copy边界像素到处理后的图像

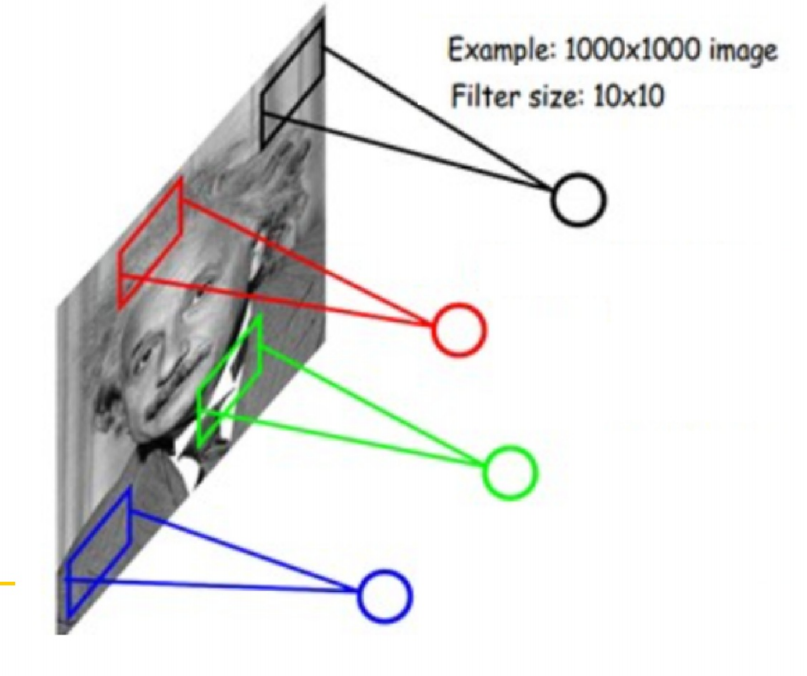
5.3 卷积神经网络核心思想一:局部感知(稀疏连接)
- 一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的,局部像素联系较为紧密,而距离较远的像素相关性则较弱。
- 受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。
- 因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知然后在更高层将局部的信息综合起来就得到了全局的信息
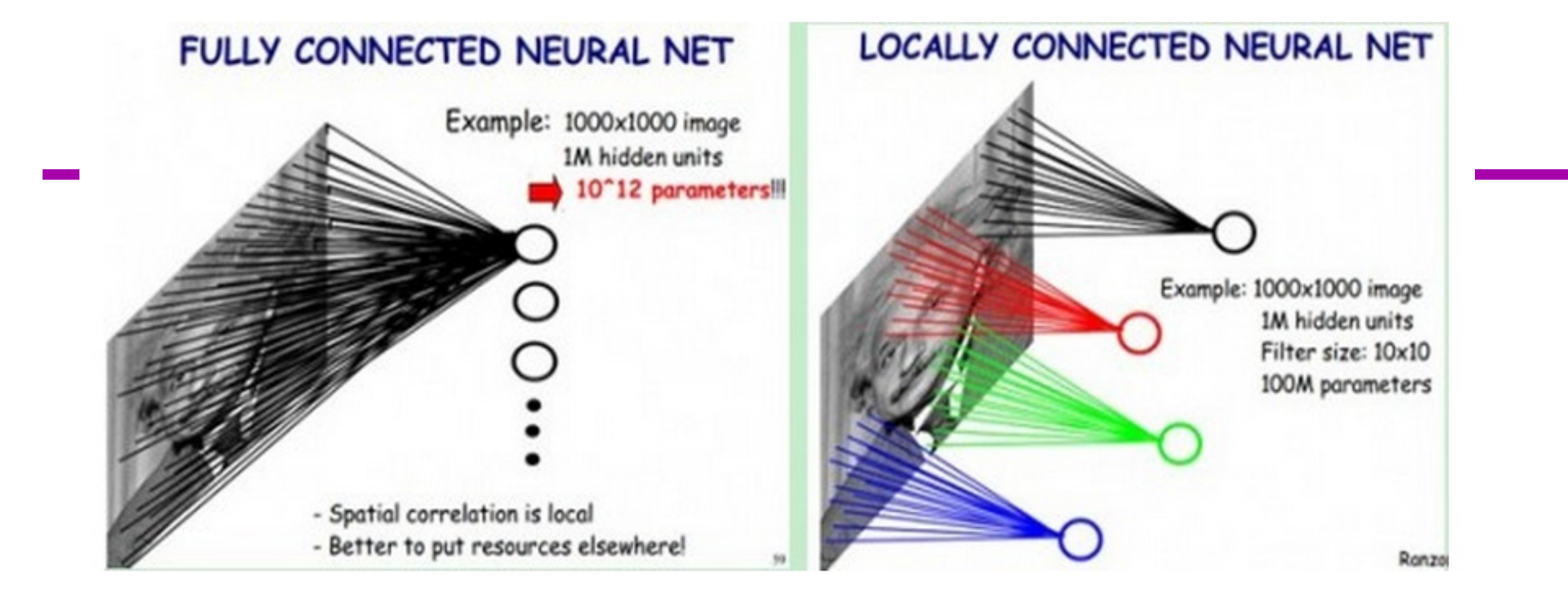
- 在上右图中,假如每个神经元只和10✖10个像素值相连,那么权值数据为1000000✖100个参数,减少为原来的万分之一
- 局部感受野:10✖10的区域,数据量依然很大,需要减少
5.4 卷积神经网络核心思想二:权值共享
-
局部感知:隐含层的每一个神经元都连接10✖10的图像区域,存在共1000000✖100个连接权值参数
-
如果所有神经元的100个参数都是相等的,那么总参数数目就为100

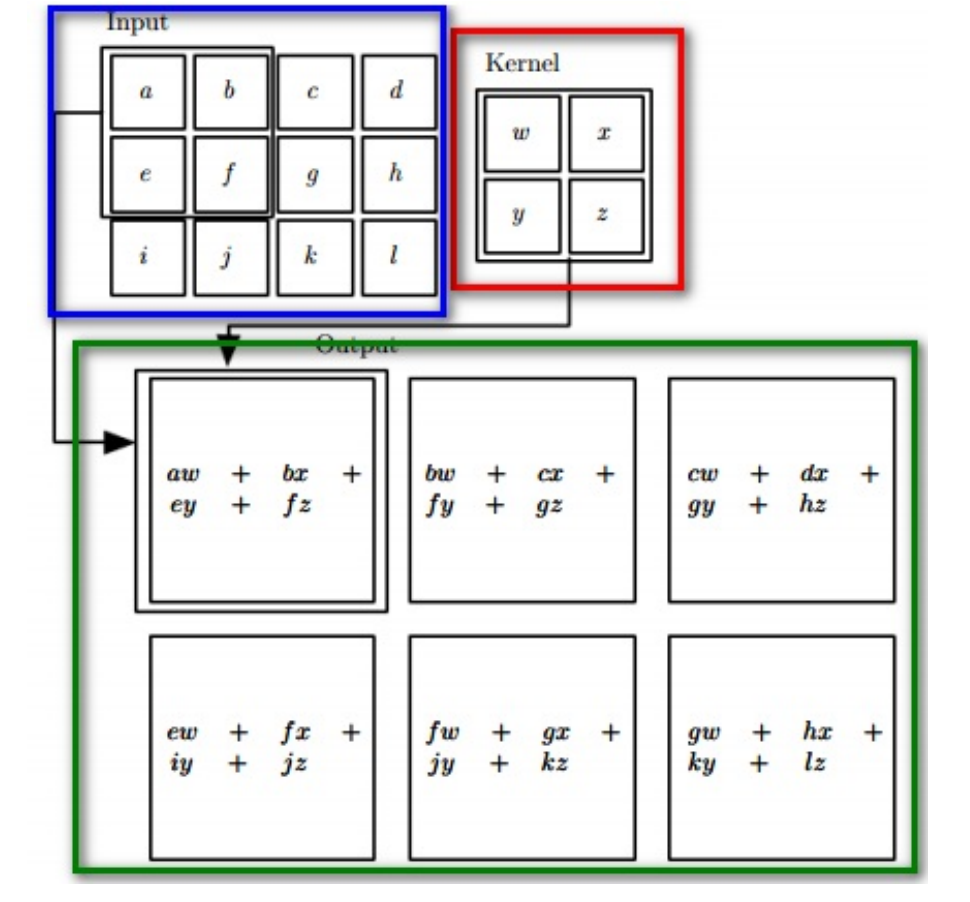
-
图像卷积:共享的100个参数可看作为一个10✖10的卷积核
可以将这100个参数(也就是卷积核)看成是提取特征的方式,该方式与位置无关
图像卷积运算:
- 无重叠(步长=10)100 ✖100 个神经元
- 有重叠(步长=k)
一种卷积核,提取一种特征,形成一个特征图Feature Map
5.5 卷积神经网络核心思想三:多卷积核
- 一个10*10的卷积核,100个参数,提取一种特征,特征提取不充分,所以设置多个卷积核以提取多种图像特征,例如:100个卷积核(Filter)可以学习100种特征,总参数数量:100 * 100 = 10000
- 卷积特征自动提取,卷积权值是基于样本集,通过CNN网络训练得到
- 卷积处理过程可以看作是使用多个卷积核分别对图像的不同局部区域作用的结果
- 卷积权值:基于样本集,通过CNN网络训练得到的
5.6 卷积神经网络核心思想四: 空间下采样
5.6.1 Pooling(池化)
-
为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计。例如,可以计算图像一个区域上的某个特定特征的平均值(或最大值)。
-
这些概要统计特征不仅具有低得多的维度(相比使用所有提取到的特征),同时还会改善结果,不容易过拟合,这种聚合操作就叫做池化(pooling)
-
利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息
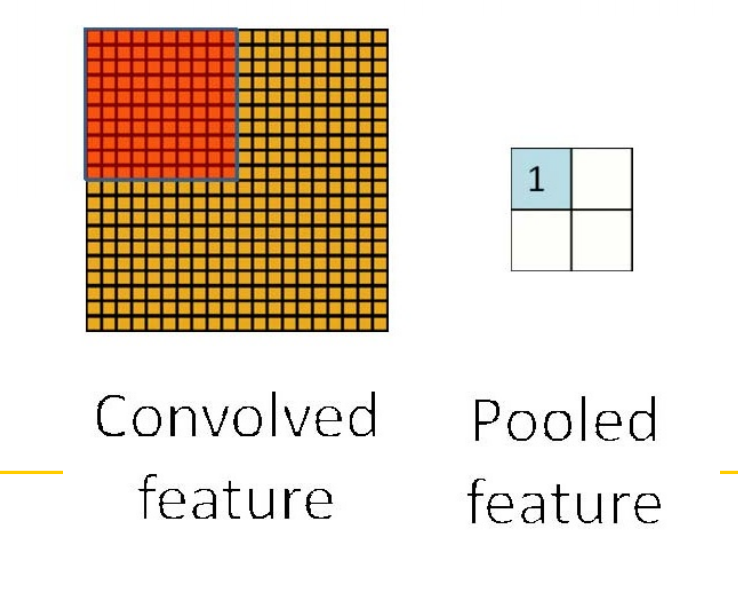
5.6.2 空间下采样
- 在CNN中,一般采用2*2大小的核

5.6.3 其他池化策略
- Mean pooling(均值采样)、Max pooling(最大值采样)、Overlapping(重叠采样)、L2 pooling(均方采样)、Local Contrast Normalization(归一化采样)、Stochasticpooling(随即采样)、Def-pooling(形变约束采样)

6. 确定隐层神经元的个数
隐层神经元的个数和输入图像大小、卷积核大小及种类、卷积步长有关
6.1 单卷积核
- 给定一种卷积核,就会得到一个feature map
- 一种卷积核需要多个神经元,一个神经元对应一个局部区域
- 神经元个数 = feature map大小
- 计算方式:下取整((图像边长-卷积边长)/步长)+ 1
例如:输入图像为32*32,卷积核大小为5 * 5
如步长为1,(32-5)/1 + 1 = 28,则输出的feature map为28 * 28
如步长为3,(32-5)/3 + 1 = 10, 则输出的feature map为10 * 10
6.2 多卷积核
- 给定n种卷积核,可得到n个feature map
- 计算每个隐层的神经元个数:
$ N = \sum_{i=1}^{k}n_{i}
其中,k为卷积核种类,n_{i}为每种卷积核对应的神经元个数。如,一个卷积核对应的神经元个数为10000;如果是30种相同大小的卷积核,则神经元个数30*10000 = 300000 $ - 一般情况下,不同隐层可以不同,同一隐层的卷积核大小相同,步长相同 \(即n_{1} = n_{2} = ... = n_{k}\)
7. 确定网络中隐层参数(权值)个数
-
与隐层神经元个数无关,只和卷积核大小及其种类多少有关
-
比如卷积核大小为10*10,卷积核种类为30,则总连接参数数量:100 * 30 = 3000
-
需要注意的是,这里没有考虑每个神经元的偏置部分。如考虑,每个卷积核对应隐层参数个数+1.即(100 + 1)* 30 = 3030,这个参数也是同一种卷积核共享的
-
可见,图像越大,神经元个数与隐层参数个数的差别越大

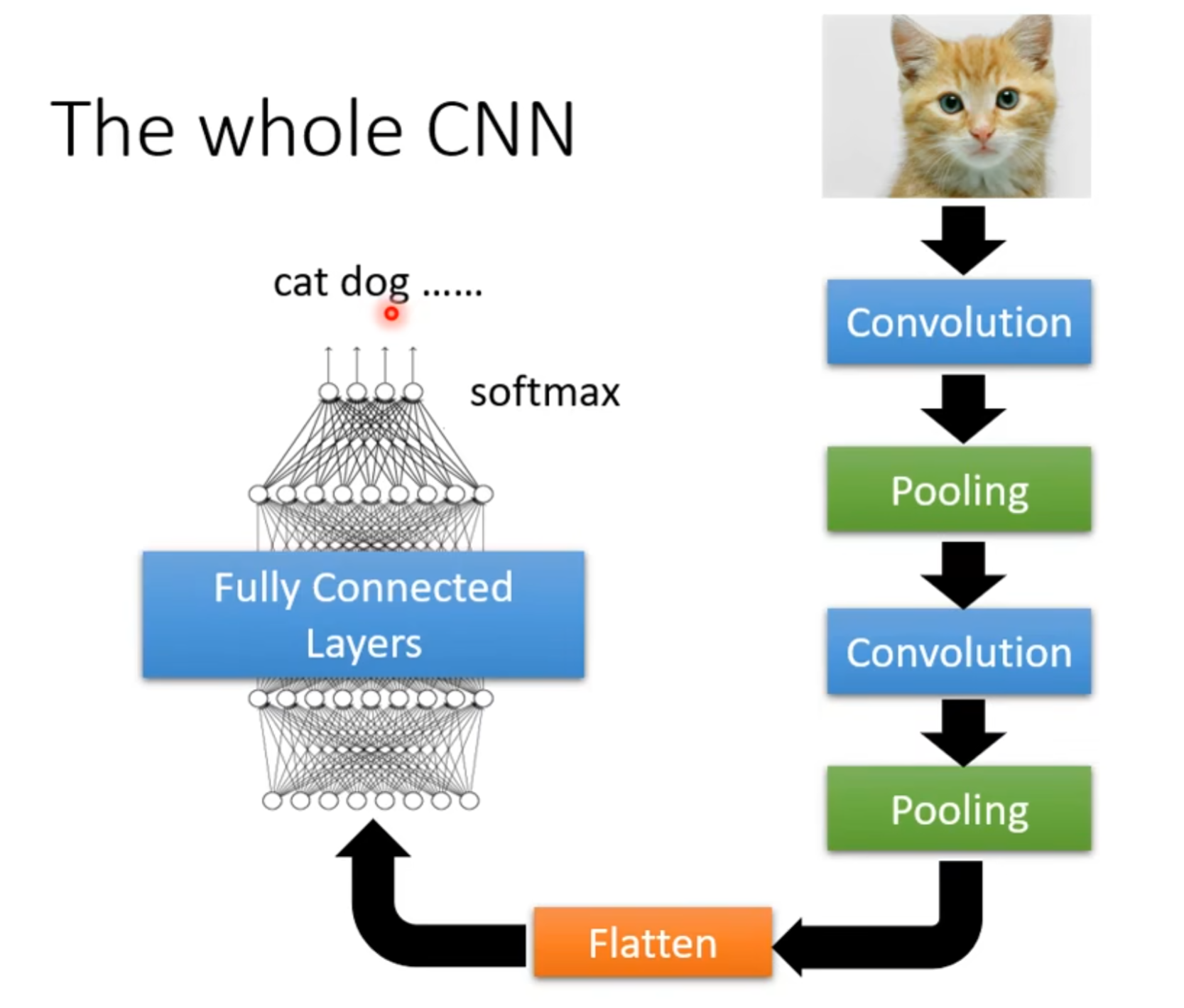
8. 卷积神经网络的结构
8.1 卷积神经网络的结构
- 在一个卷积网络中常包含三层:卷积层、池化层、全连接层

8.2 卷积层
8.2.1 Padding
- 进行padding操作的原因是:(1)每次卷积之后,图像变小(2)图像边缘信息发挥作用小
- 为了解决上述问题,可以在卷积操作之前填充这幅图像。
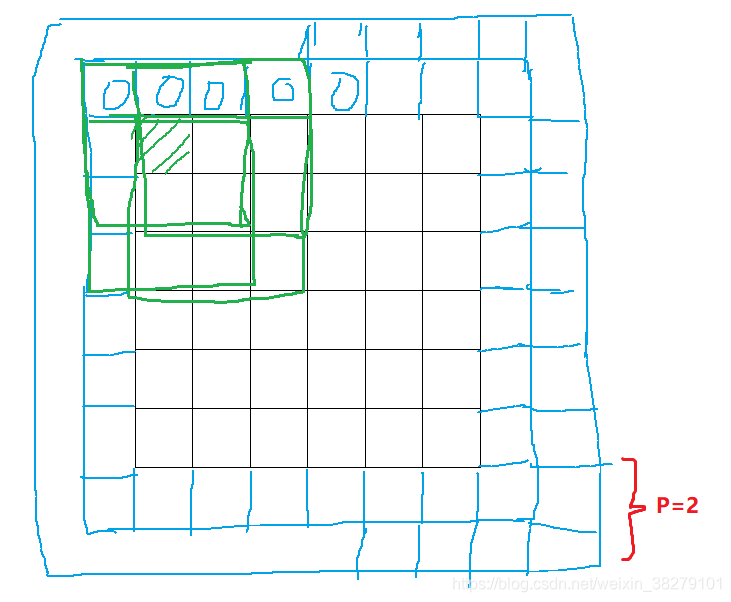
padding的取值
- 至于选择填充多少像素,通常有两个选择,分别叫做Valid卷积和Same卷积。
- Valid卷积
- Valid卷积意味着不填充,这样的话,如果你有一个n × n 的图像,用一个f × f 的过滤器卷积,它将会给你一个( n − f + 1 ) × ( n − f + 1 ) 维的输出。例如,有一个6×6的图像,通过一个3×3的过滤器,得到一个4×4的输出。
- Same卷积
- 填充后,输出大小和输入大小是一样的。根据这个公式n − f + 1,当填充p个像素点,n就变成了n + 2p,最后公式变为n + 2 p − f + 1。因此如果有一个n × n 的图像,用p个像素填充边缘,输出的大小就是这样的( n + 2 p − f + 1 ) × ( n + 2 p − f + 1 )。
- 如果让n + 2 p − f + 1 = n的话,使得输出和输入大小相等,p = ( f − 1 ) / 2 。所以当f是一个奇数的时候,只要选择相应的填充尺寸,就能确保得到和输入相同尺寸的输出。另一个例子,当你的过滤器是5×5,如果f = 5,然后代入那个式子,就会发现需要2层填充使得输出和输入一样大,这是过滤器5×5的情况。
- 以上是针对stride=1情况下,通用公式


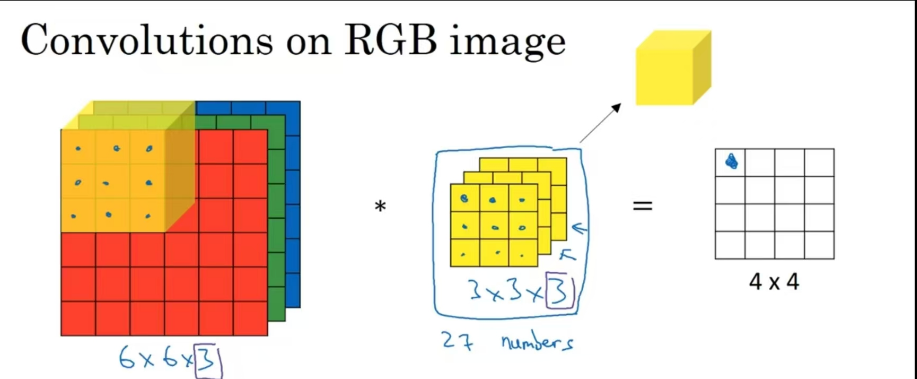
8.2.2 三维卷积
- 卷积操作通道数应该等于输入通道数
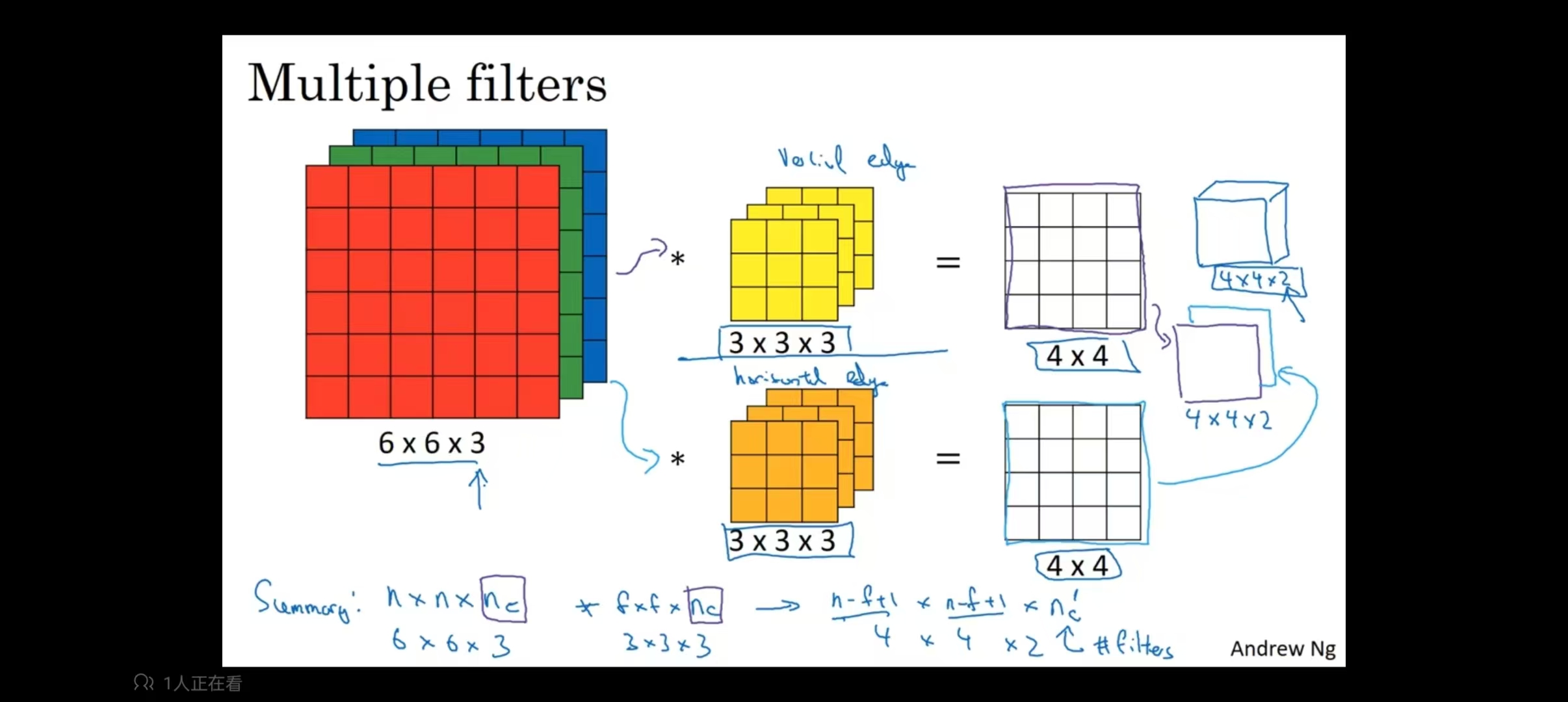
- 要是输出通道数不为一,应当增加卷积核种类,例如下图使用两种卷积核,生成4 * 4 * 2图像
8.2.3 1 * 1 的卷积
- 对构件Inception很有帮助
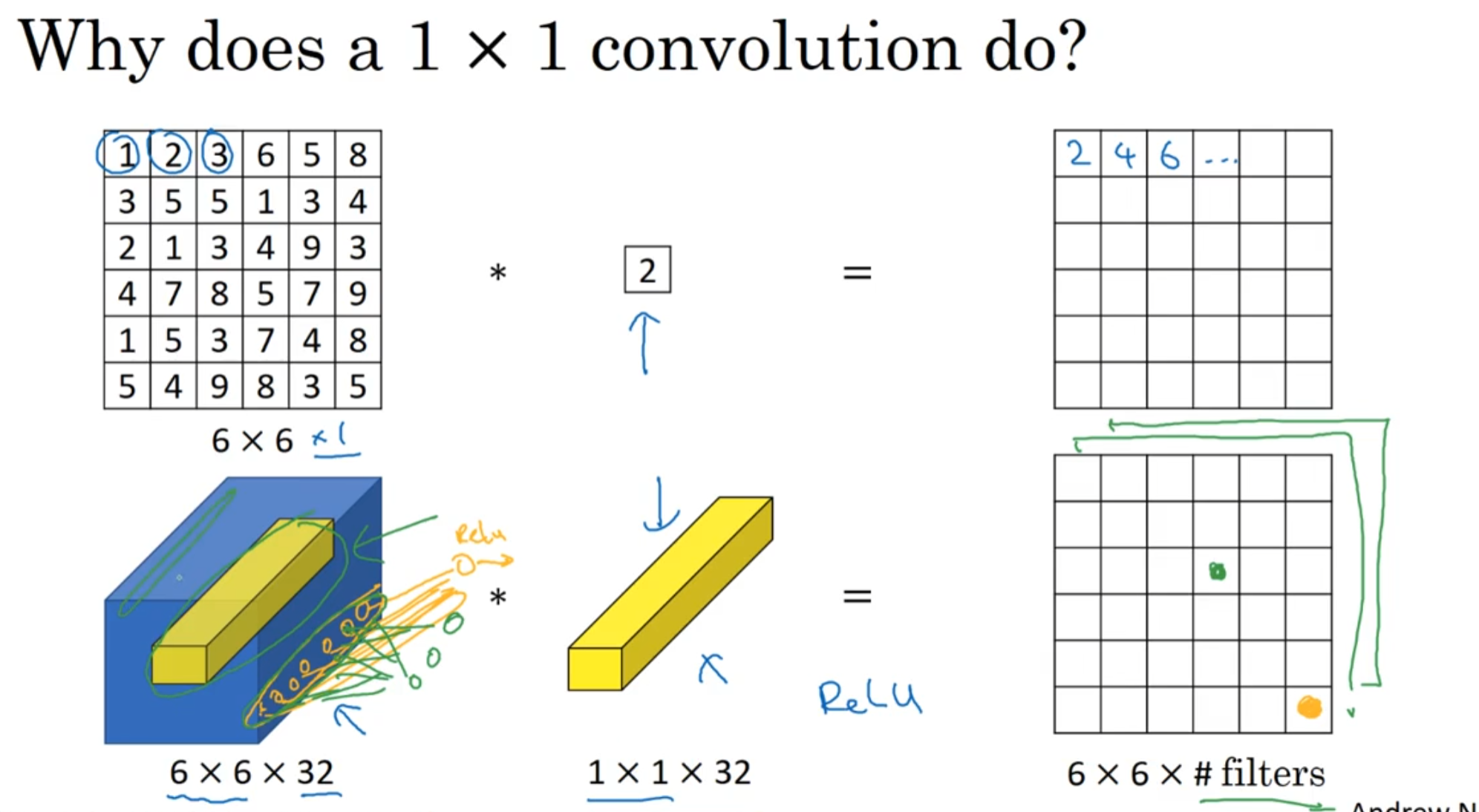
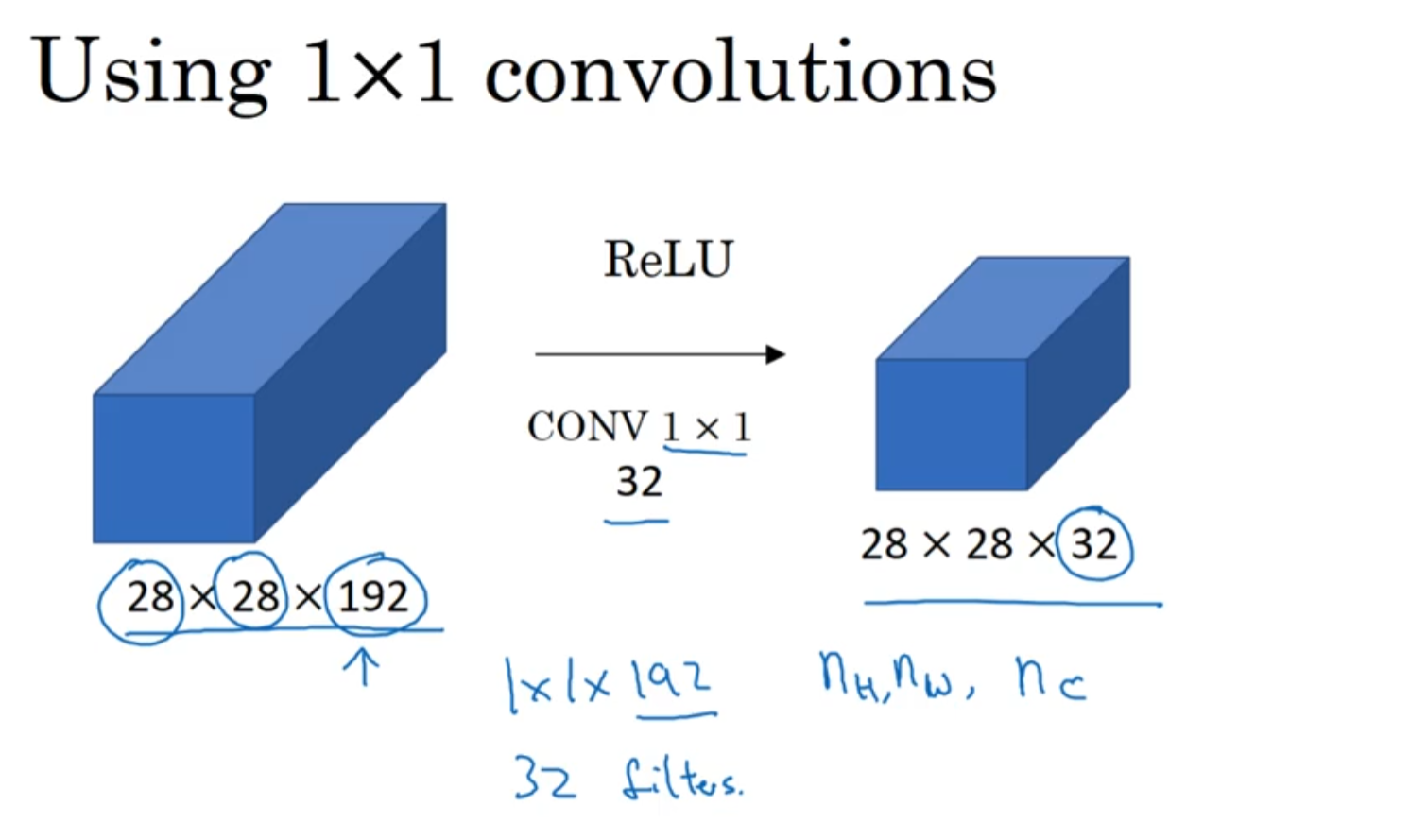
- 1 * 1 卷积作用
- 实现信息的跨通道交互与整合。考虑到卷积运算的输入输出都是3个维度(宽、高、多通道),所以1×1卷积实际上就是对每个像素点,在不同的通道上进行线性组合,从而整合不同通道的信息。
- 对卷积核通道数进行降维和升维,减少参数量。经过1×1卷积后的输出保留了输入数据的原有平面结构,通过调控通道数,从而完成升维或降维的作用。
- 利用1×1卷积后的非线性激活函数,在保持特征图尺寸不变的前提下,大幅增加非线性
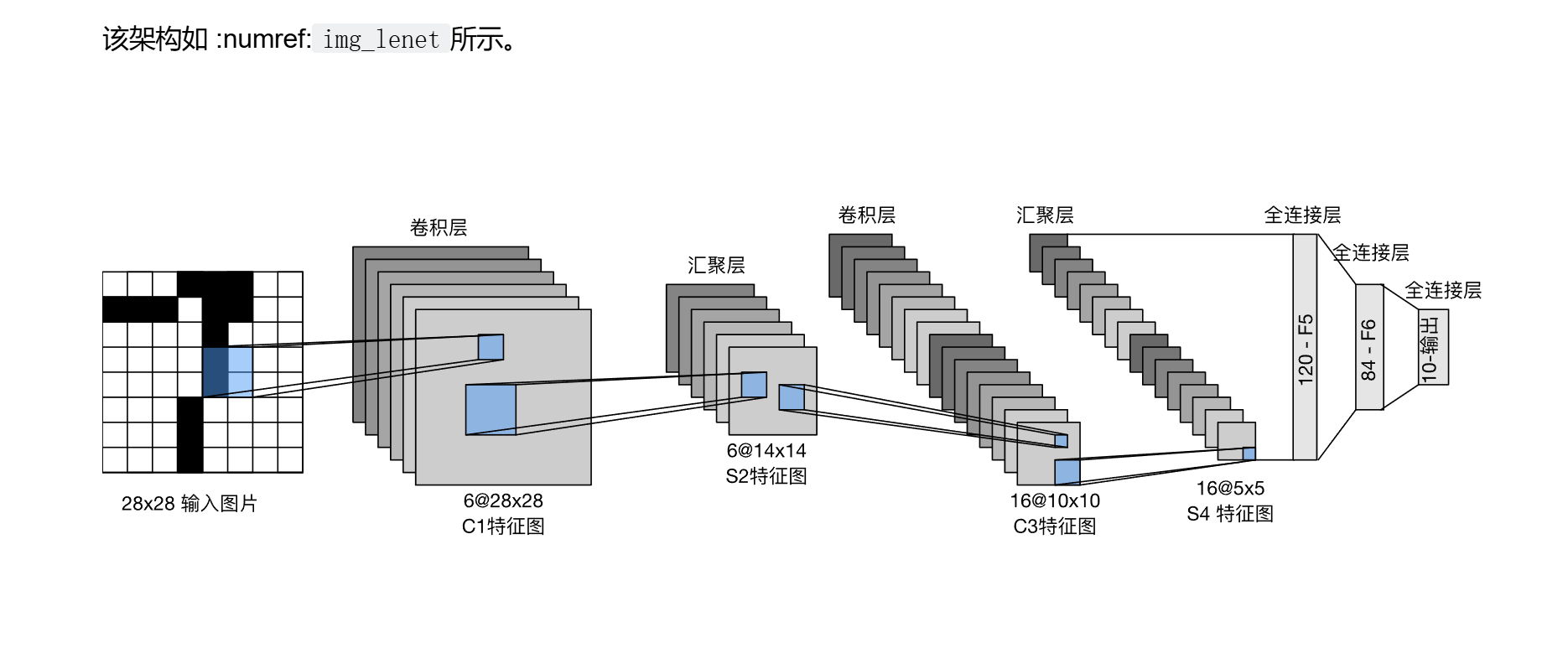
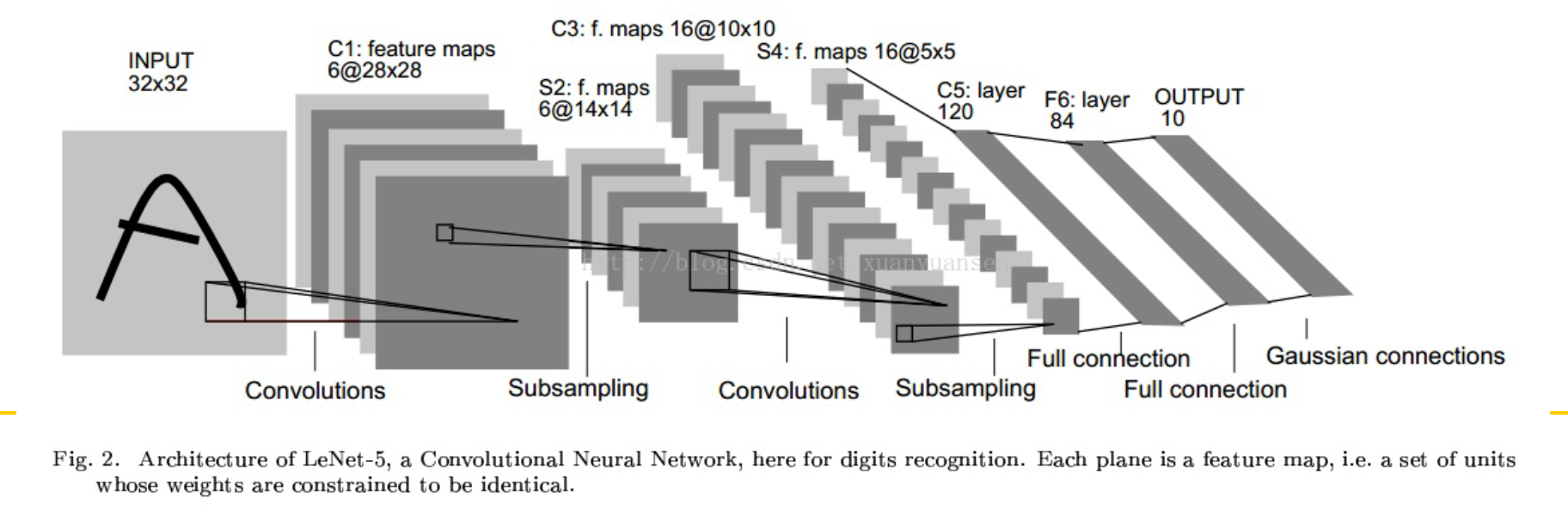
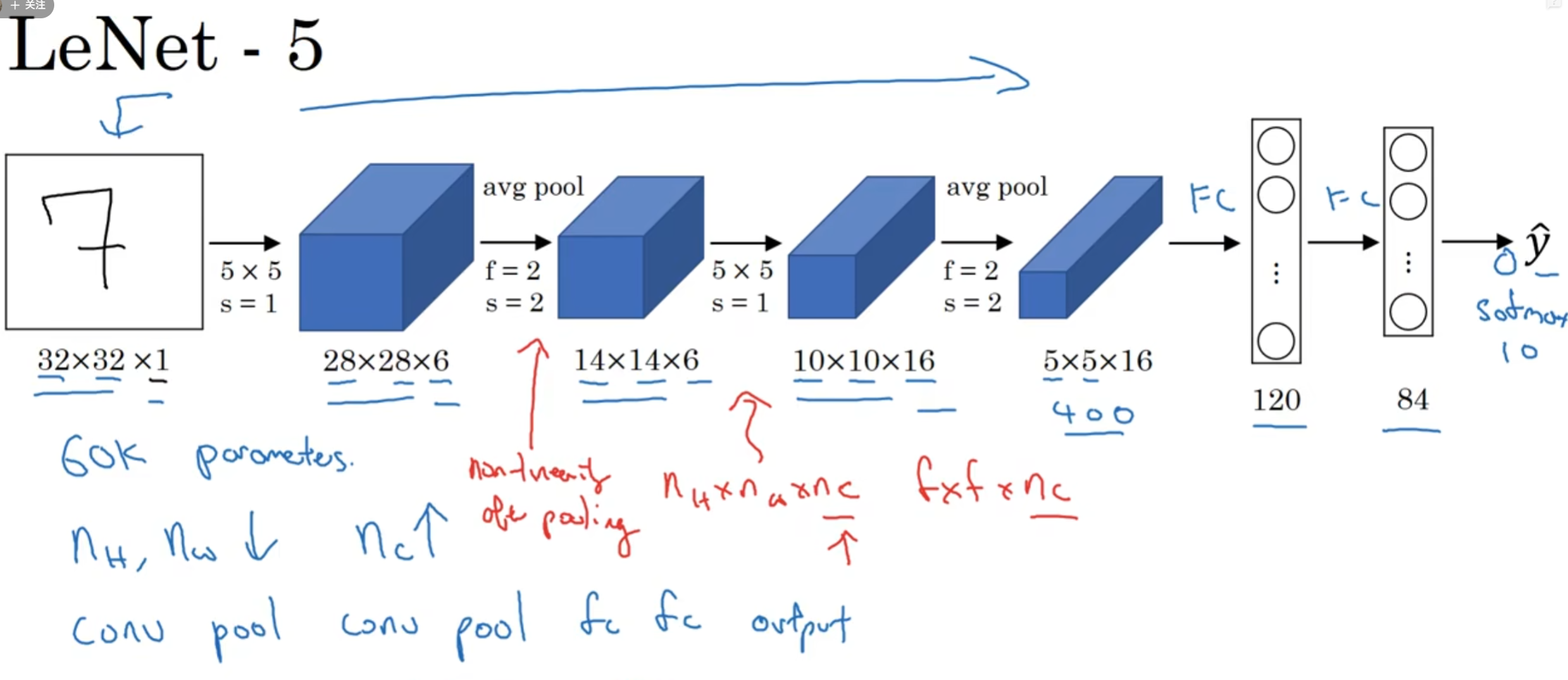
9. 实例:卷积神经网络实现手写数字识别:Lenet-5
-
Lenet-5共有7层,不包含输入,每层都包含可训练参数(连接权值)。输入图像大小为32*32
-
每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每个Feature Map有多个神经元(神经元个数=Feature Map大小)
9.1 C1 卷积层
- 这一层的输入就是原始图像,输入层接受图片的输入大小为32 * 32 * 1。
- 卷积层的核(过滤器)尺寸为5 * 5,深度为6,不使用0进行填充,步长为1。通过计算公式(下取整(32-5)/1 + 1)可以求出输出的尺寸为28 * 28 * 6,卷积层的深度决定了输出尺寸的深度。
- 卷积层总共的参数有(5 * 5 + 1) * 6 = 156 个参数,加的6为卷积后的偏置项参数。
- 本层所拥有的节点(神经元)有28 * 28 * 6 = 4704个节点
- 而本层的每一个节点都是经过一个5 * 5的卷积和一个偏置项计算所得到的,5 * 5 + 1=26,所以本层卷积层一共有4704*26 = 122304个连接。
9.2 S2池化层
- 本层的输入是C1层的输出,它接受一个28 * 28 * 6的节点矩阵。
- 在卷积神经网络中,常用的池化层有最大池化和平均池化,所使用的核大小为2 * 2,长和宽的步长都是2,意味着输入矩阵的每四个相邻的元素经过S2之后只会有一个输出元素,所以本层的输出矩阵大小为14 * 14 * 6,池化层不会改变输入矩阵的深度。
- 在LeNet5网络中,池化层是首先对C1层输出中的2 * 2相邻的区域内,先求和乘以一个可训练参数然后再加上一个偏置项,最后将结果做一次映射通过sigmoid函数,所以就将输出的行和列变成了输入的一半,一共有 6 * 2 = 12个参数。与C1层一共有(4+1) * 6 * 14 * 14=5880个连接。

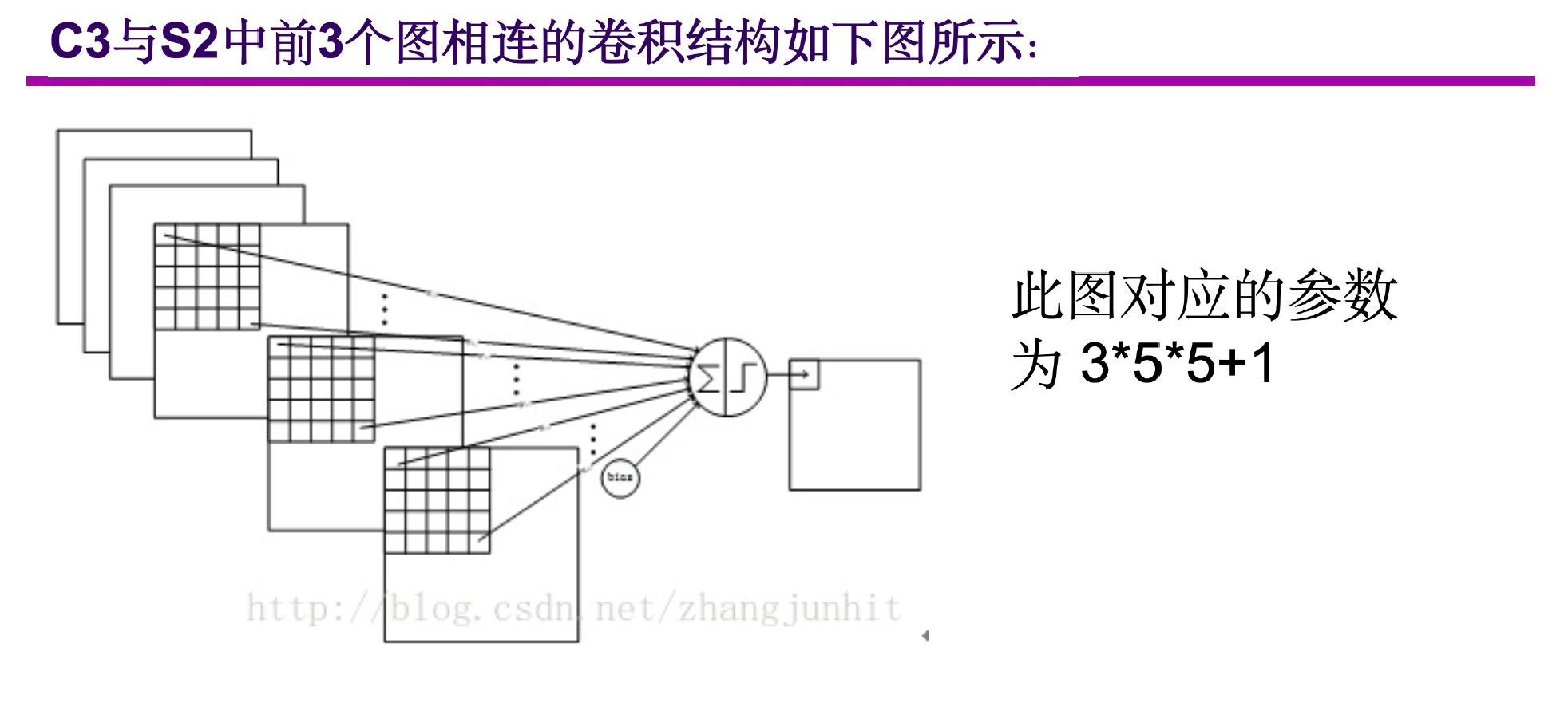
9.3 C3卷积层
-
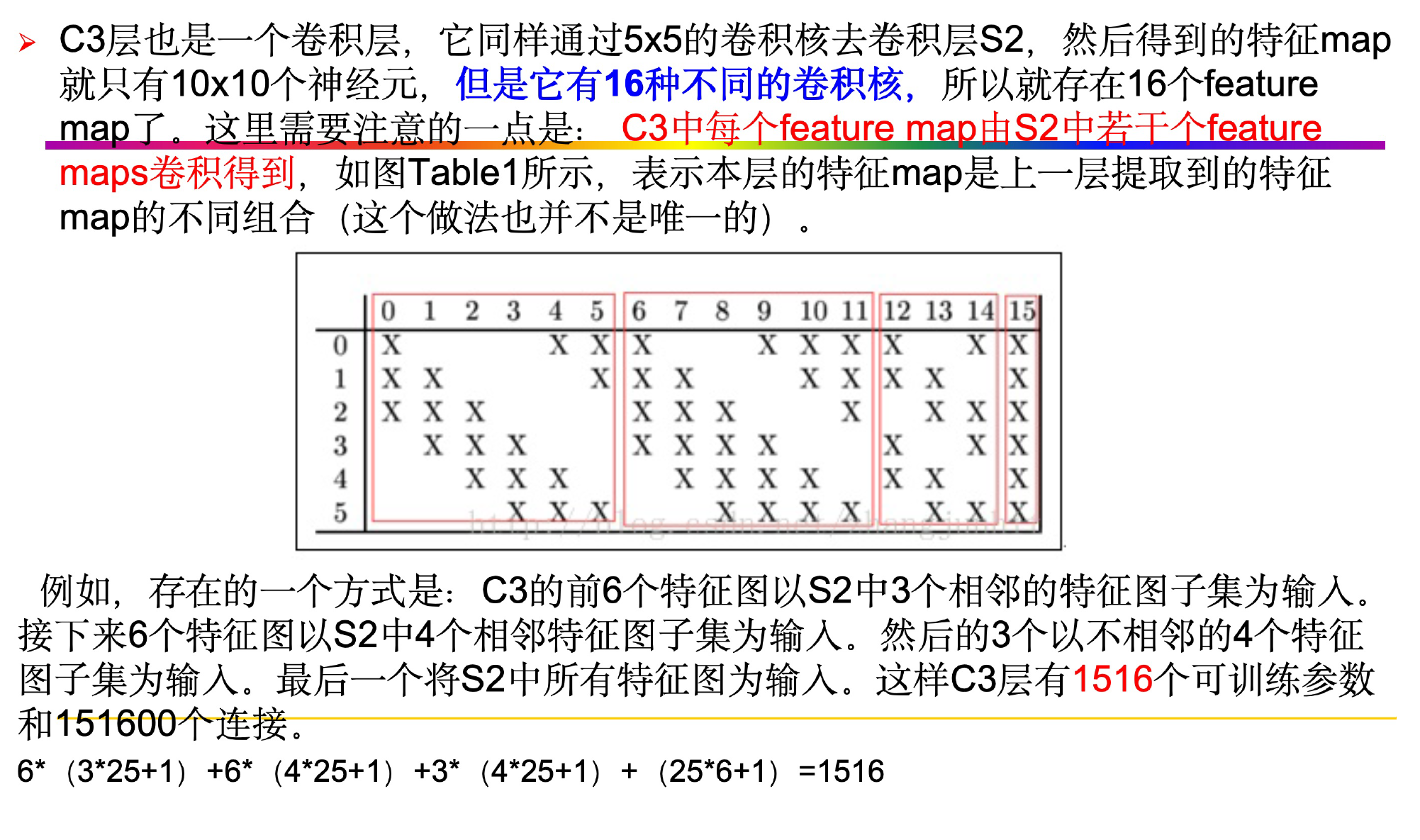
这一层的输入是一个14 * 14 * 6的矩阵,C3层一共有16个卷积核,每一个卷积核的大小为5 * 5,输出是10 * 10 * 16,下面的表格展示了S2层与C3层的连接关系。
-
从上表中可以发现,行号表示C3层中的16个卷积核,列号表示的是S2层中的6个卷积核的输出。C3层中的前6(0-5)个卷积与S2层中的3个卷积核输出相连,C3层中的中间的3个(6-8)与S2层中连续的4个卷积核的输出相连,后面6个(9-14)与S2层中不连续的4个卷积核的输出相连
-
C3层中的最后一个卷积与S2层中所有输出相连。
-
为什么S2不和C3的每一个卷积核相连呢?
- 不使用全连接能够保证有连接的数量保持在一个合理的界限范围内可以减少参数
- 通过这种方式可以打破网络的对称性,不同的卷积核通过输入可以得到不同的特征。
-
从表中的C3层与S2层的连接关系可以求出C3的参数一共有:6*(5 * 5 * 3 + 1)+9 *(5 * 5 * 4 + 1)+ 1 *( 5 * 5 * 6+1)=1516个参数,与S2层的连接一共有,10 * 10 * 1516 = 151600个连接。
9.4 S4池化层
- S4层的池化方式与S2层相同,输入是10 * 10 * 16,输出是 5 * 5 * 16。所以,S4层一共有16 * 2 = 32个参数,与S3层一共有(4+1)* 5 * 5 * 16=2000个连接。
9.5 C5卷积层
- C5层由120个卷积核组成,一个卷积与S4中每一个feature map(5 * 5 * 16)相连,所以每一个C5的卷积核都会输出一个1 * 1,所以在S4与C5之间是属于全连接。C5是一个卷积层而不是一个全连接层,如果这个LeNet5的输入变的更大了而其它的保持不变,那么这个输出将要大于1 * 1。C5层与S4一共有120*(5 * 5 * 16 + 1)=48120个连接。

9.6 F6全连接层
- F6层包含了84个节点,一共包含了84*(120+1)=10164个参数。F6层通过将输入向量与权重向量求点积,然后在加上偏置项。这个加权和表示为a(i),对于第i个单元,然后通过一个sigmoid压缩函数,来产生一个x(i),x(i)=f(a(i))。这个压缩函数是双曲正切函数(tanh),f(a)=Atanh(Sa)。A是函数的振幅决定了函数最大最小值,决定了曲线在原点的斜率,这个tanh函数是奇函数(关于原点对称),下图是tanh的函数图像,y的范围在[-1,1],所以f(a)的函数取值范围就在[-A,A]。

9.7 输出层
- 输出层是由欧式径向基函数(RBF)组成。每一个输出对应一个RBF函数,每一个RBF函数都有84维的输入向量。每一个RBF函数都会有一个输出,最后输出层会输出一个10维的向量。

10. ALEXNET
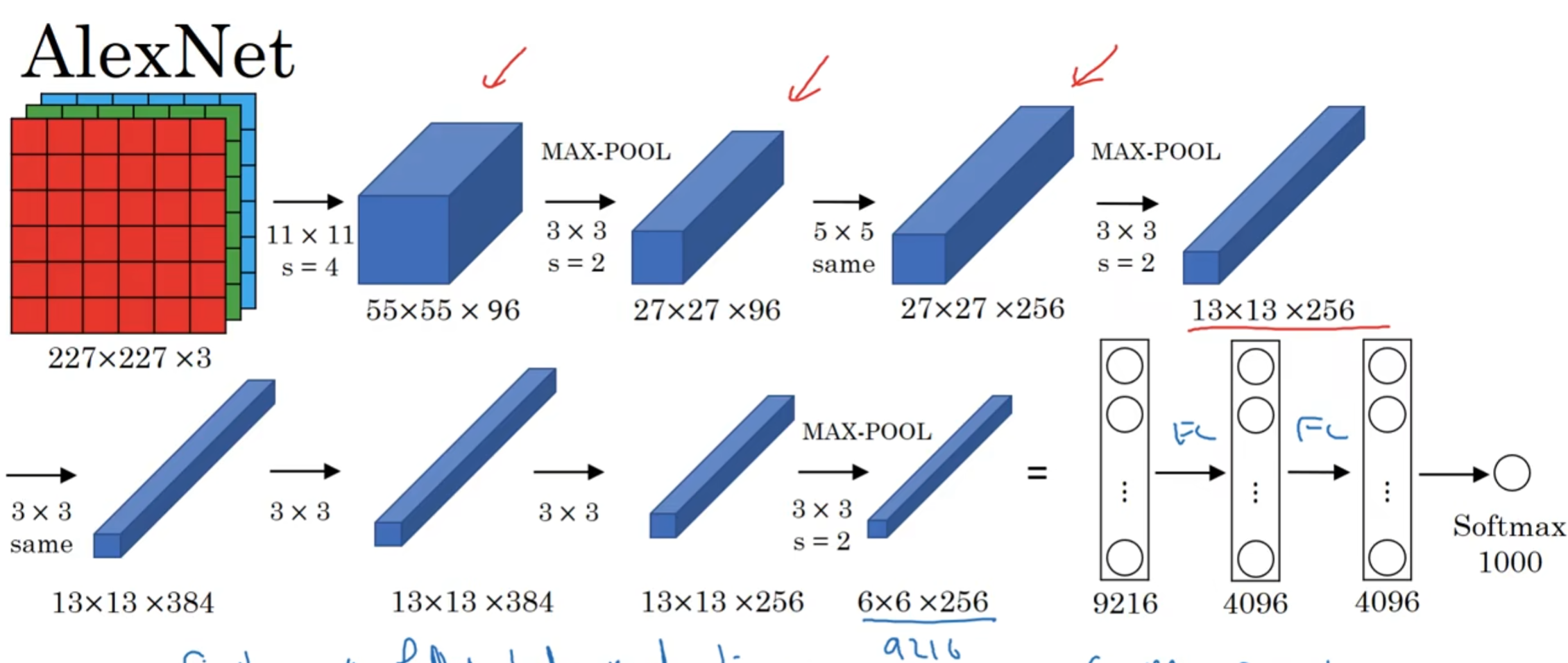
10.1 AlexNet基本结构
- AlexNet整体的网络结构包括:1个输入层(input layer)、5个卷积层(C1、C2、C3、C4、C5)、2个全连接层(FC6、FC7)和1个输出层(output layer)
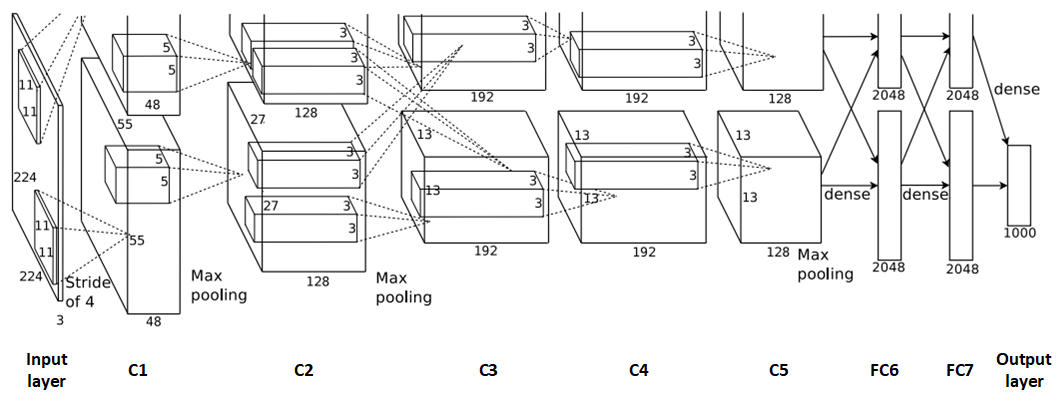
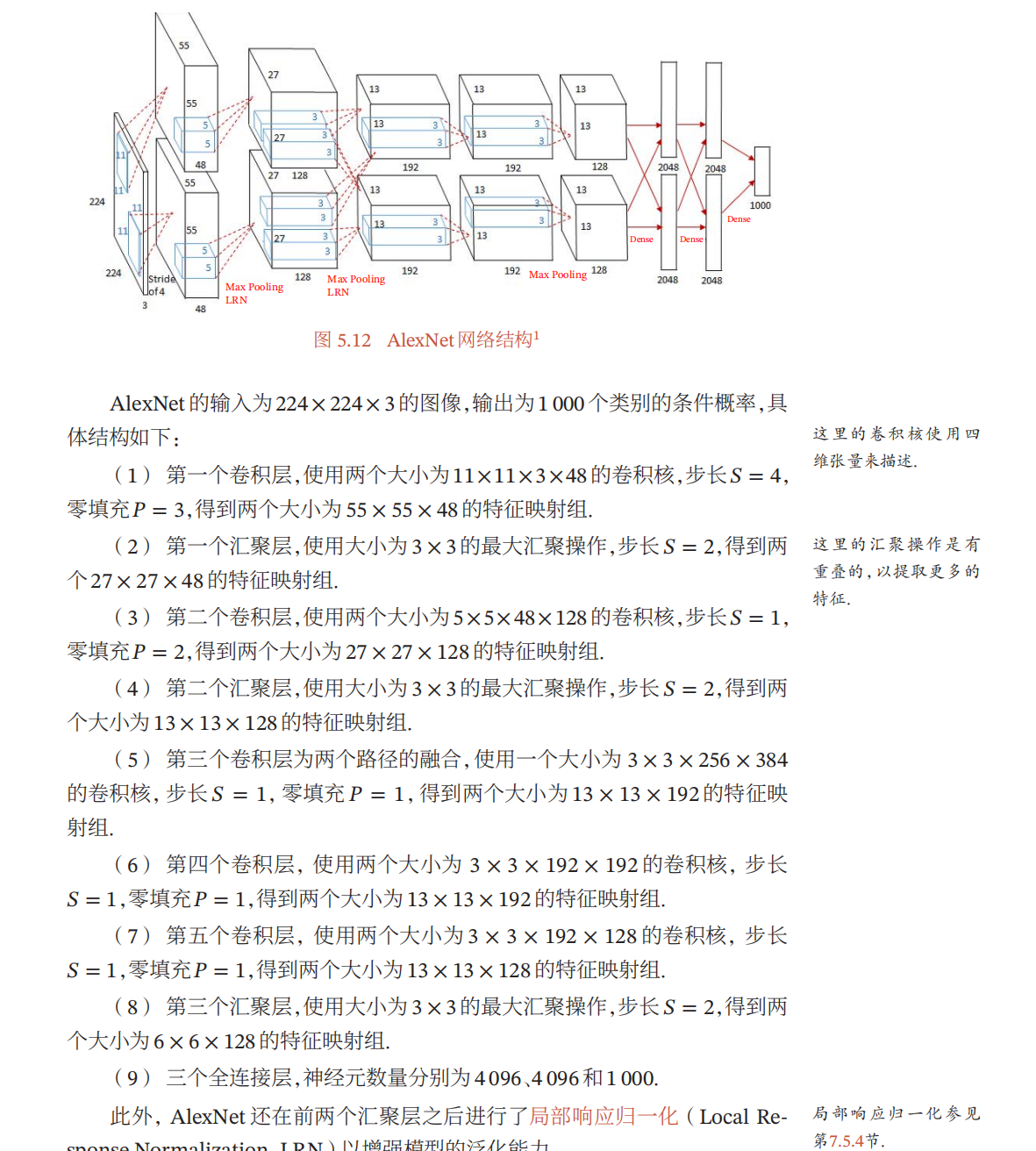
10.2 Alex优势
- 算法的改进,包括网络变深、数据增强、ReLU、局部响应归一化、Dropout等
- relu函数的导数在正数部分是恒等于1的,因此在深层网络中使用relu激活函数就不会导致梯度消失和爆炸的问题
- 单侧抑制功能:使得神经网络中的神经元也具有了稀疏激活性。ReLU实现稀疏
后的模型能够更好地挖掘相关特征,拟合训练数据 - 左边全部关了很容易导致某些隐藏节点永不使用(dead ReLU):Leak ReLu, elu,
pReLU、random ReLU等改进 - 输出不是以0为中心的,很容易改变数据的分布:Batch Normalization
11.VGG-16
-
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的
较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片
的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层
可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)
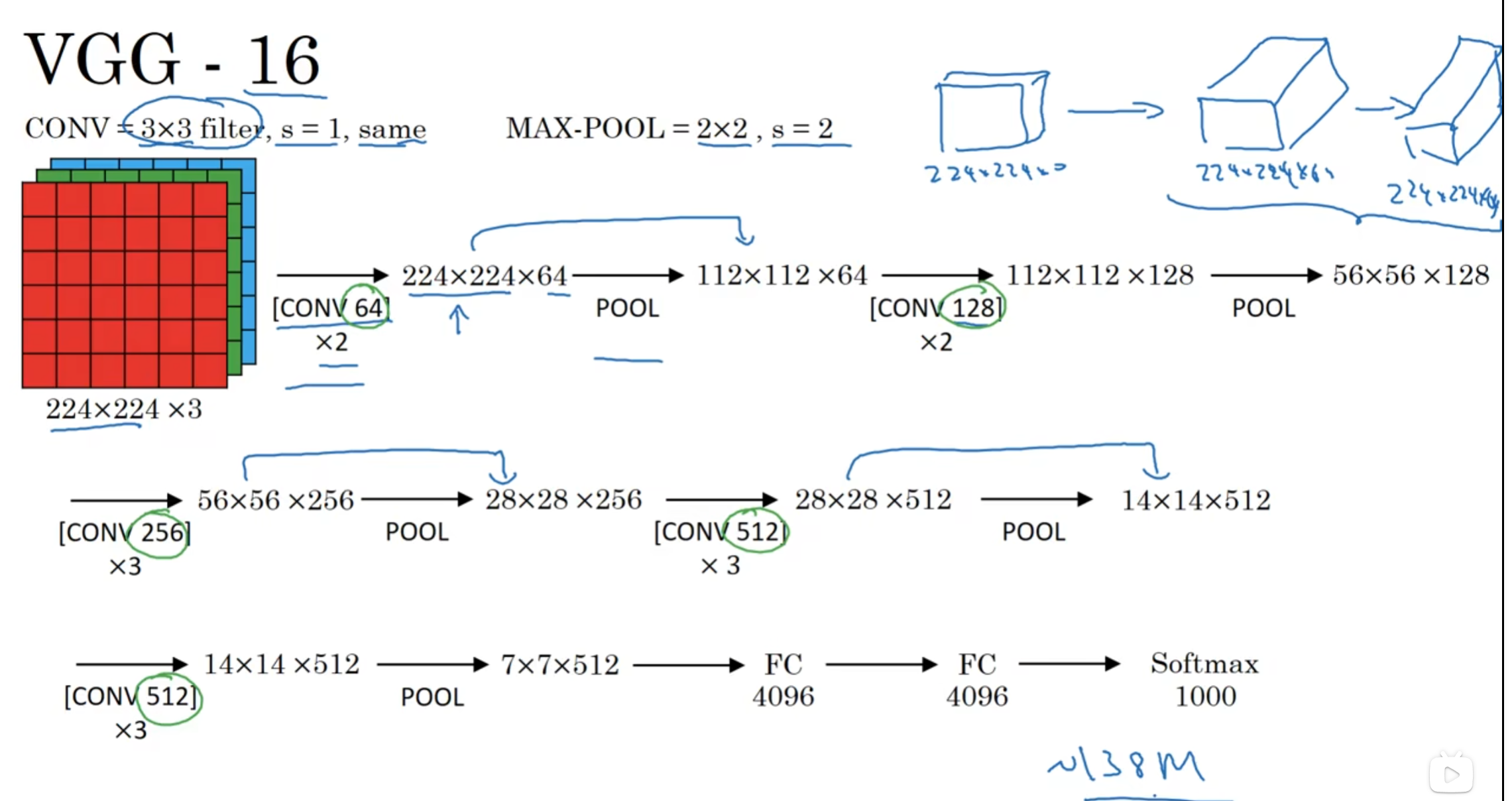

优点
- VGGNet的结构简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)
- 几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好
- 验证了通过不断加深网络结构可以提升性能
- 去掉了LRN层,作用不明显
缺点
- VGG耗费更多计算资源,并且使用了更多的参数,其中绝大多数的参数都是来自于第一个全连接层
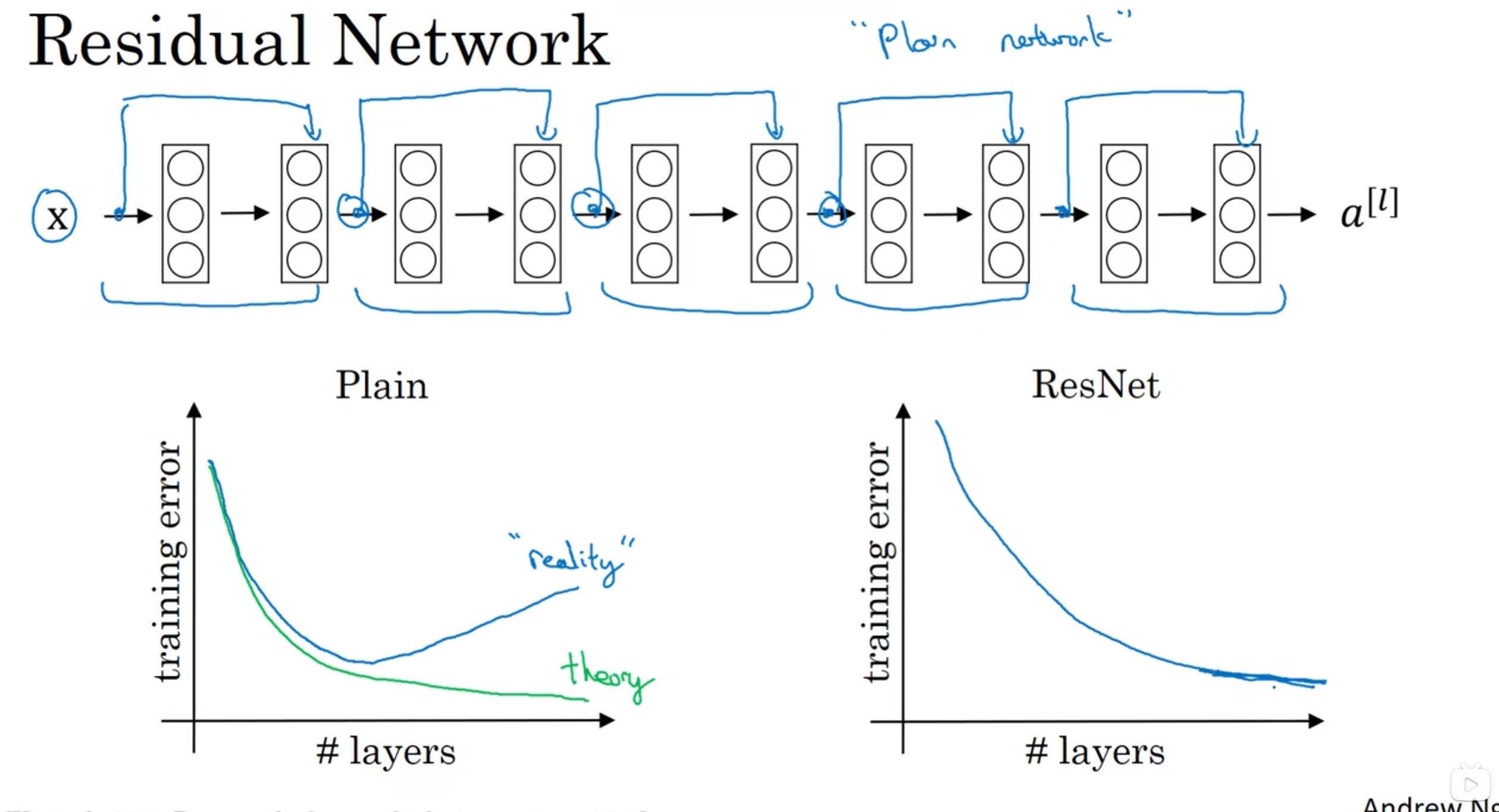
12. Resnet
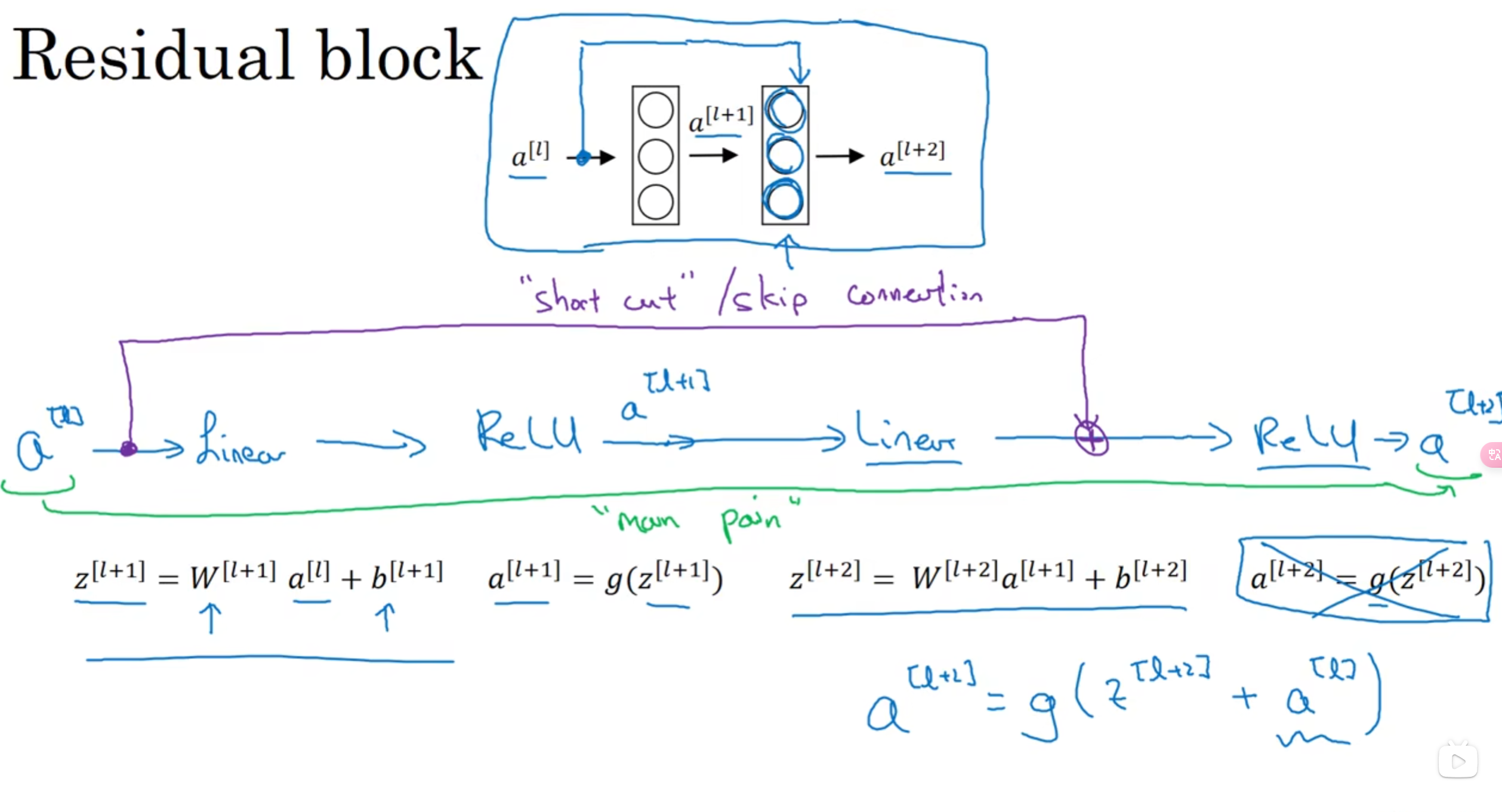
- 解决梯度消失和梯度爆炸很有用
13. Google Inception
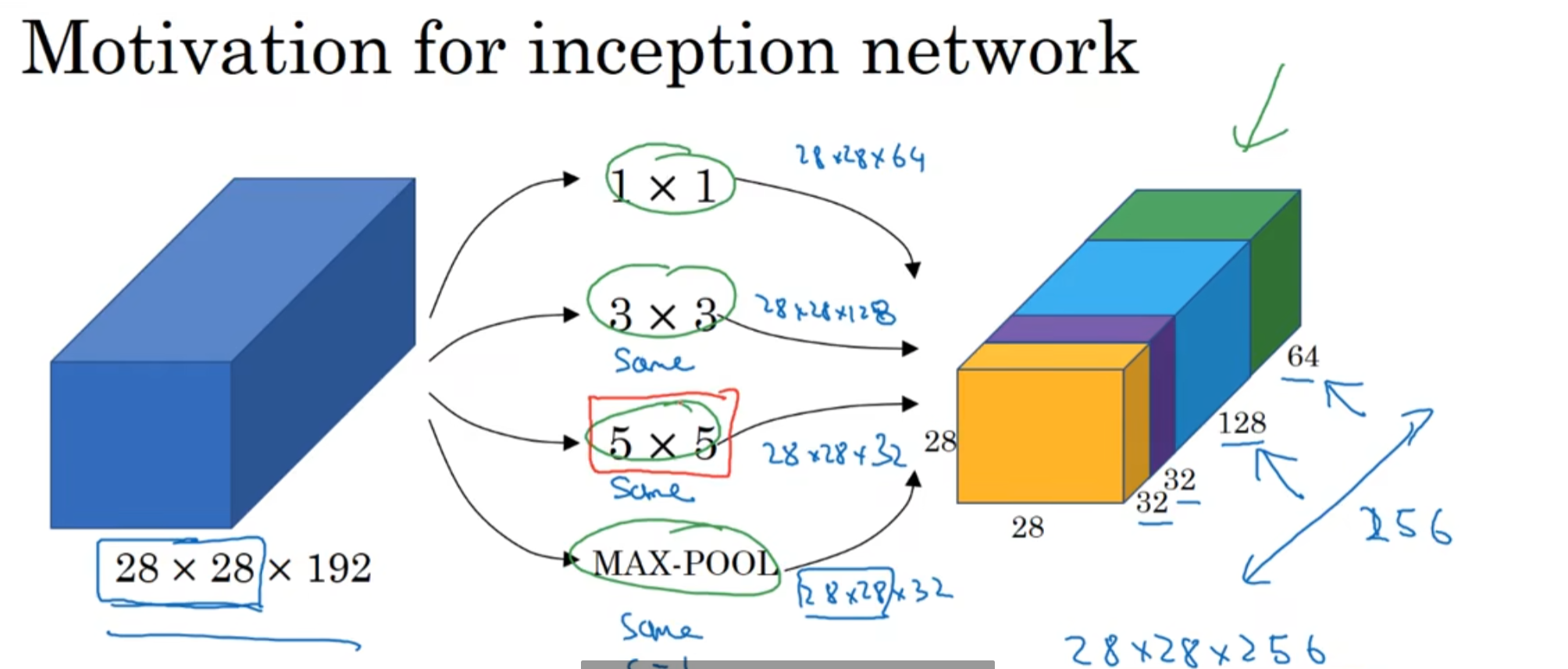
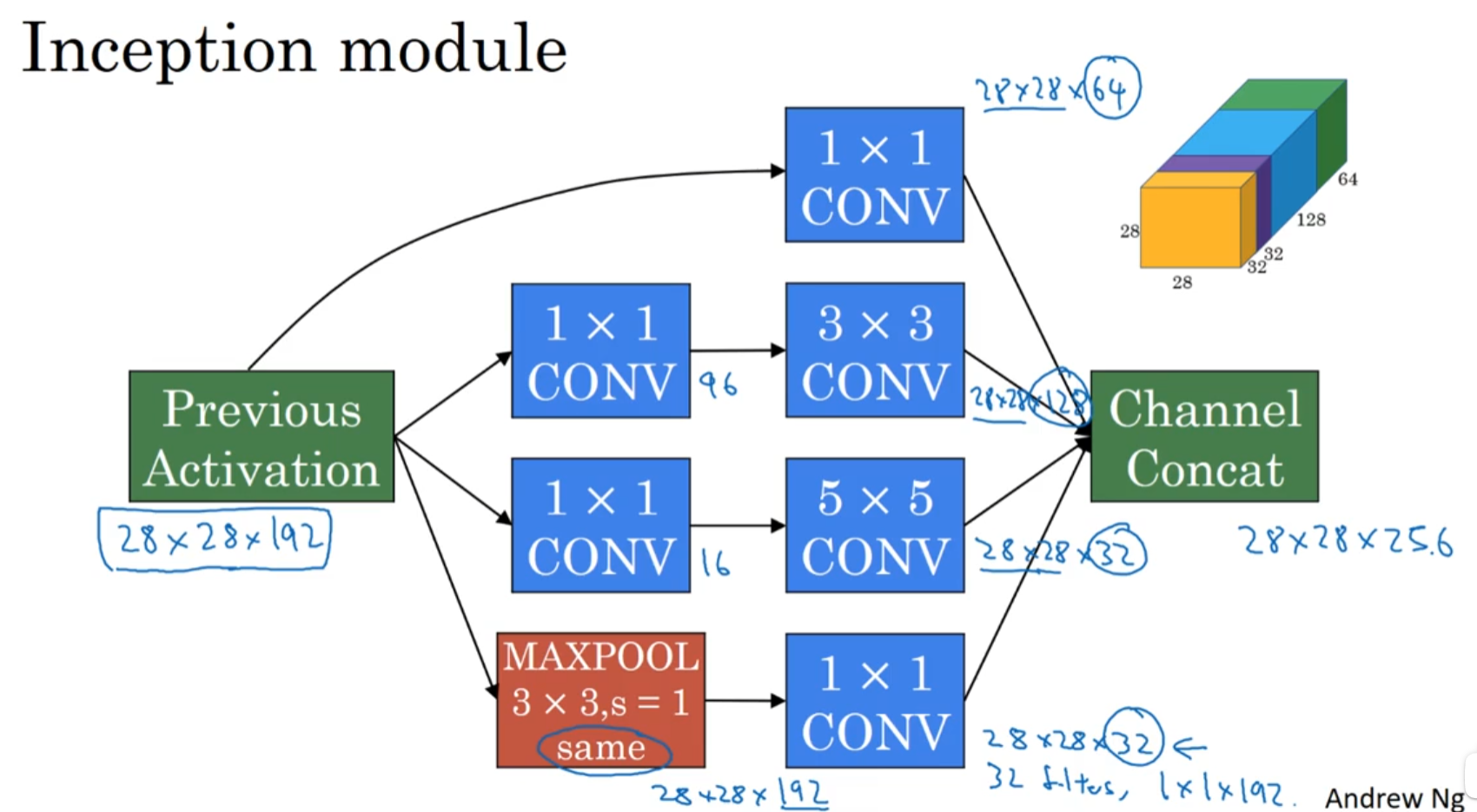
友链:
卷积神经网络LeNet5结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号