



Minikube 本地部署 Jupyter 集群
背景
Jupyter 是兼备优秀的编程体验和交互体验的在线 IDE,它能让你的代码不再受限于自己的电脑环境,也不只是编程语言本身,而是可以结合数学公式、Markdown、命令行等各种语法和指令,在更高性能的服务器以更灵活的交互方式,随处运行,随时可见结果。也正因为这些特性,它在教学、大数据分析、机器学习等领域都能助开发者一臂之力

在最近一年维护和使用 Jupyter 服务的过程中,我部署 Jupyter 的方式也经历了从 linux 服务器单点,到 minikube 本地部署模拟集群,再到生产环境 k8s 正式部署集群的升级过程。之所以要将 Jupyter 从单点升级成集群,主要是为了解决单点会遇到的可靠性、可扩展性和可维护性等问题

上面的问题要解决,首先需要一套可以管理集群的基础服务,这个服务就是 Kubernetes ,而借助 Jupyter 官方提供的 helm chart,几行配置几条指令,就可以部署成集群了,“理论上”整个过程可以非常顺滑
当然,上线生产之前必不可少的过程是测试。在这篇文章中,我们就以自己电脑作为基本环境,借助 minikube 和 k8s 生态下的工具, 部署一套类似生产环境的 Jupyter
事不宜迟,让我们先从了解 Jupyter 服务开始,一步步深入了解如何在本机玩转 Jupyter 集群吧
Jupyter 生态
Jupyter 在组件通信、页面交互和后台运行环境上,都具有各司其职的组件,这也形成了 Jupyter 独一无二的生态

若从最关键的用户使用场景入手,最重要的组件有以下四个:
-
JupyterHub: 登录页面,只提供简单的用户信息输入框( 不过默认的 Spawner 和 Authticator 也在其源码中 )
-
JupyterLab: 新一代的 Notebook 编辑器,界面功能更丰富,且支持通过插件系统扩展更多功能(如 git、资源查看器等)
-
Spawner: 登录 JupyterHub 后实际运行的 IDE(主要是 Notebook 或者 JupyterLab ),IDE 可以自定义运行环境: 跑在本地、 k8s 或者 yarn 等等。一个用户 IDE 进程也可以称作 Jupyter Server
-
Ipykernel: 用户运行每一个 Notebook,又会在 Spawner 运行的服务器上启动一个个负责运行代码的进程。它既是进程,也是服务器上预装的不同开发环境( 比如可选择在不同 Python 版本作为运行代码的环境 )
只是简单介绍这些组件的概念,并不能讲清楚它们之间的协同和交互机制。相信通过接下来的实践,它们各自的发挥的作用都会在我们面前清晰展现出来
环境准备
既然要在 k8s 部署 Jupyter,第一步当然需要把 k8s 先启动起来
在自己电脑启动 k8s 可选的工具有 minikube, kind, k3s, microk8s 等,它们实际启动集群的过程是差不多的。这里笔者从功能的完善程度考虑,选择了 minikube
在文章最后会提到 k3s 也可作为在电脑资源受限情况下的备选
minikube
minikube 是一个在本地快速启动 k8s 集群的工具,由 kubernetes 社区开源,支持多种虚拟化运行环境(Docker、Hyper-V、VirtualBox、podman 等)。它基于一个轻量级虚拟机 coreboot 启动,因此 minikube 也支持跨平台
minikube 可执行文件可以直接从 官方仓库 或者 官方网站 下载
Docker 镜像源配置
注: 由于 minikube 网络插件的依赖,会导致非 root 权限运行的 podman 无法启动 minikube,笔者为测试 root 的 podman,目前还是建议使用 Docker
Docker 的具体的安装方式这里就不赘述了。不过还是要提一下镜像源的配置
网易云、中科大等之前常用的比较官方的镜像源现在都用不了,其他第三方可用的镜像源可以 参考这里 或 这里, 目前可用的部分镜像源如下:
// vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://docker-0.unsee.tech",
"https://docker.1ms.run",
"https://docker.m.daocloud.io"
"https://docker.xuanyuan.me",
]
}
注: 一切网络问题都不是等等就能好的,再等也是浪费时间,这也是在开始就要把国内镜像源这种信息告诉大家的原因
minikube 安装和启动
启动 minikube 遇到的第一个坑,就是经典的国内网络问题: 下载镜像和二进制文件时不太顺畅
首先 minikube 运行的基础系统镜像 kicbase 会按照 docker.io、 gcr.io 和 github release 的顺序尝试下载。然而这些下载地址都在外网,都可能下载不成功
其次,minikube 还会下载 kubectl, kubelet 和 kubeadm 这三个用于访问和管理 k8s 集群的可执行文件(下载后放在虚拟机内部)在设置了 image-mirror-country=cn 参数后,下载地址会被替换成 kubernetes.oss-cn-hangzhou.aliyuncs.com,但是这个地址并没有提供这些文件,所以还需要配置正确的 binary-mirror 参数
(不得不说坑是真的多啊)
正是因为有这些问题,建议通过源码编译来生成 minikube 二进制文件,方便快速修正镜像下载问题
# linux 下载 minikube
curl -LO https://github.com/kubernetes/minikube/releases/download/v1.36.0/minikube-linux-amd64
# windows
curl -LO https://github.com/kubernetes/minikube/releases/download/v1.36.0/minikube-windows-amd64.exe
# github 加速
curl -LO https://ghfast.top/https://github.com/kubernetes/minikube/releases/download/v1.36.0/minikube-linux-amd64
curl -LO https://ghfast.top/https://github.com/kubernetes/minikube/releases/download/v1.36.0/minikube-windows-amd64.exe
# 安装 minikube
sudo install minikube-linux-amd64 /usr/local/bin/minikube
# 通过源码编译 minikube
git clone https://github.com/kubernetes/minikube
git checkout tags/v1.36.0
## 替换 docker.io/kicbase/stable 下载镜像源
sed -i "s#\"docker.io/#\"docker.1ms.run/#g" pkg/drivers/kic/types.go
## 编译
make
mv out/minikube /usr/local/bin/
# 启动 k8s 1.33.1 版本
minikube start --kubernetes-version=v1.33.1
# “最终版”启动 k8s 参数 (适配国内网络)
# --v 和 --log_file: 增加日志输出,并打印到指定日志文件中,方便定位问题
minikube start --kubernetes-version=v1.33.1 --iso-url https://ghfast.top/https://github.com/kubernetes/minikube/releases/download/v1.35.0/minikube-v1.35.0-arm64.iso --image-mirror-country=cn --image-repository=registry.cn-hangzhou.aliyuncs.com/google_containers --binary-mirror https://files.m.daocloud.io/dl.k8s.io/release --v=8 --log_file /tmp/test.log
# 扩展: 限定运行资源、磁盘大小等
minikube start --cpus=2 --memory=4096 --disk-size=20g ...
# 扩展: 指定镜像下载路径
export MINIKUBE_HOME=/opt/minikube
顺利启动 minikube 后,我们在命令行可以通过 minikube 虚拟机内部的 kubectl 来访问集群,或者为了操作更方便可以在主机也安装 kubectl( minikube 启动时已经在本机设置好了 ~/.kube/config )
# kubectl 安装
curl -LO https://dl.k8s.io/release/v1.33.0/bin/linux/amd64/kubectl
curl -LO https://dl.k8s.io/release/v1.33.0/bin/windows/amd64/kubectl.exe
# 国内源
curl -LO https://files.m.daocloud.io/dl.k8s.io/release/v1.33.0/bin/linux/amd64/kubectl
curl -LO https://files.m.daocloud.io/dl.k8s.io/release/v1.33.0/bin/windows/amd64/kubectl.exe
# 或者通过 k8s 源码安装
git clone https://github.com/kubernetes/kubernetes
make kubectl
mv _output/local/bin/linux/amd64/kubectl /usr/local/bin
# 获取所有 pod
kubectl get pods --all-namespaces
# 使用 minikube 自带的 kubectl
minikube kubectl -- get pods --all-namespaces
通过 kubectl get pods -A 查看所有 pod,可以看到 minikube 启动了一套标准的 k8s 组件,简单说明每个组件的作用

-
CoreDNS: k8s 集群内部的 DNS 服务,负责提供 k8s 内服务的访问地址,前身是 kube-dns,现在发展成 CNCF(Cloud Native Community Foundation 云原生基金会) 中的独立项目
-
ETCD: k8s 的元数据服务,记录了当前集群的所有节点、配置、服务、密钥等等信息
-
kube-apiserver: 提供k8s资源( pod, deployment, service 等)的 restful api 接口
-
kube-controller-manager: 通过 api 对集群资源进行管理和控制,在资源出现异常的时候自动恢复
-
kube-proxy: 在每个 k8s 节点(node)上运行,负责 监测 apiserver 收到的用户请求,并将请求转发到具体的 Pod 进行处理
-
kube-scheduler: 负责将 Pending 状态的 pod 分配到最合适的 node 上运行
-
storage-provisioners: 在服务需要挂载存储目录的时候,自动从本地分配一块目录空间给服务使用
dashboard
dashboard 是 kubernetes 官方提供的 k8s 集群看板,通过它能够看到集群的基本状态、资源、日志等,尽管功能简单,还是建议在首次启动时候打开它,方便后续查看 pod 日志定位问题
minikube 内置 dashboard, 执行 minikube dashboard 即可打开


helm
在不使用 k8s,只用 docker 如何启动,最简单的方案通常会用到 docker compose,在 docker-compose.yaml 配置文件中编写集群每个节点部署的服务和配置,比如 flink 的官方示例,一个 jobmanager 和一个 taskmanager 组成的集群

但这种方式对于生产环境部署大规模集群的目标,就有点力所不及了。自动发现和恢复故障节点、自动扩缩容、动态升级和配置变更等方面的支持,还是 k8s 更擅长
当然 k8s 这套生态的门槛也比较高,相关的组件和配置也更多,如何在 k8s 也像 docker compose 一样能丝滑一键启动集群呢?Helm 就是我们的答案
Helm 是 CNCF 社区孵化的集群服务编排和部署工具,它将一个服务在 k8s 部署需要的服务以及依赖的资源,抽象成了可以通过 golang template 批量生成的配置,配置的格式也统一为 yaml
从 2016 年发展至今,Helm 已经成为了在 k8s 平台管理服务发行包和发布服务的主流标准
Helm 的几个概念这里也简单介绍下,稍做了解就好
-
chart: 服务定义,包括服务名、服务版本、依赖 k8s 版本
-
value: 启动服务所需所有资源的配置默认值,可在启动时加上 -f new.yaml 覆盖默认配置文件
-
template: k8s 相关资源( deployment, service, pvc, configmap 等)的配置模板,和 values 结合生成完整的资源清单
-
release: chart 可以发布到 k8s 的版本
-
repo: 用于存放所有 chart release 打包文件的服务器

大部分支持云原生的开源组件,官方都会提供 Helm chart,让我们只修改少量的配置,即可完成集群部署
Helm 的安装也非常简单,只需下载一个二进制文件
# linux
curl -LO https://get.helm.sh/helm-v3.18.2-linux-amd64.tar.gz
# mac
brew install helm@stable
curl -LO https://get.helm.sh/helm-v3.18.2-darwin-arm64.tar.gz
# windows
choco install kubernetes-helm
https://get.helm.sh/helm-v3.18.2-windows-amd64.zip
Jupyter
环境准备工作终于万事俱备,各位久等,我们终于要来启动 Jupyter 服务了
这里我们需要用到 Jupyter 官方提供的 chart zero-to-jupyterhub-k8s
启动服务
# 在本地添加 jupyter 官方 repo
helm repo add jupyterhub https://hub.jupyter.org/helm-chart
helm repo update
# 启动
# vim start.sh
RELEASE=jhub
NAMESPACE=jhub
VERSION=4.2.0
# 彻底清理上次启动 Jupyter 的所有资源
helm uninstall ${RELEASE} -n ${NAMESPACE}
kubectl delete daemonsets,replicasets,services,deployments,pods,jobs,rc,ingress,persistentvolumes,persistentvolumeclaims --all --namespace=jhub
# 将 Jupyter 组件安装到 jhub 的命名空间(namespace)下
helm upgrade --cleanup-on-fail \
--install $RELEASE jupyterhub/jupyterhub \
--namespace $NAMESPACE \
--create-namespace \
--timeout 600s \
--version $VERSION
成功启动后查看 jhub 这个 namespace 下相关的 pod 如下:

默认方式启动后,再通过执行 minikube service proxy-public -n jhub --url ,即可随机开放一个端口以供访问 JupyterHub 登录页面了
![]()
Hub 默认使用 DummyAuthenticator 作为用户登录校验器 ( values.yaml 中的 hub.config.JupyterHub.authenticator_class 默认值 ),所以我们可以使用任意用户名 + 任意密码登录
登录后,默认的界面不是最经典的 Notebook 而是功能更现代更丰富的 JupyterLab( JupyterHub 在 2.0 版本后就将用户登录后默认跳转 url 指向了 /lab,参考配置 : c.Spawner.default_url )

Jupyter on k8s
相较于直接通过容器或者运行 JupyterLab 命令启动的 Jupyter,这套 Jupyter helm chart 在哪里做了优化呢?我们可以从启动的 Pod 中一步步探究竟

-
hub: JupyterHub,提供登录页面
-
continuous-image-puller: 在新的 node 加入 k8s 集群的时候,自动在该 node 拉取 Jupyter 所需要的镜像,避免用户在登录后因拉取 Jupyter 服务镜像长时间等待
-
proxy: JupyterHub 的上层代理, 即 configurable-http-proxy
-
user-scheduler: 通过 k8s 的调度策略让 Jupyter 相关的 Pod 尽量分配到同个节点,资源更紧凑
-
singleuser.storage: 每个用户首次启动时都会自动申请一个 pv, 后续用户重新登录,重启 notebook 也能使用之前已经保存的文件
-
singleuser.cpu & singleuser.memory: 单个 Notebook 的资源限制, 默认对 cpu 无限制,内存最多 1G
功能概述
在 JupyterLab 界面你能看到的几个基本功能有 Notebook 、Console 和 Terminal 等
具体功能有机会可以单开一篇详细介绍,这里只提几点注意的
-
你在其中一个 Jupyter Server 中编写的 Notebook,启动其他镜像也能看到,因为是同一个目录
-
打开 Terminal 并执行 pwd 你会看到每个用户的主目录都是 /home/jovyan ,这是因为 Notebook 镜像设置了默认用户就是 jovyan ,但因为每个用户都会申请独立的存储挂载到 Notebook,所以实际目录是分开的
-
Notebook 快捷键和 ipykernel 语法非常强大,强烈建议在深度使用 Notebook 之前先了解这些技巧
自定义配置
那么到这里我们已经通过 minikube + helm 在本地成功启动了类生产环境启动的一个 Jupyter 集群了,不妨先喝杯茶🍵 因为接下来又是一个重头戏了
我们需要先转换一下思路,从 Jupyter 的运维者变成它的使用者,来看看 Jupyter 会有哪些实际的需求,我们又可以怎样修改 Jupyter chart 的配置,让它实现这些需求
如果你想了解 Jupyter chart 每一项配置的详细说明,可以翻阅官方文档 Customization Guide 和 Customizing User Environment
values.yaml
values.yaml 包含了整个 Jupyter 服务的大部分默认配置,其他配置都由这里衍生。它的配置内容会通过 k8s secret 分发到 JupyterHub 的 Pod 中,对后续 Hub 的启动和 Notebook 的启动产生作用
这里列举其中一部分配置的作用:
-
db: JupyterHub 默认使用 sqlite 作为元数据库,用于记录服务状态、登录用户信息和token等。Hub 启动前需要申请 PV 存储 sqlite db 文件,Hub 重载后数据不会丢失
-
hub: 定义 JupyterHub 的登录方式、登录后的 Notebook 镜像选择列表等
-
culler: 不活跃用户进程超时后自动清理,默认打开,超时时间1小时
-
singleuser: 定义用户登录后默认使用的 Notebook 镜像,以及扩展镜像选择等
修改启动镜像源
通过 helm install 首次启动 Jupyter,需要拉取的镜像也大多在外网,但主机配置的 /etc/docker/daemon.json 对 minikube 虚拟机是不生效的。我们可以手动在配置中把这些镜像都替换成国内源,下一节设置 Notebook 启动镜像时也会用到这种方式来给镜像下载加速(放心,这一步之后,就再没有镜像下载的问题了)
这里列几个常见的镜像下载地址替代方式
-
docker.io -> docker.1ms.run / docker-0.unsee.tech / docker.m.daocloud.io
-
quay.io -> quay.m.daocloud.io
-
gcr.io -> gcr.m.daocloud.io
-
ghcr.io -> ghcr.m.daocloud.io
-
registry.k8s.io -> registry.cn-hangzhou.aliyuncs.com/google_containers / k8s.m.daocloud.io
在 values.yaml 中修改方式如下:
# vim config.yaml
hub:
image:
name: quay.m.daocloud.io/jupyterhub/k8s-hub
proxy:
chp:
image:
name: quay.m.daocloud.io/jupyterhub/configurable-http-proxy
secretSync:
image:
quay.m.daocloud.io/jupyterhub/k8s-secret-sync
scheduling:
userPlaceholder:
image:
name: registry.cn-hangzhou.aliyuncs.com/google_containers/pause
userScheduler:
image:
name: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler
prePuller:
hook:
image:
name: quay.m.daocloud.io/jupyterhub/k8s-image-awaiter
pause:
image:
name: registry.cn-hangzhou.aliyuncs.com/google_containers/pause
singleuser:
image:
name: quay.m.daocloud.io/jupyterhub/k8s-singleuser-sample
networkTools:
image:
name: quay.m.daocloud.io/jupyterhub/k8s-network-tools
Notebook镜像选择列表
默认的 Notebook 镜像为 jupyterhub/k8s-singleuser-sample,它自带 jupyter 运行所需的基础环境,但是对于实际的开发场景,肯定还需要安装很多其他 Python 依赖的。在 Notebook 镜像中提前装好 Python 依赖,减轻用户操作负担,是非常经典的需求
好在官方的镜像仓库 jupyter/docker-stacks 已经为我们提供了一些扩展镜像作为参考,有适用于数据开发的 scipy-notebook、适用于机器学习的 tensorflow-notebook 等。我们可以修改 singleuser.profileList 把这些镜像加进来,给用户更多的开发环境选择
# vim config.yaml
singleuser:
profileList:
- display_name: "singleuser"
description: "singleuser default"
default: true
kubespawner_override:
image: 'docker-0.unsee.tech/jupyterhub/singleuser:5.3'
- display_name: "scipy"
description: "scipy"
kubespawner_override:
image: 'docker-0.unsee.tech/jupyter/scipy-notebook:python-3.11'
- display_name: "tensorflow"
description: "tensorflow"
kubespawner_override:
image: 'docker-0.unsee.tech/jupyter/tensorflow-notebook:python-3.11.6'
这里也是将每个镜像都设置了具体的 tag 名,避免每次启动时都需要从镜像仓库拉取 latest 镜像
注: hub.extraConfig 也可以设置 c.KubeSpawner.profile_list,两种方法最后生成的 Hub 配置文件都是类似的,区别在于 prePuller 是否会解析镜像列表。前者添加的镜像在 Jupyter chart 启动阶段不会预拉取( 参考 _helpers-daemonset.tpl 文件和 Relevant image sources ),这会导致在 k8s 节点未下载过的镜像,用户启动后需要先等待镜像下载完成才能进入 JupyterLab 界面,等个几分钟也是可能的,体验很差
在 profileList 添加多个镜像后,登录 JupyterHub 就不会立刻跳转 Notebook 了,而是先展示这些镜像列表,给用户选择

笔者平时对接负责数据开发的同学比较多,scipy-notebook 比较适合他们的开发场景,镜像中安装的依赖也非常实用,做自定义镜像的时候也可以考虑将它们加进来,分类如下:
-
数据可视化: altair, bokeh, matplotlib, seaborn
-
数据采集: beautifulsoup4, sqlalchemy
-
数据计算: bottleneck, numba, dask, statsmodel, sympy, patsy, scikit-learn, scipy
-
数据导出/格式化: openpyxl, pandas, pytables, h5py, protobuf, dill
-
Lab插件: jupyterlab-git
登录密码
基于默认的 DummyAuthenticator 我们也可以对登录方式稍做限制,比如限制哪些用户允许登录、规定必须使用哪个登录密码
hub:
config:
Authenticator:
admin_users:
- can_login_user_admin
allowed_users:
- can_login_user_normal
DummyAuthenticator:
password: login_password
JupyterHub:
authenticator_class: dummy
对接 ldap
尽管可以限定登录密码,但 DummyAuthenticator 的校验方式依然太简单太不安全了,所有用户都使用同一密码。对公司来说肯定需要专门的身份认证服务的,比如 LDAP
在本地我们想快速启动 LDAP 可以通过 osixia/docker-openldap 封装的镜像快速启动,然后 Jupyter 通过 host.minikube.internal 域名来访问暴露在宿主机的 LDAP 端口
# 启动 ldap 容器, 并预设 cn=myreadonly,dc=example,dc=com 作为可以检索所有用户信息的只读用户
docker run --name openldap --network ldap_network --hostname openldap -e LDAP_DOMAIN=example.com -e LDAP_ADMIN_PASSWORD=readonly_pwd -e LDAP_READONLY_USER=true -e LDAP_READONLY_USER_USERNAME=readonly -e LDAP_READONLY_USER_PASSWORD=readonly -p 30389:389 -p 30636:636 -d osixia/openldap:1.5.0
hub:
config:
JupyterHub:
authenticator_class: ldapauthenticator.LDAPAuthenticator
LDAPAuthenticator:
lookup_dn: true
use_lookup_dn_username: false
use_ssl: false # 登录时不使用 ssl
tls_strategy: insecure # 登录时不使用 tls
lookup_dn_search_password: myreadonly # 配只读用户名
lookup_dn_search_user: cn=myreadonly,dc=example,dc=com
lookup_dn_user_dn_attribute: cn
server_address: host.minikube.internal # 可以访问到主机的域名
server_port: 30389
user_attribute: givenName
user_search_base: ou=users,dc=example,dc=com
allow_all: true # 允许所有用户登录
关于 LDAP 如何添加用户,可以参考 Creating users in an LDAP。先创建一个组织 ou=users,dc=example,dc=com ,再在这个组织下创建具体的用户 uid=具体用户名,ou=users,dc=example,dc=com
指定开放端口
注: 这种通过 nodePorts 暴露端口的方法,适用于直接在机器上部署的 k8s 集群(比如通过 sealos 工具部署 )。但 minikube 是在虚拟机之上启动的 k8s,此方法不适用
proxy:
service:
type: NodePort
nodePorts:
http: 30080 # 注意: nodePort 受 apiserver 的 service-node-port-range 参数限制,默认必须在 30000-32767 之间
https: 30443
但是 minikube 是通过虚拟机的方式启动 k8s ,和主机并不属于同一个网络环境,需要通过 minikube service 或者 kubectl port forward 指令开放到宿主机
# 随机开放端口
minikube service proxy-public -n jhub --url
# 通过 kubectl 指令,将 Hub 端口映射到主机的指定端口
# 加上 --address='0.0.0.0' 参数以供内网其他电脑访问
kubectl port-forward svc/proxy-public 30080:80 -n jhub
黑暗主题
作为一个黑暗模式强迫症, 笔者不管是用什么 IDE 第一时间都是先把主题设置成 dark mode,Jupyter 也不例外
(不过有一个说法是黑暗模式对眼睛不太好)
JupyterLab 默认主题是 light mode,为了让自己能在每次重新启动 Jupyter 都自动使用黑暗模式,需要把默认主题修改成 dark mode
从界面的 Settings -> Theme 修改主题的话,会在 /home/jovyan/.jupyter/lab/user-settings/@jupyterlab/apputils-extension/themes.jupyterlab-settings 这个配置文件中新增一项 "theme" 属性来实现配置变更。那么要修改默认主题配置,第一反应就是在构建镜像时直接把这个文件修改了。但这个文件路径有一个特殊点在于它是 PV 的挂载路径( /home/jovyan ),而 PV 默认又是会从本地申请一个新的目录挂载进去的,这会导致我们在镜像中打入到这个路径的配置文件最终是找不到的
所以这个配置的初始化,不应该放在镜像构建阶段,而是在 Pod 启动时,也就是初始化 Pod 阶段完成
因此思路变成了在镜像中添加一个初始化配置的脚本
# vim images/singleuser-sample/initandstartjupyter
config_home=${HOME}/.jupyter/lab/user-settings/@jupyterlab/apputils-extension
mkdir -p ${config_home}
# 设置主题配置为 dark mode
echo '{"theme": "JupyterLab Dark"}' > ${config_home}/themes.jupyterlab-settings
# 启动 jupyter
jupyterhub-singleuser
然后修改 Dockerfile 的 CMD,在启动 JupyterLab 前先执行这个脚本 (但关于这个 CMD 又有一个坑 请看后续)
# Dockerfile
# 在 dockerfile 设置 pip index 加速镜像构建
ENV PIP_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple
# 拷贝脚本 initandstartjupyter 到镜像内,并设置权限
COPY --chmod=0755 initandstartjupyter /
CMD [ "/initandstartjupyter" ]
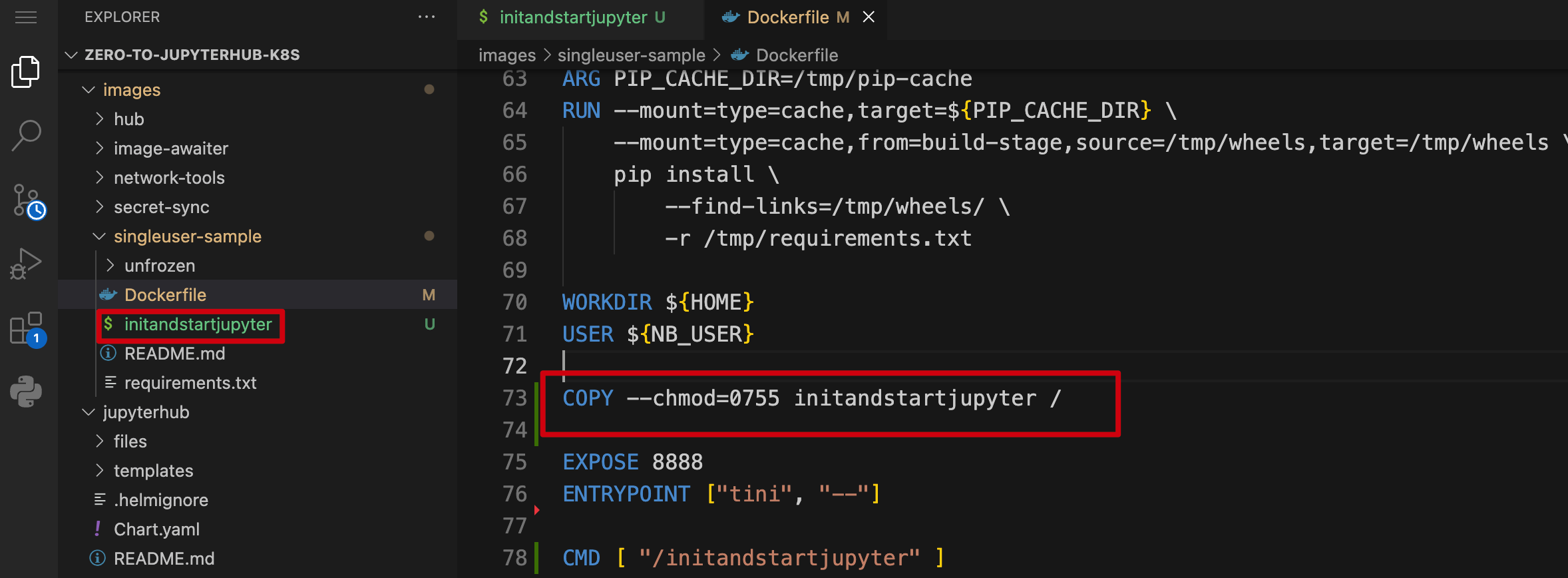
接下来我们需要构建新的 singleuser 镜像。为了不覆盖默认镜像,我把镜像名设置成 jupyterhub/singleuser_withdark
关于构建的镜像 tag 要注意最好不要用 latest,因为 latest 会导致启动时每次都向官方镜像仓库拉取最新的( kubespawner 的参数 image_pull_policy 的默认策略 ),而这个镜像是我们在本地构建的,官方仓库并没有,会导致报错
# 注意: 需要先将 docker 运行环境切换到 minikube 虚拟机,否则构建的镜像是在主机的 docker 中,minikube 虚拟机是访问不到的
# 切换到 minikube 的虚拟机 docker 环境
eval $(minikube docker-env)
# 构建镜像
docker build -t jupyterhub/singleuser_withdark:1.0.0 /Volumes/dream/workspace/router1/coding/zero-to-jupyterhub-k8s/images/singleuser-sample
# 退出 minikube 的 docker 环境
eval $(minikube docker-env -u)
最后一步是把 withdark 镜像添加到 profileList 中
# config.yaml
# 修改全局 cmd,这里对 singleuser.profileList 也是生效的
singleuser:
cmd: "/initandstartjupyter"
# 或者在需要配置黑暗主题模式的镜像才添加 cmd, 此时 singleuser.cmd 可以不配置,保持默认。实际启动时会以 kubespawner_override.cmd 为准(参考 jupyterhub_config.py 中设置 c.Spawner.cmd 的逻辑 )
profileList:
- display_name: "singleuser dark"
description: "singleuser dark"
kubespawner_override:
image: 'jupyterhub/singleuser_withdark:1.0.0'
cmd: '/initandstartjupyter'
为什么在 kubespawner_override 或者 singleuser 中还需要设置 cmd 呢,前面在 Dockerfile 不是已经覆盖了吗?这是因为 singleuser.cmd 在 values.yaml 中是有默认值的( jupyterhub-singleuser ),并不是空值,即使不声明 cmd,Dockerfile 的 cmd 也是会再被覆盖掉
(还是要认真看默认配置啊...)
共享磁盘
除了功能性的需求,有的需求是和体验优化相关的,这些需求比较隐蔽,但实现之后往往会有事半功倍的效果
譬如对于第一次使用 Jupyter 的用户,登录 Jupyter 他想做的第一件事并不是写代码,而是最好直接就有个教程,教他怎么使用 Notebook,就不用再跑去翻阅官方文档了
这时如果他能直接看到类似 donnemartin/data-science-ipython-notebooks,以 Notebook 为展现形式的教学工程,他就可以直接把代码运行起来,甚至还能了解到 Notebook 的更高阶用法,体验非常好

有两种方案可以实现这个效果
-
直接把教程代码打入到 Notebook 镜像中,好处是方案实现起来比较容易,不过镜像体积会增大
-
每个 Notebook 都共享一个存放教程代码的只读目录(避免相互修改覆盖),好处是不会影响镜像体积,但正因为目录只读,所以用户只能查看,不能修改这些代码
这两种方案各有优劣,实际场景下,肯定有的用户是希望可以一边修改代码一边运行的,因此第一种方案更合适
不过通过第二种方案,我们还能了解到如何通过 extraVolumes 配置共享磁盘的方法,因此这里稍做介绍
首先我们需要创建一个 PVC ( PersistentVolumeClaim ) 作为共享存储,并设置为只读权限
# vim shared-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: jupyterhub-shared-volume
namespace: jhub
spec:
accessModes:
- ReadOnlyMany # 只读
resources:
requests:
storage: 2Gi
执行 kubectl apply -f shared-pvc.yaml 然后在 singleuser.storage.extraVolumes 和 extraVolumeMounts 在 /home/jovyan 下面添加一个共享目录,挂载到这个共享存储
singleuser:
storage:
extraVolumes:
- name: jupyterhub-shared
persistentVolumeClaim:
claimName: jupyterhub-shared-volume
extraVolumeMounts:
- name: jupyterhub-shared
mountPath: /home/jovyan/shared
配置好之后重启 Jupyter chart,我们就能测试看到多个用户登录后,在各自的根目录下都有 shared 共享目录的效果了

不过,第一次创建的 PV 里面还是空目录,还需要放置教程代码。方法稍微有点绕,因为这个目录对于 Jupyter 用户来说是只读的,所以 Jupyter 上没有权限上传,需要利用 storage-provisioner 挂载本地目录的机制,登录 minikube 虚拟机,找到这个共享目录再下载代码
# 登录 minikube 虚拟机
minikube ssh
# 进入默认的 stroage-provisioner 挂载目录
cd /var/hostpath-provisioner/jhub/jupyterhub-shared-volume
# 安装 git
sudo apt -y update
apt -y install git
# 下载教程代码
git clone https://github.com/donnemartin/data-science-ipython-notebooks
限制资源
在 k8s 部署的另一个特性也是可以对资源进行合理的限制,避免其中一个用户运行的脚本占用太多资源,影响了其他用户正常使用
# 全局限制用户使用 Notebook 的 CPU、内存和磁盘资源
singleuser:
cpu:
limit: 1
guarantee: 1
memory:
limit: 1G
guarantee: 1G
storage:
capacity: 1Gi
# kubespawner 对镜像进行限制
# 对于一些要使用 GPU 的镜像,可以将资源限制适当调大
profileList:
- display_name: "singleuser"
description: "singleuser default"
default: true
kubespawner_override:
image: 'docker-0.unsee.tech/jupyterhub/singleuser:5.3'
cpu_limit: 1
mem_limit: '1G'
mem_guarantee: '512M'
然后启动 singleuser 的默认镜像,执行一段会申请超过 1G 内存空间的程序,我们会发现 notebook 直接提示触发 kill 和自动重启了

注: 如果你通过 top 指令或者是 psutil 库查看系统总资源,会发现和实际限制的配置不一致,比如限制 1G 内存,实际看到的还是有十几G。这是因为 top 和 psutil 看到的都是整个虚拟机的资源,而 k8s 是通过 cgroup 来限制 pod 资源的,cgroup 相关的资源限制文件在 /sys/fs/cgroup 目录下
对接外部数据库
用来存储元数据的数据库默认为 sqlite,尽管会使用 PV 进行持久化,但真的要去查数据的时候还是不如外部数据库方便的
因此如果你本地还部署了 mysql,可以考虑把 JupyterHub 使用的数据库切换成 mysql
# 配置使用 mysql 作为数据库
hub:
db:
type: mysql
url: mysql+pymysql://root:root_pwd@host.minikube.internal:3306/jupyter # 连接开放在宿主机330端口的 mysql
upgrade: true # 首次启动时需要设置 upgrade: true 以初始化数据库
culler
culler 是 jupyter 用来定期清理 Jupyter Server 进程的工具,它的清理机制是判断用户上次在 JupyterLab 界面有活动的间隔时间,是否有活动,和这个用户是否有运行中的代码无关,即使用户依然有代码未结束,长时间未操作页面,进程也会被清理
默认的清理判断超时时间为 3600s ,也就是一小时, 但这对于实际的数据分析和机器学习等场景肯定是不够,因此可以适当调大一些
注意:
cull:
enabled: true
timeout: 604800 # 7 days
every: 300
支持用户启动多个 notebook
有些用户会有在多套 Python 环境下同时开发代码的需求,比如一套 Python 用来做数仓查询,另一套 Python 环境用于 BI 制作。可以通过 allowNamedServers 配置来支持
hub:
allowNamedServers: true
namedServerLimitPerUser: 5

不过从体验上来看并不是很方便,用户需要先跳转到 control panel ,对已启动的 server 命名,才能启动新的 server
admin ui
最后介绍的自定义配置,是对运维比较有帮助,在定位具体用户反馈问题时可以用上的 admin ui
hub:
config:
Authenticator:
admin_users:
- adminuser1
- adminuser2
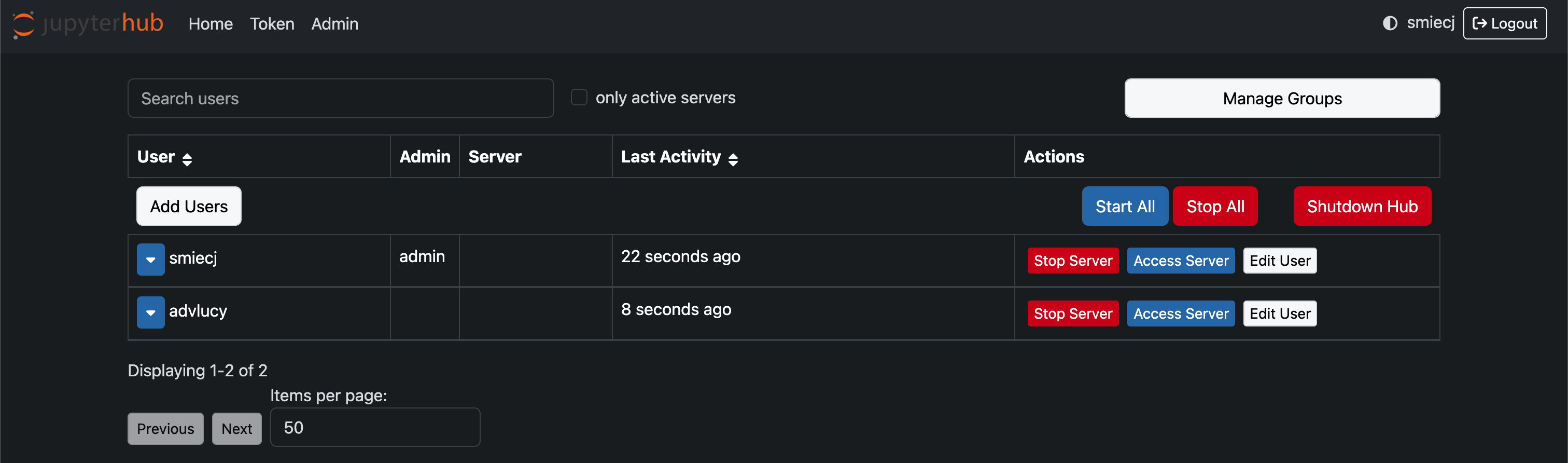
管理员可以在管理页面进行的操作主要有:
-
查看已登录用户
-
管理用户组
-
查看所有运行的 server 状态
-
停止任意 server
-
登录其他用户的 server
最后一点在定位问题时特别有用: 当用户反馈 "我执行一段 Python 代码有报错",但是同样代码在你自己的 Notebook 环境却是正常跑的,原因有可能是他自己装了其他的 Python 依赖有问题,那你就可以登录他的 Notebook 去定位
扩展
以下是笔者在安装和使用 Jupyter 过程中的其他经验分享
Helm 本地仓库
在通过 Helm 安装集群的时候,我们依然会遇到老朋友: 网络不佳,导致拉取 repo 要很久的问题,于是我就去找 Helm repo 是否也有统一的国内源
但发现它不像各个语言的依赖仓库,基本都有大厂维护的国内源。Helm repo 并没有 “官方” 源,每个开源组件自己维护自己的 repo
所以对于大公司来说一般会自建 helm repo,定期同步开源组件官方 repo。当然笔者想的是先解决眼前的问题,看看如何将 Jupyter 的官方 chart 打包,并直接通过本地启动文件服务器的方式,开放到本地使用,先解决眼前的 Jupyter repo 更新慢的问题
# 通过 python http.server 模拟文件服务器
# 正式环境建议通过 httpd 或者 nginx 等服务
cd ~/modules/helm_repo
nohup python3 -m http.server 30088 > python_http.log 2>&1 &
# 添加本地 helm repo
helm repo add myrepo http://localhost:30088
# 拉取官方 Jupyter chart
git clone https://github.com/jupyterhub/zero-to-jupyterhub-k8s
# 切换到 4.2.0 的 tag
# 注意: 这一步很重要,因为 Chart.yaml 以及 values.yaml 等文件中有 chart version 和 镜像 tag 相关的配置
# 这两个的默认值 ( 0.0.1-set.by.chartpress 和 4.2.1-0.dev.git.7 ) 是无法直接启动 jupyter 服务的
# 需要切换到已发布的一个 tag,再通过官方的 chartpress 工具设置
cd zero-to-jupyterhub-k8s
git checkout tags/4.2.0
# 初始化 chart version 等配置
pip3 install chartpress
./tools/generate-json-schema.py
chartpress --no-build
./tools/set-chart-yaml-annotations.py
# 打包 chart package 格式为压缩包
helm package jupyterhub # 生成 jupyterhub-4.2.0.tgz
cp jupyterhub-4.2.0.tgz ~/modules/helm_repo
# 生成 index.yaml 这里会记录整个 helm repo 提供的 chart 列表
helm repo index . --url http://localhost:30088
# 更新 helm repo, 后续执行 helm install 安装组件时只会读取本地已缓存的 index.yaml 文件
helm repo update
# 只更新本地的 myrepo
helm repo update myrepo
# 确认是否能搜到 jupyter chart
helm search repo myrepo
# 通过自建 helm repo 中的 Jupyter chart 启动
helm --install $RELEASE myrepo/jupyterhub ...
chartpress 是官方提供的一键构建 Jupyter chart 及其所需镜像的工具。添加参数 --no-build 可以只设置 chart 配置文件中的 tag,使得代码可以打包成 release package,不会触发镜像构建
更轻量的启动 k8s 工具
本机启动 k8s 的工具,除了 minikube 还有更轻量的 k3s、microk8s 和 kind 等,它们对比 minikube 的优势主要体现在体积更小,占用资源更少,因此更适合在嵌入式环境中(如树莓派)使用
笔者在本地测试了 k3s 的安装,在 mac 或者 windows 需要先通过 multipass 或者其他方式启动一个虚拟机,再启动 k3s, 在 linux 安装过程则不需要依赖虚拟机,有兴趣可以参考官方文档 Quick-Start Guide
sealos
假设公司已经为你提供了3台以上虚拟机,你已经可以启动真正的 k8s 集群了,sealos 是一个选择
有个小细节要注意,启动集群参数中还需要加上 local-path-provisioner 组件参数,否则 Hub 启动会卡在为 sqlite 申请 PV 的步骤
sealos gen registry.cn-shanghai.aliyuncs.com/labring/kubernetes:v1.29.0 registry.cn-shanghai.aliyuncs.com/labring/helm:v3.8.2 registry.cn-shanghai.aliyuncs.com/labring/calico:v3.24.1 registry.cn-shanghai.aliyuncs.com/labring/local-path-provisioner:v0.0.28 --masters master_node --nodes worker_nodes
其他扩展方向
成功使用 minikube 在本地搭建 Jupyter 集群之后,沿着这两个组件和集群部署的思路,我们还可以发掘更多值得动手测试的需求
-
Bitnami: Bitnami 提供和云厂商合作,提供可靠的云服务的企业,19年被 VMware 收购。它的开源仓库针对很多开源组件实现了 Helm chart ,比如 flink、airflow 等,可以作为参考(不过也看到有吐槽它的 Rabbitmq chart 做得不怎么样 )
-
JupyterLab 相关的各种可以提升体验的插件,以及 Jupyter AI
-
对 Jupyter 更加贴近企业实践的改造, 可以参考字节这篇文章,其中 Session 持久化和 Kernel 持久化对于优化用户体验都非常有用
-
学习更多 Notebook 的高级用法,参考 data-science-ipython-notebooks,以及 快捷键 和 ipykernel 使用技巧


 浙公网安备 33010602011771号
浙公网安备 33010602011771号