


通配符-特殊符号-正则表达式
1.1 正则表达式:通配符知识回顾
通配符------用来匹配 查找文件 文件名
找出/oldboy 以 .txt结尾的文件
find /oldboy –type f –name “*.txt”
1.2 正则表达式:通配符和特殊符号讲解
它是shell的内置功能。
通配符(wildcard),用过DOS的应该很了解
通配符是用来匹配/查找文件名。
Linux命令基本都支持通配符:

通配符详解
测试文件的创建:
[root@oldboyedu-39 ~]# mkdir /oldboy/20170118 -p
[root@oldboyedu-39 ~]# cd /oldboy/20170118/
[root@oldboyedu-39 20170118]# touch stu{00..10}.txt oldboy{00.10}.log
[root@oldboyedu-39 20170118]# #找出当前目录下 文件名是以stu开头的
[root@oldboyedu-39 20170118]# find -type f -name "stu*"
./stu05.txt
./stu00.txt
./stu01.txt
./stu02.txt
./stu07.txt
./stu04.txt
./stu10.txt
./stu03.txt
./stu09.txt
./stu06.txt
./stu08.txt
[root@oldboyedu-39 20170118]# find -type f -name "*.txt"
./stu05.txt
./stu00.txt
./stu01.txt
./stu02.txt
./stu07.txt
./stu04.txt
./stu10.txt
./stu03.txt
./stu09.txt
./stu06.txt
./stu08.txt
[root@oldboyedu-39 20170118]# ls stu*
stu00.txt stu02.txt stu04.txt stu06.txt stu08.txt stu10.txt
stu01.txt stu03.txt stu05.txt stu07.txt stu09.txt
[root@oldboyedu-39 20170118]# find -type f -name "stu*.txt"
./stu05.txt
./stu00.txt
./stu01.txt
./stu02.txt
./stu07.txt
./stu04.txt
./stu10.txt
./stu03.txt
./stu09.txt
./stu06.txt
./stu08.txt
[root@oldboyedu-39 20170118]# ###找出当前目录下文件名中包含(只要有就行)oldboy的文件 ----模糊查找
[root@oldboyedu-39 20170118]# find -type f -name "*oldboy*"
./oldboy07.log
./oldboy09.log
./oldboy08.log
./oldboy03.log
./oldboy02.log
./oldboy10.log
./oldboy06.log
./oldboy04.log
./oldboy01.log
./oldboy05.log
./oldboy00.log
*所有 通配符符号-----查找文件
以stu开头的文件
以.txt结尾的文件
文件中包含oldboy
生成序列: {}
[root@oldboyedu-39 20170118]# echo {a..z}
a b c d e f g h i j k l m n o p q r s t u v w x y z
[root@oldboyedu-39 20170118]# echo {1..9}
1 2 3 4 5 6 7 8 9
[root@oldboyedu-39 20170118]# #生成stu1---stu10
[root@oldboyedu-39 20170118]# echo stu{1..10}
stu1 stu2 stu3 stu4 stu5 stu6 stu7 stu8 stu9 stu10
[root@oldboyedu-39 20170118]# echo stu{1..10}.txt
stu1.txt stu2.txt stu3.txt stu4.txt stu5.txt stu6.txt stu7.txt stu8.txt stu9.txt stu10.txt
[root@oldboyedu-39 20170118]# echo stu{1..10}{a..z}
stu1a stu1b stu1c stu1d stu1e stu1f stu1g stu1h stu1i ...
备份:
[root@oldboyedu-39 20170118]# ###生成无规律的
[root@oldboyedu-39 20170118]# echo {1,5,100}
1 5 100
[root@oldboyedu-39 20170118]# echo {1..5}
1 2 3 4 5
[root@oldboyedu-39 20170118]# echo {1,2,3,4,5}
1 2 3 4 5
[root@oldboyedu-39 20170118]# echo A{B,C}
AB AC
[root@oldboyedu-39 20170118]# echo A{,C}
A AC
[root@oldboyedu-39 20170118]# echo oldboy.txt{,.bak}
oldboy.txt oldboy.txt.bak
[root@oldboyedu-39 20170118]# cp oldboy
oldboy00.log oldboy02.log oldboy04.log oldboy06.log oldboy08.log oldboy10.log
oldboy01.log oldboy03.log oldboy05.log oldboy07.log oldboy09.log
[root@oldboyedu-39 20170118]# cp oldboy01.log {,.bak}
等差创建
[root@oldboyedu-39 20170118]# echo {1..10}
1 2 3 4 5 6 7 8 9 10
[root@oldboyedu-39 20170118]# echo {1..10..2}
1 3 5 7 9
[root@oldboyedu-39 20170118]# echo {a..z..2}
a c e g i k m o q s u w y
1.3 正则表达式:通配符合特殊符号讲解
| && | 并且,前一个命令执行成功之后在执行后面的命令重启某一块网卡的时候 |
|---|---|
| >> | 标准输出,追加重定向,把内容追加到文件的最后一行 |
| > | 重定向 危险 先把文件的内容清空 把内容追到文件的最后一行 |
| / | 根/etc/hosts 路径分隔符号 |
| $LANG 取出变量里面的内容. | |
| . | 当前目录 |
| .. | 上一级目录 |
| 家目录 | |
| | | 管道(或者)[正则表达式egrep] |
| # | 注释 |
1.4 常用通配符及单引号,双引号,不加引号的区别
单引号-所见即所得。
[root@oldbouedu-39 20170118]# echo '$LANG $(which mkdir) {a..z}'
$LANG $(which mkdir) {a..z}
双引号-解析特殊符号,特殊符号有了原本的特殊意思
[root@oldbouedu-39 20170118]# echo "$LANG $(which mkdir) {a..z}"
en_US.UTF-8 /bin/mkdir {a..z}
不加引号-和双引号类似,但是支持通佩服符
[root@oldbouedu-39 20170118]# echo $LANG $(which mkdir) {a..z}
en_US.UTF-8 /bin/mkdir a b c d e f g h i j k l m n o p q r s t u v w x y z
1.5 基础正则表达式
-
使用简单的符号 ^ $ . * + ......表示字母 文本
-
省事 提高我们效率
egrep "oldboy[0-9]+" oldboy.txt
综合:
①正则表达式就是为了出来大量的文字,文本,字符串而定义一套规则和方法.
②通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串.
③Linux正则表达式一般以行为单位处理的.
简单说:
⊙为处理大量文本,字符串而定义的一套规则和方法
⊙以行为单位出来,一次处理一行
###正则表达式是一种描述一组字符串的模式,类似数学表达式,通过各种操作符组成更小的表达式.正则表达式-regular expression
正则表达式与通配符的区别
通配符是用来找文件,Linux下面大部分命令都可以用 ls *.txt rm *.txt cp *.txt /tmp
正则表达式 用了找文本 文字 (文件内容) 常用的地方linux grep sed awk
正则不表达式使用注意事项:
1.正则表达式是按照行来处理的
2.grep/egrep使用高亮带颜色
cat >>/etc/profile<<EOF
alias egerp='egrep --color=auto'
alias grep='grep --color=auto'
EOF
[root@oldboyedu-39 ~]# source /etc/profile
基础正则表达式:
^ $ . * [] [^]
扩展正则表达式:
+ | ? {} ()
基本正则表达式:(查找man grep 查找REGULAR)
创建测试环境:
cat>>oldboy.txt<<EOF
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my QQ num is 49000448.
not 4900000448.
my god,i am not oldboy,but OLDBOY!
EOF
以^什么的开头:
[root@oldbouedu-39 ~]# grep "^m" oldboy.txt
my blog is http://oldboy.blog.51cto.com
my QQ num is 49000448.
my god,i am not oldboy,but OLDBOY!
[root@oldbouedu-39 ~]# grep -n "^m" oldboy.txt
6:my blog is http://oldboy.blog.51cto.com
8:my QQ num is 49000448.
11:my god,i am not oldboy,but OLDBOY!
[root@oldbouedu-39 ~]# \grep -n "^m" oldboy.txt
6:my blog is http://oldboy.blog.51cto.com
8:my QQ num is 49000448.
11:my god,i am not oldboy,but OLDBOY!
[root@oldbouedu-39 ~]# \grep -n "^m" oldboy.txt
6:my blog is http://oldboy.blog.51cto.com
8:my QQ num is 49000448.
11:my god,i am not oldboy,but OLDBOY!
[root@oldbouedu-39 ~]# grep -n "^m" oldboy.txt
6:my blog is http://oldboy.blog.51cto.com
8:my QQ num is 49000448.
11:my god,i am not oldboy,but OLDBOY!
以什么的结尾$
[root@oldbouedu-39 ~]# cat -A oldboy.txt
I am oldboy teacher!$
I teach linux.$
$
$
I like badminton ball ,billiard ball and chinese chess!$
my blog is http://oldboy.blog.51cto.com$
$
my QQ num is 49000448.$
$
not 4900000448.$
my god,i am not oldboy,but OLDBOY!$
[root@oldbouedu-39 ~]# grep -n "m$" oldboy.txt
6:my blog is http://oldboy.blog.51cto.com
空行 这一行:
[root@oldbouedu-39 ~]# grep "^$" oldboy.txt
[root@oldbouedu-39 ~]# grep -n "^$" oldboy.txt
3:
4:
7:
9:
[root@oldbouedu-39 ~]# cat -An oldboy.txt
1 I am oldboy teacher!$
2 I teach linux.$
3 $
4 $
5 I like badminton ball ,billiard ball and chinese chess!$
6 my blog is http://oldboy.blog.51cto.com$
7 $
8 my QQ num is 49000448.$
9 $
10 not 4900000448.$
11 my god,i am not oldboy,but OLDBOY!$
以.(点)为开头的任意字符:
[root@oldbouedu-39 ~]# grep "." oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my QQ num is 49000448.
not 4900000448.
my god,i am not oldboy,but OLDBOY!
[root@oldbouedu-39 ~]# grep -o "." oldboy.txt
特殊字符的转意用法:
[root@oldbouedu-39 ~]# grep "\.$" oldboy.txt
I teach linux.
my QQ num is 49000448.
not 4900000448.
1.6 扩展正则表达式:
[root@oldbouedu-39 ~]# grep -n "^m.*m$" oldboy.txt
6:my blog is http://oldboy.blog.51cto.com
1.7 扩展正则表达式2
[abc] [0-9] [\.,/]
匹配字符集合内的任意一个字符a或b或c;
[root@oldbouedu-39 ~]# grep "[abc]" oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my god,i am not oldboy,but OLDBOY!
[root@oldbouedu-39 ~]# grep "[a-z]" oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
my QQ num is 49000448.
not 4900000448.
my god,i am not oldboy,but OLDBOY!
[root@oldbouedu-39 ~]# grep "[A-Z]" oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my QQ num is 49000448.
my god,i am not oldboy,but OLDBOY!
[root@oldbouedu-39 ~]# grep "[0-9]" oldboy.txt
my blog is http://oldboy.blog.51cto.com
my QQ num is 49000448.
not 4900000448.
以不是mn 开头的行
[root@oldbouedu-39 ~]# grep "^[mn]" oldboy.txt
my blog is http://oldboy.blog.51cto.com
my QQ num is 49000448.
not 4900000448.
my god,i am not oldboy,but OLDBOY!
[root@oldbouedu-39 ~]# grep "^[^mn]" oldboy.txt
I am oldboy teacher!
I teach linux.
I like badminton ball ,billiard ball and chinese chess!
1.8 扩展正则表达式ERE
| 特殊字符 | 含义与例子 |
|---|---|
| + | 重复前一个字符一次货一次以上 |
| 前面一个字符连续出现一个或多个,可以取出连续的前一个字符。[a-z] | |
| [root@oldbouedu-39 data]# cat >>a.txt<<EOF |
good
gd
goood
[root@oldbouedu-39 data]# grep -E "go+d" a.txt
good
goood
[root@oldbouedu-39 oldboy]# grep "0+" oldboy.txt
[root@oldbouedu-39 oldboy]# grep "0" oldboy.txt
my QQ num is 49000448.
not 4900000448.
[root@oldbouedu-39 oldboy]# grep -o "0" oldboy.txt
0
0
0
0
0
0
0
0
[root@oldbouedu-39 oldboy]# grep -E "0+" oldboy.txt
my QQ num is 49000448.
not 4900000448.
[root@oldbouedu-39 oldboy]# grep -oE "0+" oldboy.txt
000
00000
[root@oldbouedu-39 oldboy]# egrep "0+" oldboy.txt
my QQ num is 49000448.
not 4900000448.
[root@oldbouedu-39 oldboy]# egrep -o "0+" oldboy
[root@oldbouedu-39 oldboy]# egrep -o "0+" oldboy.txt
000
00000 |
| | | 表示或者 同时过滤多个字符
[root@oldbouedu-39 oldboy]#
[root@oldbouedu-39 oldboy]# grep -E "3306|1521" /etc/services
mysql 3306/tcp # MySQL
mysql 3306/udp # MySQL
ncube-lm 1521/tcp # nCube License Manager
ncube-lm 1521/udp # nCube License Manager
[root@oldbouedu-39 oldboy]# grep -E "3306|1521|873" /etc/services
rsync 873/tcp # rsync
rsync 873/udp # rsync
mysql 3306/tcp # MySQL
mysql 3306/udp # MySQL
ncube-lm 1521/tcp # nCube License Manager
ncube-lm 1521/udp # nCube License Manager
fjmpjps 1873/tcp # Fjmpjps
fjmpjps 1873/udp # Fjmpjps
fagordnc 3873/tcp # fagordnc
fagordnc 3873/udp # fagordnc
dtp-net 8732/udp # DASGIP Net Services
ibus 8733/tcp # iBus
ibus 8733/udp # iBus
dxspider 8873/tcp # dxspider linking protocol
dxspider 8873/udp # dxspider linking protocol |
| () | 反向引用
[root@oldboyedu-39 ~]# cat >a.log<<EOF
good
glad
gd
god
goood
EOF
[root@oldboyedu-39 ~]# egrep "g(oo|la)d" a.log
good
glad |
| {} | a{n,m}前面一个字符连续出现至少n次,最多出现m次 |
| ? | |
1.9 元字符
元字符是一种Perl风格的正则表达式,只有一部分文本处理工具支持它,并不是所有的文本处理工具都支持。
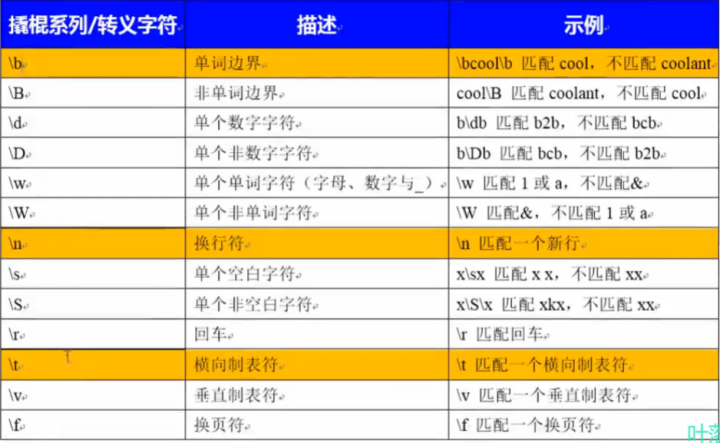
[root@oldbouedu-39 oldboy]# grep "\boldboy\b" q.txt
oldboy oldboy
练习题:取IP地址方法:
sed方法:
[root@oldbouedu-39 oldboy]# ifconfig eth0|sed -n '2p'|sed 's#^.*dr:##g'|sed 's# B.*$##g'
10.0.0.200
sed -r 反向引用:
[root@oldbouedu-39 oldboy]# ifconfig eth0|sed -n '2p'|sed -r 's#^.*addr:(.*)Bc.*#\1#g'
10.0.0.200
sed + 正则表达式的应用:
[root@oldbouedu-39 oldboy]# stat /etc/hosts|sed -n '4p'|sed -r 's#^.*ss: \((.*)\/-rw.*$#\1#g'
0644
[root@oldbouedu-39 ~]# stat /etc/hosts|awk 'NR==4'|sed -r 's#^.*s: \(0(.*)/-rw.*$#\1#g'
644
awk方法一:
[root@oldbouedu-39 oldboy]# ifconfig eth0|awk -F "[ :]+" 'NR==2{print $4}'
10.0.0.200
awk 方法二:
[root@oldbouedu-39 oldboy]# stat /etc/hosts|awk -F "[ ]+" 'NR==4{print $2}'
(0644/-rw-r--r--)
[root@oldbouedu-39 oldboy]# stat /etc/hosts|awk -F "[ (]+" 'NR==4{print $2}'
0644/-rw-r--r--)
[root@oldbouedu-39 oldboy]# stat /etc/hosts|awk -F "[ (/]+" 'NR==4{print $2}'
0644

 浙公网安备 33010602011771号
浙公网安备 33010602011771号