自定义分页
1 . 分页的实现与使用
app01 page.py
""" 分页组件使用示例: obj = Pagination(request.GET.get('page',1),len(USER_LIST),request.path_info) page_user_list = USER_LIST[obj.start:obj.end] page_html = obj.page_html() return render(request,'index.html',{'users':page_user_list,'page_html':page_html}) """ class Pagination(object): def __init__(self,current_page_num,all_count,request,per_page_num=2,pager_count=11): """ 封装分页相关数据 :param current_page_num: 当前访问页的数字 :param all_count: 分页数据中的数据总条数 :param per_page_num: 每页显示的数据条数 :param pager_count: 最多显示的页码个数 """ try: current_page_num = int(current_page_num) except Exception as e: current_page_num = 1 if current_page_num <1: current_page_num = 1 # 当前访问页的数字 self.current_page_num = current_page_num # 数据总条数 self.all_count = all_count # 每页显示的数据条数 self.per_page_num = per_page_num # 实际总页码 all_pager, tmp = divmod(all_count, per_page_num) if tmp: all_pager += 1 self.all_pager = all_pager # 最多显示的页码个数,(比如默认显示11个页码,当前页码11-1 / 2 就是第五页) self.pager_count = pager_count self.pager_count_half = int((pager_count - 1) / 2) # 5 #左5页右5页 # print(request.GET) # <QueryDict:{'a':['1'],'b':['2'],'xxx':[123]}> 搜索条件 # 保存搜索条件 import copy # 深度拷贝 self.params=copy.deepcopy(request.GET) # {"a":"1","b":"2"} @property def start(self): return (self.current_page_num - 1) * self.per_page_num @property def end(self): return self.current_page_num * self.per_page_num def page_html(self): # 如果总页码 < 11个:(比如10页,那么就显示10页) if self.all_pager <= self.pager_count: pager_start = 1 pager_end = self.all_pager + 1 #<11页,就显示总页数,+1是因为ranger循环的时候顾头不顾尾 # 总页码 > 11 else: # 当前页如果<=页面上最多显示11/2个页码 if self.current_page_num <= self.pager_count_half: pager_start = 1 pager_end = self.pager_count + 1 # 当前页大于5 else: # 页码翻到最后 if (self.current_page_num + self.pager_count_half) > self.all_pager: pager_start = self.all_pager - self.pager_count + 1 pager_end = self.all_pager + 1 #倒数11个 else: pager_start = self.current_page_num - self.pager_count_half pager_end = self.current_page_num + self.pager_count_half + 1 page_html_list = [] # {source:[2,], status:[2], gender:[2],consultant:[1],page:[1]} first_page = '<li><a href="?page=%s">首页</a></li>' % (1,) page_html_list.append(first_page) if self.current_page_num <= 1: prev_page = '<li class="disabled"><a href="#">上一页</a></li>' else: prev_page = '<li><a href="?page=%s">上一页</a></li>' % (self.current_page_num - 1,) page_html_list.append(prev_page) #self.params=copy.deepcopy(request.GET) # {"a":"1","b":"2"} # 中间页码 for i in range(pager_start, pager_end): self.params["page"]=i if i == self.current_page_num: temp = '<li class="active"><a href="?%s">%s</a></li>' %(self.params.urlencode(),i) else: temp = '<li><a href="?%s">%s</a></li>' % (self.params.urlencode(),i,) page_html_list.append(temp) # 尾页 if self.current_page_num >= self.all_pager: next_page = '<li class="disabled"><a href="#">下一页</a></li>' else: next_page = '<li><a href="?page=%s">下一页</a></li>' % (self.current_page_num + 1,) page_html_list.append(next_page) last_page = '<li><a href="?page=%s">尾页</a></li>' % (self.all_pager,) page_html_list.append(last_page) return ''.join(page_html_list)
views.py
from django.shortcuts import render # Create your views here. from app01.models import Book from django.core.paginator import Paginator,EmptyPage def index(request): ''' 批量插入数据: # for i in range(100): # Book.objects.create(title="book_%s"%i,price=i*i) book_list=[] for i in range(100): book=Book(title="book_%s"%i,price=i*i) book_list.append(book) Book.objects.bulk_create(book_list) 分页器的使用: paginator=Paginator(book_list,8) print(paginator.count) # 100 print(paginator.num_pages) # 分页数:13 print(paginator.page_range) # range(1, 14) page=paginator.page(5) for i in page: print(i) print(page.has_next()) print(page.has_previous()) print(page.next_page_number()) print(page.previous_page_number()) book_list = Book.objects.all() paginator = Paginator(book_list, 2) try: current_page_num=request.GET.get("page",1) current_page=paginator.page(current_page_num) except EmptyPage as e: current_page_num=1 current_page = paginator.page(1) ''' # 自定义分页 print(request.GET) from app01.page import Pagination current_page_num = request.GET.get("page") book_list = Book.objects.all() pagination=Pagination(current_page_num,book_list.count(),request) ''' count=100 per_page=9 current_page_num=1 start 0 end 8 current_page_num=2 start 8 end 16 current_page_num=3 start 16 end 24 current_page_num=n start (n-1)*per_page end n*per_page ''' book_list=book_list[pagination.start:pagination.end] return render(request,"index.html",locals())
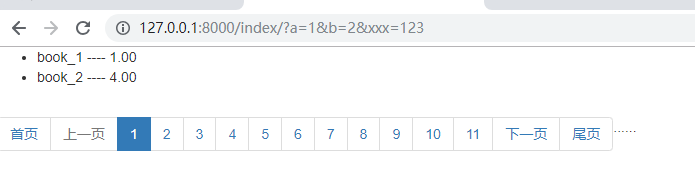
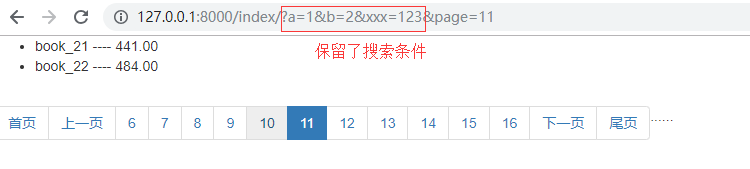
2 . 编辑后保留原URL搜索的条件
① . request.GET 是一个QueryDict 类型的,想要取出 ? 后面的结构用 request.GET.unlencode()
② . request.GET 默认是不可修改的,需要把 params=QueryDict(mutable=True),mutable这个参数设置成 True .
③ . 1和2虽然可以更改,但是这样会麻烦,因为QueryDict 是保存的用户请求状态,当我们完成这次请求之后,下次请求会乱,所有我们不用...我们可以使用copy
import copy self.params=copy.deepcopy(request.GET) #由于 print(request.GET) 的结果 <QueryDict:{'a':['1'],'b':['2'],'xxx':[123]}> ,只能读取,不能更改 #所所以我们要先深度拷贝一份,虽然是深度拷贝,但是在源码里面,request.GET 的 mutable=False----不能更改,但是拷贝之后的mutable=True----可以更改 self.params.urlencode() ---#可以将{"a":"1","b":"2"} ===>a=1&b=2&xxx=123
效果 :


 浙公网安备 33010602011771号
浙公网安备 33010602011771号