
Beats & FileBeat
Beats是一个开放源代码的数据发送器。我们可以把Beats作为一种代理安装在我们的服务器上,这样就可以比较方便地将数据发送到Elasticsearch或者Logstash中。Elastic Stack提供了多种类型的Beats组件。
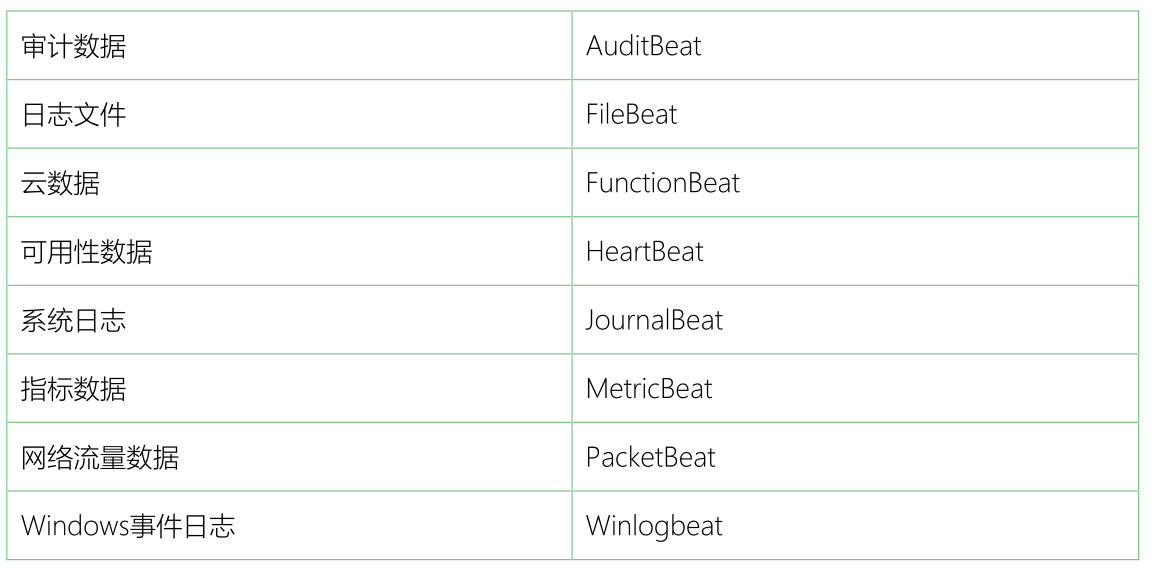
Beats可以直接将数据发送到Elasticsearch或者发送到Logstash, 基于Logstash可以进一步地对数据进行处理,然后将处理后的数据存入到Elasticsearch,最后使用Kibana进行数据可视化。
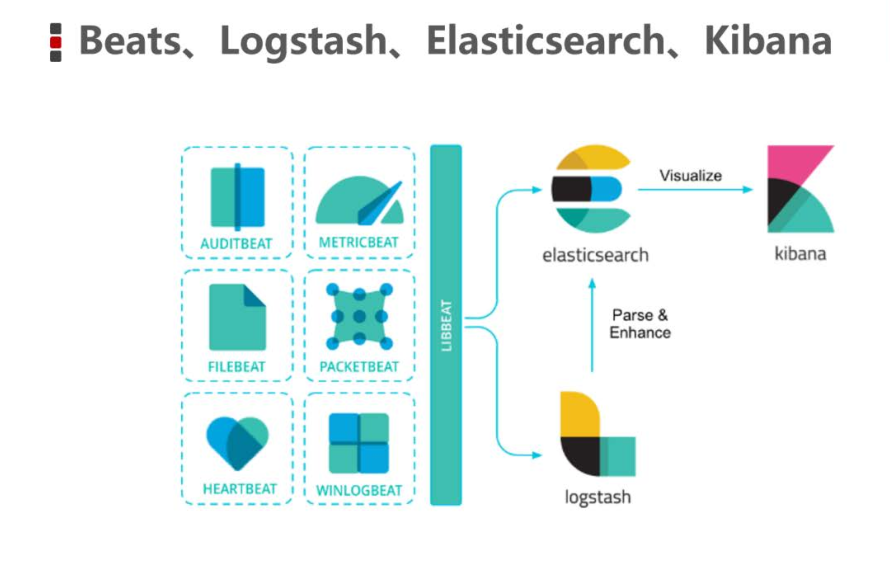
FileBeat简介
FileBeat专门用于转发和收集日志数据的轻量级采集工具。它可以作为代理安装在服务器上,FileBeat监视指定路径的日志文件,收集日志数据,并将收集到的日志转发到Elasticsearch或者Logstash。
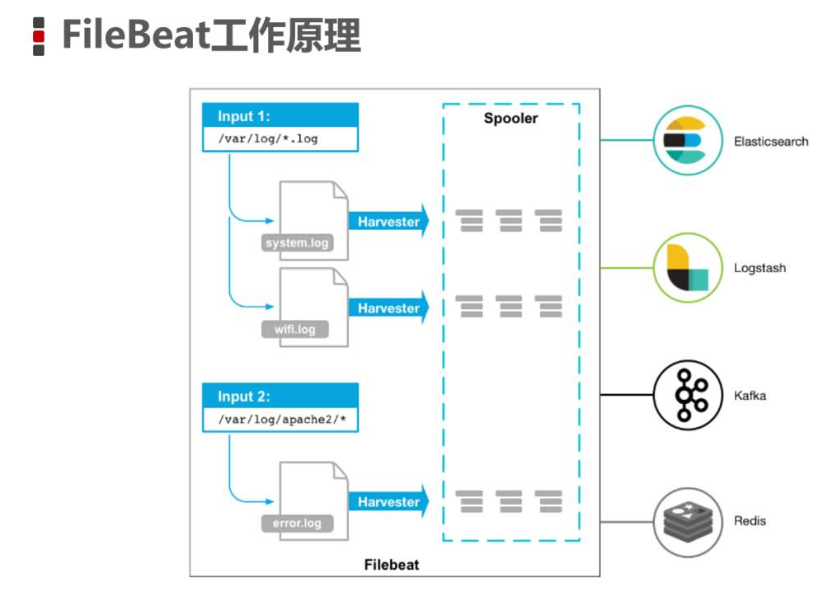
FileBeat的工作原理
启动FileBeat时,会启动一个或者多个输入(Input),这些Input监控指定的日志数据位置。FileBeat会针对每一个文件启动一个Harvester(收割机)。Harvester读取每一个文件的日志,将新的日志发送到libbeat,libbeat将数据收集到一起,并将数据发送给输
出(Output)。
解决一个日志涉及到多行问题
在FileBeat的配置中,专门有一个解决一条日志跨多行问题的配置。主要为以下三个配置:
multiline.pattern: ^\[
multiline.negate: false
multiline.match: after
- multiline.pattern:表示能够匹配一条日志的模式,默认配置的是以[开头的才认为是一条新的日志。 ^[表示匹配以[开头的消息
- multiline.negate:配置为false,正常匹配(默认),表示不需要取反,配置为true,表示取反
- multiline.match:表示是否将未匹配到的行追加到上一日志,还是追加到下一个日志。
FileBeat是如何工作的
FileBeat主要由input和harvesters(收割机)组成。这两个组件协同工作,并将数据发送到指定的输出。
inputs(输入)
- input是负责管理Harvesters和查找所有要读取的文件的组件
- 如果输入类型是 log,input组件会查找磁盘上与路径描述的所有文件,并为每个文件启动一个Harvester,每个输入都独立地运行
Harvesters(收割机)
- Harvesters负责读取单个文件的内容,它负责打开/关闭文件,并逐行读取每个文件的内容,将读取到的内容发送给输出
- 每个文件都会启动一个Harvester
- Harvester运行时,文件将处于打开状态。如果文件在读取时,被移除或者重命名,FileBeat将继续读取该文件
FileBeats如何保持文件状态
- FileBeat保存每个文件的状态,并定时将状态信息保存在磁盘的「注册表」文件中
- 该状态记录Harvester读取的最后一次偏移量,并确保发送所有的日志数据
- 如果输出(Elasticsearch或者Logstash)无法访问,FileBeat会记录成功发送的最后一行,并在输出(Elasticsearch或者Logstash)可用时,继续读取文件发送数据
- 在运行FileBeat时,每个input的状态信息也会保存在内存中,重新启动FileBeat时,会从「注册表」文件中读取数据来重新构建状态。
在filebeat-7.6.1-linux-x86_64/data目录中有一个Registry文件夹,里面有一个data.json,该文件中记录了Harvester读取日志的offset。
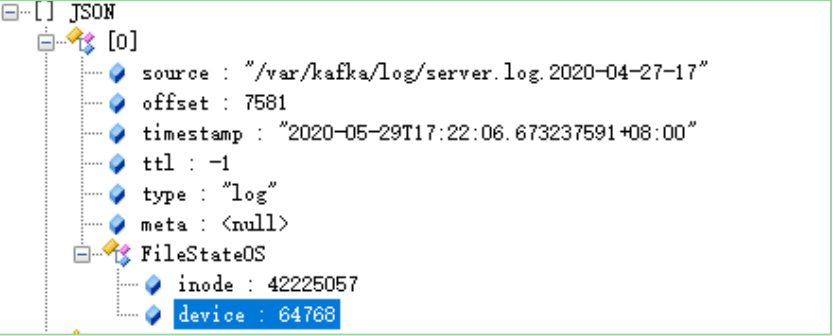
删除「注册表」/data.json也就是删除日志收集时记录的位置,删除后则会从头开始收集
filebeat-7.6.1-linux-x86_64/data/registry/filebeat/data.json
