



摘要:
计算机科学的论文最大特点在于:
极度重视会议,而期刊则通常只用来做re-publication,也就是说很多期刊文章是会议论文的扩展版,而不是首发的工作。并且期刊的录用到发表中间的等待时间极长,有的甚至需要等上1-2年,因此即使投稿时是最新的工作,等发表的时候也不一定是最新了!也正因为如此,很多计算机期刊的影响因子都低的惊人,很多顶级刊物也只有1到2的印象因子!
因此,要讨论计算机科学的publication,那么请忽视影响因子。 阅读全文
posted @ 2011-11-24 21:52
Bin的专栏
阅读(5498)
评论(0)
推荐(0)
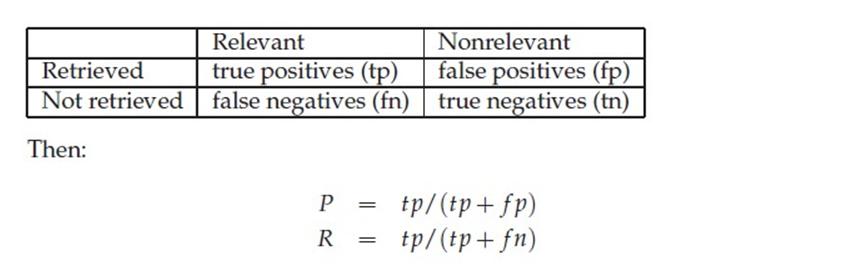 通俗的讲,Precision 就是检索出来的条目中(比如网页)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
下面这张图介绍True Positive,False Negative等常见的概念,P和R也往往和它们联系起来。
通俗的讲,Precision 就是检索出来的条目中(比如网页)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
下面这张图介绍True Positive,False Negative等常见的概念,P和R也往往和它们联系起来。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号