

对蔬菜商情网的价格数爬取及分析
对蔬菜商情网的价格数据及分析
一 、选题背景
蔬菜是指可以做菜、烹饪成为食品的一类植物或菌类,蔬菜是人们日常饮食中必不可少的食物之一。近期,蔬菜价格有所上涨,引起广泛关注。“双节”将至,物价走势如何?9月16日,国家发改委召开9月份例行新闻发布会。针对蔬菜价格上涨相关情况,国家发改委新闻发言人孟玮表示,蔬菜的生长周期比较短,后期随着极端天气减少,秋季蔬菜陆续上市,市场供应有望在较短时间内恢复,鲜菜价格将随之回落。夏季到来,合理饮食很关键。夏季的饮食讲究清淡,多吃蔬菜有利于养生。那么哪个地区的蔬菜批发价格要便宜一些呢?让我们用Python爬取某蔬菜网的行情价格,来分析下,到底哪个地区的蔬菜,要更便宜一些。
二、设计方案
1.主题式网络爬虫名称
对蔬菜商情网的价格数爬取及分析
2.主题式网络爬虫爬取内容与数据特征分析
对价格榜单的发布时间,产地,种类,等进行爬取并做分析
3·主题式爬虫设计方案概述(包括实现思路与技术难点)
1.通过开发者模式查看网页结构与所需爬取的东西所在的位置
2.通过简单的input函数做一个选择界面
3.存储数据:利用open(),WRITE()等等
三、实现步骤及代码
1.爬虫设计
(1)主题页面结构特征与特征分析
url =2021年农产品价格数据中心 - 蔬菜商情网 (shucai123.com)
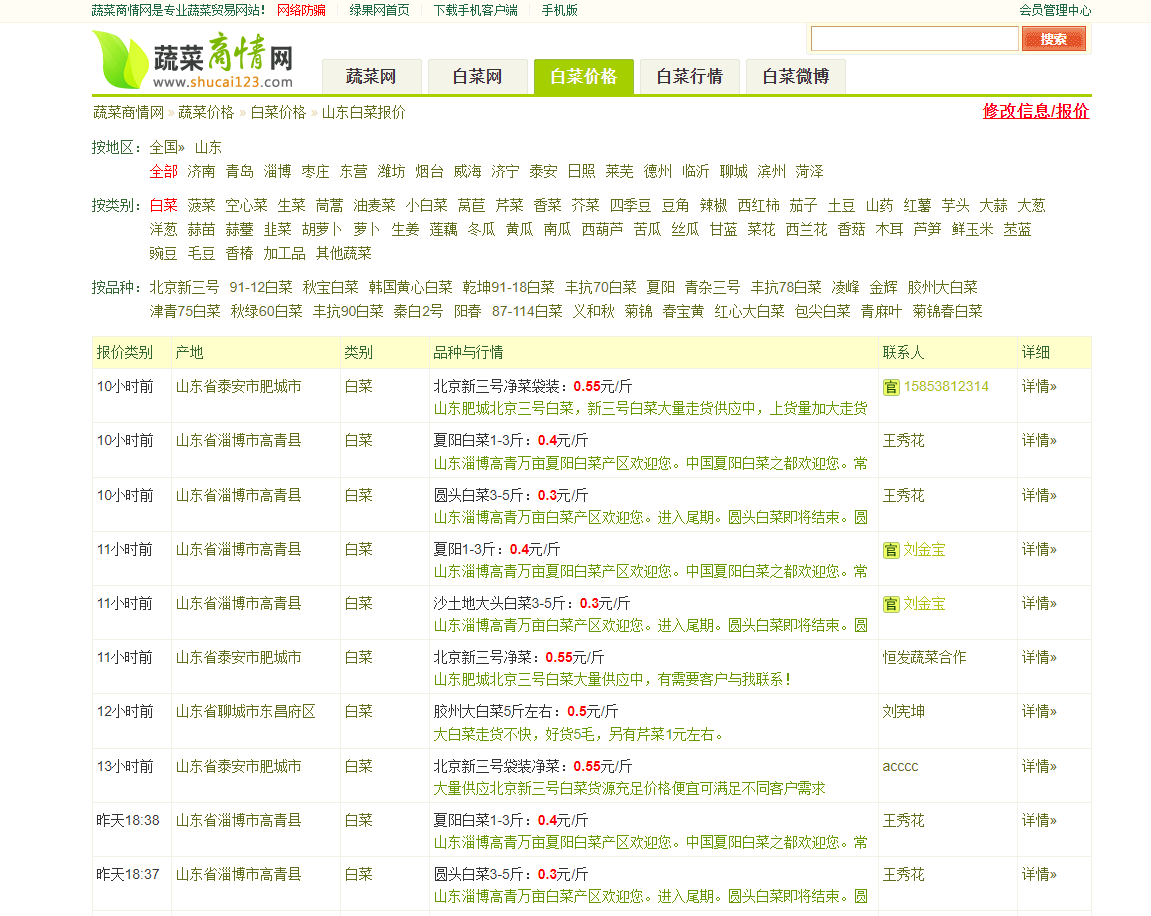
(2)html页面解析
定位到所爬取的表,关键词class='bjtbl'
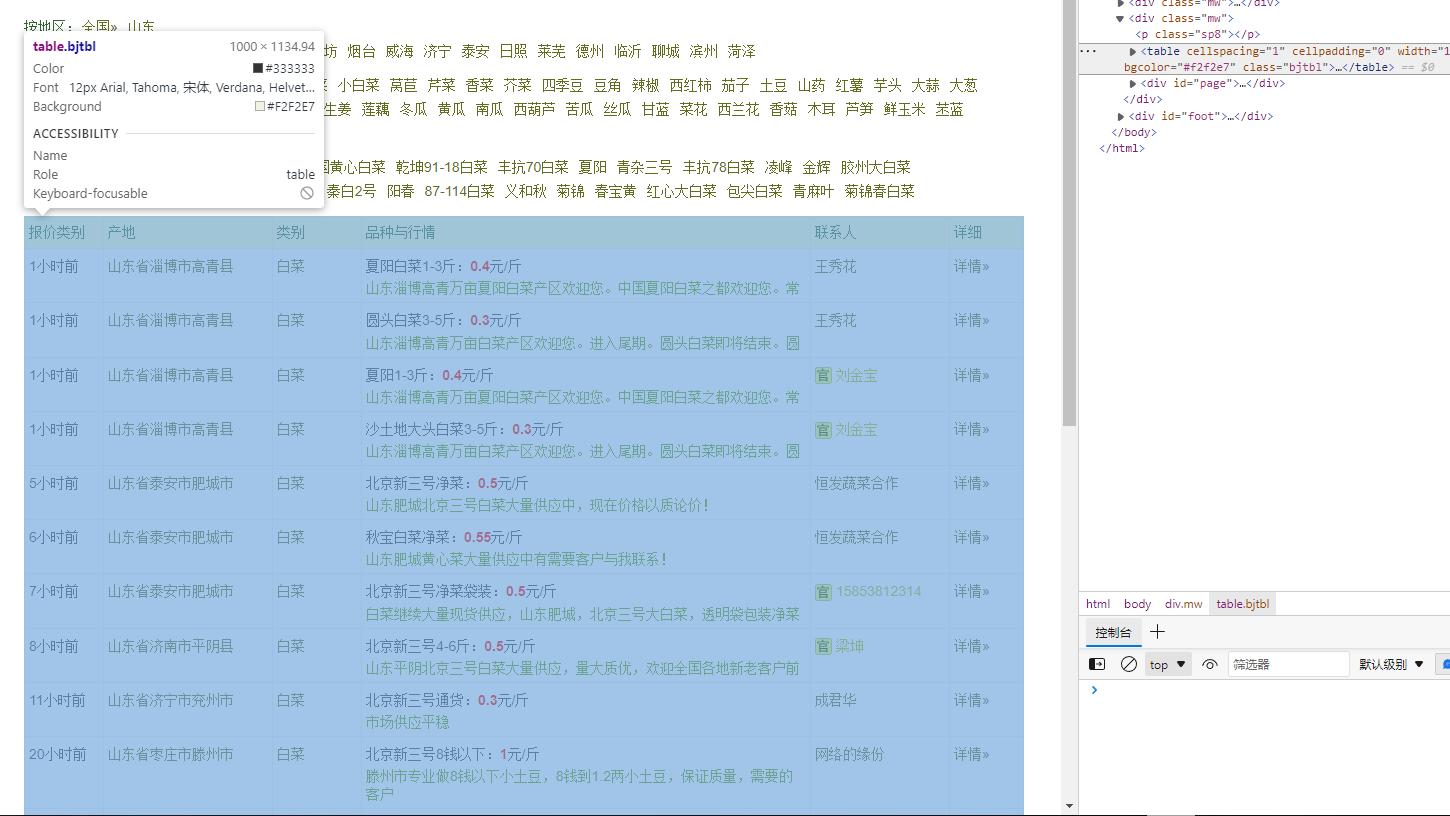
类型和关键字:
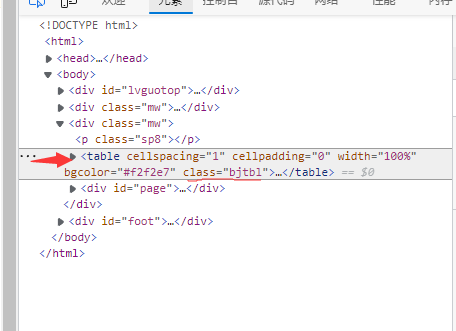
(3)节点查找方法与遍历
import textwrap import requests from bs4 import BeautifulSoup import wordcloud import csv import pandas as pd import numpy as np #设置交互 s = (input('请输入你想查询的种类:')) l = (input('请输入你所查询的地点:')) #一.爬取数据
#设置循环语句翻页爬取翻页内容10次 def main(): baseurl = f'http://www.shucai123.com/price/{s}/{l}/t' #所爬取的网页是伴随url翻页的形式,以此设立一个循环爬取翻页内容 i = 1 #初始页码为t1 for i in range(1, 5): #根据需求,只爬取前四页内容 url = baseurl + str(i) getdata(url) def getdata(url): #模拟浏览器头部信息,向蔬菜网服务器发送消息 header = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62" } #用户代理,告诉蔬菜商情网服务器,我们是Windows NT 10.0; Win64; x64.....类型的机器、浏览器 resp = requests.get(url,headers=header) #requests.get(url, params = None, **kwargs)requests库get方法 #url: 拟获取页面的url链接 #params: url中额外参数,字典或字节流格式,可选 #**kwargs: 12个控制访问的参数 resp.encoding = 'utf-8' # 手动指定字符编码为utf-8 #二.解析数据 #1.将页面源代码交给BeautifulSoup处理,生成bs对象 page = BeautifulSoup(resp.text,"html.parser") #指定html解析器 #2.从bs中查找数据 table = page.find("table",class_="bjtbl") #“bjtbl”是该表的关键字 #拿到所有行 trs = table.find_all("tr")[1:] for tr in trs: #每一行 tds = tr.find_all("td") #拿到每行的所有td(二次筛选) time_ = tds[0].text #发布时间 origin = tds[1].text #产地 sort = tds[2].text #种类 variety = tds[3].find_all('p')[0].next_element #具体品种 price = tds[3].find_all('p')[0].find_all('b')[0].text #价格 market = tds[3].find_all('p')[1].text #行情 contacts = tds[4].text #联系人 print("over!") if __name__ == '__main__': main()
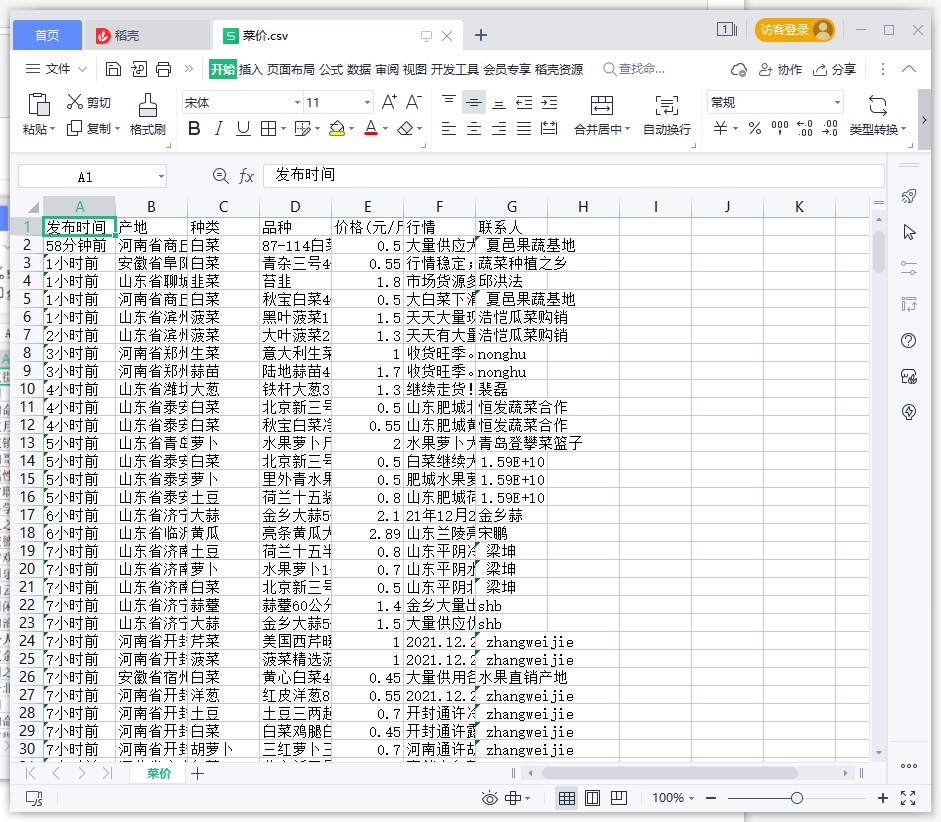
2.数据持久化及演示:
import textwrap
from bs4 import BeautifulSoup
import wordcloud
import csv
import pandas as pd
import numpy as np
#建立一个csv表存储数据
#newline=''的作用是删除隔行的空格
f = open("菜价.csv", mode="a", encoding="utf-8",newline='')
csvwriter = csv.writer(f)
#2.从bs中查找数据
table = page.find("table",class_="bjtbl") #“bjtbl”是该表的关键字
#拿到所有行
trs = table.find_all("tr")[1:]
for tr in trs: #每一行
tds = tr.find_all("td") #拿到每行的所有td(二次筛选)
time_ = tds[0].text #发布时间
origin = tds[1].text #产地
sort = tds[2].text #种类
variety = tds[3].find_all('p')[0].next_element #具体品种
price = tds[3].find_all('p')[0].find_all('b')[0].text #价格
market = tds[3].find_all('p')[1].text #行情
contacts = tds[4].text #联系人
variety_ = variety.replace(':','') #去除多余冒号
csvwriter.writerow([time_, origin, sort, variety_,price,market, contacts]) #将数据写入csv中
print("over!")
if __name__ == '__main__':
main()
f.close() #关闭文件
#写入表头'发布时间','产地','种类','行情','联系人'
data=pd.read_csv(r'C:/Users/Master/PycharmProjects/pythonProject/菜价.csv',header=0,names=['发布时间','产地','种类','品种','价格(元/斤)','行情','联系人'])
data.to_csv('菜价.csv',index=False)
3.数据可视化
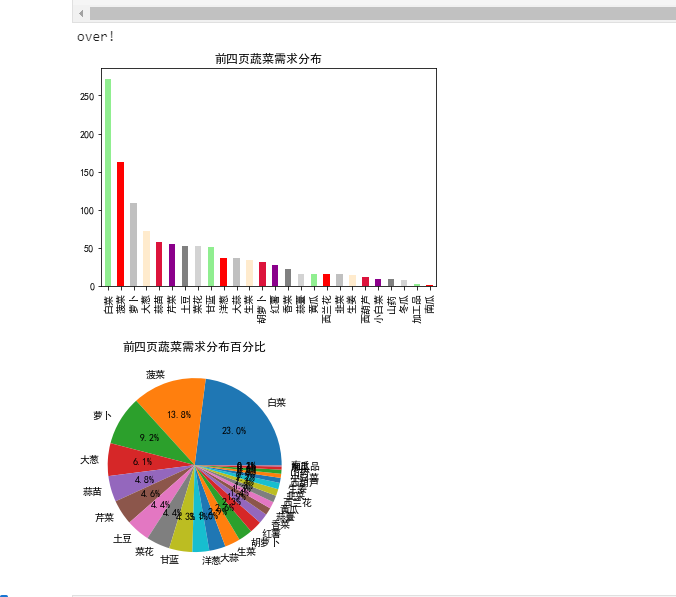
from bs4 import BeautifulSoup import wordcloud import csv import pandas as pd import numpy as np import matplotlib as mpl import seaborn as sns #三、数据可视化 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False #读取csv date=pd.read_csv('C:/Users/Master/PycharmProjects/pythonProject/菜价.csv') #统计每种蔬菜出现次数 t=date['种类'].value_counts() #统计总次数 x=len(date['种类']) #定义一个字典 g={} #设置循环写入每种蔬菜出现次数的小数形式于g for i in range(len(t)): g[i]=t[i]/x #出现次数除以总次数 #将字典转换为列表 g_ = list(g.values()) #输出一个柱状图 t.plot(kind='bar',color=['green','red','silver','#FFEBCD','#DC143C','#8B008B','#808080','#D3D3D3'])
plt.title("前四页蔬菜需求分布")
plt.show()
plt.savefig('前四页蔬菜需求分布.jpg')
# x: 作直方图所要用的数据,必须是一维数组;多维数组可以先进行扁平化再作图;必选参数; # bins: 直方图的柱数,即要分的组数,默认为10; # range:元组(tuple)或None;剔除较大和较小的离群值,给出全局范围;如果为None,则默认为(x.min(), x.max());即x轴的范围; # density:布尔值。如果为true,则返回的元组的第一个参数n将为频率而非默认的频数; # weights:与x形状相同的权重数组;将x中的每个元素乘以对应权重值再计数;如果normed或density取值为True,则会对权重进行归一化处理。这个参数可用于绘制已合并的数据的直方图; # cumulative:布尔值;如果为True,则计算累计频数;如果normed或density取值为True,则计算累计频率; # bottom:数组,标量值或None;每个柱子底部相对于y=0的位置。如果是标量值,则每个柱子相对于y=0向上/向下的偏移量相同。如果是数组,则根据数组元素取值移动对应的柱子;即直方图上下便宜距离; # align:{‘left’, ‘mid’, ‘right’};‘left’:柱子的中心位于bins的左边缘;‘mid’:柱子位于bins左右边缘之间;‘right’:柱子的中心位于bins的右边缘; # histtype:{‘bar’, ‘barstacked’, ‘step’, ‘stepfilled’};'bar’是传统的条形直方图;'barstacked’是堆叠的条形直方图;'step’是未填充的条形直方图,只有外边框;‘stepfilled’是有填充的直方图;当histtype取值为’step’或’stepfilled’,rwidth设置失效,即不能指定柱子之间的间隔,默认连接在一起; # stacked:布尔值。如果取值为True,则输出的图为多个数据集堆叠累计的结果;如果取值为False且histtype=‘bar’或’step’,则多个数据集的柱子并排排列; # orientation:{‘horizontal’, ‘vertical’}:如果取值为horizontal,则条形图将以y轴为基线,水平排列;简单理解为类似bar()转换成barh(),旋转90°; # rwidth:标量值或None。柱子的宽度占bins宽的比例; # log:布尔值。如果取值为True,则坐标轴的刻度为对数刻度;如果log为True且x是一维数组,则计数为0的取值将被剔除,仅返回非空的(frequency, bins, patches); # color:具体颜色,数组(元素为颜色)或None。 # label:字符串(序列)或None;有多个数据集时,用label参数做标注区分; # edgecolor: 直方图边框颜色; # alpha: 透明度;
#绘制一个饼图
plt.pie(g_[:],labels=t.index,autopct="%1.1f%%")
#labels :(每一块)饼图外侧显示的说明文字 #g :(每一块)的比例,如果sum(x) > 1会使用sum(x)归一化 #autopct :控制饼图内百分比设置,可以使用format字符串或者format function'%1.1f'指小数点前后位数(没有用空格补齐); # explode :(每一块)离开中心距离; # startangle :起始绘制角度,默认图是从x轴正方向逆时针画起,如设定=90则从y轴正方向画起; # shadow :在饼图下面画一个阴影。默认值:False,即不画阴影; # labeldistance :label标记的绘制位置,相对于半径的比例,默认值为1.1, 如<1则绘制在饼图内侧; # pctdistance :类似于labeldistance,指定autopct的位置刻度,默认值为0.6; # radius :控制饼图半径,默认值为1; # counterclock :指定指针方向;布尔值,可选参数,默认为:True,即逆时针。将值改为False即可改为顺时针。 # wedgeprops :字典类型,可选参数,默认值:None。参数字典传递给wedge对象用来画一个饼图。例如:wedgeprops={'linewidth':3}设置wedge线宽为3。 # textprops :设置标签(labels)和比例文字的格式;字典类型,可选参数,默认值为:None。传递给text对象的字典参数。 # center :浮点类型的列表,可选参数,默认值:(0,0)。图标中心位置。 # frame :布尔类型,可选参数,默认值:False。如果是true,绘制带有表的轴框架。 # rotatelabels :布尔类型,可选参数,默认为:False。如果为True,旋转每个label到指定的角度。
plt.show()
plt.savefig('蔬菜需求分布百分比.jpg')
#绘制词云
import pandas as pd
import jieba
from pylab import *
from wordcloud import WordCloud
text = ''
df=pd.read_csv('C:/Users/Master/菜价.csv')
for line in df['种类'].head(200):
text+= line
# 使用jieba模块将字符串分割为单词列表
cut_text = ' '.join(jieba.cut(text))
color_mask = imread('D:/蘑菇.jpg') #设置背景图
cloud = WordCloud(
background_color = 'white',
# 对中文操作必须指明字体
font_path='C:\Windows\Fonts\simkai.ttf',
mask = color_mask,
max_words = 50,
max_font_size = 200
).generate(cut_text)
# 保存词云图片
cloud.to_file('wordcloud.jpg')
plt.imshow(cloud)
plt.axis('off')
plt.show()

四、总代码
1 import textwrap 2 import requests 3 from bs4 import BeautifulSoup 4 import wordcloud 5 import csv 6 import pandas as pd 7 import numpy as np 8 import matplotlib as mpl 9 import seaborn as sns 10 11 #设置交互 12 13 s = (input('请输入你想查询的种类:')) 14 15 l = (input('请输入你所查询的地点:')) 16 17 #建立一个csv表存储数据 18 19 #newline=''的作用是删除隔行的空格 20 21 f = open("菜价.csv", mode="a", encoding="utf-8",newline='') 22 23 csvwriter = csv.writer(f) 24 25 #一.爬取数据 26 27 #设置循环语句翻页爬取翻页内容10次 28 def main(): 29 baseurl = f'http://www.shucai123.com/price/{s}/{l}/t' 30 #所爬取的网页是伴随url翻页的形式,以此设立一个循环爬取翻页内容 31 i = 1 #初始页码为t1 32 for i in range(1, 5): #根据需求,只爬取前四页内容 33 url = baseurl + str(i) 34 getdata(url) 35 36 37 def getdata(url): 38 #模拟浏览器头部信息,向蔬菜网服务器发送消息 39 40 header = { 41 "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62" 42 } 43 44 #用户代理,告诉蔬菜商情网服务器,我们是Windows NT 10.0; Win64; x64.....类型的机器、浏览器 45 46 resp = requests.get(url,headers=header) 47 48 #requests.get(url, params = None, **kwargs) requests库get方法 49 50 #url: 拟获取页面的url链接 51 52 #params: url中额外参数,字典或字节流格式,可选 53 54 #**kwargs: 12个控制访问的参数 55 56 resp.encoding = 'utf-8' 57 # 手动指定字符编码为utf-8 58 59 #二.解析数据 60 #1.将页面源代码交给BeautifulSoup处理,生成bs对象 61 page = BeautifulSoup(resp.text,"html.parser") 62 #指定html解析器 63 64 #2.从bs中查找数据 65 table = page.find("table",class_="bjtbl") 66 #“bjtbl”是该表的关键字 67 68 #拿到所有行 69 trs = table.find_all("tr")[1:] 70 71 for tr in trs: #每一行 72 tds = tr.find_all("td") #拿到每行的所有td(二次筛选) 73 time_ = tds[0].text #发布时间 74 origin = tds[1].text #产地 75 sort = tds[2].text #种类 76 variety = tds[3].find_all('p')[0].next_element #具体品种 77 price = tds[3].find_all('p')[0].find_all('b')[0].text #价格 78 market = tds[3].find_all('p')[1].text #行情 79 contacts = tds[4].text #联系人 80 variety_ = variety.replace(':','') #去除多余冒号 81 82 csvwriter.writerow([time_, origin, sort, variety_,price,market, contacts]) #将数据写入csv中 83 84 print("over!") 85 86 if __name__ == '__main__': 87 main() 88 89 #关闭文件 90 f.close() 91 92 #写入表头 93 data=pd.read_csv(r'C:/Users/Master/PycharmProjects/pythonProject/菜价.csv',header=0,names=['发布时间','产地','种类','品种','价格(元/斤)','行情','联系人']) 94 data.to_csv('菜价.csv',index=False) 95 96 97 #三、数据可视化 98 import matplotlib.pyplot as plt 99 plt.rcParams['font.sans-serif'] = ['SimHei'] 100 plt.rcParams['axes.unicode_minus'] = False 101 102 #读取csv 103 date=pd.read_csv('C:/Users/Master/PycharmProjects/pythonProject/菜价.csv') 104 105 #统计每种蔬菜出现次数 106 t=date['种类'].value_counts() 107 108 #统计总次数 109 x=len(date['种类']) 110 111 #定义一个字典 112 g={} 113 #设置循环写入每种蔬菜出现次数的小数形式于g 114 for i in range(len(t)): 115 g[i]=t[i]/x 116 #出现次数除以总次数 117 118 #将字典转换为列表 119 g_ = list(g.values()) 120 121 #输出一个柱状图 122 t.plot(kind='bar',color=['green','red','silver','#FFEBCD','#DC143C','#8B008B','#808080','#D3D3D3']) 123 124 plt.title("前四页蔬菜需求分布") 125 126 plt.show() 127 128 plt.savefig('前四页蔬菜需求分布.jpg') 129 130 # x: 作直方图所要用的数据,必须是一维数组;多维数组可以先进行扁平化再作图;必选参数; 131 # bins: 直方图的柱数,即要分的组数,默认为10; 132 # range:元组(tuple)或None;剔除较大和较小的离群值,给出全局范围;如果为None,则默认为(x.min(), x.max());即x轴的范围; 133 # density:布尔值。如果为true,则返回的元组的第一个参数n将为频率而非默认的频数; 134 # weights:与x形状相同的权重数组;将x中的每个元素乘以对应权重值再计数;如果normed或density取值为True,则会对权重进行归一化处理。这个参数可用于绘制已合并的数据的直方图; 135 # cumulative:布尔值;如果为True,则计算累计频数;如果normed或density取值为True,则计算累计频率; 136 # bottom:数组,标量值或None;每个柱子底部相对于y=0的位置。如果是标量值,则每个柱子相对于y=0向上/向下的偏移量相同。如果是数组,则根据数组元素取值移动对应的柱子;即直方图上下便宜距离; 137 # align:{‘left’, ‘mid’, ‘right’};‘left’:柱子的中心位于bins的左边缘;‘mid’:柱子位于bins左右边缘之间;‘right’:柱子的中心位于bins的右边缘; 138 # histtype:{‘bar’, ‘barstacked’, ‘step’, ‘stepfilled’};'bar’是传统的条形直方图;'barstacked’是堆叠的条形直方图;'step’是未填充的条形直方图,只有外边框;‘stepfilled’是有填充的直方图;当histtype取值为’step’或’stepfilled’,rwidth设置失效,即不能指定柱子之间的间隔,默认连接在一起; 139 # stacked:布尔值。如果取值为True,则输出的图为多个数据集堆叠累计的结果;如果取值为False且histtype=‘bar’或’step’,则多个数据集的柱子并排排列; 140 # orientation:{‘horizontal’, ‘vertical’}:如果取值为horizontal,则条形图将以y轴为基线,水平排列;简单理解为类似bar()转换成barh(),旋转90°; 141 # rwidth:标量值或None。柱子的宽度占bins宽的比例; 142 # log:布尔值。如果取值为True,则坐标轴的刻度为对数刻度;如果log为True且x是一维数组,则计数为0的取值将被剔除,仅返回非空的(frequency, bins, patches); 143 # color:具体颜色,数组(元素为颜色)或None。 144 # label:字符串(序列)或None;有多个数据集时,用label参数做标注区分; 145 # edgecolor: 直方图边框颜色; 146 # alpha: 透明度; 147 148 #绘制一个饼图 149 150 plt.pie(g_[:],labels=t.index,autopct="%1.1f%%") 151 152 #labels :(每一块)饼图外侧显示的说明文字 153 #g :(每一块)的比例,如果sum(x) > 1会使用sum(x)归一化 154 #autopct :控制饼图内百分比设置,可以使用format字符串或者format function'%1.1f'指小数点前后位数(没有用空格补齐); 155 # explode :(每一块)离开中心距离; 156 # startangle :起始绘制角度,默认图是从x轴正方向逆时针画起,如设定=90则从y轴正方向画起; 157 # shadow :在饼图下面画一个阴影。默认值:False,即不画阴影; 158 # labeldistance :label标记的绘制位置,相对于半径的比例,默认值为1.1, 如<1则绘制在饼图内侧; 159 # pctdistance :类似于labeldistance,指定autopct的位置刻度,默认值为0.6; 160 # radius :控制饼图半径,默认值为1; 161 # counterclock :指定指针方向;布尔值,可选参数,默认为:True,即逆时针。将值改为False即可改为顺时针。 162 # wedgeprops :字典类型,可选参数,默认值:None。参数字典传递给wedge对象用来画一个饼图。例如:wedgeprops={'linewidth':3}设置wedge线宽为3。 163 # textprops :设置标签(labels)和比例文字的格式;字典类型,可选参数,默认值为:None。传递给text对象的字典参数。 164 # center :浮点类型的列表,可选参数,默认值:(0,0)。图标中心位置。 165 # frame :布尔类型,可选参数,默认值:False。如果是true,绘制带有表的轴框架。 166 # rotatelabels :布尔类型,可选参数,默认为:False。如果为True,旋转每个label到指定的角度。 167 168 plt.show() 169 170 plt.savefig('蔬菜需求分布百分比.jpg') 171 172 import pandas as pd 173 import jieba 174 from pylab import * 175 from wordcloud import WordCloud 176 text = '' 177 df=pd.read_csv('D:/菜价.csv') 178 for line in df['种类'].head(200): 179 text+= line 180 # 使用jieba模块将字符串分割为单词列表 181 cut_text = ' '.join(jieba.cut(text)) 182 color_mask = imread('D:/书本.jpg') #设置背景图 183 cloud = WordCloud( 184 background_color = 'white', 185 # 对中文操作必须指明字体 186 font_path='C:\Windows\Fonts\simkai.ttf', 187 mask = color_mask, 188 max_words = 50, 189 max_font_size = 200 190 ).generate(cut_text) 191 192 # 保存词云图片 193 cloud.to_file('wordcloud.jpg') 194 plt.imshow(cloud) 195 plt.axis('off') 196 plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号