pyspider用法----1
缘起
pyspider 来源于以前做的一个垂直搜索引擎使用的爬虫后端。我们需要从200个站点(由于站点失效,不是都同时啦,同时有100+在跑吧)采集数据,并要求在5分钟内将对方网站的更新更新到库中。
所以,灵活的抓取控制是必须的。同时,由于100个站点,每天都可能会有站点失效或者改版,所以需要能够监控模板失效,以及查看抓取状态。
为了达到5分钟更新,我们使用抓取最近更新页上面的最后更新时间,以此来判断页面是否需要再次抓取。
可见,这个项目对于爬虫的监控和调度要求是非常高的。
GitHub地址:https://github.com/binux/pyspider
pyspider 的主要特性
- python 脚本控制,可以用任何你喜欢的html解析包(内置 pyquery)
- WEB 界面编写调试脚本,起停脚本,监控执行状态,查看活动历史,获取结果产出
- 数据存储支持MySQL, MongoDB, Redis, SQLite, Elasticsearch; PostgreSQL 及 SQLAlchemy
- 队列服务支持RabbitMQ, Beanstalk, Redis 和 Kombu
- 支持抓取 JavaScript 的页面
- 组件可替换,支持单机/分布式部署,支持 Docker 部署
- 强大的调度控制,支持超时重爬及优先级设置
- 支持python2&3
安装
pip install pyspider
启动环境
安装完成后运行以下命令运行pyspider程序
pyspider
注意:pyspider命令默认会以all模式运行所有的组件,方便调试。作者建议在线上模式分开部署各各组件,详情请查看部署章节
运行成功后用浏览器打开http://localhost:5000/访问控制台
编写脚本
在web控制台点create按钮新建任务,项目名自定义。本例项目名为get_film(爬去豆瓣电影排行榜)

保存后打开代码编辑器(代码编辑器默认有简单的实例代码)

右侧就是代码编辑器,以后可以直接在这添加修改代码。
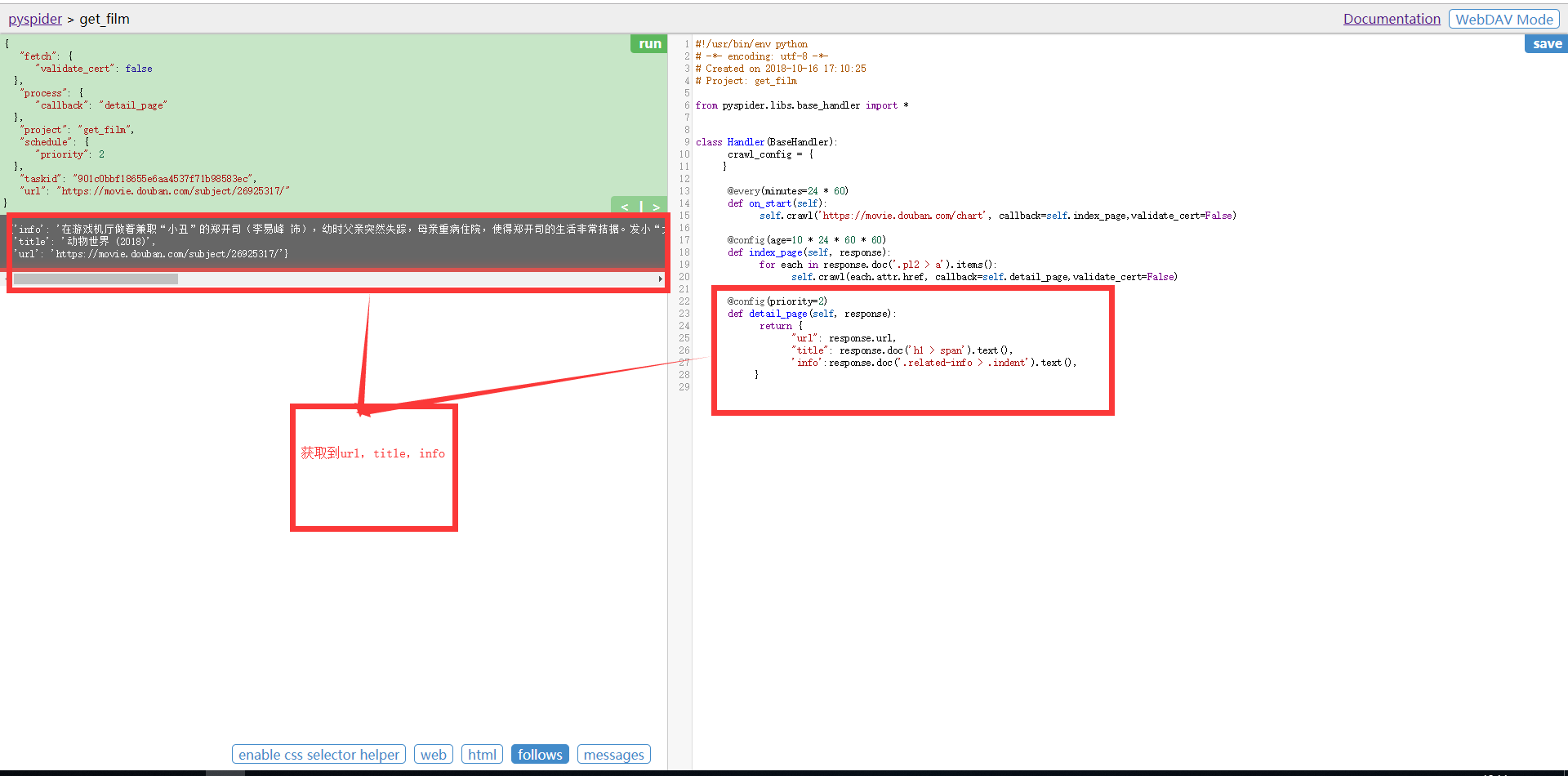
#!/usr/bin/env python # -*- encoding: utf-8 -*- # Created on 2018-10-16 17:10:25 # Project: get_film from pyspider.libs.base_handler import * class Handler(BaseHandler): crawl_config = { } @every(minutes=24 * 60) def on_start(self): self.crawl('https://movie.douban.com/chart', callback=self.index_page,validate_cert=False) @config(age=10 * 24 * 60 * 60) def index_page(self, response): for each in response.doc('.pl2 > a').items(): self.crawl(each.attr.href, callback=self.detail_page,validate_cert=False) @config(priority=2) def detail_page(self, response): return { "url": response.url, "title": response.doc('h1 > span').text(), 'info':response.doc('.related-info > .indent').text(), }
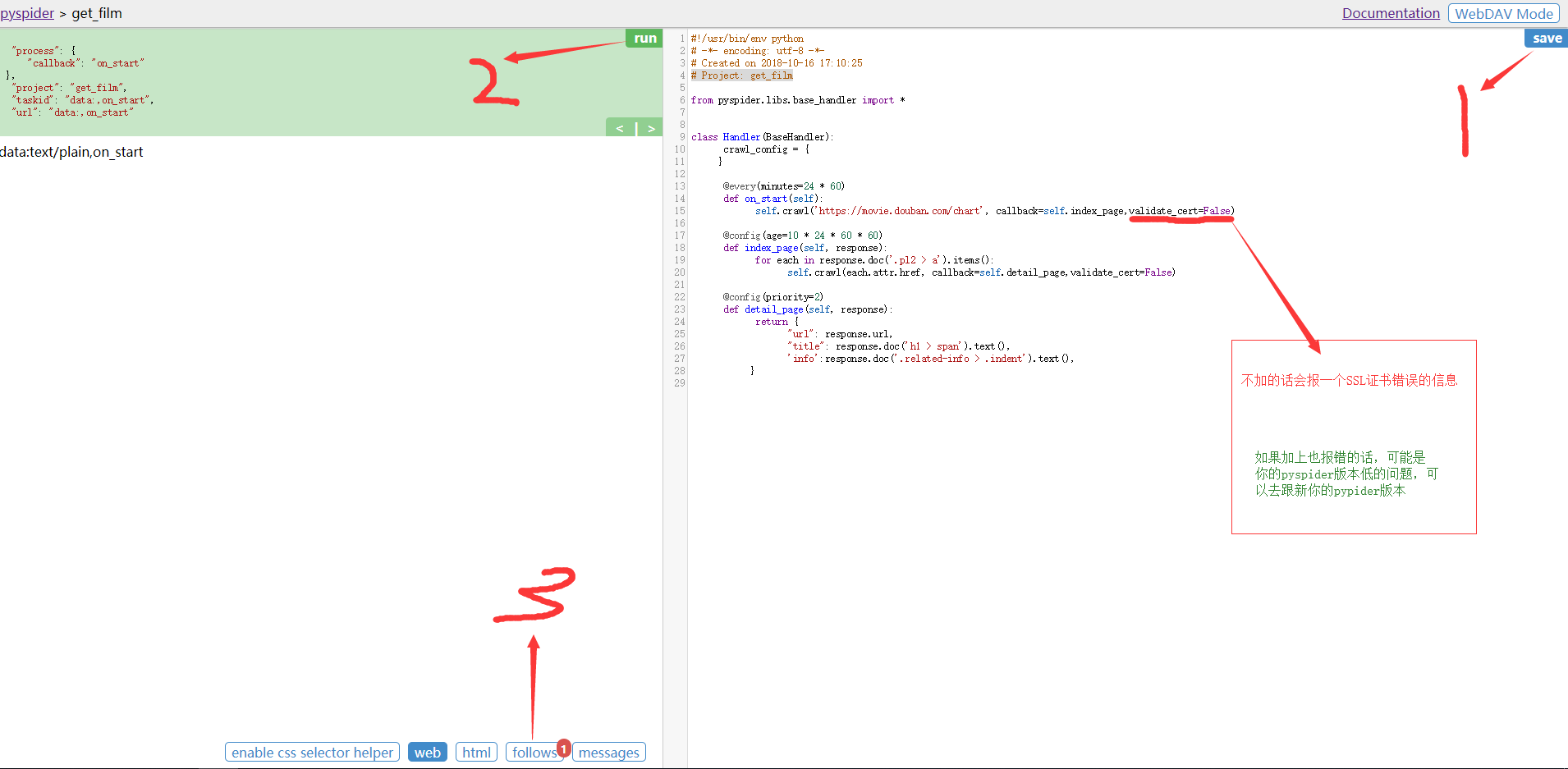
设置参数:
validate_cert=False
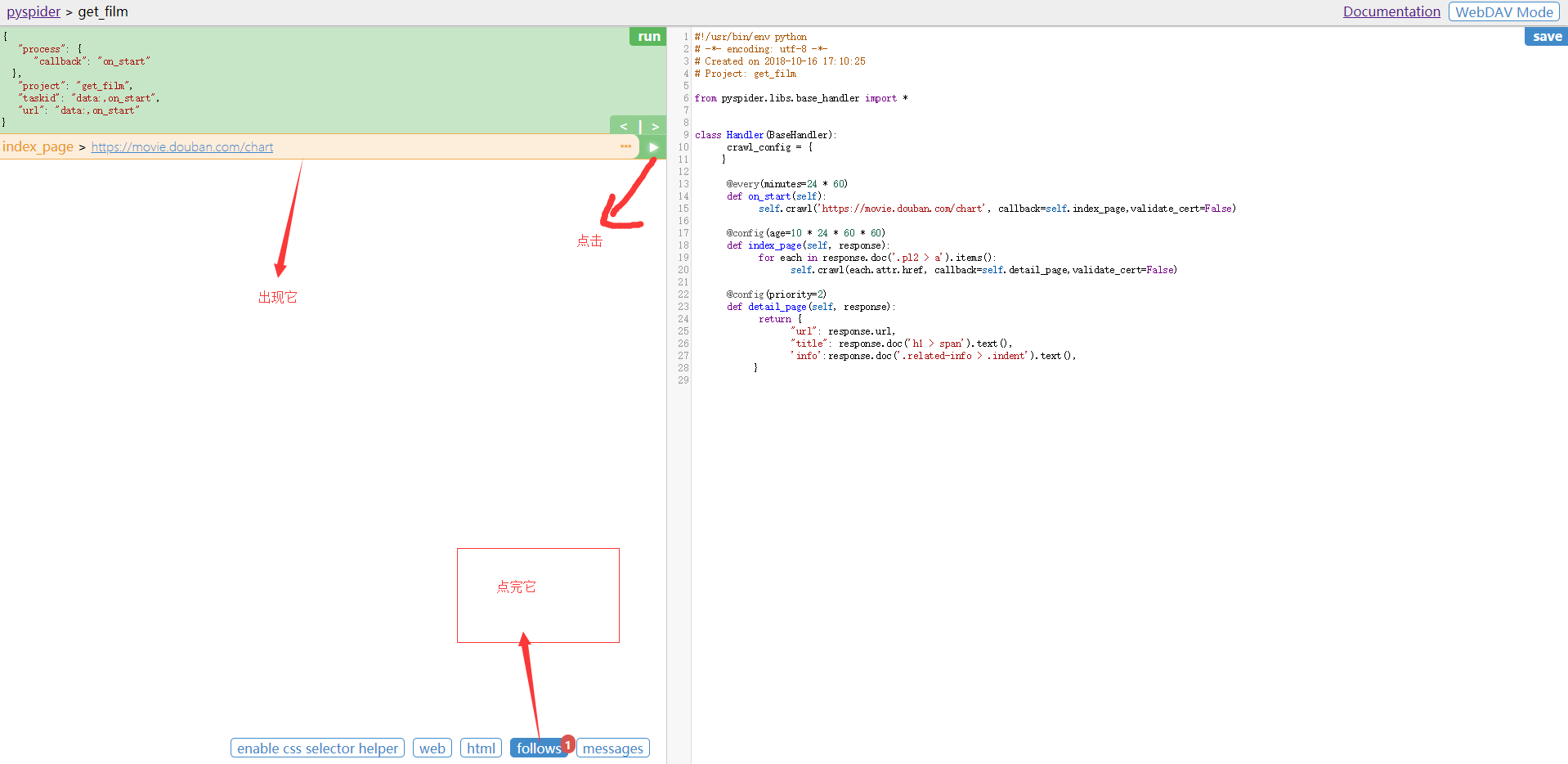




然后点击右上角的保存,并返回上一级

当出现效果时,点击Results
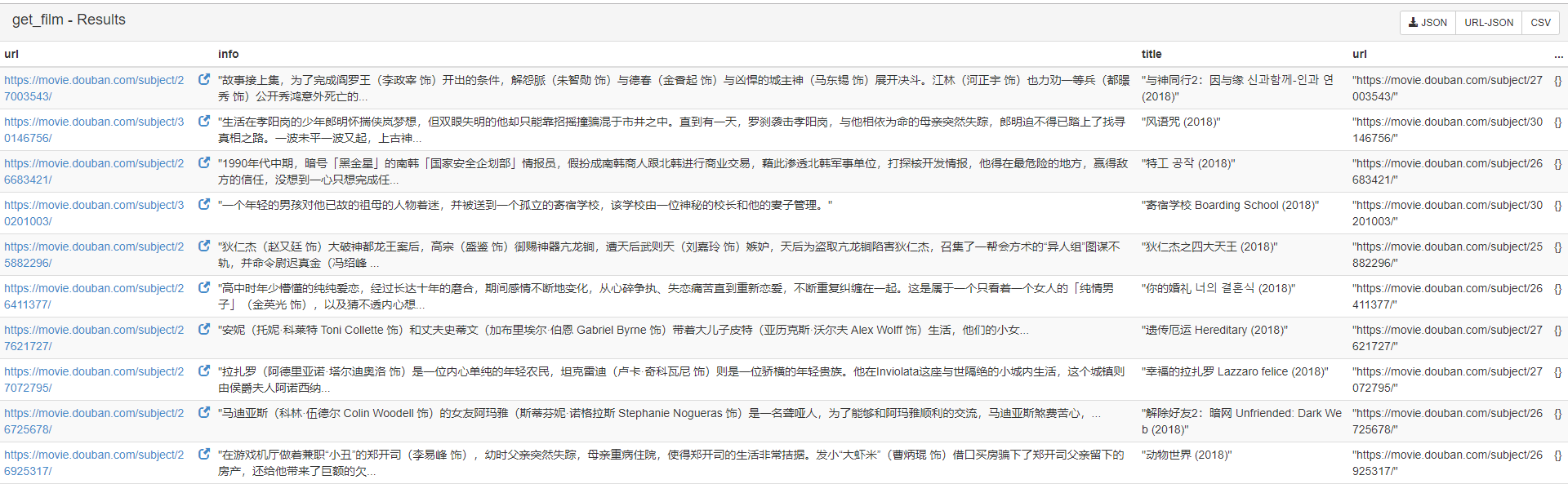
出现结果
当我们实现一个简单的项目时,我们返回头看代码

通过我们点击run的时候,程序会先执行on_start 回调函数,作为爬取的入口点,启动抓取。self.crawl 告诉调度器,我们需要抓取 'http://movie.douban/chart' 这个页面,然后使用 callback=self.index_page 这个回调函数进行解析。拿到所有的电影URL,并进行爬去,再通过detail_page回调,通过pyQuery拿到title与info,所有 return 的内容默认会被捕获到 resultdb 中,可以直接在 DEBUI 上看到。
总结 :
- def on_start(self) 方法是入口代码。当在web控制台点击run按钮时会执行此方法。
- self.crawl(url, callback=self.index_page)这个方法是调用API生成一个新的爬取任务,这个任务被添加到待抓取队列。
- def index_page(self, response) 这个方法获取一个Response对象。 response.doc是pyquery对象的一个扩展方法。pyquery是一个类似于jQuery的对象选择器。
- def detail_page(self, response)返回一个结果集对象。这个结果默认会被添加到resultdb数据库(如果启动时没有指定数据库默认调用sqlite数据库)。你也可以重写on_result(self,result)方法来指定保存位置。
- 更多知识:
- @every(minutes=24*60, seconds=0) 这个设置是告诉scheduler(调度器)on_start方法每天执行一次。
- @config(age=10 * 24 * 60 * 60) 这个设置告诉scheduler(调度器)这个request(请求)过期时间是10天,10天内再遇到这个请求直接忽略。这个参数也可以在self.crawl(url, age=10*24*60*60) 和 crawl_config中设置。
- @config(priority=2) 这个是优先级设置。数字越大越先执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号