



《BI那点儿事》ETL中的关键技术
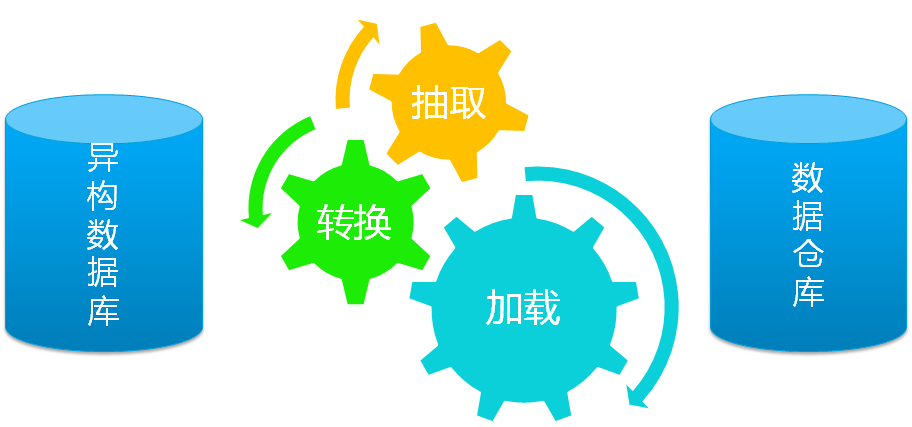
ETL(Extract/Transformation/Load)是BI/DW的核心和灵魂,按照统一的规则集成并提高数据的价值,是负责完成数据从数据源向目标数据仓库转化的过程,是实施数据仓库的重要步骤。
ETL过程中的主要环节就是数据抽取、数据转换和加工、数据装载。为了实现这些功能,各个ETL工具一般会进行一些功能上的扩充,例如工作流、调度引擎、规则引擎、脚本支持、统计信息等。
数据抽取
数据抽取是从数据源中抽取数据的过程。实际应用中,数据源较多采用的是关系数据库。从数据库中抽取数据一般有以下几种方式。
(1)全量抽取 全量抽取类似于数据迁移或数据复制,它将数据源中的表或视图的数据原封不动的从数据库中抽取出来,并转换成自己的ETL工具可以识别的格式。全量抽取比较简单。
(2)增量抽取 增量抽取只抽取自上次抽取以来数据库中要抽取的表中新增或修改的数据。在ETL使用过程中。增量抽取较全量抽取应用更广。如何捕获变化的数据是增量抽取的关键。对捕获方法一般有两点要求:准确性,能够将业务系统中的变化数据按一定的频率准确地捕获到;性能,不能对业务系统造成太大的压力,影响现有业务。目前增量数据抽取中常用的捕获变化数据的方法有:
a.触发器:在要抽取的表上建立需要的触发器,一般要建立插入、修改、删除三个触发器,每当源表中的数据发生变化,就被相应的触发器将变化的数据写入一个临时表,抽取线程从临时表中抽取数据,临时表中抽取过的数据被标记或删除。触发器方式的优点是数据抽取的性能较高,缺点是要求业务表建立触发器,对业务系统有一定的影响。
b.时间戳:它是一种基于快照比较的变化数据捕获方式,在源表上增加一个时间戳字段,系统中更新修改表数据的时候,同时修改时间戳字段的值。当进行数据抽取时,通过比较系统时间与时间戳字段的值来决定抽取哪些数据。有的数据库的时间戳支持自动更新,即表的其它字段的数据发生改变时,自动更新时间戳字段的值。有的数据库不支持时间戳的自动更新,这就要求业务系统在更新业务数据时,手工更新时间戳字段。同触发器方式一样,时间戳方式的性能也比较好,数据抽取相对清楚简单,但对业务系统也有很大的倾入性(加入额外的时间戳字段),特别是对不支持时间戳的自动更新的数据库,还要求业务系统进行额外的更新时间戳操作。另外,无法捕获对时间戳以前数据的delete和update操作,在数据准确性上受到了一定的限制。
c.全表比对:典型的全表比对的方式是采用MD5校验码。ETL工具事先为要抽取的表建立一个结构类似的MD5临时表,该临时表记录源表主键以及根据所有字段的数据计算出来的MD5校验码。每次进行数据抽取时,对源表和MD5临时表进行MD5校验码的比对,从而决定源表中的数据是新增、修改还是删除,同时更新MD5校验码。MD5方式的优点是对源系统的倾入性较小(仅需要建立一个MD5临时表),但缺点也是显而易见的,与触发器和时间戳方式中的主动通知不同,MD5方式是被动的进行全表数据的比对,性能较差。当表中没有主键或唯一列且含有重复记录时,MD5方式的准确性较差。
d.日志对比:通过分析数据库自身的日志来判断变化的数据。Oracle的改变数据捕获(CDC,ChangedDataCapture)技术是这方面的代表。CDC特性是在Oracle9i数据库中引入的。CDC能够帮助你识别从上次抽取之后发生变化的数据。利用CDC,在对源表进行insert、update或delete等操作的同时就可以提取数据,并且变化的数据被保存在数据库的变化表中。这样就可以捕获发生变化的数据,然后利用数据库视图以一种可控的方式提供给目标系统。CDC体系结构基于发布者/订阅者模型。发布者捕捉变化数据并提供给订阅者。订阅者使用从发布者那里获得的变化数据。通常,CDC系统拥有一个发布者和多个订阅者。发布者首先需要识别捕获变化数据所需的源表。然后,它捕捉变化的数据并将其保存在特别创建的变化表中。它还使订阅者能够控制对变化数据的访问。订阅者需要清楚自己感兴趣的是哪些变化数据。一个订阅者可能不会对发布者发布的所有数据都感兴趣。订阅者需要创建一个订阅者视图来访问经发布者授权可以访问的变化数据。CDC分为同步模式和异步模式,同步模式实时的捕获变化数据并存储到变化表中,发布者与订阅都位于同一数据库中。异步模式则是基于Oracle的流复制技术。
ETL处理的数据源除了关系数据库外,还可能是文件,例如txt文件、excel文件、xml文件等。对文件数据的抽取一般是进行全量抽取,一次抽取前可保存文件的时间戳或计算文件的MD5校验码,下次抽取时进行比对,如果相同则可忽略本次抽取。
数据转换和加工
从数据源中抽取的数据不一定完全满足目的库的要求,例如数据格式的不一致、数据输入错误、数据不完整等等,因此有必要对抽取出的数据进行数据转换和加工。 数据的转换和加工可以在ETL引擎中进行,也可以在数据抽取过程中利用关系数据库的特性同时进行。
(1)ETL引擎中的数据转换和加工
ETL引擎中一般以组件化的方式实现数据转换。常用的数据转换组件有字段映射、数据过滤、数据清洗、数据替换、数据计算、数据验证、数据加解密、数据合并、数据拆分等。这些组件如同一条流水线上的一道道工序,它们是可插拔的,且可以任意组装,各组件之间通过数据总线共享数据。 有些ETL工具还提供了脚本支持,使得用户可以以一种编程的方式定制数据的转换和加工行为。
(2)在数据库中进行数据加工
关系数据库本身已经提供了强大的SQL、函数来支持数据的加工,如在SQL查询语句中添加where条件进行过滤,查询中重命名字段名与目的表进行映射,substr函数,case条件判断等等。
相比在ETL引擎中进行数据转换和加工,直接在SQL语句中进行转换和加工更加简单清晰,性能更高。对于SQL语句无法处理的可以交由ETL引擎处理。
数据装载
将转换和加工后的数据装载到目的库中通常是ETL过程的最后步骤。装载数据的最佳方法取决于所执行操作的类型以及需要装入多少数据。当目的库是关系数据库时,一般来说有两种装载方式:
(1)直接SQL语句进行insert、update、delete操作。
(2)采用批量装载方法,如bcp、bulk、关系数据库特有的批量装载工具或api。 大多数情况下会使用第一种方法,因为它们进行了日志记录并且是可恢复的。但是,批量装载操作易于使用,并且在装入大量数据时效率较高。使用哪种数据装载方法取决于业务系统的需要。
常见的数据质量问题
|
数据质量 |
问题 |
数据问题示例 |
|
格式 |
值是否按照一致的格式标准? |
电话号码 # 可能显示为 xxxxxxxxxx, (xxx) xxx-xxxx, 1.xxx.xxx.xxxx, 等. |
|
标准 |
数据元素是否一致性定义和理解 ? |
一个系统性别代码 = M, F, U ,另一个系统性别代码 = 0, 1, 2 |
|
一致性 |
值是否代表统一的含义? |
营业额是否总是显示为美元还是也有可能为? |
|
完整性 |
是否所有必须的数据都包含? |
20% 的顾客的 last name 为空, |
|
精确性 |
数据是否准确地反映现实或可验证的数据来源? |
供应商显示为‘活动’,但是其实6年前已经和它没有业务往来。 |
|
有效性 |
数据值是否在接受的范围内? |
薪水值应该在 60,000-120,000 |
|
重复性 |
数据多次出现 |
John Ryan 和 Jack Ryan 都在系统中出现了 – 他们是同一个人吗? |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号