

Hadoop4 利用VMware搭建自己的hadoop集群
前言:
前段时间自己学习如何部署伪分布式模式的hadoop环境,之前由于工作比较忙,学习的进度停滞了一段时间,所以今天抽出时间把最近学习的成果和大家分享一下。
本文要介绍的是如何利用VMware搭建自己的hadoop的集群。如果大家想了解伪分布式的大家以及eclipse中的hadoop编程,可以参考我之前的三篇文章。
1.在Linux环境中伪分布式部署hadoop(SSH免登陆),运行WordCount实例成功。 http://www.cnblogs.com/PurpleDream/p/4009070.html
2.自己打包hadoop在eclipse中的插件。 http://www.cnblogs.com/PurpleDream/p/4014751.html
3.在eclipse中访问hadoop运行WordCount成功。 http://www.cnblogs.com/PurpleDream/p/4021191.html
===============================================================长长的分割线====================================================================
正文:
在之前的hadoop文章中,我主要是介绍了自己初次学习hadoop的过程中是如何将hadoop伪分布式模式部署到linux环境中的,如何自己编译一个hadoop的eclipse插件,以及如何在eclipse中搭建hadoop编程环境。如果大家有需要的话,可以点击我在前言中列出的前前三篇文章的链接。
闲话少说,言归正传,本次的目的是利用VMware搭建一个属于自己的hadoop集群。本次我们选择的是VMware10,具体的安装步骤大家可以到网上搜索,资源很多。
如果大家再安装过程中,遇到了我没有提到的错误,可以先参考文章底部列出的三个问题,看看解决方案是不是在其中,如果不在的话,再自行上网搜索。
第一步,确定目标:
master 192.168.224.100 CentOS
slave1 192.168.224.201 CentOS
slave2 192.168.224.202 CentOS
其中master为nameNode和jobTracker节点,slave1和slave2为dataNode和taskTracker节点。
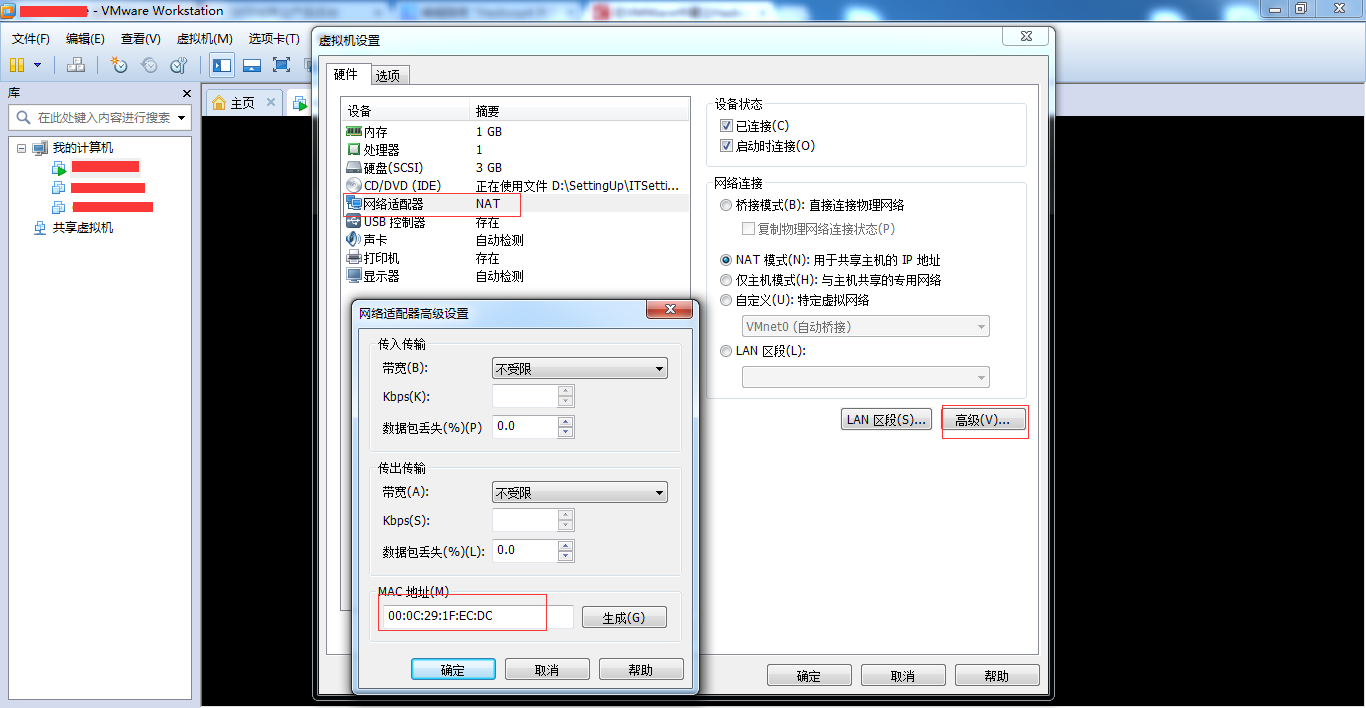
第二步,配置虚拟网络,在VMware工具栏中点击“编辑”,然后选择“虚拟网络编辑器”,在弹出框中设置选项;然后点击“NAT设置”,也按照图片设置,详细参照如下图:


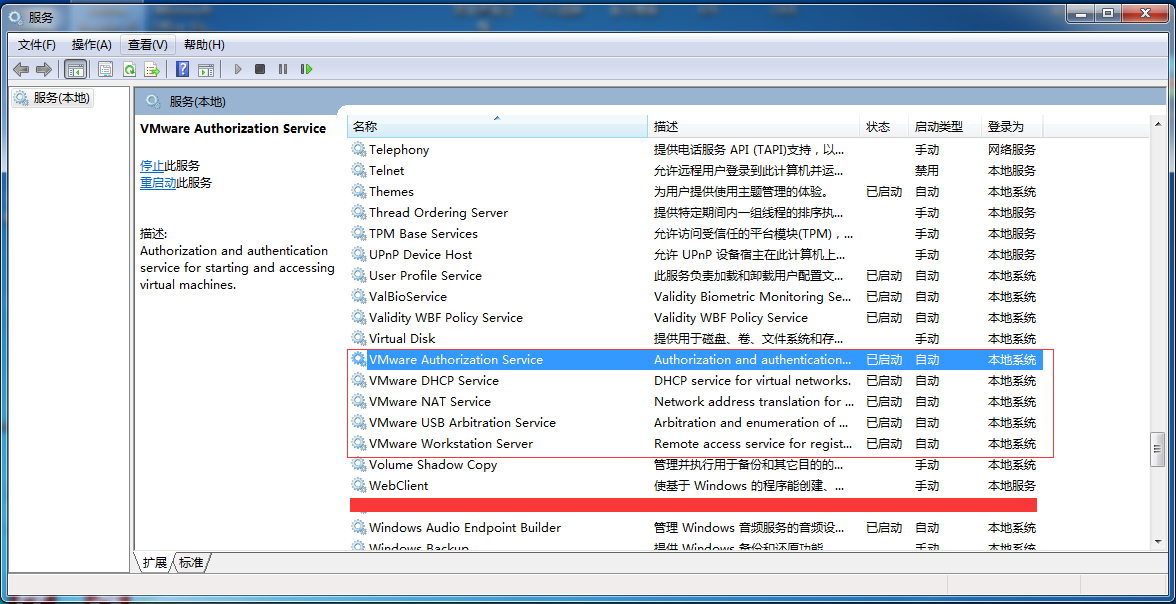
第三步,确认VMware服务都已经启动,这个很重要,不然对你后边的操作很有影响的,如下图:
第四步,在VMware中建立一个CentOS6.5虚拟机,详情可以参考我的另一篇文章:http://www.cnblogs.com/PurpleDream/p/4263465.html
第五步,经过第四步我们的第一个master虚拟机已经建立好了,下面针对这台虚拟机,进行网络、主机等配置,详细步骤如下:
(1).关掉SELINUX:vi /etc/selinux/config ,设置SELINUX=disabled,保存退出,如下图:

(2).关闭防火墙:/sbin/service iptables stop;chkconfig --level 35 iptables off ;执行完毕后,调用 service iptables status,查看防火墙的状态,如下图:

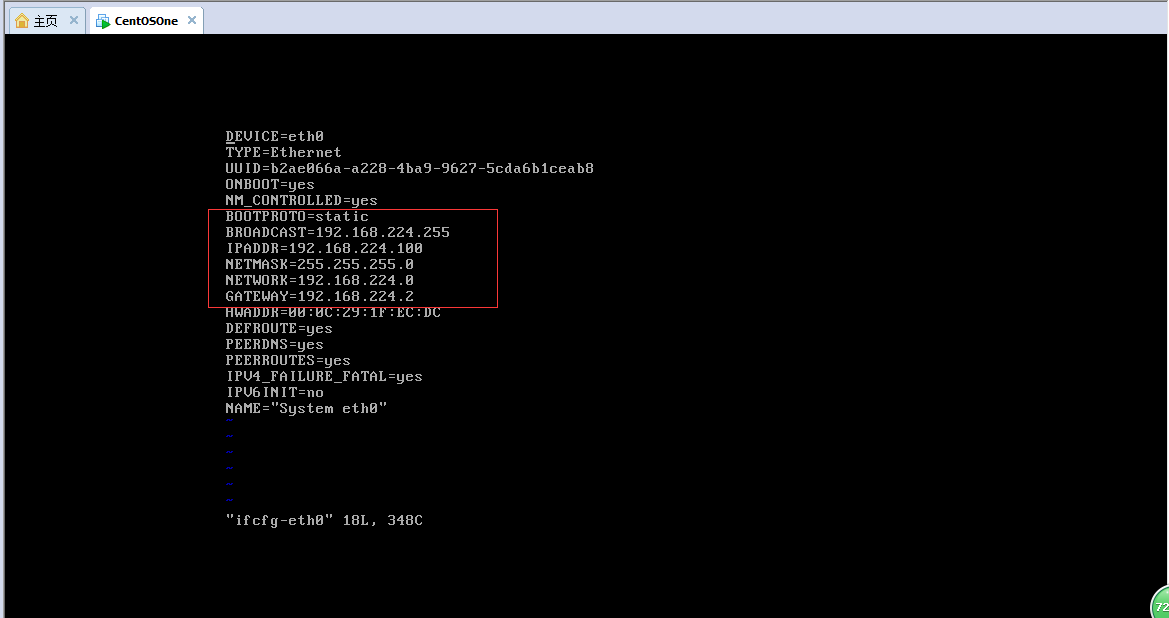
(3).修改IP地址为静态地址:vi /etc/sysconfig/network-scripts/ifcfg-eth0,将其内容改为如下图所示,注意HWADDR那一行,你所创建的虚拟机的值很可能与之不同, 保持原值,不要修改它。
(4).修改主机名称: vi /etc/sysconfig/network,如下图:

(5).修改hosts映射:vi /etc/hosts,这里我们也将slave1和slave2的主机ip映射关系添加上,方便后边使用,如下图:

(6).执行service network restart,重新启动网络,这一步是必须的,请注意。
第七步,安装putty工具,可以在百度上直接搜索,下载解压到自己的目录即可,我们会用到目录中的pscp.exe。
第八步,安装JDK,详细步骤如下:
(1).我从网上下载的是jdk-6u45-linux-i586.bin,放到了我的如下目录是D:\SettingUp\ITSettingUp\Java\JDK\JDK1.6(linux32),注意此目录大家可以根据自己的情 况自行选择,这里我把自己的目录粘出来,是为了后边方便说明pscp的上传。
(2).打开cmd,定位到putty的解压目录,调用如下命令,如果提示输入密码,就输入虚拟机中root帐户的密码。对于下边的命令,我们使用的是pscp命令,两个参数:第一个参数是本地的jdk路径,后边的参数是我们的虚拟机路径,这里我提前在虚拟机上建立了两个父子文件夹:/myself_settings/jdk1.6
pscp D:\SettingUp\ITSettingUp\Java\JDK\JDK1.6(linux32)\jdk-6u45-linux-i586.bin root@192.168.224.100:/myself_settings/jdk1.6
(3).进入虚拟机jdk的所在目录/myself_settings/jdk1.6,执行命令: ./jdk-6u45-linux-i586.bin,等待安装完成。
(4).修改环境变量:vi ~/.bash_profile,在最后添加,如下图所示:

(5).输入命令 source ~/.bash_profile 使配置生效,之后可以执行 java -version 判断jdk是否已经配置成功
第九步,安装hadoop,详细步骤如下:
(1).下载hadoop,我从网上下载的是hadoop-1.0.1.tar.gz。放在了我的本机:D:\SettingUp\ITSettingUp\Hadoop\hadoop-1.0
(2).打开cmd,定位到putty的解压目录,调用如下命令,如果提示输入密码,就输入虚拟机中root帐户的密码。
pscp D:\SettingUp\ITSettingUp\Hadoop\hadoop-1.0\hadoop-1.0.1.tar.gz root@192.168.224.100:/myself_settings/hadoop1.0
(3).进入虚拟机hadoop所在的目录/myself_settings/hadoop1.0,调用命令: tar -xzvf hadoop-1.0.1.tar.gz 将文件解压缩。
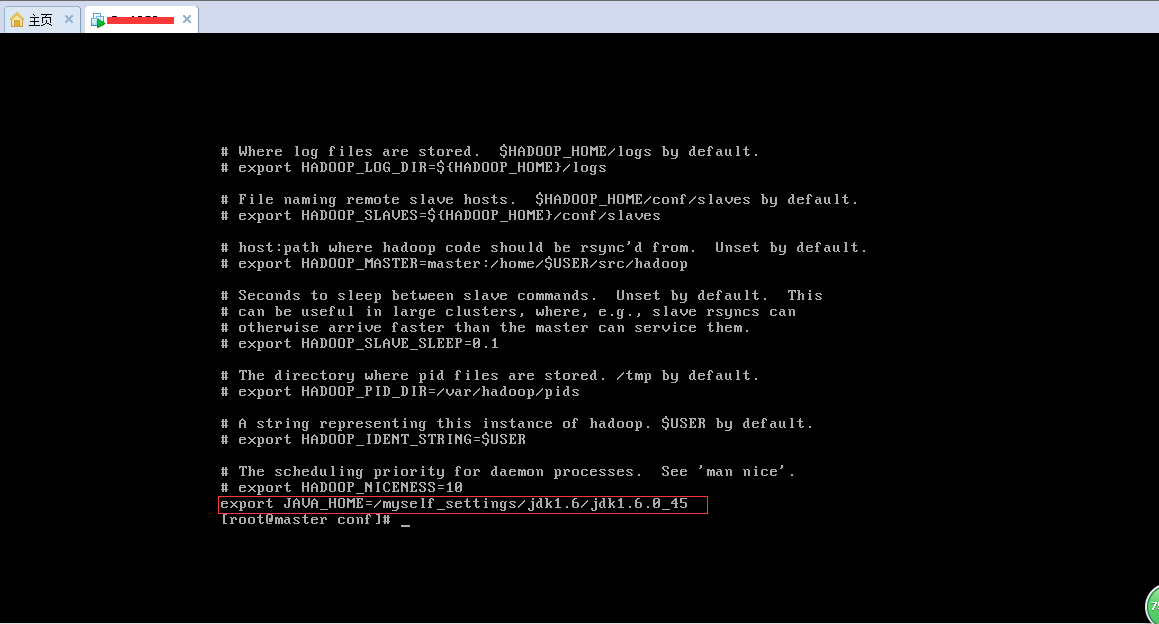
(4).进入(3)中解压缩后的目录后,进入到conf文件夹中进行配置,使用命令: vi hadoop-env.sh ,将JAVA_HOME一行的注释去掉,并改为如下设置:
(5).添加环境变量 vi ~/.bash_profile ,如下图:

(6).打开conf文件: vi core-site.xml, 进行编辑,如下图:

(7).打开conf文件: vi hdfs-site.xml, 进行编辑,如下图:

(8).打开conf文件: vi mapred-site.xml, 进行编辑,如下图:

(9).打开conf文件: vi masters, 进行编辑,如下图:

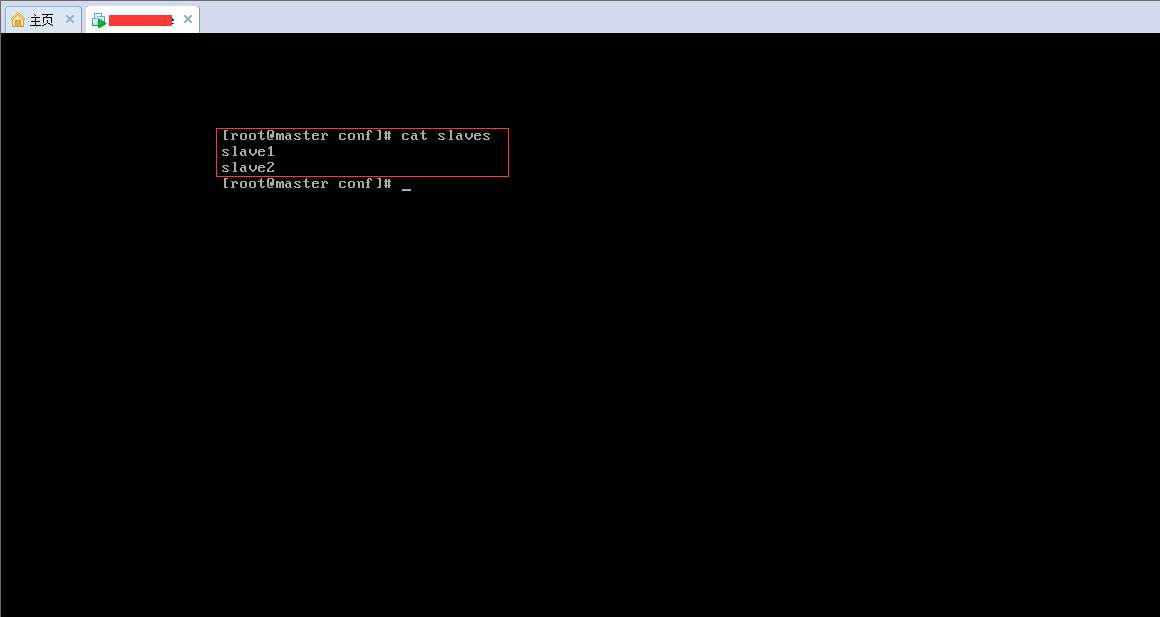
(10).打开conf文件: vi slaves, 进行编辑,如下图:
第十步,经过上述步骤,第一个虚拟机已经配置完毕了,下边我们要克隆两个虚拟机出来,作为slave1和slave2,详细步骤如下:
(1).在VMware左侧的虚拟机列表中选中第一个虚拟机,右键选择“管理”,在“管理”的面板中选择“克隆”,依次选择“下一步 ===》 虚拟机中的当前状态,下一步 ===》 创建完整克隆,下一步 ===》 设置虚拟机名称和安装目录 ===》 点击完成”,然后分别在这两个虚拟机继续做如下操作。
(2).执行:rm -f /etc/udev/rules.d/70-persistent-net.rules
(3).执行 reboot 重启虚拟机
(4).执行 vi /etc/sysconfig/networking/devices/ifcfg-eth0 将其中的 HWADDR修改为新虚拟机的网卡地址,具体查看虚拟机网卡地址的方式为: 选中虚拟机,邮件选择“设置”,在弹出的面板中按照下图所示进行设置,如下图:
(5).同样将(4)文件中将IPADDR改为192.168.224.201(对于slave1)或192.168.224.202(对于slave2)。
(6).修改slave1和slave2的/etc/sysconfig/network文件,将主机名改为slave1或者slave2
(7).两台虚拟机执行 service network restart 重启网络
第十一步,经过上述步骤,三台虚拟机已经基本配置完毕,但是还有一个重要的步骤,那就是ssh免登陆的配置,这块我当时出了问题,所以这里再详细的说明一下:
备注:由于我第一次搭建的时候这里出了问题,所以此处当时没有来得及做记录,现在为了演示,我重新搭建了两个虚拟机,分别是TestOne和TestTwo,我这里要做的就是从TestOne免登陆到TestTwo。大家以此类推,与我们这个文章中要做的master免登陆 到slave1和slave2是一样的。
(1).首先在TestOne虚拟机中,通过 cd ~/.ssh 进入~/.ssh目录,会看到有一个known_hosts文件,
(2).在~/.ssh文件夹中,输入 ssh-keygen -t dsa ,然后会让你输入密钥存储文件的名称,我输入的是id_dsa。前边这两部可以参考下边的图片,注意图片中用红色矩形框圈中的部分:
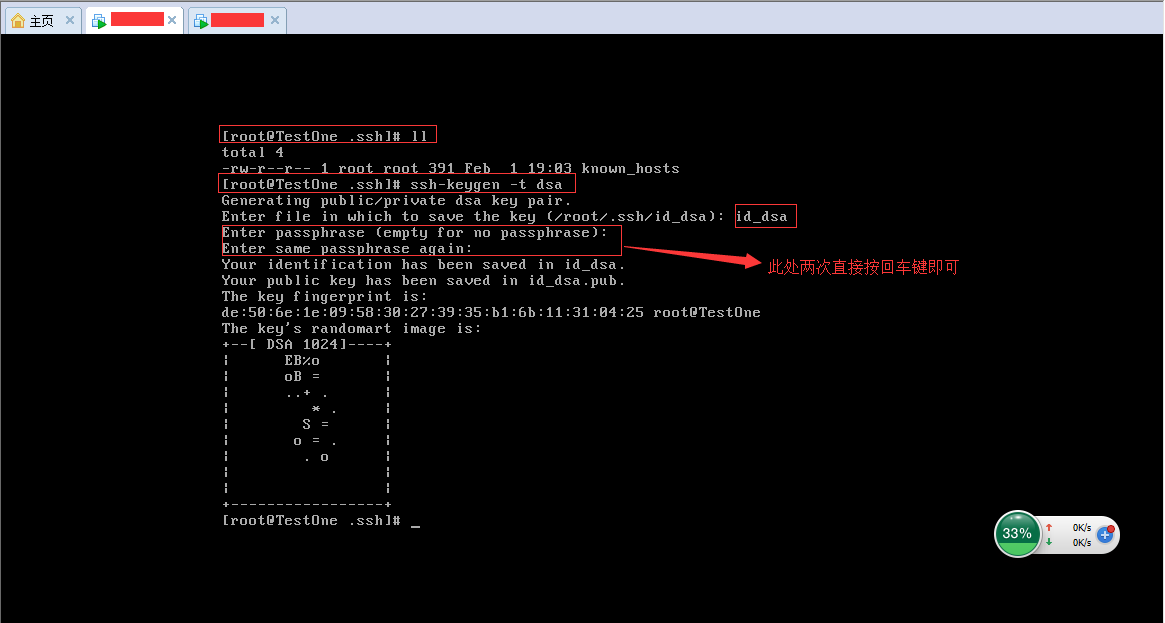
(3).在~/.ssh文件夹中输入 cat id_dsa.pub >> authorized_keys,如下图所示:

(4).在~/.ssh文件夹中,将刚才生成的密钥拷贝到TestTwo机器上,输入命令: scp authorized_keys TestTwo:~/.ssh ,过程中需要输入TestTwo的密码,详细参考下图,注意图中用红色矩形框圈中的部分:

(5).经过上述4步,输入 ssh TestTwo,应该不需要再输入TestTwo的登录密码,就可以从TestOne直接登录到TestTwo了。
第十二步,至此,虚拟机的配置全部完毕,我们依次执行hadoop namenode -format 、 hadoop datanode -format ,然后在hadoop的安装目录下,进入bin目录,执行如下命令: ./start-all.sh . 然后可以在宿主机中打开浏览器,查看 192.168.224.100:50070 的内容,如果正常显示,就说明启动正常了。注意,这里也可以分别在master和slaves输入jps命令验证是否启动成功,如下图:


经过上边的十二步,我相信属于你自己的hadoop集群已经大家成功了,后边你可以参考我文章开头列出的文章,在eclipse中添加自己的DFS Location,指向我们的集群。在上述这个过程中,你有可能遇到一些问题,可以参考下边我列出的文章:
1.在eclipse中访问hadoop集群时出现 org.apache.hadoop.security.AccessControlException: Permission denied: user=DrWho, access=WRITE 这个错误,参考如下:
解决方案:http://www.cnblogs.com/acmy/archive/2011/10/28/2227901.html
2.启动hadoop时有这样的提示 Warning: $HADOOP_HOME is deprecated. 这个不会影响使用,如果想解决的话,参考如下:
解决方案:http://chenzhou123520.iteye.com/blog/1826002
3. 如果在设置完网络,调用service network restart时,出现Device eth0 does not seem to be present这个问题,参考如下:
解决方案:重新打开vi /etc/sysconfig/network-scripts/ifcfg-eth0,将其中的DEVICE的值改为eth1或者别的,然后重启网络,应该就不会报错了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号