

20162309第16、17章第二次实验报告
实验名称:关于java树的相关内容学习
实验目的:学习课本关于树的结构和二叉树的使用的相关知识,通过决策树进行程序设计和程序开发;学习通过使用二叉树的相关知识来解决实际问题,包括几种二叉树方法的实现,二叉树中元素的查找;以及实现自己构造二叉树,并对其进行测试;使用二叉树来表示表达式树。
实验题目:1、实现二叉树:完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder),用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试。
2、中序先序序列构造二叉树:基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,给出HDIBEMJNAFCKGL和ABDHIEJMNCFGKL,构造出树,用JUnit或自己编写驱动类对自己实现的功能进行测试。实验2需要自主构建给定二叉树,需要调试课本的代码。
3、决策树:通过决策树的方法,设计一个20问的游戏,需要尽可能少的进行判断。
4、表达式树:使用二叉树来表示表达式树,实现算数表达式的实现,并得到表达式的结果。
5、二叉查找树:实现课本代码LinkedBinarySearchTree,并完成测试驱动类,实现findMin和findMax两个查找方法,通过遍历来查找最大值和最小值。
6、红黑树分析:对Java中的红黑树(TreeMap,HashMap)进行源码分析,学习有关红黑树的相关知识。
实验日期:2017.10.23
指导老师:娄老师、王老师
实验具体过程:(部分实验需要对相同的代码进行调试,但所需要的异常和测试驱动类均有所不同。)
实验一:实验截图

首先需要调试课本的代码LinkedBinaryTree以及BTNode,同时需要导入ElementNotFoundException和EmptyCollectionException两个异常,并需要队列代码LinkedQueue中的相关入队和出队的方法,需要自己实现的方法是preorder(先序遍历方法)和postorder(后序遍历方法),其中inorder(中序遍历方法)已经实现,其他两种方法只需要照葫芦画瓢,改变对根、左子树、右子树的访问顺序,使用相同的方法即可完成编译,这里需要注意调用的ArrayIterator类需要课件资源里的,在BTNode里需要调试的是几个返回值,最后需要编写测试类,对已经实现的几个方法进行测试(inorder、postorder、preorder、isEmpty、toString、getLeft、getRight):

方法实现:改变访问顺序

实验二:实验截图
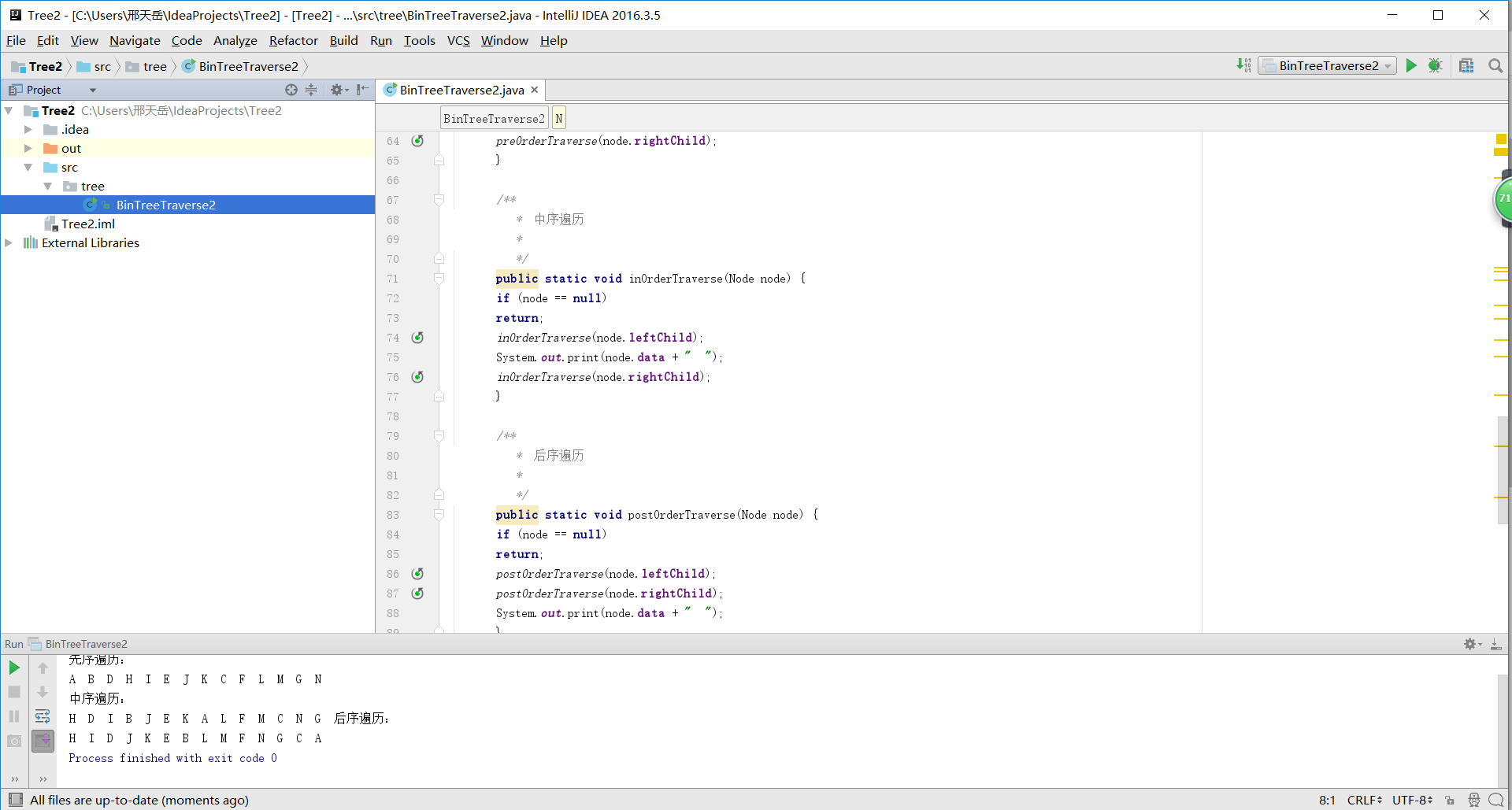
构建符合条件的二叉树,需要分别遍历输入的值,主要是左右节点和根的设置位置。在左右节点设置完毕后需要设置访问顺序,按照题目要求的顺序进行遍历即可。这个实验的程序需要转化Node节点,

并设好左右节点,再分别进行遍历。

在遍历之前还需要做的是确定节点的位置(根节点),可以用索引值的方法来确定,对多个节点值进行分辨。则在nodeList中,索引值为0的是root根节点。
索引值判断节点的实例:若给出一棵二叉树的一系列节点,且每个节点的信息中都包含其左右子节点的索引值,如:
struct BinaryNode
{
i nt identifier ;
int leftchild ;
int rightchild ;
}
其中identifier代表每个节点的索引值,leftchild和rightchild分别是其左右子节点的索引值,若给出一系列这样的节点的信息,要如何才能从中找出这棵二叉树的根节点。
整棵树中唯一只有根节点“只有后续 而无前驱”
这样可以事先通过程序列出树的节点集合,在排除“必定不为根”的节点(即一节点为另一节点的左右孩子时,该节点则有前驱,必不为树根),这样将每个节点处理一遍后,树的节点集合中
必定只有一个节点未被排除,即那个没有前驱的节点,这个点就是树根。
用此类方法可以对一个新建的二叉树进行节点判断。
实验三:实验截图
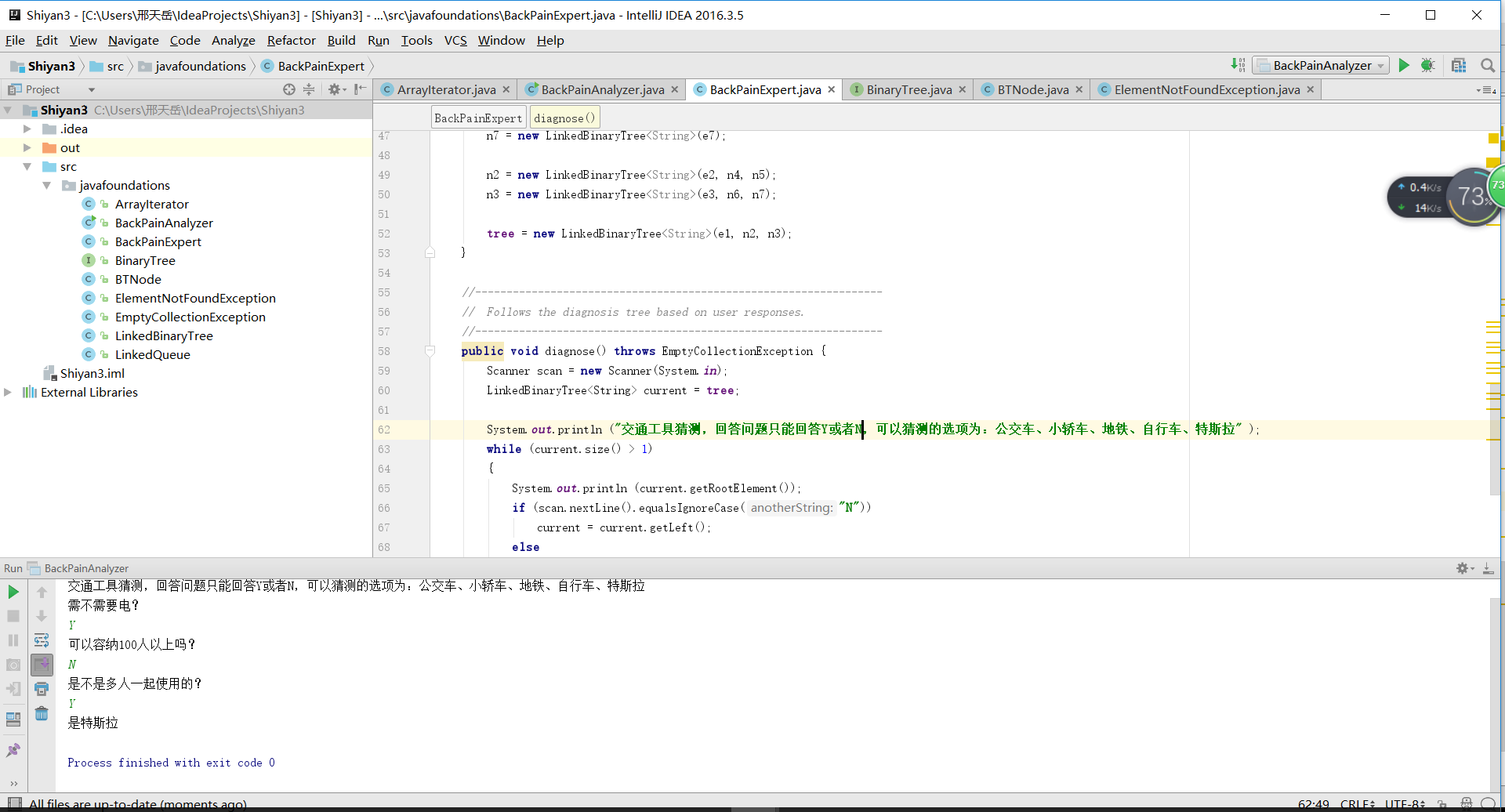
实验三是使用决策树的方法来实现一个20问程序,这个过程其实是一个判断的过程,不过需要使用到树的节点分析。首先需要分析决策树的使用方法和概念:决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。
使用决策树进行实验三时,需要连续进行判断,通过回答问题,程序判断答案来选择下一个节点。这里所使用的原代码是教材17章的BackPainExpert,使用的方法也类似,但同时链树代码(LinkedBinaryTree)中的数中方法也需要实现,在实验过程中,我的contains方法一直不知道如何正确实现,在查阅了相关资料后,查阅了contains方法实现的实例:
import java.lang.*;
public class StringDemo {
public static void main(String[] args) {
String str1 = "tutorials point", str2 = "http://";
CharSequence cs1 = "int";
// string contains the specified sequence of char values
boolean retval = str1.contains(cs1);
System.out.println("Method returns : " + retval);
// string does not contain the specified sequence of char value
retval = str2.contains("_");
System.out.println("Methods returns: " + retval);
}
}
在决策树中实现contains方法就需要一个if判断语句,对根节点的值进行判断,并确定返回值的类型。

之后就设定几个问题和几个答案就可以进行实验了。
实验四:实验截图
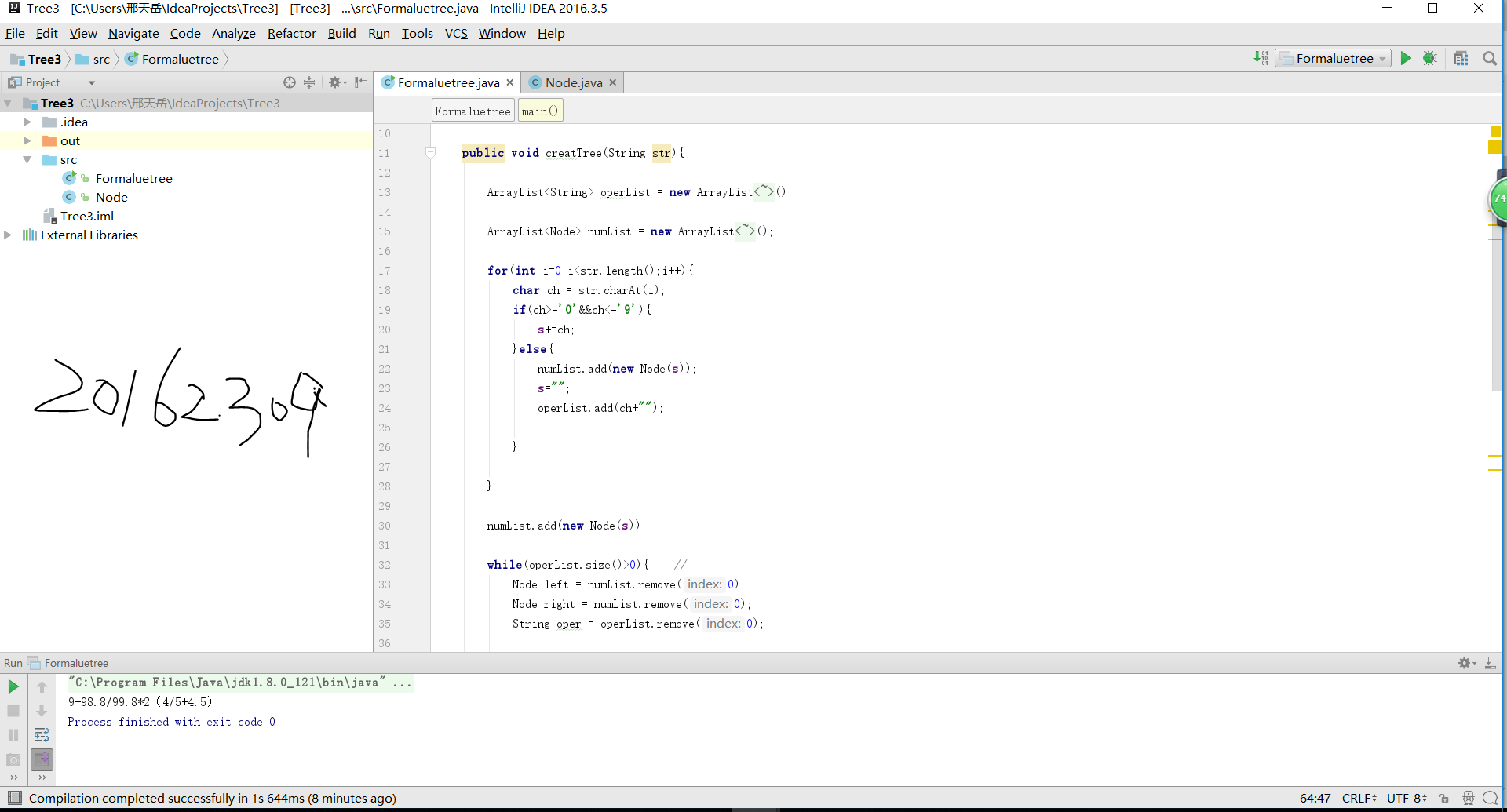
这个实验和栈的方法很相似,但计算则需要用树的方法来实现,首先仍是需要实现遍历方法,这里有一个中缀转后缀的过程,就是在生成表达式后对结果的计算,可以使用栈的方法进行实现。这里也可以使用四则运算的知识来完成对表达式的计算。把后缀表达式转变成表达式树。我们一次一个符号地读入表达式。如果符号是操作数,那么就建立一个单结点树并将它推入栈中。如果符号是操作符,那么就从栈中弹出两棵树T1和T2(T1先弹出)并形成一棵新的树,该树的根就是操作符,它的左、右儿子分别是T2和T1。然后将指向这颗树的指针压入栈中。
//入栈操作
int push_stack{
p->n ++;
p->buf[p->n] = data;
return 0;
}
//把最后的数字加入到数字节点中
numList.add(new Node(s));
实验五:实验截图
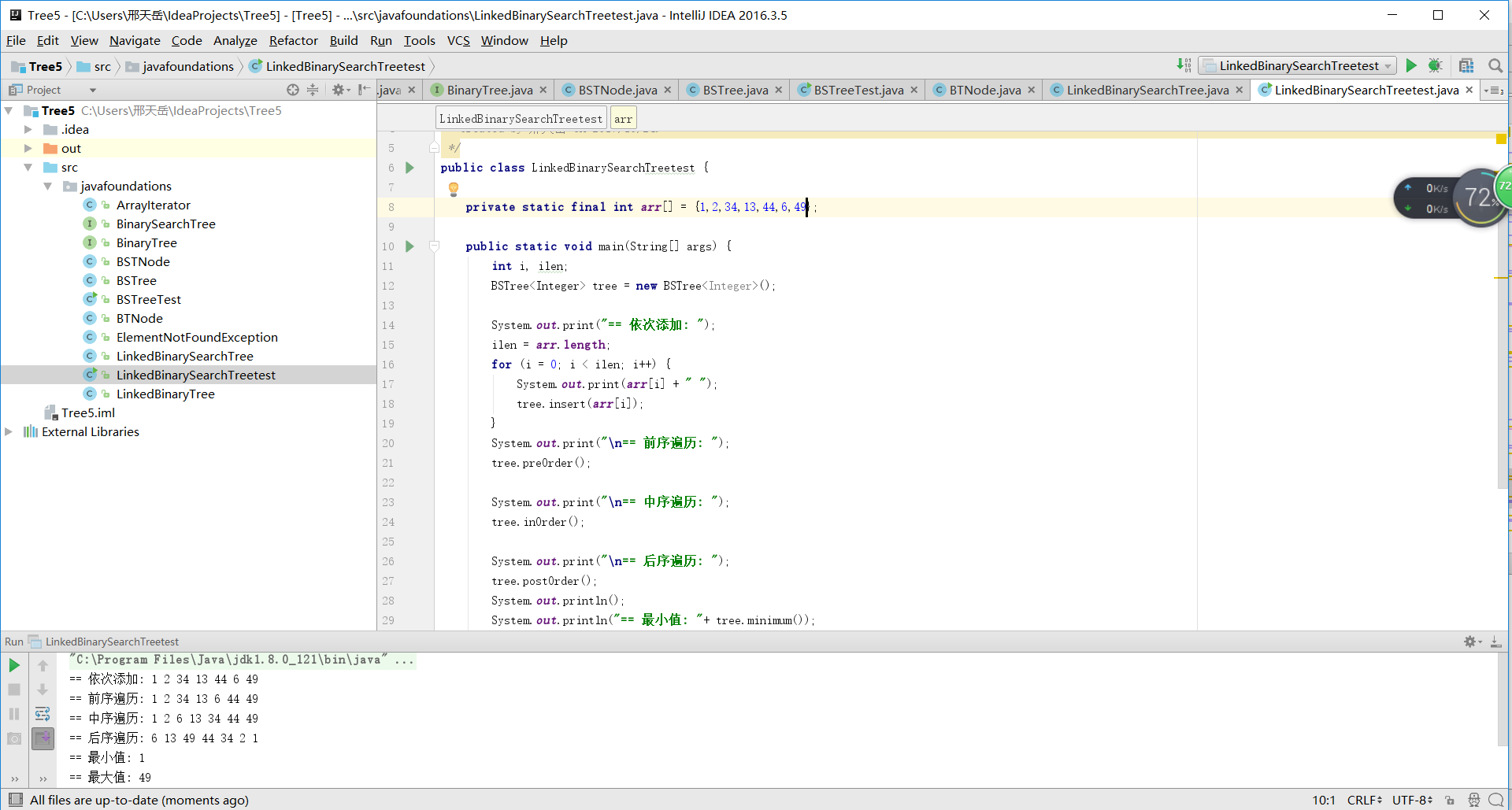
实验五是对链树的一个查找,需要实现findMax和findMin两个方法。这个方法的实现仍然需要遍历,此实验是一个二叉查找树的实现。首先了解一下二叉查找树的概念:它是特殊的二叉树:对于二叉树,假设x为二叉树中的任意一个结点,x节点包含关键字key,节点x的key值记为key[x]。如果y是x的左子树中的一个结点,则key[y] <= key[x];如果y是x的右子树的一个结点,则key[y] >= key[x]。那么,这棵树就是二叉查找树。如下图所示:

在二叉查找树中:
(01) 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(02) 任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(03) 任意节点的左、右子树也分别为二叉查找树。
(04) 没有键值相等的节点(no duplicate nodes)。
这是查找树的相关概念。
实验中的需要先对已构建的树进行遍历,再实现查找最大最小值的方法

编写测试驱动类,首先需要建立树:

之后再测试几个已经实现的方法就可以了。
实验六:关于java红黑树的实现
关于java红黑树:
红黑树(Red-Black Tree,简称R-B Tree),它一种特殊的二叉查找树。
红黑树是特殊的二叉查找树,意味着它满足二叉查找树的特征:任意一个节点所包含的键值,大于等于左孩子的键值,小于等于右孩子的键值。
除了具备该特性之外,红黑树还包括许多额外的信息。
红黑树的每个节点上都有存储位表示节点的颜色,颜色是红(Red)或黑(Black)。
红黑树的特性:
(1) 每个节点或者是黑色,或者是红色。
(2) 根节点是黑色。
(3) 每个叶子节点是黑色。 [注意:这里叶子节点,是指为空的叶子节点!]
(4) 如果一个节点是红色的,则它的子节点必须是黑色的。
(5) 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
关于它的特性,需要注意的是:
第一,特性(3)中的叶子节点,是只为空(NIL或null)的节点。
第二,特性(5),确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树。
红黑树的实例:

关于红黑树的码源分析:
1.TreeMap:
// 默认构造函数。使用该构造函数,TreeMap中的元素按照自然排序进行排列。
TreeMap()
// 创建的TreeMap包含Map
TreeMap(Map<? extends K, ? extends V> copyFrom)
// 指定Tree的比较器
TreeMap(Comparator<? super K> comparator)
// 创建的TreeSet包含copyFrom
TreeMap(SortedMap<K, ? extends V> copyFrom)
API文档分析:

Entry<K, V> ceilingEntry(K key)
K ceilingKey(K key)
void clear()
Object clone()
Comparator<? super K> comparator()
boolean containsKey(Object key)
NavigableSet
NavigableMap<K, V> descendingMap()
Set<Entry<K, V>> entrySet()
Entry<K, V> firstEntry()
K firstKey()
Entry<K, V> floorEntry(K key)
K floorKey(K key)
V get(Object key)
NavigableMap<K, V> headMap(K to, boolean inclusive)
SortedMap<K, V> headMap(K toExclusive)
Entry<K, V> higherEntry(K key)
K higherKey(K key)
boolean isEmpty()
Set
Entry<K, V> lastEntry()
K lastKey()
Entry<K, V> lowerEntry(K key)
K lowerKey(K key)
NavigableSet
Entry<K, V> pollFirstEntry()
Entry<K, V> pollLastEntry()
V put(K key, V value)
V remove(Object key)
int size()
SortedMap<K, V> subMap(K fromInclusive, K toExclusive)
NavigableMap<K, V> subMap(K from, boolean fromInclusive, K to, boolean toInclusive)
NavigableMap<K, V> tailMap(K from, boolean inclusive)
SortedMap<K, V> tailMap(K fromInclusive)
结构分析:继承
java.lang.Object
↳ java.util.AbstractMap<K, V>
↳ java.util.TreeMap<K, V>
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable {}
继承图解:

从图中可以看出:
(01) TreeMap实现继承于AbstractMap,并且实现了NavigableMap接口。
(02) TreeMap的本质是R-B Tree(红黑树),它包含几个重要的成员变量: root, size, comparator。
root 是红黑数的根节点。它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
红黑数排序时,根据Entry中的key进行排序;Entry中的key比较大小是根据比较器comparator来进行判断的。
size是红黑数中节点的个数。
2.HashMap:基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。 此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性能。
图解:

其中put方法的详解:
public V put(K key, V value) {
// 处理key为null,HashMap允许key和value为null
if (key == null)
return putForNullKey(value);
// 得到key的哈希码
int hash = hash(key);
// 通过哈希码计算出bucketIndex
int i = indexFor(hash, table.length);
// 取出bucketIndex位置上的元素,并循环单链表,判断key是否已存在
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 哈希码相同并且对象相同时
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 新值替换旧值,并返回旧值
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// key不存在时,加入新元素
modCount++;
addEntry(hash, key, value, i);
return null;
}
执行put方法后,最终HashMap的存储结构会有这三种情况,情形3是最少发生的,哈希码发生碰撞属于小概率事件。到目前为止,我们了解了两件事:
HashMap通过键的hashCode来快速的存取元素。
当不同的对象hashCode发生碰撞时,HashMap通过单链表来解决,将新元素加入链表表头,通过next指向原有的元素。单链表在Java中的实现就是对象的引用(复合)。
实验总结:
本次实验内容较多,更多的是对课本代码的理解和调试,并加以利用。我们需要理解什么是树,树的方法,树的结构,树与栈、队列的区别与联系,并对树加以实现。同时要辨析几种树的区别和联系,重点是二叉树的学习,和各种二叉树的实际利用,对我们对数据结构的学习有很大的帮助。
代码链接:https://gitee.com/pdds2017/xty20162309-JavaFoundations2nd/tree/master/TreeS

 浙公网安备 33010602011771号
浙公网安备 33010602011771号