


20162307 实验二 二叉树
20162307 实验二 二叉树
北京电子科技学院(BESTI)
实 验 报 告
课程:程序设计与数据结构
班级:1623
姓名:张韵琪
学号:20162307
指导教师:娄佳鹏老师、王志强老师
实验日期:2017年10月27号
实验密级:非密级
实验时间:一周
必修/选修:必修
实验名称:二叉树
实验仪器:电脑
实验目的与要求:
-
目的:
学习二叉树的应用,实现和分析 -
要求:
1.没有Linux基础的同学建议先学习《Linux基础入门(新版)》《Vim编辑器》 课程 2.完成实验、撰写实验报告,实验报告以博客方式发表在博客园,注意实验报告重点是运行结果,遇到的问题(工具查找,安装,使用,程序的编辑,调试,运行等)、解决办法(空洞的方法如“查网络”、“问同学”、“看书”等一律得0分)以及分析(从中可以得到什么启示,有什么收获,教训等)。报告可以参考范飞龙老师的指导 3. 严禁抄袭,有该行为者实验成绩归零,并附加其他惩罚措施。
实验内容、步骤
一、实验要求
参考教材p375,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)
用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
一、实验步骤
-
- 仔细研究16.2LinkedBinaryTree
-
- LinkedBinaryTree中有给出getLeft的方法,所以根据所给的getLeft补写出getRight方法
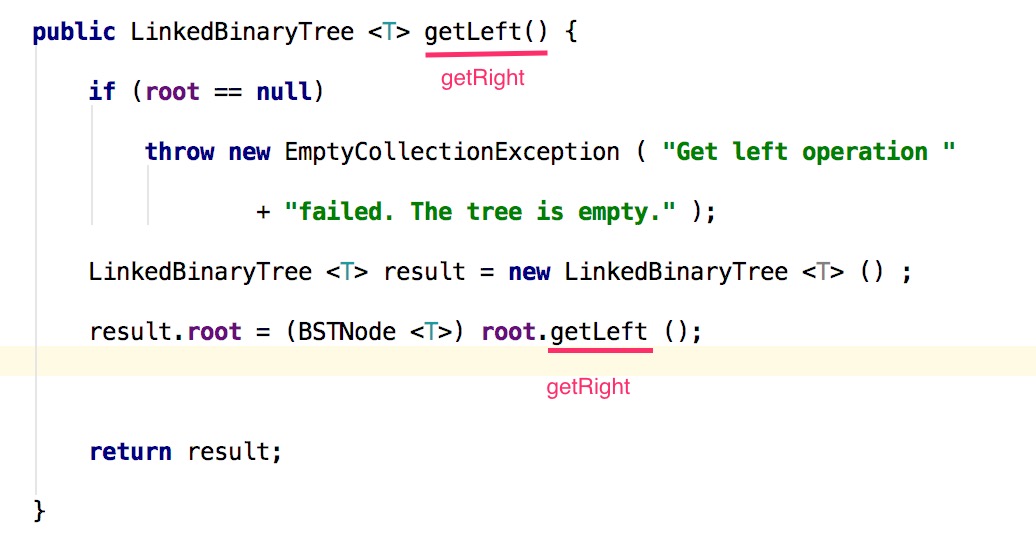
- LinkedBinaryTree中有给出getLeft的方法,所以根据所给的getLeft补写出getRight方法
-
- LinkedBinaryTree的contains方法,在书P382有这样一段话
LinkedBinaryTree中的contains方法留作程序设计项目,它可以使用find方法判定目标元素是否存在于书中
-
3.1 书中说的是用find判断contains,所以应该是public boolean contains(T target) ,然后根据find方法写contains

改为: if (node ==root.find ( target )){ return false; } else return true; -
-
LinkedBinaryTree要补写preorder,postorder,LinkedBinaryTree中给出了inorder的方法,根据inorder写出preorder和postorder
public Iterable
inorder() {
ArrayIteratoriter = new ArrayIterator ();
if (root != null)
root.inorder ( iter );
return (Iterable) iter;
}
-
一、实验结果

二、实验要求
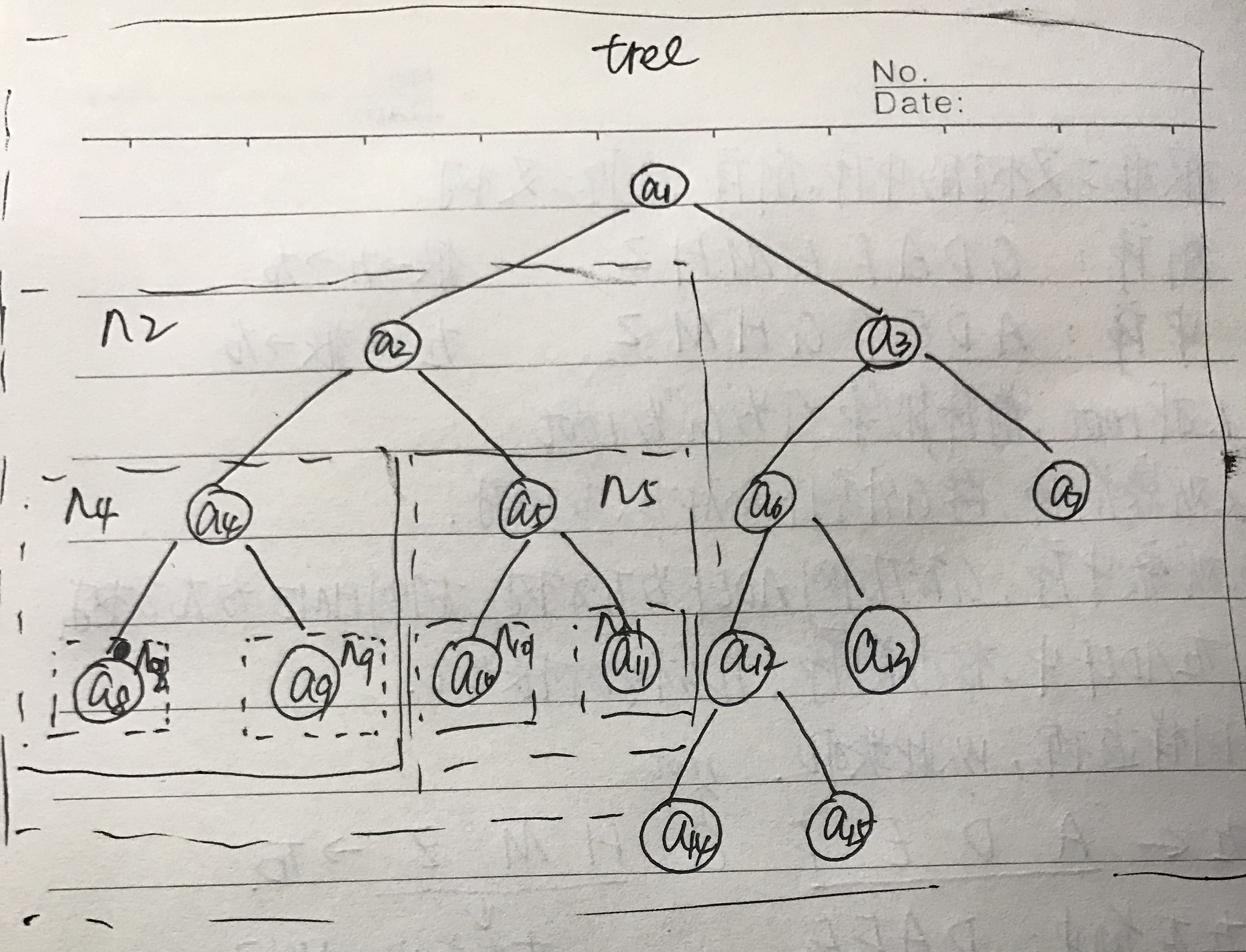
基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如教材P372,给出HDIBEMJNAFCKGL和ABDHIEJMNCFGKL,构造出附图中的树
用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
二、实验步骤
-
知道如何根据先序和中序求出二叉树

-
根据上述思路写对应代码
-
找root
if (preStart == preEnd && inStart == inEnd) { return tree; } int root = 0; for(root= inStart; root < inEnd; root++){ if (pre[preStart] == in[root]) { break; } -
后续步骤代码
int leftLength = root - inStart; int rightLength = inEnd - root; if (leftLength > 0) { tree.left = reConstructBinaryTreeCore(pre, in, preStart+1, preStart+leftLength, inStart, root-1); } if (rightLength > 0) { tree.right = reConstructBinaryTreeCore(pre, in, preStart+1+leftLength, preEnd, root+1, inEnd); } return tree; }
二、实验结果
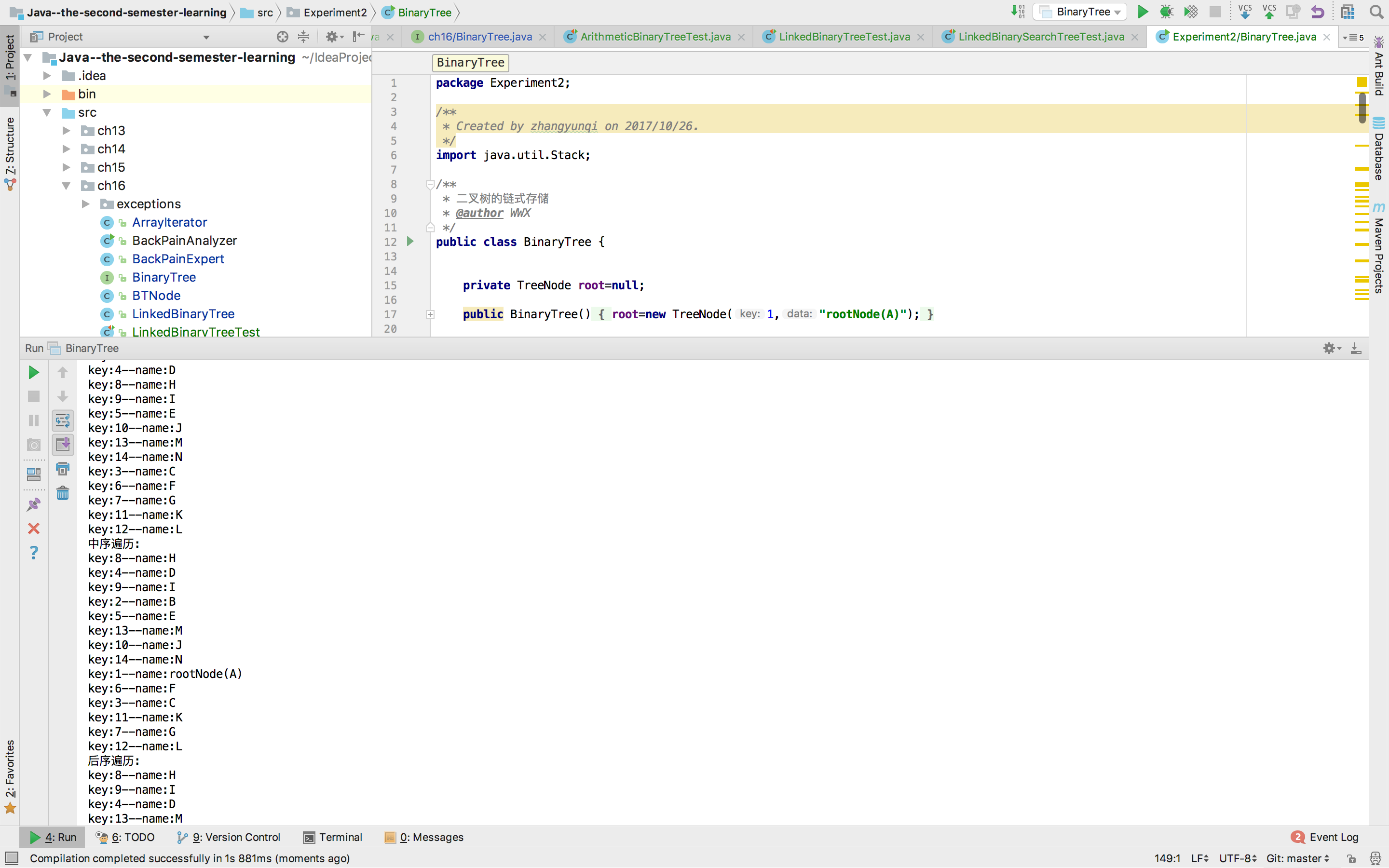
三、实验要求
完成PP16.6
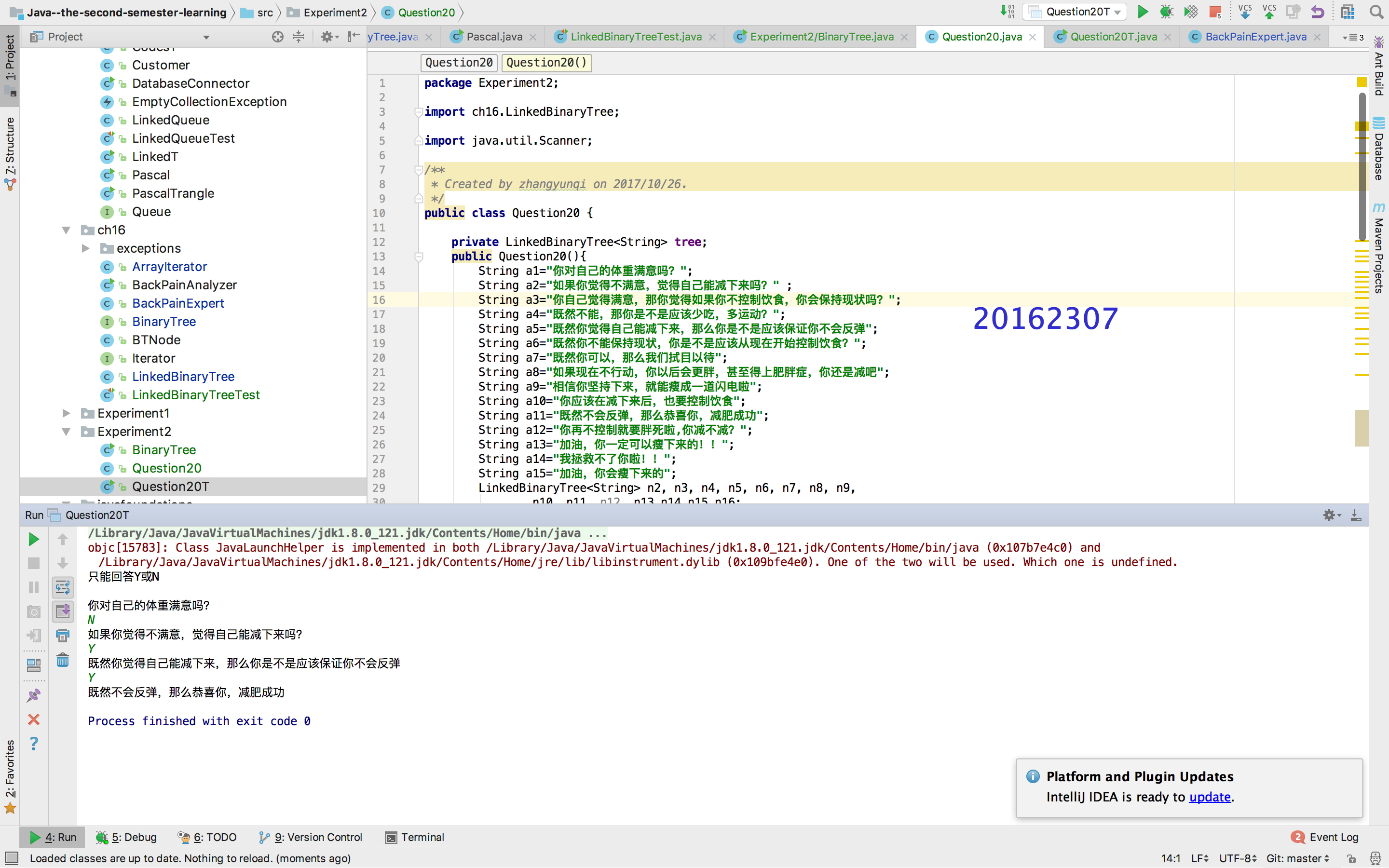
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
三、实验步骤
- 实验三我是参考着16.4和16.5写的
三、实验结果
四、实验要求
完成PP16.8
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
四、实验步骤
-
根据上学期学习的后缀表达式的特点,我们可以知道,只要是运算符的就都是根结点。
-
我们这里需要使用一个栈来保存字符。遍历后缀表达式,每当遇到是非运算符的字符,就将它入栈,当遇到是运算符,就将栈中前两个结点出栈,和运算符组成一棵子树,然后入栈。遍历完成后,栈中剩下的唯一的一个结点就是该后缀表达式的二叉树的根结点。
char[] chs=suffixStr.toCharArray(); Stack<TreeNode> stack=new Stack<TreeNode>(); for(int i=0;i<chs.length;i++){
if(isOperator(chs[i]))
{
if(stack.isEmpty()||stack.size()<2)
{
System.out.println("输入错误");
return;
}
TreeNode root=new TreeNode(chs[i]);
root.left=stack.pop();
root.right=stack.pop();
stack.push(root);
}
else
{
stack.push(new TreeNode(chs[i]));
}
四、实验结果
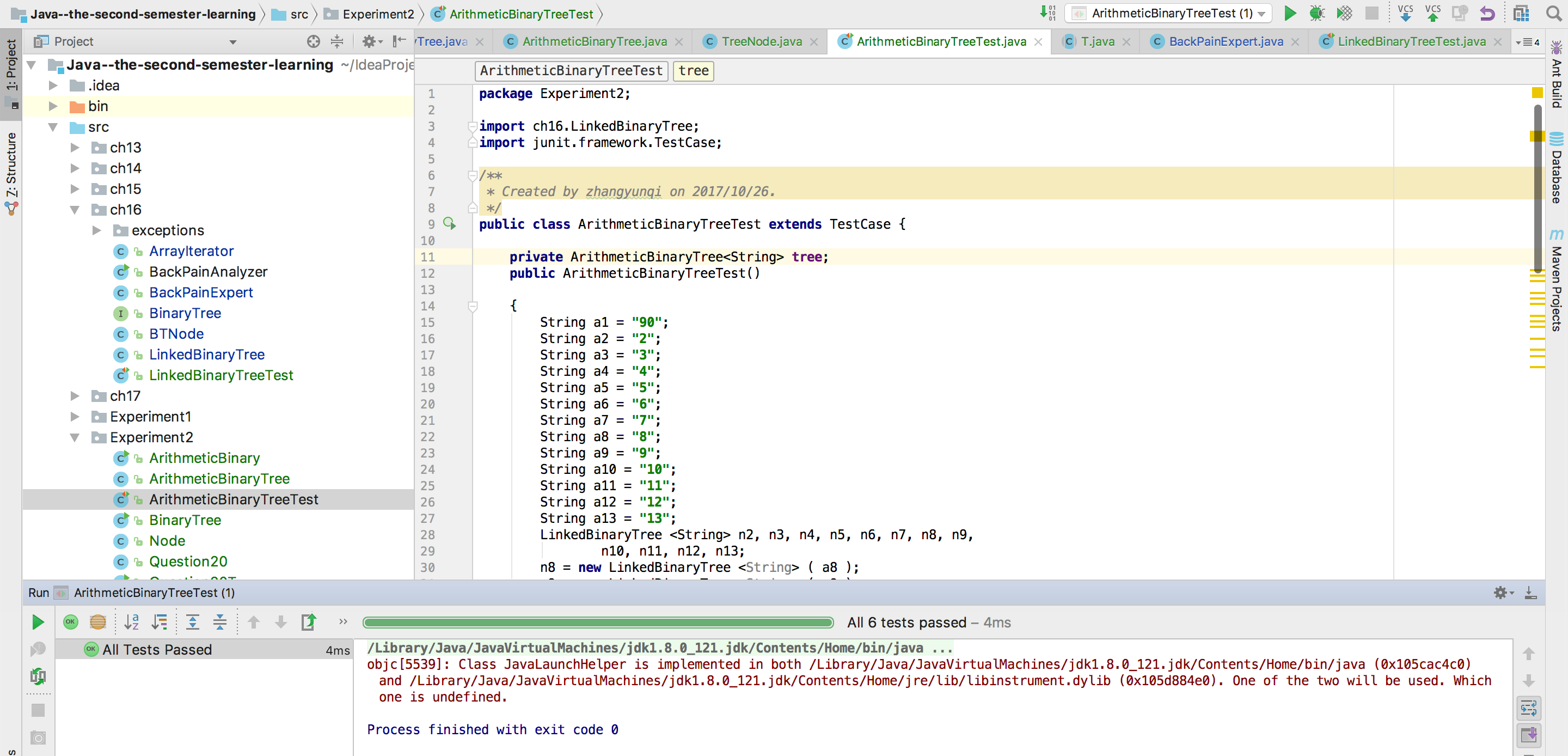
五、实验要求
完成PP17.1
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
五、实验步骤
-
在17.1中补写出
public T findMin(); public T findMax(); -
在17.2中补写findMin,findMax
-
二叉搜索树是一种特殊的二叉树,即:节点的左子节点的值都小于这个节点的值,节点的右子节点的值都大于等于这个节点的值
-
比根节点要小的数会放在当前根节点的左子结点,因此要实现findMin()只要获取该树的最左边的结点即是最小值
-
比根节点要大的数会放在当前根节点的右子结点,因此要实现findMax()只要获取该树的最右边的结点即是最大值
//获取树(子树)中的最小节点
public T findMin(T node){
if(this.find(root) == null){
return null;
}
if(node.leftChild == null)
return node;
T current = node.leftChild;
while(current.leftChild != null)
current = current.leftChild;
return current;
}//获取树(子树)中的最大节点
public T findMax(T node){
if(this.find(root) == null){
System.out.println("Node dosen't exist!");
return null;
}
if(node.rightChild == null)
return node;
T current = node.rightChild;
while(current.rightChild != null)
current = current.rightChild;
return current;
}
五、实验结果

六、实验要求
参考http://www.cnblogs.com/rocedu/p/7483915.html对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果
六、实验步骤
TreeMap
- 博客参考
- TreeMap(K,V) K - 此映射维护的键的类型 V - 映射值的类型
- TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
- TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
- TreeMap 实现了Cloneable接口,意味着它能被克隆。
- TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
- TreeMap() 使用键的自然顺序构造一个新的、空的树映射。
- TreeMap(Comparator<? super K> comparator) 构造一个新的、空的树映射,该映射根据给定比较器进行排序。
- TreeMap(Map<? extends K,? extends V> m) 构造一个与给定映射具有相同映射关系的新的树映射,该映射根据其键的自然顺序 进行排序。
-TreeMap(SortedMap<K,? extends V> m) 构造一个与指定有序映射具有相同映射关系和相同排序顺序的新的树映射。
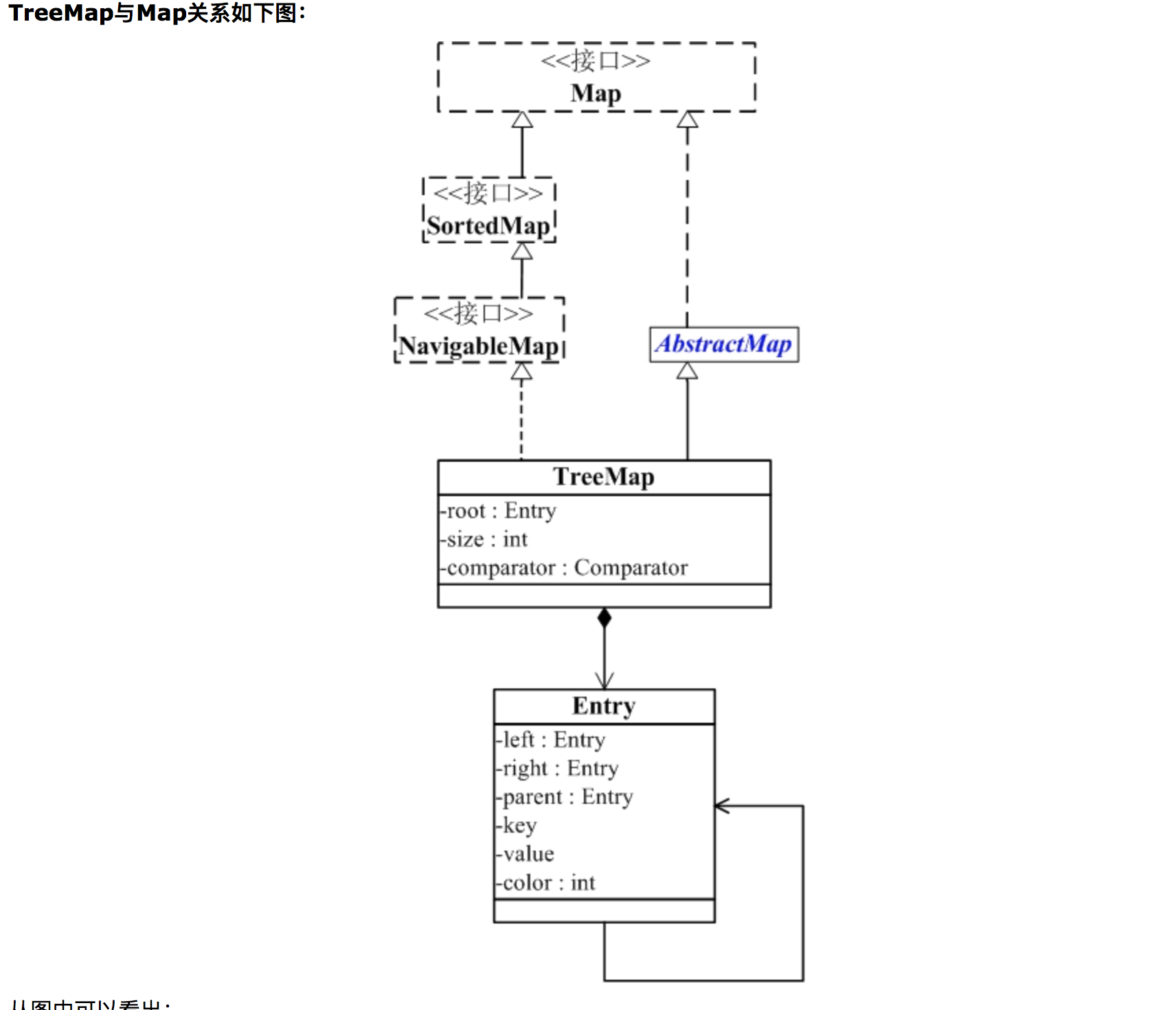
HashMap
- 博客参考
- HashMap<K,V> K - 此映射所维护的键的类型 V - 所映射值的类型
- HashMap() 构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
- HashMap(int initialCapacity) 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
- HashMap(int initialCapacity, float loadFactor) 构造一个带指定初始容量和加载因子的空 HashMap。
- HashMap(Map<? extends K,? extends V> m) 构造一个映射关系与指定 Map 相同的新 HashMap。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号