



如何处理AWS EC2上运行的Linux实例宕机,异常重启,内核崩溃等问题
环境
- Amazon Linux
- Amazon Linux 2
- Red Hat Enterprise Linux
- CentOS
- 所有基于Nitro的实例类型(A1类型除外),具体的实例型号, 请参阅基于Nitro的实例
问题
- 什么是Kdump服务
- 如何在Linux操作系统中设置Kdump服务
- Kdump服务需要预留多少存储空间用来存储生成的vmcore文件
- 如何排查系统宕机或异常重启的问题
- 如何在EC2实例上触发Kernel Panic收集vmcore文件
内容
引导概述
kexec 是 Linux 内核的一个补丁,让您可以从当前正在运行的内核直接引导到一个新内核。在上面描述的引导序列中,kexec 跳过了整个引导装载程序阶段(第一部分)并直接跳转到我们希望引导到的内核。不再有硬件的重启,不再有固件操作,不再涉及引导装载程序。完全避开了引导序列中最弱的一环 -- 固件。这一功能部件带来的最大益处在于,系统现在可以极其快速地重新启动。对企业级系统而言,kexec 大大减少了重新启动引起的系统宕机时间。对内核和系统软件开发者而言,kexec 帮助您在开发和测试成果时可以迅速重新启动系统,而不必每次都要再经历耗时的固件阶段。Kdump服务就是在系统崩溃, Kernel Panic时使用kexec软件启动第二内核转储内存中的运行参数和数据的一个工具和服务。
实现原理
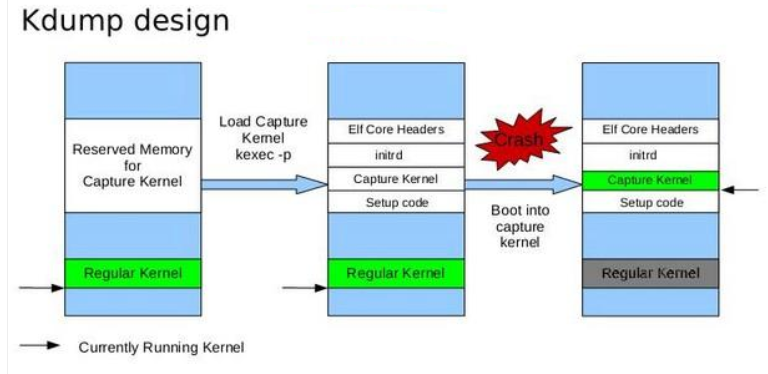
- 通过内核启动项为第二内核预留足够大的空间。
- 启动Kdump服务,第一次启动Kdump服务或对服务配置有任何修改,/boot/目录下均会生成名为initramfs-xxxxxkdump.img文件
- 系统出现Kernel Panic现象,Kdump内核启动,加载initramfs并运行/init,进行内存数据转储。
Kdump执行过程
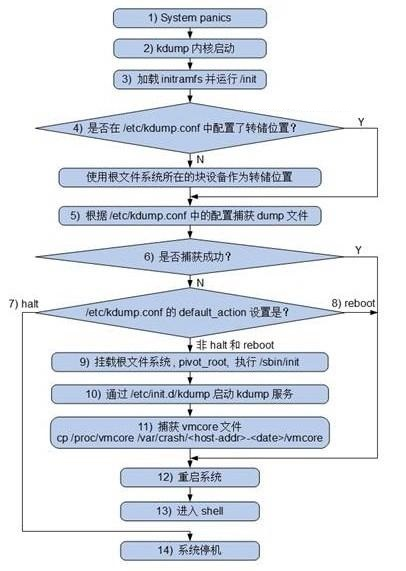
如何在Linux操作系统中配置Kdump服务
* 预留第二内核大小添加crashkernel=168M至/etc/sysconfig/grub文件中GRUB_CMDLINE_LINUX_DEFAULT一行结尾
[root@ip-172-31-31-14 boot]# cat /etc/sysconfig/grub
GRUB_CMDLINE_LINUX_DEFAULT="console=tty0 console=ttyS0,115200n8 net.ifnames=0 biosdevname=0 nvme_core.io_timeout=4294967295 rd.emergency=poweroff rd.shell=0 crashkernel=168M" <----
GRUB_TIMEOUT=0
GRUB_DISABLE_RECOVERY="true"
更新grub2配置
[root@ip-172-31-31-14 boot]# grub2-mkconfig -o /boot/grub2/grub.cfg
重启实例
[root@ip-172-31-31-14 boot]# reboot
以下命令返回输出则说明空间预留成功
[root@ip-172-31-31-14 ec2-user]# cat /proc/iomem | grep -i crash
29000000-337fffff : Crash kernel
- 安装kdump服务,启动Kdump进程,并设置开机自动启动
[root@ip-172-31-31-14 ec2-user]# yum install kdump
[root@ip-172-31-31-14 ec2-user]# systemctl start kdump
[root@ip-172-31-31-14 ec2-user]# systemctl enable kdump
- 测试Kdump服务是否可以正常工作
通过以下命令触发系统Kernel Panic, 此命令会直接引起系统宕机。
[root@ip-172-31-31-14 ec2-user]# echo c > /proc/sysrq-trigger
查看默认路径/var/crash中是否可以收集到vmcore
[root@ip-172-31-31-14 ec2-user]# tree /var/crash/
/var/crash/
└── 127.0.0.1-2019-12-13-06:12:39
├── vmcore
└── vmcore-dmesg.txt
Kdump配置注意事项
1. crashkernel大小推荐,4G-64G内存大小,推荐设置为160M, 64G-1T内存大小,推荐设置为256M, 1T以上内存大小,推荐设置为512M。crashkernel预留内存不够,会造成第二内核无法启动,vmcore收集失败。 2. 转储目录/var/crash,推荐大小大于内存大小,根据工作负载的不同,vmcore文件大小不确定,但是最大不会超过物理内存大小。如何排查系统宕机或异常重启的问题
正常的Linux系统重启,可以在/var/log/messages日志中观察到以下日志, 如何日志中查看到以下日志,可以排除是由于系统异常导致的重启。 * shutdown: shutting down for system reboot * init: Switching to runlevel: 6 * exiting on signal 15 * Got SIGTERM, quitting.系统异常导致的宕机,EC2 CloudWatch会显示实例健康检查失败, 但是系统健康检查正常。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号