
深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用。
1. seq2seq模型介绍
seq2seq模型是以编码(Encode)和解码(Decode)为代表的架构方式,seq2seq模型是根据输入序列X来生成输出序列Y,在翻译,文本自动摘要和机器人自动问答以及一些回归预测任务上有着广泛的运用。以encode和decode为代表的seq2seq模型,encode意思是将输入序列转化成一个固定长度的向量,decode意思是将输入的固定长度向量解码成输出序列。其中编码解码的方式可以是RNN,CNN等。
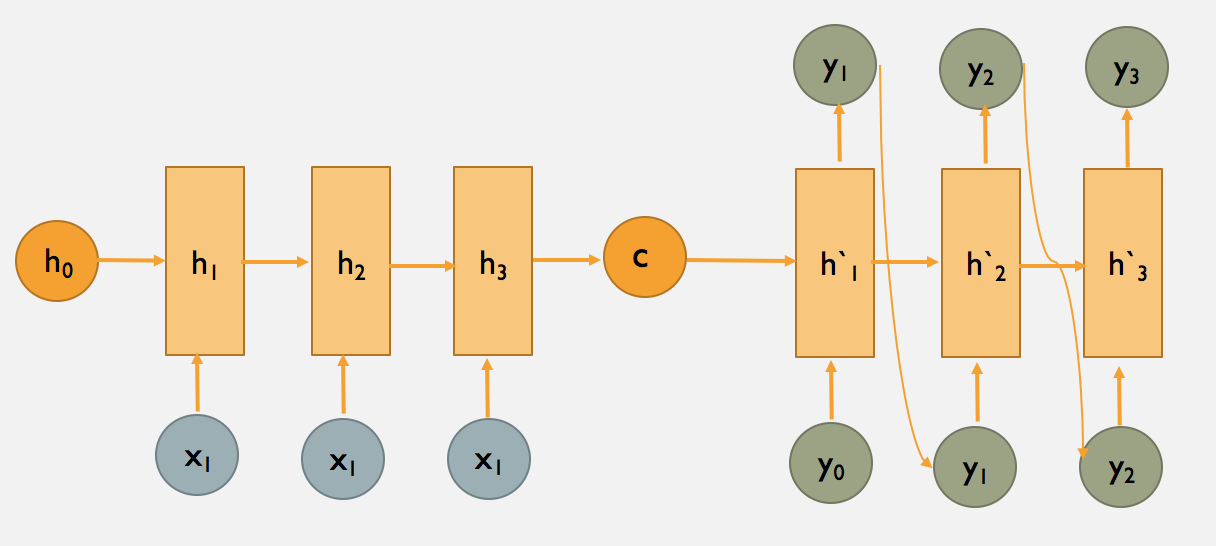
图1. encode和decode框架
上图为seq2seq的encode和decode结构,采用CNN/LSTM模型。在RNN中,当前时间的隐藏状态是由上一时间的状态和当前时间的输入x共同决定的,即
![]()
【编码阶段】
得到各个隐藏层的输出然后汇总,生成语义向量
![]()
也可以将最后的一层隐藏层的输出作为语义向量C ![]()
【解码阶段】
这个阶段,我们要根据给定的语义向量C和输出序列y1,y2,…yt−1来预测下一个输出的单词yt,即
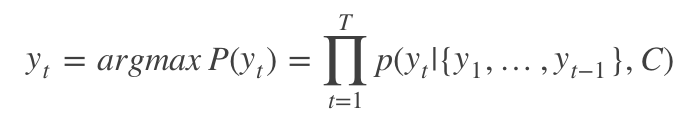
也可以写做 ![]()
其中g()代表的是非线性激活函数。在RNN中可写成 yt=g(yt−1,ht,C) ,其中h为隐藏层的输出。
以上就是seq2seq的编码解码阶段,seq2seq模型的抽象框架可描述为下图:
图2. seq2seq抽象框架图
2.Attention机制在seq2seq模型中的运用
2.1 自然语言处理中的Attention机制
由于encoder-decoder模型在编码和解码阶段始终由一个不变的语义向量C来联系着,编码器要将整个序列的信息压缩进一个固定长度的向量中去。这就造成了 (1)语义向量无法完全表示整个序列的信息,(2)最开始输入的序列容易被后输入的序列给覆盖掉,会丢失许多细节信息。在长序列上表现的尤为明显。
Attention模型的引入:
相比于之前的encoder-decoder模型,attention模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。
下图为seq2seq模型加入了Attention注意力机制
图3. Attention注意力机制的seq2seq模型
【seq2seq的attention解码过程】
现在定义条件概率:![]()
上式 si 表示解码器 i 时刻的隐藏状态。计算公式为:
![]()
注意这里的条件概率与每个目标输出 yi相对应的内容向量 ci有关。在sea2seq模型中,只有一个语义向量C。‘s’为隐藏层输出,相当于上面提到的h。
关键问题是语义向量 C 怎么得到?
ci 是由编码时的隐藏向量序列(h1,…,hTx)按权重相加得到的。
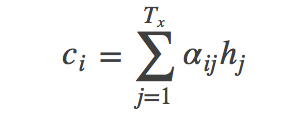
将隐藏向量序列按权重相加,表示在生成第j个输出的时候的注意力分配是不同的。αij的值越高,表示第i个输出在第j个输入上分配的注意力越多,在生成第i个输出的时候受第j个输入的影响也就越大。
这意味着在生成每个单词Yi的时候,原先都是相同的中间语义表示C会替换成根据当前生成单词而不断变化的Ci。理解AM模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci
如何得到 αij 的权重值?
由第i-1个输出隐藏状态 si−1 和输入中各个隐藏状态共同决定的,即:

si−1 先跟每个h分别计算得到一个数值,然后使用softmax函数得到i时刻的输出在Tx个输入隐藏状态中的注意力分配向量。这个分配向量也就是计算ci的权重。
图4. 分配概率(权值)的计算
图4 显示的是Attention模型在计算αij 的概率分配过程。
对于采用RNN的Decoder来说,如果要生成yi单词,在时刻i,我们是可以知道在生成Yi之前的隐层节点i时刻的输出值Hi的,而我们的目的是要计算生成Yi时的输入句子单词“Tom”、“Chase”、“Jerry”对Yi来说的注意力分配概率分布,那么可以用i时刻的隐层节点状态Hi去一一和输入句子中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(hj,Hi)来获得目标单词Yi和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。图4显示的是当输出单词为“汤姆”时刻对应的输入句子单词的对齐概率。绝大多数AM模型都是采取上述的计算框架来计算注意力分配概率分布信息,区别只是在F的定义上可能有所不同。
公式汇总: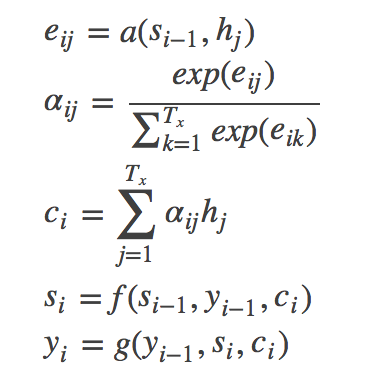
【Attention机制类别】
Attention机制大的方向可分为 Soft Attention 和 Hard Attention 。
Soft Attention通常是指以上我们描述的这种全连接(如MLP计算Attention 权重),对每一层都可以计算梯度和后向传播的模型;不同于Soft attention那样每一步都对输入序列的所有隐藏层hj(j=1….Tx) 计算权重再加权平均的方法,Hard Attention是一种随机过程,每次以一定概率抽样,以一定概率选择某一个隐藏层 hj*,在估计梯度时也采用蒙特卡罗抽样Monte Carlo sampling的方法。
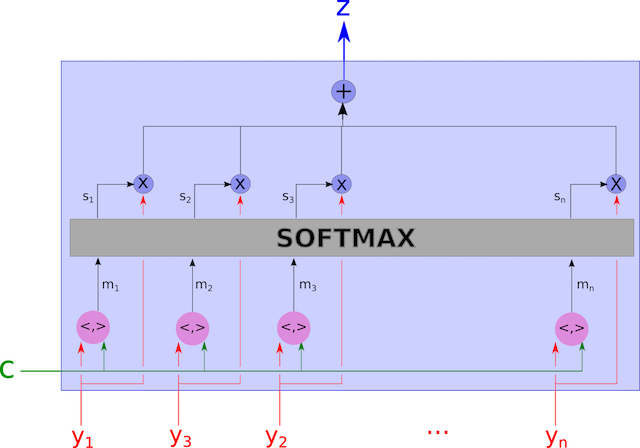
图5. Soft Attention 模型

图6. Hard Attention
考虑到计算量,attention的另一种替代方法是用强化学习(Reinforcement Learning)来预测关注点的大概位置。这听起来更像是人的注意力,这也是Recurrent Models of Visual Attention文中的作法。然而,强化学习模型不能用反向传播算法端到端训练,因此它在NLP的应用不是很广泛(我本人反而觉得这里有突破点,数学上的不可求解必然会得到优化,attention model在RL领域的应用确实非常有趣)
参考资料:http://blog.csdn.net/u014595019/article/details/52826423
http://blog.csdn.net/wuzqChom/article/details/75792501
http://blog.csdn.net/mpk_no1/article/details/72862348
http://www.deepnlp.org/blog/textsum-seq2seq-attention/
http://blog.csdn.net/malefactor/article/details/50550211
http://blog.csdn.net/xbinworld/article/details/54607525
2.2 计算机视觉中的Attention机制
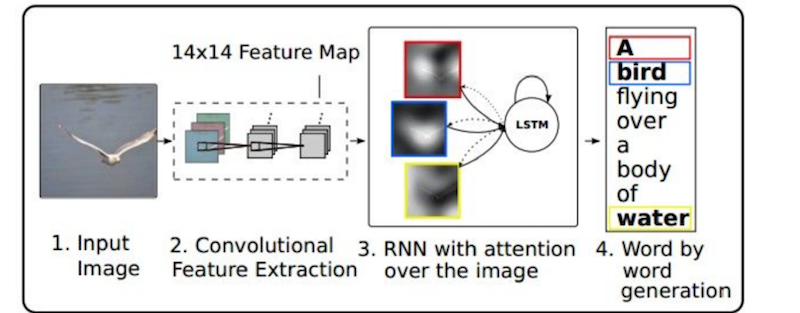
图7. 基于注意力attention的RNN模型
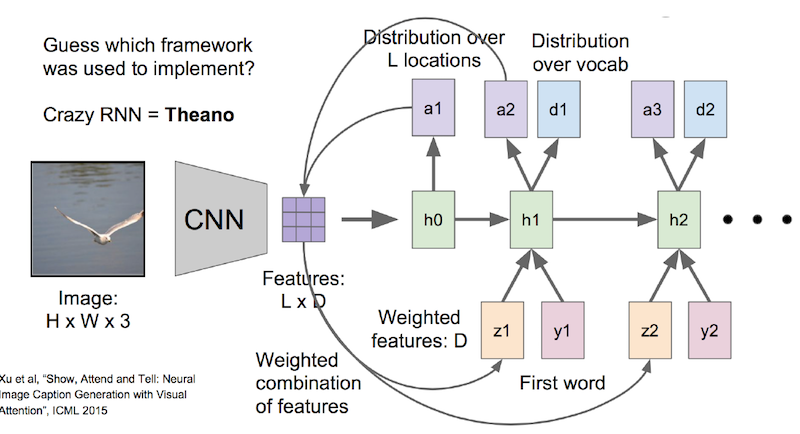
图8. 视觉中的注意力模型结构
(1)输入图片经过一系列变换后转化为 H * W * 3维的矩阵,H,W 分别为图片的高和宽度,3为RGB三通道。
(2)CNN层:经过一些列卷积层和池化之后得到 L*D的 feature map,D是这一层卷积层中神经元的个数,比如有512个。L是每个神经元中的feature map,比如是14 * 14维。那么L * D 就代表 196 * 512维的向量
(3)创建一个D * 1维的权重向量W(这个权重的最优值在后向求导的时候会算出来的,一开始可以先随便初始化一个)。拿从CNN出来的feature向量L * D 去乘以 这个权重向量W,得到的是L * 1的向量。也就是图中的h0,h0经过一个sotmax,会得到L * 1的概率,也就是说,对一个L 维的feature map(14 * 14)求出196个相对应的概率向量,就是图中的a1。
(4)a1是196维的概率向量,把它再与 L * D的feature向量相乘,求加权。也就是说,对521层神经元上的feature map都乘以一组概率,得到的是图中的z1。
这是至关重要的一步,也是注意力模型的核心,因为概率的大小重新调整了feature向量中每个值的大小。概率大的就会放更多的注意力上去,概率小的,注意力就减小了。
这个z1直接作用于第二次循环中的h1.
(5)现在来到了h1这一层,这一层的输入除了刚刚说的z1,还有原来就有的y1,和h0,y1是上一次循环的输出,h0是上一时刻的记忆。h1也会进入一个softmax的运算,输出一组概率,这组概率会再回到feature向量那里做权重加和,于是feature向量又进行了一轮的调整,再作用到了h2上,也就是我们看到的z2。h1出来生成一个概率向量外,还会输出一组每个词的概率,然后选取概率最大的那个词作为本轮循环的最终输出。(所有词以one-hot的形式维护在词典中)。
循环往复以上两步,实现了在每一轮的循环中都输入了新的feature向量,注意力也会改变。比如第一轮注意力是在bird,第二轮注意力在sea.
视觉注意力以及物体聚焦是人类视觉所特有的一种信号处理机制。人类视觉系统能够在关键场景中提取大脑反馈的关键信息,抑制无用信息。注意力机制在NLP已经取得很大成功,如RNN+CNN的图像描述系统,机器翻译等。
Attention机制在自然语言处理和计算机视觉图像领域都有着广泛的运用。神经网络中的注意力机制是从人类视觉中受到启发而来的,模拟人眼的注意力功能,集中聚焦一些关键信息而虚化或者抑制掉一些不重要信息。计算机视觉中的注意力机制,从理论上看是融合了底层卷积和高层卷积的特征,由此既能识别高分辨率中的一些细节特定区域的特征,又能感知到高层网络中的关键特征。在图像领域中, 2010年的《Examples include Learning to combine foveal glimpses with a third-order Boltzmann machine》,以及2011年的论文《Learning where to Attend with Deep Architectures for Image Tracking》上都有提及注意力attention机制的运用。
2016年和2017年CVPR顶会论文:
Wang F, Jiang M, Qian C, et al. Residual Attention Network for Image Classification[J]. 2017.
Lin T Y, Dollár P, Girshick R, et al. Feature Pyramid Networks for Object Detection[J]. 2016.
