


第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
学习进度
Python网络爬虫与信息提取学习笔记
第一周:
Requests库入门:
Requests库的安装:在命令提示符界面输入:pip install requests
Requests库有7个主要的方法,分别是:
- requests.request() : 构造一个请求,支撑以下各方法的基础方法;
- requests.get() : 获取HTML网页的主要方法,对应于HTTP的GET;
- requests.head() : 获取HTML网页头信息的方法,对应于HTTP的HEAD;
- requests.post() : 向HTML网页提交POST请求的方法,对应于HTTP的POST;
- requests.put() : 向HTML网页提交PUT请求的方法,对应于HTTP的PUT;
- requests.patch() : 向HTML网页提交局部修改的请求,对应于HTTP的PATCH;
- requests.delete() : 向HTML页面提交删除请求,对应于HTTP的DELETE。
Requests库有2个重要对象,分别是Response对象和Request对象。
Response对象包含服务器返回的所有信息,也包含请求的Request信息。Response对象的属性有:
- r.status_code :HTTP请求的返回状态,200表示连接成功。
- r.text :HTTP响应内容的字符串形式,即url对应的页面内容。
- r.encoding :从HTTP header中猜测的响应内容编码方式。
- r.apparent_encoding:从内容中分析出的响应内容编码方式(备选编码方式)。
- r.content:HTTP响应内容的二进制形式。
爬取网页的通用代码框架:
import requests
def getHTMLText(url): try: r = requests.get(url,timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "产生异常"
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))
网络爬虫的Robots协议:
Robots Exclusion Standard,网络爬虫排除标准
作用:网站告知网络爬虫哪些页面可以爬取,哪些不行。
形式:在网站根目录下的robots.txt文件
例如:京东的Robots协议
http://www.jd.com/robots.txt
Robots协议的使用
网络爬虫:自动或人工识别robots.txt,再进行内容爬取。
约束性:Robots协议是建议但非约束性的,网络爬虫可以不遵守,但存在法律风险。
对Robots协议的理解
- 爬取网页/玩转网页:访问量很小时可以遵守;访问量较大时建议遵守。
- 爬取网站/爬取系列网站:非商业且偶尔时建议遵守;商业利益时必须遵守。
- 爬取全网:必须遵守。
Requests库网络爬取实战
实例1:京东商品页面爬取
import requests
url = "http://item.jd.com/2967929.html"
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
实例2:亚马逊商品页面爬取
import requests url = "http://www.amazon.cn/gp/product/B01M8L5Z3Y" try:
kv = {'user-agent':'Mozilla/5.0'} r = requests.get(url,headers=kv) r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[1000:2000]) except: print("爬取失败")
实例3:百度收索全代码
import requests
keyword = "Python" url = "http://item.jd.com/2967929.html" try:
kv = {'wd':keyword} r = requests.get(url,params=kv) r.raise_for_status() r.encoding = r.apparent_encoding print(len(r.text)) except: print("爬取失败")
实例4:网络图片的爬取
import requests import os
url = "http://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg"
root = "D://pics//"
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(utl)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
实例5:IP地址归属地的自动查询
import requests
url = "http://m.ip138.com/ip.asp?ip="
try:
r = requests.get(url+'202.204.80.112')
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")
第二周:
BeautifulSoup库入门
BeautifulSoup库安装:在命令提示符页面输入pip install beautifulsoup4 。
BeautifulSoup库的理解:
BeautifulSoup可=库是解析、遍历、维护“标签树”的功能库


BeautifulSoup类的基本元素:
- Tag:标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾;
- Name:标签的名字,用<p>...</p>的名字是'p',格式:<tag>.name
- Attributes:标签的属性,字典形式组织,格式:<tag>.attrs
- NavigableString:标签内非属性字符串,<>...</>中字符串,格式:<tag>.string
- Comment:标签内字符串的注释部分,一种特殊的Comment类型

基于bs4库的HTML内容遍历方法:
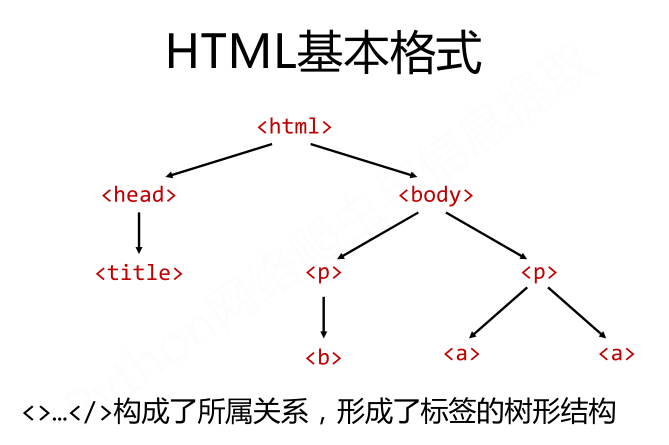
标签树的下行遍历:
- .contents:子节点的列表,将<tag>所有儿子节点存入列表;
- .children:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点;
- .descendants:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历。
![]()

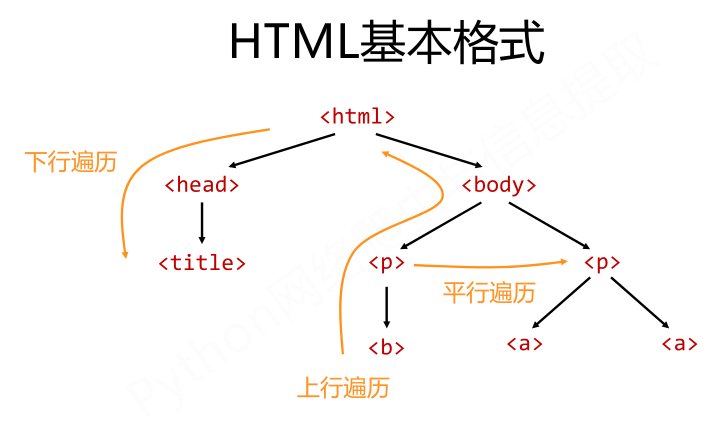
标签树的上行遍历:
- .parent:节点的父亲标签;
- .parents:节点先辈标签的迭代类型,用于循环遍历先辈节点。

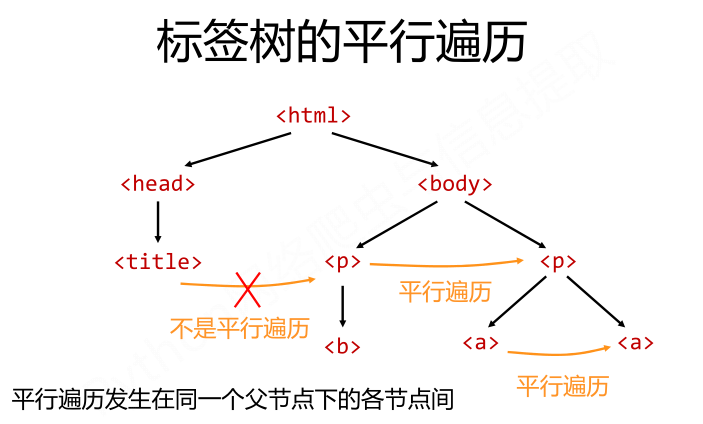
标签树的平行遍历:
- .next_sibling:返回按照HTML文本顺序的下一个平行节点标签;
- .previous_sibling:返回按照HTML文本顺序的上一个平行节点标签;
- .next_siblings:迭代类型,返回按照HTML文本顺序的后续所有平行节点标签;
- .previous_siblings:迭代类型,返回按照HTML文本顺序的前序所有平行节点标签。


bs4库的prettify()方法可以为HTML文本<>及其内容增加更多'\n',用法是:<tag>.prettify()

BeautifulSoup库入门总结:

信息标记与提取方法:
信息标记的好处:
- 标记后的信息可形成信息组织结构,增加了信息维度;
- 标记的结构与信息一样具有重要价值;
- 标记后的信息可用于通信、存储或展示;
- 标记后的信息更利于程序理解和运用。
信息标记的三种形式:
- XML
![]()
![]()
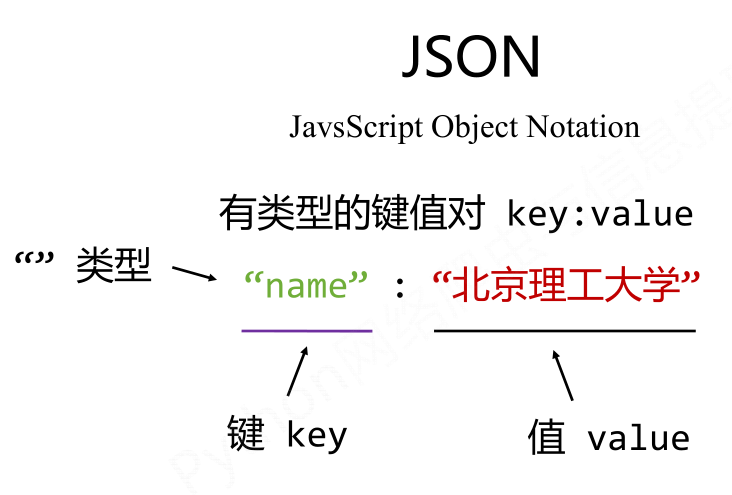
- JSON
![]()
![]()
![]()
![]()
![]()
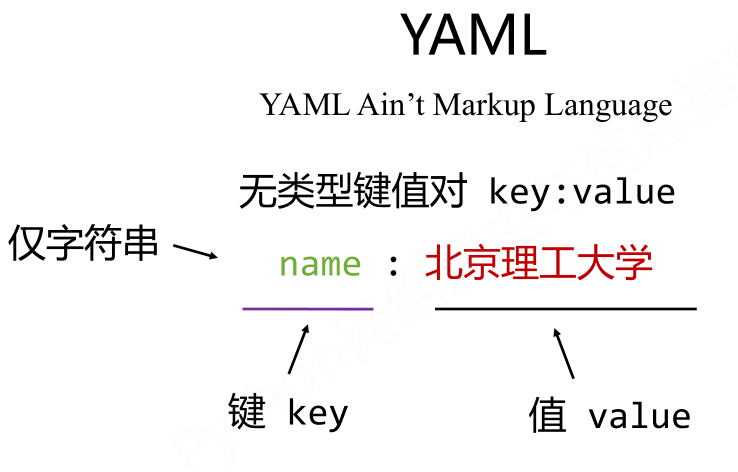
- YAML
![]()










三种信息标记形式的比较:
- XML:最早的通用信息标记语言,可扩展性好,但繁琐;
- JSON:信息有类型,适用程序处理(JS),较XML简洁;
- YAML:信息无类型,文本信息比例最高,可读性好。
三种信息标记形式适用场景的比较:
- XML:Internet上的信息交互与传递;
- JSON:移动应用云端和节点的信息通讯,无注释;
- YAML:各类系统的配置文件,有注释易读。
信息提取:从标记后的信息中提取所关注的内容


融合方法:
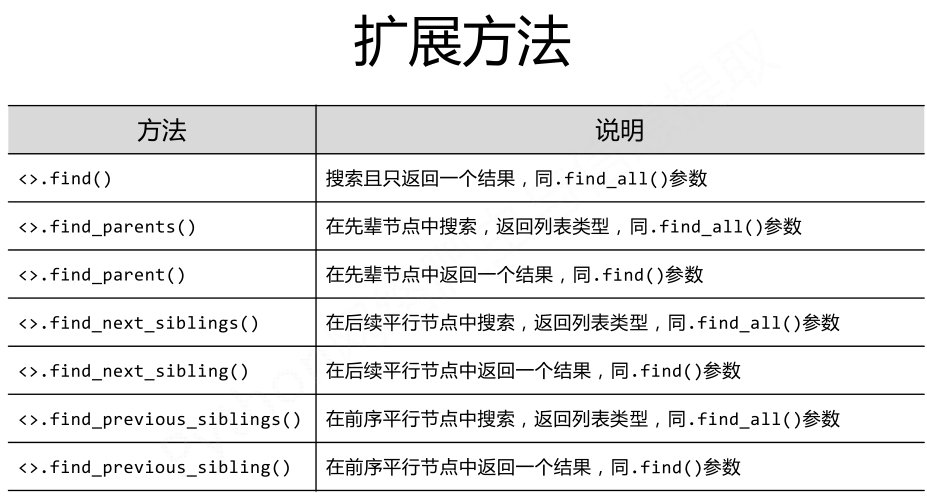
基于bs4库的HTML内容查找方法:
<>.find_all(name,attrs,recursive,string,**kwargs)
返回一个列表类型,存储查找的结果;
.name:对标签名称的检索字符串;
.attrs:对标签属性值的检索字符串,可标注属性检索;
.recursive:是否对子孙全部检索,默认True;
.string:<>...</>中字符串区域的检索字符串。
<tag>(..) 等价于 <tag>.find_all(..)
soup(..) 等价于 soup.find_all(..)
实例:中国大学排名定向爬虫
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'#这里需要注意,若运行不了,建议更新下最新的url链接
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()

第三周:
正则表达式入门:
正则表达式是用来简洁表达一组字符串的表达式;是一种通用的字符串表达框架。
正则表达式在文本处理器中十分常用:表达文本类型的特征(病毒、入侵等);同时查找或替换一组字符串;匹配字符串的全部或部分(最主要应用在字符串匹配中)等。
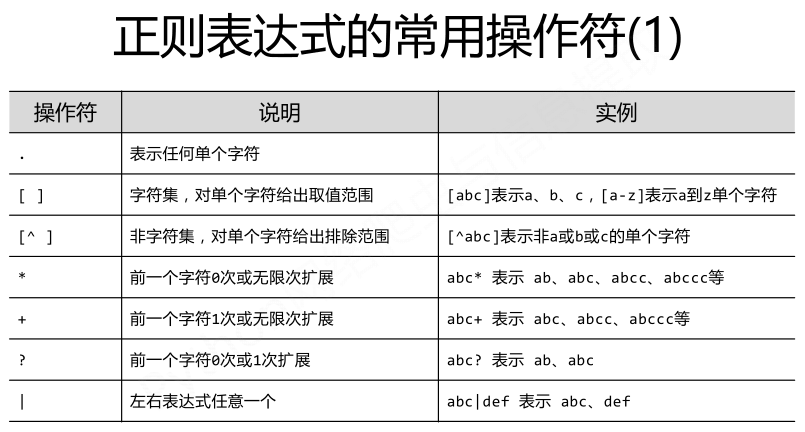
正则表达式的语法:
正则表达式语法由字符和操作符构成,常用的操作符如下图所示:
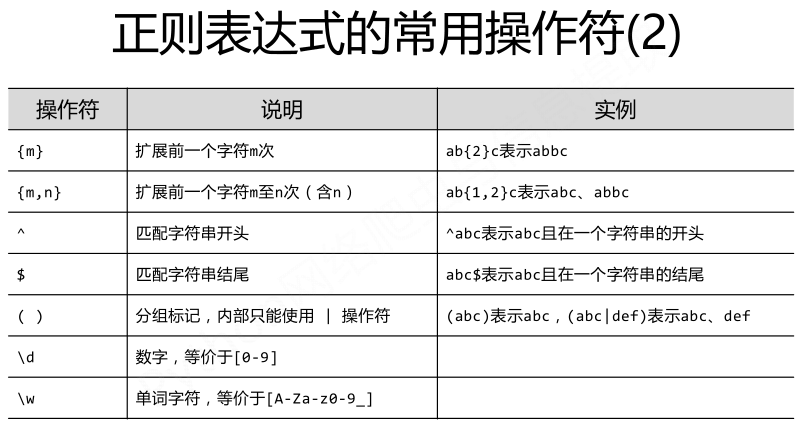
经典正则表达式实例:

re库介绍:
re库是Python的标准库,主要用于字符串匹配。
调用方式:import re
正则表达式的表示类型:
raw string类型(原生字符串类型)
re库采用raw string类型表达式正则表达式,表示为:r'text'
raw string是不包含对转义符再次转义的字符串
re库也可以采用string类型表示正则表达式,但更繁琐。建议当正则表达式包含转义符时,使用raw string.
re库主要功能函数:

第四周:
Scrapy爬虫框架
Scrapy的安装:打开命令提示符输入 pip install scrapy。
Scrapy爬虫框架结构:
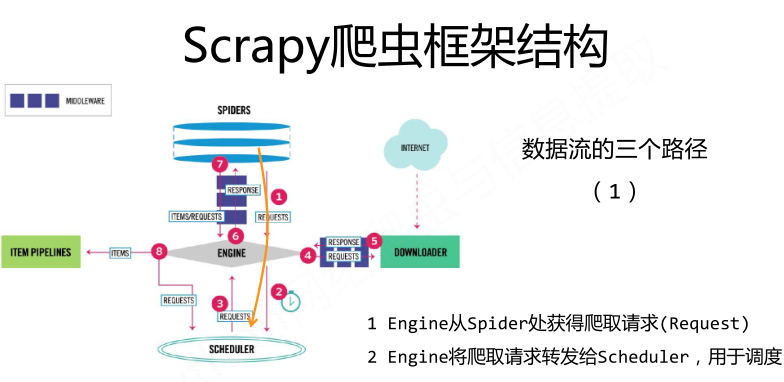
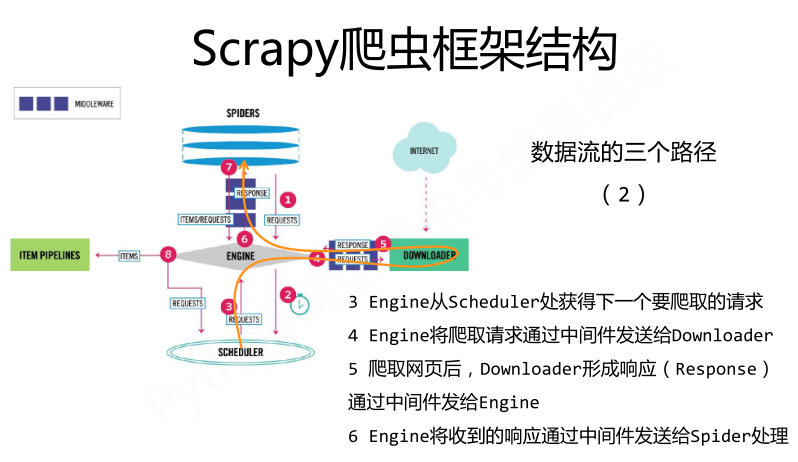
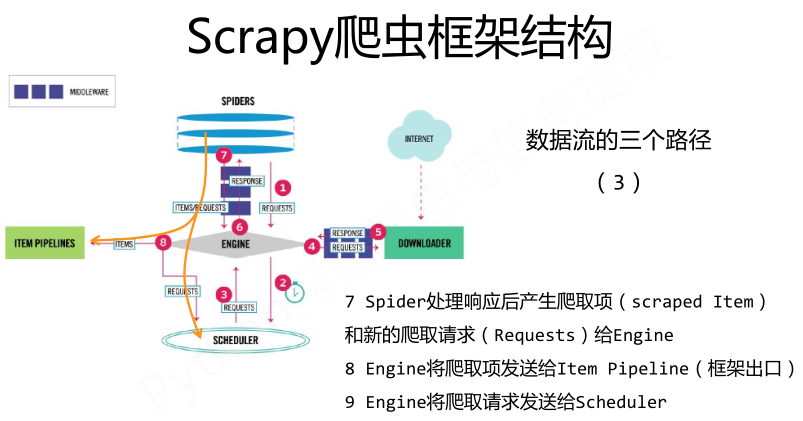
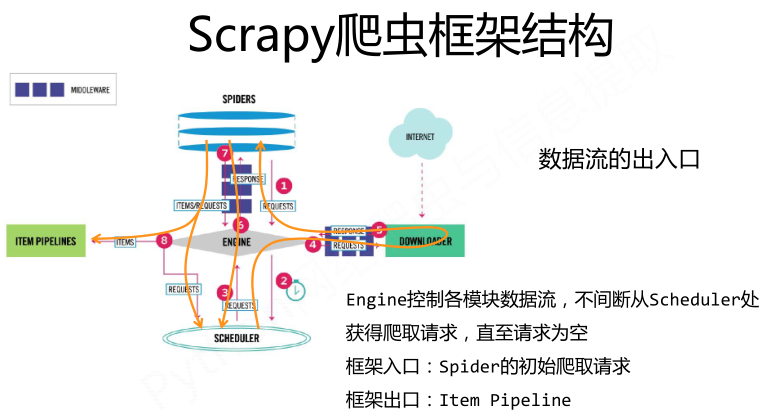
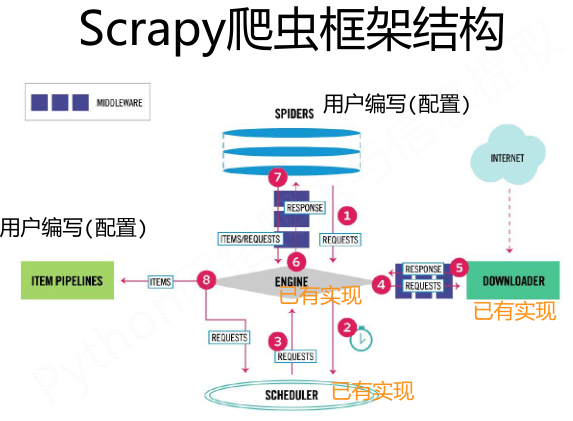
requests库和Scrapy爬虫的比较:
相同点:
两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线;
两者可用性都好,文档丰富,入门简答;
两者都没有处理js、提交表单、应对验证码等功能(可扩展)。
不同点:

Scrapy命令行:
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行。在Win下,启动cmd控制台:

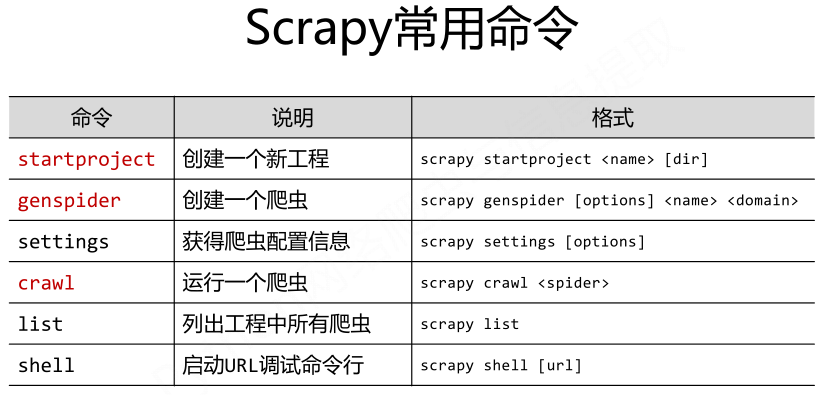
为什么Scrapy采用命令行创建和运行爬虫?
命令行更容易自动化,适合脚本控制,本质上,Scrapy是给程序员用的,功能(而不是界面)更重要。
Scrapy爬虫基本使用:
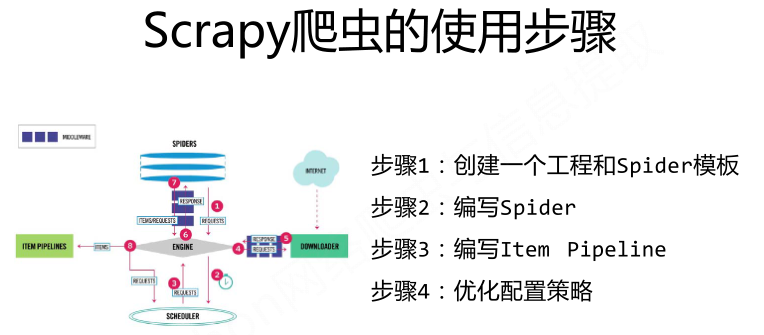
步骤1:建立一个Scrapy爬虫工程。
Scrapy startproject python123demo


步骤2:在工程中产生一个Scrapy爬虫
进入工程目录,然后执行如下命令:
scrapy genspider demo python123.io
该命令的作用:
(1)生成一个名词为demo的spider;
(2)在spiders目录下增加代码文件demo.py。

步骤3:配置产生的spider爬虫

步骤4:运行爬虫,获取网页
在命令行下,执行如下命令:
scrapy crawl demo
demo爬虫被执行,捕获页面存储在demo.html。
yield关键字:


为何要有生成器?
生成器相比一次列出所有内容的优势:
(1)更节省存储空间;
(2)响应更迅速;
(3)使用更灵活。
Scrapy爬虫的数据类型:
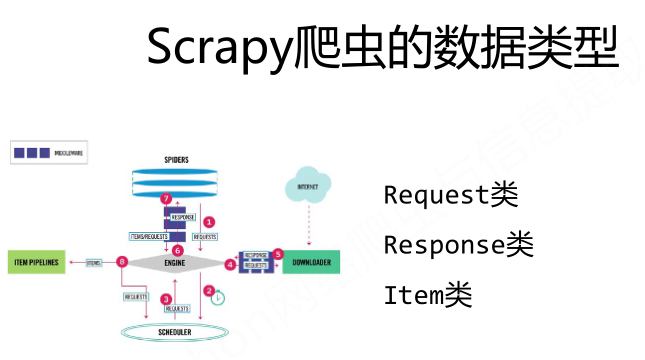



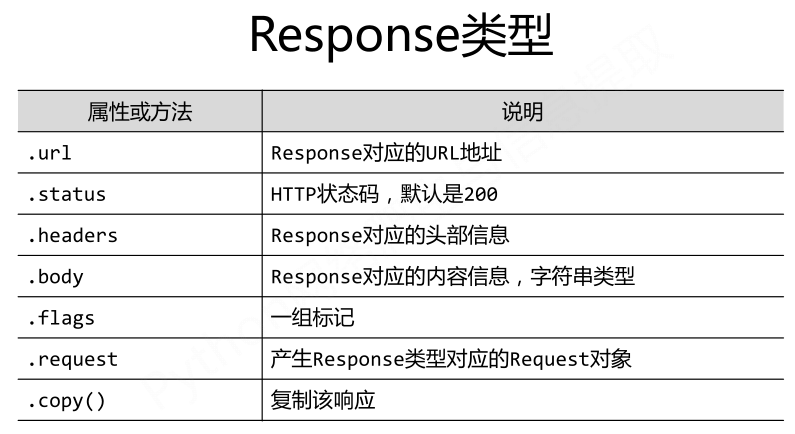

Scrapy爬虫提取信息的方法:
Scrapy爬虫支持多种HTML信息提取方法:
- Beautiful Soup
- lxml
- re
- XPath Selector
- CSS Selector

学习的体会和收获
不愧是国家精品课程,讲解知识通俗易懂,内容生动有趣。通过这段时间的学习,让我对爬虫有了基本的认识。以前买过一本网络爬虫的书,也看过几章《网络数据采集》,里面也讲了Beautiful Soup库,讲的也比较深,但是跟视频比起来,就没那么容易懂了。
通过这段时间的学习,收获了一个自学的好去处,这个网站里面的课程不可不畏精品,业余时间可以很好的给自己充充电。最大的收获莫过于让我了解了爬虫的步骤,先要想办法获取目标页面的源代码,然后就可以使用BeautifulSoup库来烹制这锅美味的汤了。在烹制过程中可以使用正则表达式为其助力。
正所谓“万事开头难”,此课程带我迈开了第一步。后面我就知道想要继续深入学习我应该怎么学,这是最重要的。师傅领进门,修行靠个人。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号