会员
周边
新闻
博问
闪存
众包
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
芋圆院长
博客园
首页
新随笔
联系
订阅
管理
上一页
1
···
12
13
14
15
16
17
下一页
2021年7月7日
文本词语读取和删除停用词处理
摘要: 前言 这一篇就来记录一下读取文本文件并使用Jieba包进行分词,存储结果用于后续处理的一些简单操作~ 分词并存储 话不多说,简单步骤就是构建好自己的词典和停用词列表,然后读取 分词 删除 存储 import jieba import pandas as pd def read_file(filena
阅读全文
posted @ 2021-07-07 17:16 芋圆院长
阅读(744)
评论(0)
推荐(0)
2021年7月5日
集合不等式之Bonferroni inequality
摘要: Bonferroni不等式: $\begin{array}{l} p({A_1} \cap {A_2}) \ge p({A_1}) + p({A_2}) - 1\ p({A_1} \cap {A_2}.... \cap {A_n}) \ge p({A_1}) + p({A_2}) + .... +
阅读全文
posted @ 2021-07-05 16:42 芋圆院长
阅读(2712)
评论(0)
推荐(0)
2021年6月1日
强化学习代码之4×4网格问题
摘要: 前言 主要参考的是《Reinforcement Learning: An introduction Second Edition》这本书里的例子 英文版地址:http://incompleteideas.net/book/first/ebook/the-book.html 代码源文件可以参考这篇回答
阅读全文
posted @ 2021-06-01 11:27 芋圆院长
阅读(543)
评论(0)
推荐(0)
2021年5月31日
强化学习代码之Gridworld
摘要: 前言 主要参考的是《Reinforcement Learning: An introduction Second Edition》这本书里的例子 英文版地址:http://incompleteideas.net/book/first/ebook/the-book.html 代码源文件可以参考这篇回答
阅读全文
posted @ 2021-05-31 16:33 芋圆院长
阅读(1170)
评论(0)
推荐(0)
强化学习代码分析之回收机器人
摘要: 前言 主要参考的是《Reinforcement Learning: An introduction Second Edition》这本书里的例子 英文版地址:http://incompleteideas.net/book/first/ebook/the-book.html 代码源文件可以参考这篇回答
阅读全文
posted @ 2021-05-31 15:41 芋圆院长
阅读(227)
评论(0)
推荐(0)
强化学习代码分析之多臂赌博机
摘要: ### 前言 主要参考的是《Reinforcement Learning: An introduction Second Edition》这本书里的例子 英文版地址:http://incompleteideas.net/book/first/ebook/the-book.html 代码源文件可以参考
阅读全文
posted @ 2021-05-31 10:59 芋圆院长
阅读(275)
评论(0)
推荐(0)
2021年5月27日
Python函数相关知识简介
摘要: 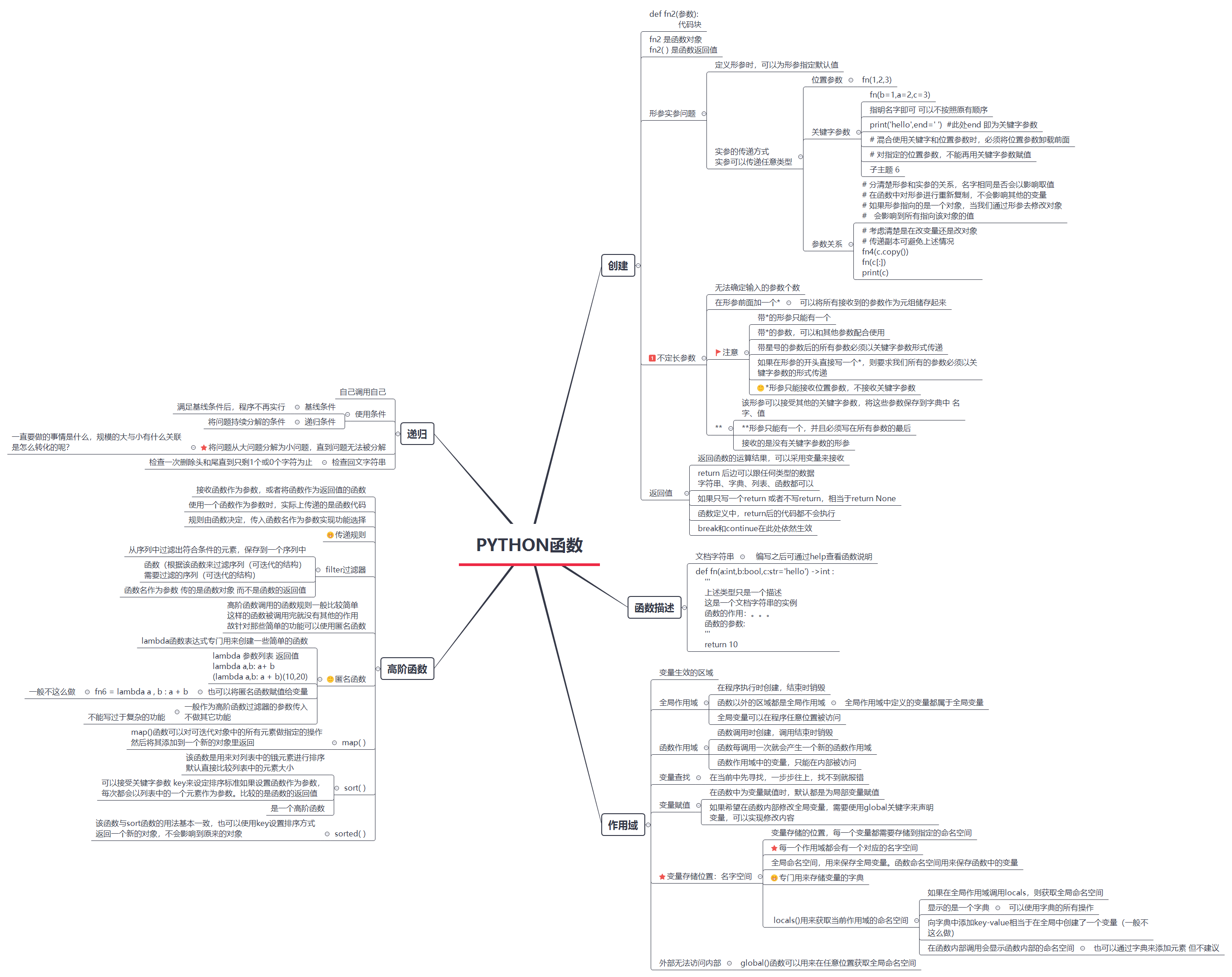
阅读全文
posted @ 2021-05-27 19:49 芋圆院长
阅读(33)
评论(0)
推荐(0)
Python 面向对象编程基础
摘要: 开始Python的复习!(以前学的忘了好多-_-) 主要参考的是Github上的一个项目:https://github.com/jackfrued/Python-100-Days 文章主要是对该项目中的内容进行学习 穿插一点自己的学习想法等内容~ 基本的那些变量类型、数据类型、循环等概念就不复习啦
阅读全文
posted @ 2021-05-27 19:43 芋圆院长
阅读(79)
评论(0)
推荐(0)
2021年5月26日
n步自举法
摘要: n步时序差分方法是单独的蒙特卡罗和时序差分方法更一般的推广,性能通常优于那两种极端形式。 n步TD预测 MC使用完整奖赏序列 一步TD基于下一步奖赏,将一步后的状态值作为剩余奖赏的近似值进行引导更新 n步自举将MC与TD统一,灵活选择用未来n步的数据进行引导更新。更新是基于中间数量的奖赏值 n步Sa
阅读全文
posted @ 2021-05-26 21:22 芋圆院长
阅读(270)
评论(0)
推荐(0)
2021年5月25日
时序差分学习(temporary learning, TD)
摘要: 蒙特卡罗方法在没有环境模型的基础上,直接从经验中学习,无需获知环境的全部信息。动态规划从其它的已经学习到的估计值去更新估计值。TD则结合了这两种方法的优点,且不需要等到片段结束。 对于控制问题,也就是寻找一个最优策略,DP、TD和蒙特卡罗方法都是用一些GPI的变量。不同之处在于它们对于预测问题的求解
阅读全文
posted @ 2021-05-25 10:46 芋圆院长
阅读(228)
评论(0)
推荐(0)
上一页
1
···
12
13
14
15
16
17
下一页
公告

 浙公网安备 33010602011771号
浙公网安备 33010602011771号