
HDKV: High-Dimensional Similarity Query in Key-Value Stores
文章集中于key-value store
Locality-sensitive hashing (LSH) is a method of performing probabilistic dimension reduction of high-dimensional data. The basic idea is to hash the input items so that similar items are mapped to the same buckets with high probability (the number of buckets being much smaller than the universe of possible input items).
Stable distributions
The hash function [8]  maps a d dimensional vector
maps a d dimensional vector 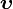 onto a set of integers. Each hash function in the family is indexed by a choice of random
onto a set of integers. Each hash function in the family is indexed by a choice of random  and b where is a d dimensional vector with entries chosen independently from a stable distribution and b is a real number chosen uniformly from the range [0,r]. For a fixed
and b where is a d dimensional vector with entries chosen independently from a stable distribution and b is a real number chosen uniformly from the range [0,r]. For a fixed  the hash function
the hash function 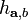 is given by
is given by 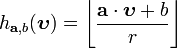 .
.
Other construction methods for hash functions have been proposed to better fit the data. [9] In particular k-means hash functions are better in practice than projection-based hash functions, but without any theoretical guarantee.
The key idea of locality-sensitive hash (LSH) is to hash the points using several hash functions so as to ensure that, for each function, the probability of
collision is much higher for objects which are close to each other than for those which are far apart. Then, one can determine near neighbors by hashing the
query point and retrieving elements stored in buckets containing that point.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号