浏览器指纹 - HTTP cookie 浏览器指纹 欺诈检测 浏览器id hash 浏览器插件信息 canvas 字体信息 生成浏览器唯一稳定 ID
生成浏览器唯一稳定 ID 的探索 - 知乎 https://zhuanlan.zhihu.com/p/400206593
生成浏览器唯一稳定 ID 的探索
作者:polozhang,腾讯 WXG 前端开发工程师

1. 背景
项目的 PC Web 端在不同浏览器有不同的登录态,同一浏览器多个窗口多个 tab 共用一个登录态(隐身无痕模式除外)。为了能够实现 PC 浏览器端设备管理功能,让用户能看到自己在浏览器的多个登录态,并能选择踢掉其中的部分或全部,就需要一种能够区分不同浏览器的方法,这个在移动端 App 就是设备 ID, 我们可以迁移一下,在 PC 端,一个浏览器就好比移动端的一个手机设备,只要能够生成浏览器 ID,就能够区分不同的登录态。
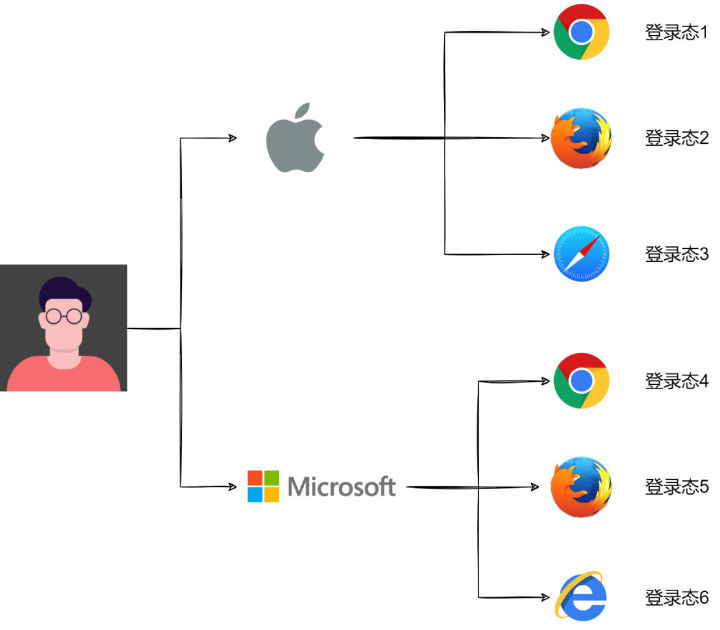
这里说的浏览器 ID 在业界早有研究,叫浏览器指纹。浏览器指纹,是 EFF(电子前哨基金会)提出的一项追踪技术,通过浏览器对网站可见的配置来匿名识别浏览器,在 50 万份不同浏览器数据分析中,在某些场景下,94%的浏览器具有唯一的指纹。当时,EFF 通过提取浏览器的 8 个特征值,{ user agent, plugins, fonts, video, supercookies, http accept, timezone, cookie enabled }, 综合起来哈希生成一个指纹值。每项浏览器特征都包含不同 bit 的信息熵,一个 bit 有两种可能性,2 bits 有四种,3 bits 就有八种,提取的八项特征共包含 18.1 bits 的信息,这意味着在 286,777 个指纹中才会出现一个与你重复的浏览器指纹[1]。
浏览器指纹是无状态的,它无需用户授权便可收集信息,并且不会像 Cookie 一样会被用户禁止或清除,只要你的指纹是唯一的,你就能够被唯一识别和跟踪。当然,一个事物的好坏是取决于怎么使用它,浏览器指纹也可用于一些好的方面,比如:反欺诈,防止刷票、黄牛、机器人,异地或者可疑登录提示,多设备管理,或者在注重用户隐私的情况下,进行一些数据分析,提高用户体验。

2. 分析
抛开业界已经存在的一些方案,我们可以先开点脑洞去分析。要实现的目标是给一个设备的一个浏览器生成一个唯一和稳定的 ID, 这里无非就是从硬件、操作系统、浏览器的维度去分析,看看有什么办法可以区分。
2.1. 一些参考维度
2.1.1. MAC 地址
MAC 地址又称为物理地址、硬件地址,它是一个用来确认网络设备位置的位址,在 OSI 七层模型中,第二层数据链路层负责 MAC 地址,网卡的 MAC 地址通常是由网卡厂家烧入网卡里的,能在网络中唯一标识一个网卡。
如果我们能获得 MAC 地址,我们就能唯一标识一台电脑(一个网卡),这能在很大程度保证生成 ID 的唯一性和稳定性。但是想在浏览器端获取 MAC 地址基本是做不到的,如果是 Windows 用户,一种可能的方法是让用户安装 ActiveX 控件。从服务端也很难操作,获取到的 MAC 地址可能是中间路由器的 MAC 地址,而不是浏览器设备的 MAC 地址。另外,MAC 地址也是可以伪造的。
2.1.2. IP 地址
当设备连接网络,设备将被分配一个 IP 地址,用作标识。IP 地址记录在 OSI 模型中的第三层网络层。服务端从 HTTP 请求中可以分析得到 IP 地址,浏览器端可以通过 WebRTC 网页实时通信技术 的 RTCPeerConnection 的 API, 获取到客户端的 IP 地址。IP 地址是可能重复的,可能有多个设备处在一个局域网下,共享一个公网 IP。 IP 地址也是多变的,计算机经常会在不同的网络和代理下使用。但是,IP 地址的唯一性比较强,两个设备的碰撞率是很低的,如果能利用 IP 地址去增强浏览器 ID 的唯一性是非常有价值的。
2.1.3. Cookie
Cookie 是存在浏览器上的一段信息,并能在服务端和浏览器之间传递,一般用于维持登录态或者保存一些信息。Cookie 中保存的信息是可以标识用户的,甚至可以追踪用户的行为和隐私数据,进而为产品决策提供数据。虽然 Cookie 本身或者其他诸如 localStorage 等存储技术不能提供浏览器特征参数(判断是否禁用 Cookie 可以作为参数),但是可以作为辅助手段存储浏览器 ID,当用户登录态过期或者伪造浏览器特征时,我们可以从 Cookie 和其他存储中取到之前的 ID 继续使用。
2.1.4. User Agent
User Agent, 用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。一般稍微熟悉一点 Web 开发的都会自然想到 UA 能够作为特征生成浏览器 ID, 它大概包含 5.34 bits 的信息熵,具有一定的唯一性,但是稳定性较差,比如:用户可能很容易升级浏览器版本,这样 UA 就会发生变化,可行的解决思路是:只取浏览器型号,不取浏览器版本,这样比较稳定;因为 UA 比较容易伪造,也可通过其他维度去代替,当这些维度发生变化,可以认为 UA 发生了改变。
可以看到,通过单一维度去生成 ID 是不太可靠的,唯一性和稳定性都无法保证,更有效的方式是通过多个维度组合起来形成一个综合指纹。通过调研,目前业界比较领先的开源库是 FingerprintJS, 现在已经更新到 v3.2.0 版本,也一直处于迭代状态。
2.2. FingerprintJS
FingerprintJS(下文简称 FPJS)是一个浏览器指纹库,同时具有开源版和 Pro 版(付费版),可查询浏览器属性并从中计算出哈希值。与 Cookie 和本地存储不同,指纹在隐身模式下保持不变,甚至在浏览器数据清除时也是如此。
它最早的灵感就是来源于 EFF 提出浏览器指纹的概念,在此基础上,又增加了许多特征参数,包括一些新型的识别技术,比如:Canvas、AudioContext 等,在不断地迭代中,优化这些参数,并用最快的方式生成指纹。
2.2.1. 开源版本
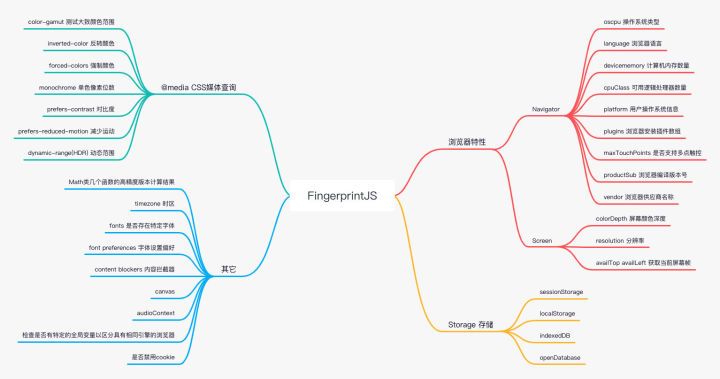
开源版本通过浏览器捕捉到各种指标并通过哈希算法组合成一个指纹,我把这些指标分成四类,浏览器特性、存储、媒体查询、其它。具体如上图所示。目前 GitHub Star 数有 14.1k, 并被 8000+ 网站使用。
2.2.2. 唯一性和稳定性
到底什么样的指纹是唯一和稳定的?
唯一性指在不同的设备,或者不同的浏览器上,每个指纹都是不同的。实际情况是,总会有各种指标都完全相同的用户,那么就会生成一样的指纹,比如唯一性能达到 95%,那 100 个指纹中,有 5 个是重复的。
稳定性指用户每次打开相同设备的相同浏览器,生成的指纹是一样的。如果用户没有修改设备或者浏览器的设置,且浏览器没有升级,生成的 ID 是不会变的。但是在实际情况中,如果选用了一些不稳定的指标参与计算或者用户使用了一些反指纹手段,那么可能每次生成的都会不一样。
为了提高唯一和稳定,我们的指纹不仅应该结合许多指标,还应该尽量筛选出区分度大和稳定性高的指标,需要找到平衡唯一和稳定的指标组合。在控制变量的情况下,随着指标的增多,唯一性增强,但同时稳定性会减弱。

在四象限中,我们优先抛弃那些唯一性和稳定性低的指标,比如图中的电池电量。其它的指标中,可以通过用各种组合进行数据采集和验证,迭代出最平衡的组合。
2.2.3. 一些有趣的指标
Canvas 指纹
Canvas(画布)是 HTML5 中的一种动态绘图标签,可以用它来绘制图片。在不同操作系统、不同浏览器上,Canvas 绘制的图像将以不同的方式呈现,具有很强的唯一性。原理是:在图片格式上,浏览器使用不同的图形处理引擎、图像导出选项、压缩级别,在系统层面,操作系统有不同的字体,它们使用不同的算法和设置来进行抗锯齿和子像素渲染。另外,Canvas 具有良好的兼容性,几乎被所有主流浏览器支持。
在具体代码上,通过 Canvas 绘图 API 绘制文字或图形后,通过 canvas.toDataURL() 方法获得 base64 编码,根据需要可再 hash 成指纹。
判断是否包含某字体
首先,前端不存在兼容性比较好的原生方法判断是否包含某字体,那么该怎么判断呢?
不同字体显示相同的文案时,宽度是不同的。我们可以利用这一点,设置三种默认字体,'monospace', 'sans-serif', 'serif', 新建一个 span 标签,设置 font-family 为当前字体和默认字体, 设置另外一个 span 为默认字体,如果存在当前字体,两个 span 的宽度或者高度是不一样的,如果完全一致,则代表不存在该字体,第一个 span 回退回默认字体。
Math 类几个函数精度不同
不同的操作系统和架构,不同的浏览器的几个 Math 数学函数可能产生不同结果。比如 Math.sin(-1e300),在不同的系统和浏览器上算出来的值可能是不同的。有趣的是,在代码注释中可以看到相关链接,是来自于 tor 浏览器,这是一个宣称保护隐私的浏览器,具备一定的反指纹策略。所以,有时候有效信息可以从对手那里获取。
音频指纹
查看链接,原理和 Canvas 类似,都是利用硬件和软件的差异,一个生成音频,一个生成图片。
2.2.4. Pro 付费版本
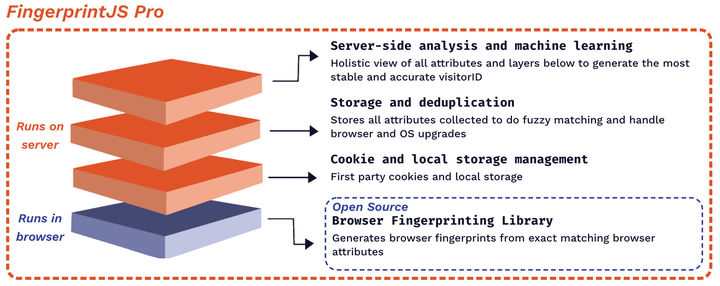
开源版本和专业版主要区别在于,开源版本仅仅运行于浏览器端,浏览器通过 JS 获取到一系列指标后计算哈希值。当两个用户有同样的设备和浏览器时,他们可能生成同样的指纹,从而无法区分两个用户(从提取的指标来看,它们的确是相同的,只是有些业务场景需要更加细分的手段去区分用户)。专业版建立在开源版的基础上,并增加了很多服务器端的手段去辅助识别用户,比如:IP 地址、Cookie、本地存储、存储历史记录进行模糊匹配和处理浏览器升级、服务器端分析和机器学习,并最终由服务端生成指纹。
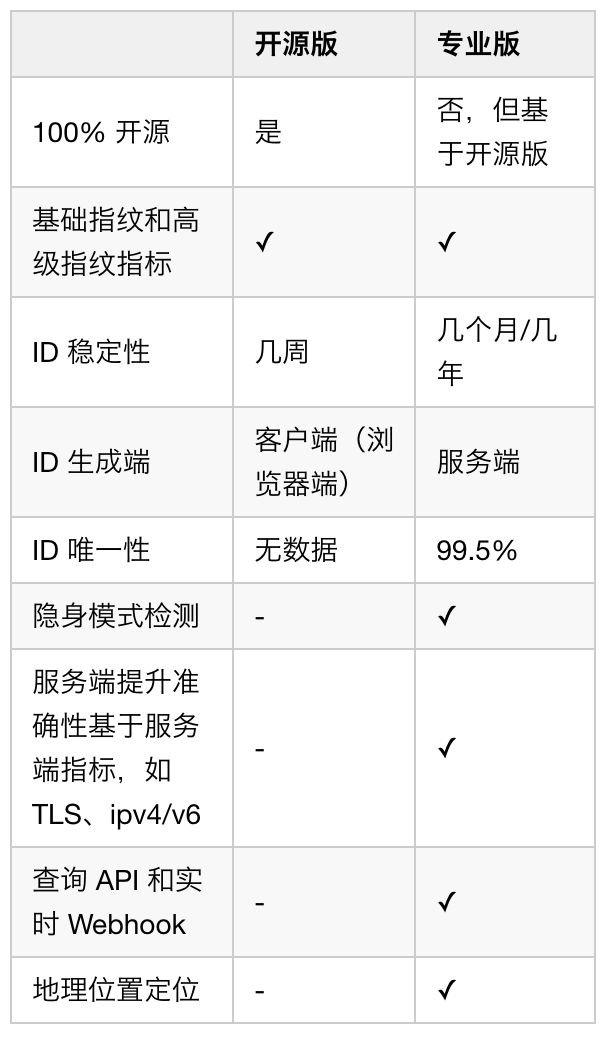
图 6. 官方提供的一些对比
可以看出,专业版增加了一些服务端检测技术后,在生成 ID 的唯一性和稳定性都有很大的提高,另外,ID 在服务端生成也更安全可靠。笔者曾试图调试研究专业版压缩混淆的代码,但能力和时间有限,只能看得出小部分。后来,尝试通过实验和对比的方法,了解专业版是怎么提高唯一性和稳定性的。
分析和发现
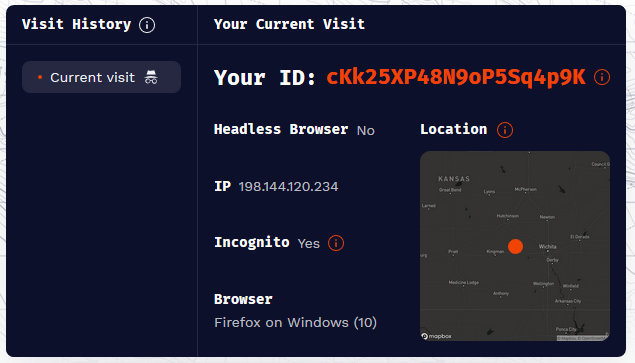
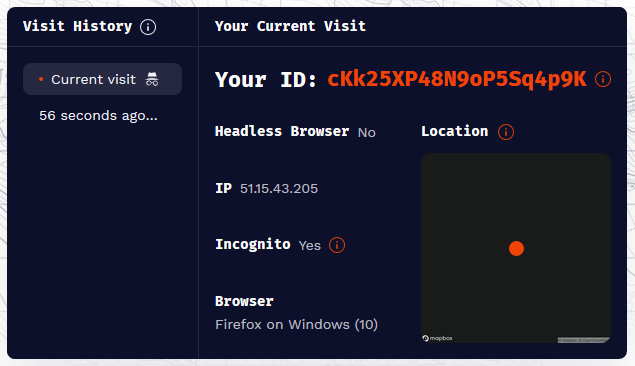
尝试 1:IP 是否会影响指纹
结果:通过 VPN 或者连接不同的网络,指纹的生成是稳定的,直接切换 IP 并不影响指纹。可以理解,因为 IP 是非常不稳定的,用户很容易切换 IP,导致指纹变化。个人看法,IP 只是作为辅助手段进行校验,比如曾经有使用某个 IP 的历史记录,就可以佐证是之前生成的某个指纹,即使某些指标发生异动。
尝试 2:伪造某些指标是否会影响指纹
开源版:只要修改了提取的某个参数值,生成的指纹就会改变。
专业版:在 Chrome 的无痕模式下,通过插件(Fingerprint Spoofing)或者断点通过 Object.defineProperty 等方式修改某些指标的值是会影响指纹的。但在普通模式下,修改参数不会影响指纹。为什么呢,我们会很容易去想普通模式和隐身模式有什么不同。经过一些尝试后,笔者把目标锁定在 Cookie 、本地存储和缓存上,专业版生成指纹后,存储在 Cookie 和本地存储中,下一次生成指纹时,先判断是否已存在 Cookie,有且符合历史记录则直接取,没有再重新生成。
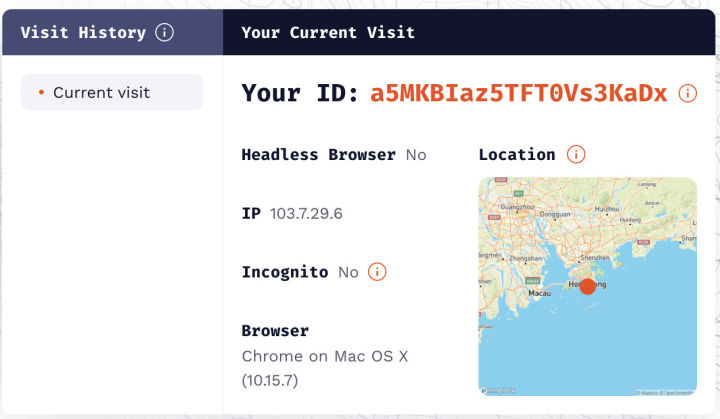
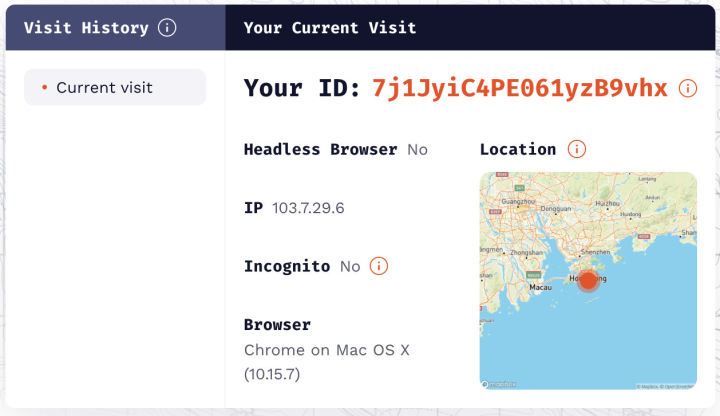
尝试 3:伪造某些指标并清除 Cookie 、本地存储和缓存后是否影响专业版指纹
结果:会影响,基本上可以实现随机指纹。所以,基本可以确认,当 Cookie 等内容存在时,能够匹配历史记录里的值就直接从里面取值,这样能在很大程度上保持指纹的稳定。在实验中,Cookie、本地存储和缓存都可以用于保持稳定。
其他发现:
- 当伪造的值不具有迷惑性时,可能绕不过服务端的分析。比如:我在 Win10 Chrome 上将
navigator.platform修改为 MacIntel, 也就是 Mac 的标识时,指纹是稳定的。猜想服务端应该分析到这个指标与整个模型有偏差,所以矫正了该指标,依然使用了之前的指纹。

- 另外发现 Pro 中引入了很多第三方分析,比如 GA 谷歌分析、linkedin 领英分析、Twitter 分析、FB 脸书分析,这些大公司为了推广广告营销等业务,可能在浏览器指纹上的造诣是很高的,Pro 版本可能利用了这些第三方分析的结果辅助指纹的唯一性和稳定性,当然,这些第三方分析同样也是利用 Cookie 等方式标记浏览器和用户,利用清除的方法可以规避追踪。
3. 采用的做法
- 首先将 FPJS v3.0.6 在项目中打点测试,在几百万~几千万的独立用户数量级上,用独立用户数 / 独立指纹数 约等于 1.3,这个在移动端 App 的数据大约是 1.1 ~ 1.2,一个用户可能有多个账号,可能用多个账号登录同一个浏览器,也可能同一个账号登录多个浏览器,是多对多的关系。在几百万到几千万的变化上,这个比例相对比较稳定,至少随着用户数的增加,稳定性不会降低;另外,这个比例跟移动端比没有偏差太多,还算合格,后面可以结合其他手段提高唯一性;其实在实现像设备管理这样的功能时,只需要保证同一用户在不同浏览器上生成不同的指纹即可。综上所述,可以采用 FPJS 作为前端生成指纹的选择,并结合 Cookie 等策略优化唯一和稳定。
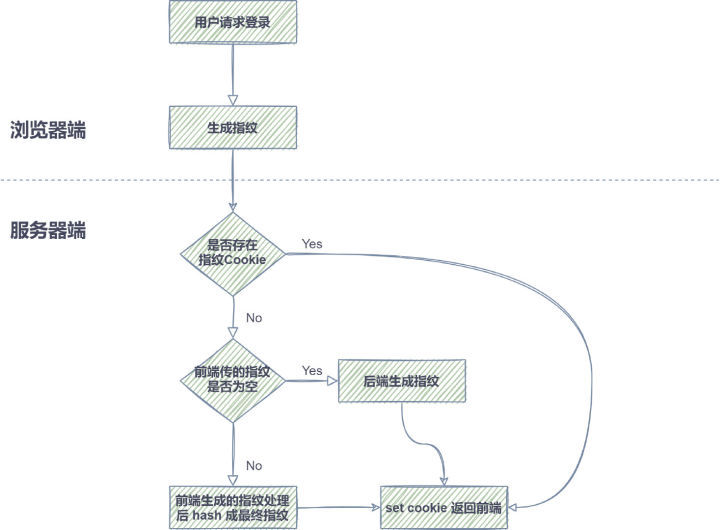
图 12. 指纹生成具体做法
- 具体做法:登录时,前端生成指纹通过 HTTP 请求传给后端,后端经过一些处理后,再 hash 以后生成一个值,通过 set cookie 返回前端,当前端传空值时,后端生成一个值返回前端。当用户再进行登录时,如果已存在 Cookie,则取 Cookie 的值,如果不存在,则根据前面逻辑生成新的。后续如用到指纹时,通过 HTTP 请求带上 Cookie 即可。
- 后续如何优化:
- FPJS 目前已升级到 v3.2.0 版本,增加了一些指标维度,并优化了一些指标的具体使用,可以打点测试后,看看唯一性是否提高,如果可行,可以考虑新的指纹生成升级到新版本。
- 目前没有历史记录,可以考虑记录历史指纹,帮助验证 Cookie 的有效性及辅助判断当前指纹是否异常等。
- 通过历史 IP 辅助验证 Cookie 的有效性和唯一性。
4. 反浏览器指纹
- 禁用 Cookie 或 JS
比较严格,应该可以防止大部分的浏览器指纹。但是,很多网站都需要依托 Cookie 维持登录态 和 JS 实现逻辑,禁用后可能没办法使用网站或者影响体验。
- 隐身模式加随机身份
这个组合可以保证大部分场景下生成随机的指纹,隐身模式下退出后会清理 Cookie、本地存储和缓存,随机的身份(指标组合)可以保证生成不了历史的指纹,从而不被跟踪。
- tor 浏览器
tor 浏览器号称是最安全的浏览器,它在反指纹上做了很多工作,它的主要策略是让所有 tor 浏览器的用户都拥有完全相同的指纹,无论你是什么设备或者操作系统,尽量降低指纹的唯一性。另外,tor 天然就是隐身模式,可以更换身份以及可以隐藏真实 IP。当然,在使用体验上,tor 相对会慢一点,毕竟经历了这么多安全策略。
- 攻与防
浏览器指纹技术根植于 Web 诞生以来就存在的机制里,在可预见的未来,要完全摆脱它是很困难的。随着浏览器指纹攻防两端技术的不断提升,这种竞争可能愈演愈烈。试想,随着技术的不断提升,希望保护隐私的用户为了不被追踪就需要更高的防御手段,这势必会影响用户体验,造成两败俱伤的局面。 其实,就像上文说的,浏览器指纹只是一种技术,它的好与坏取决于你所身处的位置以及怎么使用它,笔者觉得,可以建立一种机制,允许它的合理存在,并合理地使用它,用于一些合法合规,并且对用户友好的场景。
5. 总结
本文从几个参考维度开始分析,介绍了浏览器指纹的生成原理。而后,展开分析了 FingerprintJS 的开源版和 Pro 版,最后在项目中进行了首次应用,在后续迭代的过程中,会不断根据实际情况进行优化。本文只是初步探索与尝试,如有任何错误和不足,欢迎批评指正。
- 参考文献
[1] https://coveryourtracks.eff.org/static/browser-uniqueness.pdf
[2] 公众号:ArkTeam
[3] FingerprintJS 官网:https://fingerprintjs.com/
详解浏览器cookie和浏览隐私之间的关系
http://www.iefans.net/cookie-yinsi-guanxi/
详解浏览器cookie和浏览隐私之间的关系
Cookie 的技术实现
本章节面向懂技术的网友。不太懂技术的读者,可以略过本节,直接进入下一章节,以免浪费时间。网站如何设置 cookie(写操作)
1、当你在浏览器中点某个书签、或者在浏览器地址栏输入某个网址,浏览器会向对应的网站发起一个 HTTP 请求(术语是 HTTP Request)。 2、然后,网站的服务器收到这个 HTTP 请求之后,会把相应的内容(比如网页、图片、等)发回给浏览器(这称为 HTTP 响应,术语是 HTTP Reponse)。 如果网站想设置 cookie,就在发回的 HTTP Response 中,包含一个设置 cookie 的指令。举例如下:Set-Cookie: user=xxxx; Path=/; Domain=www.example.com上述这个例子中,设置了一个 cookie。这个 cookie 的"名"是 user;cookie 的"值"是 xxxx;cookie 绑定的域名是 www.example.com 3、浏览器在收到这个指令后,就会在你的电脑中存储该 cookie 的信息。
网站如何获取 cookie(读操作)
假设过了几天之后,你再次访问上述的 www.example.com 网站(在上次的访问中,已经被设置过 cookie 了)。这时候,浏览器发现该网址已经有对应的 cookie,就会把 cookie 的信息放在 HTTP Request 中,然后发送到网站服务器。具体的指令如下:Cookie: user=xxxx网站服务器拿到这个 HTTP Request 之后,就可以通过上述信息,知道 cookie 的"名"和"值"。
Cookie 的特点
存储信息量小
cookie 在洋文中的意思就是:小甜饼、曲奇饼。这个单词其实已经暗示了 cookie 技术所能存储的信息量是比较小滴。 从刚才的技术实现机制可以看出,cookie 只能用来存储纯文本信息,而且存储的内容不能太长——因为 Cookie 的读写指令受限于 HTTP Header 的长度。 但是,cookie 的信息量虽小,能耐却很大哦。请看下面的例子。 举例 比如某个网站上有很多网页,每个网页上有很多广告。该网站想要收集:每一个访客点击了哪些广告。 由于这些信息量比较大,直接存储在 cookie 里可能放不下。所以,网站通常是在 cookie 中保存一个唯一的用户标识。然后把用户的点击信息(包括在哪个时间点击哪个广告)都存储在服务器上。 下次你再访问该网站,网站先拿到 cookie 中的用户标识,因为这个标识具有唯一性,那么就可以根据该标识,从网站服务器上查出该用户的详细信息。绑定到域名和路径
从上述的实现机制可以看出,cookie 是跟 HTTP Request 对应的网址(域名和路径)相关的。 所以,不同域名的网站设置的 cookie 是互相独立的(隔离的)。这一点由浏览器来保证,以确保安全性。 补充一下:cookie 绑定的域名可以是小数点开头的。举例如下:Set-Cookie: user=xxxx; Path=/; Domain=.example.com这个指令设置的 cookie,可以被 example.com 的所有下级域名读取(比如 www.example.com 或 ftp.example.com)。
Cookie 的类型
第一方 Cookie VS 第三方 Cookie
首先来说说"第一方"和"第三方" Cookie 的区别,因为这跟隐私的关系比较密切。 要说清楚 "第一方 Cookie" 和 "第三方 Cookie" 的差别,俺来举个例子。 举例 打个比方,你上新浪去看新闻,并且新浪的网页上嵌入了阿里巴巴的广告(假设新浪的页面和嵌入的广告都会设置 cookie)。那么,当你的浏览器加载完整个页面之后,浏览器中就会同时存在新浪网站的 cookie 和 阿里巴巴网站的 cookie。这时候,新浪网站的 cookie 称为"第一方 Cookie"(因为你访问的就是新浪嘛),相对的,阿里巴巴的 cookie 称为"第三方 Cookie"(因为你访问的是新浪,阿里巴巴只是不相干的第三方)内存型 VS 文件型
根据存储方式的不同,分为两类:基于内存的 Cookie 和 基于文件的Cookie。基于内存的 cookie,当浏览器关闭之后,就消失了;而基于文件的 cookie,即使浏览器关闭,依然存在于硬盘上。和隐私问题相关的 cookie,主要是第二类(基于文件的Cookie)。Cookie 有啥正经用途?
今年的315晚会,央视猛烈抨击了 cookie 的隐私问题,搞得好像 cookie 是洪水猛兽一般。央视对 cookie 的宣传,典型是用来吓唬不懂技术的外行。其实捏,cookie 是有利有弊的。cookie 之所以应用这么广泛,因为它本身确实是很有用的。请看下面的几个例子。举例1——自动登录
目前很多基于 Web 的邮箱,都有自动登录功能。也就是说,你第一次打开邮箱页面的时候,需要输入用户名和口令;过几天之后再来打开邮箱网页,就不需要再次输入用户名和口令了(比如 Gmail 和 Hotmail 就是这样的)。 为啥邮箱可以做到自动登录,就是因为邮箱的网站在你的浏览器中保存了 cookie,通过 cookie 中记录的信息来表明你是已登录用户。举例2——提供个性化界面
比如某个论坛允许匿名用户设置页面的字体样式和字体大小。那么,该论坛就可以把匿名用户设置的字体信息保存在 cookie 中,下次你用同一个浏览器访问该论坛,自动就帮你把字体设置好了。小结
一般来说,有正经用途的 cookie,大都是"第一方 Cookie";至于"第三方 Cookie",大部分是用来收集广告信息和用户行为的。Cookie 如何泄漏隐私?
cookie 就像一把双刃剑,有很多用途,但也有弊端。一个主要的弊端就是隐私问题。举例1
假如你同时使用 Google 的 Gmail 和 Google 的搜索(很多 Google 用户都这么干)。当你登录过 Gmail 之后,cookie 中会保存你的用户信息(标识你是谁);即使你在 Gmail 中点了注销(logout),cookie 中还是会有你的用户信息。之后,你再用 Google 的搜索功能,那么 Google 就可以通过 cookie 中的信息,知道这些搜索请求是哪个 Gmail 用户发起的。 可能有些同学会问,Gmail 和 Google 搜索,是不同的域名,如何共享 cookie 捏?俺前面有介绍过,某些 cookie 绑定的域名是以小数点开头的,也就是说,这类 cookie 可以被所有下级域名读取。因为 Gmail 的域名是 mail.google.com,而 Google 搜索的域名是 www.google.com。所以这两者都可以读取绑定在 .google.com 的 cookie! 注:俺拿 Google 来举例是因为俺博客的读者,大部分都是 Google 用户。其实不光 Google 存在此问题,百度、腾讯、阿里巴巴、奇虎360、等等,都存在类似问题(这几家都有搜索功能,也都有自己的一套用户帐号体系)。举例2
很多网站会利用 cookie 来追踪你访问该网站的行为(包括你多久来一次,每次来经常看哪些页面,每个页面的停留时间),这样一来,网站方面就可以根据这些数据,分析你的个人的种种偏好(这就涉及到个人隐私)。 请注意:利用 cookie 收集个人隐私的把戏有很多,俺限于篇幅,仅列出上述两例。始终用隐私浏览模式
关于"隐私浏览模式",在本系列的前一篇已经介绍过了,此处不再啰嗦。 在隐私浏览模式下,浏览器关闭之后,期间所有的 cookie 都消失。 但是,这样设置也可能带来一些不方便之处(安全性和方便性通常是截然对立)。你可能要先尝试一段时间,看看自己能否忍受这种模式。小结
刚才介绍的几招,都是针对单个浏览器 。大部分情况下是够用了。但是某些特殊情况,还是会搞不定。 比如:你经常用 Gmail,而且依赖于 Gmail 的自动登录。这时候,你就不能禁用 .google.com 域名下的 cookie(禁用了就无法自动登录 Gmail)。 但是,你在用 Google 搜索的时候,又不希望让 Google 知道你是谁。咋办捏?请听下回分解——用多浏览器搭配不同的招数。 via:编程随想的博客什么是浏览器指纹?它是如何泄露我们的隐私?
http://www.iefans.net/liulanqi-zhiwen-ruhe-xielou-yinsi/
什么是浏览器指纹?它是如何泄露我们的隐私?
什么是“指纹”?
说到“指纹”可能大家都知道是手指头的纹理,而且每个人的指纹都是唯一的。 如果你时常接触信息安全领域的一些资料,也会听到“指纹”这个形象的说法(比如:操作系统指纹、网络协议栈指纹、等等)。IT 领域提到的“指纹”一词,其原理跟“刑侦”是类似的——“当你需要研究某个对象的类型/类别,但这个对象你又无法直接接触到。这时候你可以利用若干技术来获取该对象的某些特征,然后根据这些特征来猜测/判断该对象的类型/类别。”什么是“指纹”的“信息量”?
在 IT 领域有各种各样的特征可以用来充当“指纹”。这时候就需要判断,用哪个特征做指纹,效果更好。为了讨论这个问题,就得扫盲一下“指纹的信息量”。 为了帮助大伙儿理解,先举一个例子: 假设你要在学校中定位某个人,如果你光知道此人的性别,你是比较难定位的(只能排除 1/2 的人);反之如果你不知道性别,但是知道此人的生日,就比较容易定位(可以排除掉大约 364/365 的人,只剩大约 1/365 的人)。为什么?因为“生日”比“性别”更加独特,所以“生日”比“性别”能够提供更多的信息量。 从这个例子可以看出:某个特征越独特,则该特征的信息量越大;反之亦然。信息量越大的特征,就可以把对象定位到越小的范围。“指纹”的“信息量”如何度量——关于指纹的比特数?
(本节涉及到中学数学,数学很差的或者对数学有恐惧感的读者,请直接无视) 在 IT 领域中,可以用【比特数】来衡量某个指纹所包含的信息量。为了通俗起见,先以前面提到的“性别”来说事儿。性别只有两种可能性——“男”或者“女”,并且男女的比例是大致平均的。所以,当你知道了某人的性别,就可以把范围缩小到原先的 1/2。用 IT 的术语来讲,就是:“性别”这个特征只包含一个比特的信息量。以此类推:- 当我们说:“某特征包含3比特信息量”,意思就是:该特征会有8种大致平均的可能性(8等于2的3次方)。一旦知道该特征,可以把目标定位到八分之一。
- 当我们说:“某特征包含7比特信息量”,意思就是:该特征会有128种大致平均的可能性(128=2^7)。一旦知道该特征,可以定位到 1/128。
多个指纹的综合定位
如果能同时获取【互不相关】的若干个指纹,就可以大大增加定位的精确性。 比如要在某个公司里面定位某人,如果你知道此人的“生日”和“生肖”,那么就可以达到 1/4380(1/4380 = 1/12 * 1/365) 的定位精度。因为综合定位之后,比例之间是【乘法】的关系,所以范围就被急剧缩小了。 为什么要特别强调“互不相关”呢?假如你同时知道的信息是“生日”和“星座”,那么定位的精度依然是 1/365——因为生日的信息已经包含了星座的信息。所以,只有那些相互独立的特征(所谓的相互独立,数学称为“正交”),在综合定位的时候才可以用【乘法】。什么是“浏览器的指纹”?
当你使用浏览器访问某个网站的时候,浏览器【必定会暴露】某些信息给这个网站。为什么强调“必定”呢?因为这些信息中,有些是跟 HTTP 协议相关的(本章节说的 HTTP 协议是广义的,也包括 HTTPS)。只要你基于 HTTP 协议访问网站,浏览器就【必定】会传输这些信息给网站的服务器。 再罗嗦一下:HTTP 协议是 Web 的基石。只要你通过浏览器访问 Web,必定是基于 HTTP 协议的。因此,Web 网站的服务器必定可以获取到跟你的浏览器相关的某些信息(具体是哪些信息,下面会说到)。“浏览器指纹”如何暴露隐私?
“浏览器指纹”的机制跟 cookie 有点相似。关于 cookie 的作用,建议那些健忘的同学先去“前面的博文”复习一下。 对于“浏览器指纹”导致的隐私问题,这里举2个例子来说明其危害。对于无需登录的网站
如果你的浏览器允许记录 cookie,当你第一次访问某网站的时候,网站会在你的浏览器端记录一个 cookie,cookie 中包含某个“唯一性的标识信息”。下次你再去访问该网站,网站服务器先从你的浏览器中读取 cookie 信息,然后就可以根据 cookie 中的“唯一标识”判断出,你之前曾经访问过该网站,并且知道你上次访问该网站时,干了些什么。对付这种 cookie 很简单,你只需要在前后两次访问之间,清空浏览器的 cookie,网站就没法用 cookie 的招数来判断你的身份。 但是“清空 cookie”这招对“浏览器指纹”是无效滴。比如说你的浏览器具有非常独特的指纹,那么当你第一次访问某网站的时候,网站会在服务器端记录下你的浏览器指纹,并且会记录你在该网站的行为;下次你再去访问的时候,网站服务器再次读取浏览器指纹,然后跟之前存储的指纹进行比对,就知道你是否曾经来过,并且知道你上次访问期间干了些什么。对于需要登录的网站
假如网站没有采用“指纹追踪”的技术,那么你可以在该网站上注册若干个帐号(马甲)。当你需要切换身份的时候,只需要先注销用户,清空浏览器的 cookie,然后用另一个帐号登录。网站是看不出来的。 一旦网站采用“指纹追踪”的技术,即使你用上述方式伪造马甲,但因为你用的是同一个浏览器,浏览器指纹相同。网站的服务器软件可以猜测出,这两个帐号其实是同一个网民注册的。“浏览器指纹”比“cookie”更隐蔽,更危险
刚才对比了“浏览器指纹”和“cookie”两种身份追踪技术。两者的原理类似——都是利用某些特殊的信息来定位你的身份。两者的本质差异在于:- cookie 需要把信息保存在浏览器端,所以会被用户发现,也会被用户清除。
- 而“浏览器指纹”无需在客户端保存任何信息,不会被用户发觉,用户也无法清除(换句话说:你甚至无法判断你访问的网站到底有没有收集浏览器指纹)。
“浏览器指纹”包含哪些信息?
浏览器暴露给网站的信息有很多种,常见的有如下几种:User Agent
关于 User Agent 是什么,已经在本系列前面的博文中有简单的说明,已了解的同学可以继续往下看。屏幕分辨率
这个比较通俗易懂。稍微补充一下:这一项不仅包括屏幕的尺寸,还包括颜色深度(比如你的屏幕是16位色、24位色、还是32位色)。时区
这个也比较通俗。我们应该都是“东8区”。浏览器的插件信息
也就是你的浏览器装了哪些插件。 再罗嗦一次:浏览器的“插件”和“扩展”是两码事儿,别搞混了。本系列前面的博文扫盲了两者的差异,链接在“这里”。浏览器的字体信息
和浏览器相关的一些字体信息。 如果你的浏览器安装了 Flash 或 Java 插件,有可能会暴露某些字体信息。所以在“如何防范浏览器泄露上网隐私”一文中就警告了浏览器插件的风险。HTTP ACCEPT
这是 HTTP 协议头中的一个字段。考虑到列位看官大都不是搞 IT 技术的,这里就不深入解释这项。其它
以上就是常见的浏览器指纹。当然啦,还有其它一些信息也可以成为“浏览器指纹”,考虑到篇幅就不一一列举并解释了。有兴趣的同学,请自行阅读 Mozilla 官网的文档。如何看自己浏览器的指纹?
关于浏览器指纹导致的隐私问题,可能是由“电子前哨基金会”(简称 EFF)率先在2010年曝光的。后来 EFF 提供了一个页面,帮助网友看自己浏览器的指纹(请点击“这个链接”)。 打开此页面之后,当中有一个大大的,红色的“TEST ME”按钮。点一下此按钮,稍等几秒钟,会显示出一个表格,里面包含你当前的浏览器的指纹信息。 在这个表格中会列出每一项指纹的“信息量”以及该指纹的“占比”。关于“信息量”的含义,本文前面已经扫盲过,此处不再说明。你只需记住,某项的信息量越大,就说明该项越独特。而越独特的指纹,对隐私的威胁也就越大。 考虑到篇幅有点长,今天先聊到这里。下次跟大家分享如何防范“浏览器指纹”导致的隐私风险。 via:编程随想的博客fingerprint hash 187c8e293354eb2d15d9363a6f52f393
index.js:42 userAgent = Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safa
index.js:42 language = zh-CN
index.js:42 colorDepth = 24
index.js:42 deviceMemory = not available
index.js:42 hardwareConcurrency = 2
index.js:42 screenResolution = 800,1280
index.js:42 availableScreenResolution = 800,1227
index.js:42 timezoneOffset = -480
index.js:42 timezone = Asia/Shanghai
index.js:42 sessionStorage = true
index.js:42 localStorage = true
index.js:42 indexedDb = true
index.js:42 addBehavior = false
index.js:42 openDatabase = true
index.js:42 cpuClass = not available
index.js:42 platform = Win32
index.js:42 plugins = com.sogou.sogoupdfviewer,,application/pdf,pdf,Native Widget Plugin,This plugin allow you to use the
index.js:42 canvas = canvas winding:yes,canvas fp:data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAB9AAAADICAYAAACwGnoBAAAgA
index.js:42 webgl = not available
index.js:42 webglVendorAndRenderer = undefined
index.js:42 adBlock = false
index.js:42 hasLiedLanguages = false
index.js:42 hasLiedResolution = false
index.js:42 hasLiedOs = false
index.js:42 hasLiedBrowser = false
index.js:42 touchSupport = 0,false,false
index.js:42 fonts = Arial,Arial Black,Arial Narrow,Calibri,Cambria,Cambria Math,Comic Sans MS,Consolas,Courier,Courier N
index.js:42 audio = 124.04344752358156
time 361
index.js:37 fingerprint hash b303b5c23680c363a36afc5764f3a275
index.js:42 userAgent = Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109
index.js:42 language = en-US
index.js:42 colorDepth = 24
index.js:42 deviceMemory = 8
index.js:42 hardwareConcurrency = 2
index.js:42 screenResolution = 800,1280
index.js:42 availableScreenResolution = 800,1227
index.js:42 timezoneOffset = -480
index.js:42 timezone = Asia/Shanghai
index.js:42 sessionStorage = true
index.js:42 localStorage = true
index.js:42 indexedDb = true
index.js:42 addBehavior = false
index.js:42 openDatabase = true
index.js:42 cpuClass = not available
index.js:42 platform = Win32
index.js:42 plugins = Chrome PDF Plugin,Portable Document Format,application/x-google-chrome-pdf,pdf,Chrome PDF Viewer,,ap
index.js:42 canvas = canvas winding:yes,canvas fp:data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAB9AAAADICAYAAACwGnoBAAAgA
index.js:42 webgl = data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAASwAAACWCAYAAABkW7XSAAAKcUlEQVR4Xu2dDYhlYxjH77uiiFBEbT
index.js:42 webglVendorAndRenderer = Google Inc.~ANGLE (Mobile Intel(R) 4 Series Express Chipset Family Direct3D9Ex vs_3_0 ps_3_0)
index.js:42 adBlock = false
index.js:42 hasLiedLanguages = false
index.js:42 hasLiedResolution = false
index.js:42 hasLiedOs = false
index.js:42 hasLiedBrowser = false
index.js:42 touchSupport = 0,false,false
index.js:42 fonts = Arial,Arial Black,Arial Narrow,Calibri,Cambria,Cambria Math,Comic Sans MS,Consolas,Courier,Courier N
index.js:42 audio = 124.0434474653739
Fingerprinting - MozillaWiki https://wiki.mozilla.org/Fingerprinting
Overview
The EFF published an excellent study in May, detailing some of the various methods of fingerprinting a browser. See http://www.eff.org/deeplinks/2010/05/every-browser-unique-results-fom-panopticlick. They found that, over their study of around 1 million visits to their study website, 83.6% of the browsers seen had a unique fingerprint; among those with Flash or Java enabled, 94.2%. This does not include cookies! They ranked the various bits of information in order of importance (i.e. how useful they are in uniquely identifying a browser): things like UA string, what addons are installed, and the font list of the system. We need to go through these, one by one, and do what we can to reduce the number of bits of information (entropy) it provides. In their study, they placed a lower bound on the fingerprint distribution of 18.1 bits of entropy. (This means that, choosing a browser at random, at best one in 286,777 other browsers will share its fingerprint.)
Data
The following data is taken from the published paper, https://panopticlick.eff.org/browser-uniqueness.pdf:
| Variable | Entropy (bits) |
| plugins | 15.4 |
| fonts | 13.9 |
| user agent | 10.0 |
| http accept | 6.09 |
| screen resolution | 4.83 |
| timezone | 3.04 |
| supercookies | 2.12 |
| cookies enabled | 0.353 |
In all cases, data was either collected or inferred via HTTP, or collected by JS code and posted back to the server via AJAX.
Plugins
The PluginDetect JS library was used to check for 8 common plugins on that platform, plus extra code to estimate the Acrobat Reader version. Data sent by AJAX post.
IE does not allow enumeration via navigator.plugins[]. Starting in Firefox 28 (bug 757726), Firefox restricts which plugins are visible to content enumerating navigator.plugins[]. This change does not disable any plugins; it just hides some plugin names from enumeration. Websites can still check whether a particular hidden plugin is installed by directly querying navigator.plugins[] like navigator.plugins["Silverlight Plug-In"].
This code change will reduce browser uniqueness by "cloaking" uncommon plugin names from navigator.plugins[] enumeration. If a website does not use the "Adobe Acrobat NPAPI Plug-in, Version 11.0.02" plugin, why does it need to know that the "Adobe Acrobat NPAPI Plug-in, Version 11.0.02" plugin is installed? If a website does need to know whether the plugin is installed or meets minimum version requirements, it can still check navigator.plugins["Adobe Acrobat NPAPI Plug-in, Version 11.0.02"] or navigator.mimeTypes["application/vnd.fdf"].enabledPlugin (to workaround problem plugins that short-sightedly include version numbers in their names, thus allow only individual plugin versions to be queried).
For example, the following JavaScript reveals my installed plugins:
for (plugin of navigator.plugins) { console.log(plugin.name); }
"Shockwave Flash"
"QuickTime Plug-in 7.7.3"
"Default Browser Helper"
"Unity Player"
"Google Earth Plug-in"
"Silverlight Plug-In"
"Java Applet Plug-in"
"Adobe Acrobat NPAPI Plug-in, Version 11.0.02"
"WacomTabletPlugin"
navigator.plugins["Unity Player"].name // get cloaked plugin by name
"Unity Player"
But with plugin cloaking, the same JavaScript will not reveal as much personally-identifying information about my browser because all plugin names except Flash, Shockwave (Director), Java, and QuickTime are hidden from navigator.plugins[] enumeration:
for (plugin of navigator.plugins) { console.log(plugin.name); }
"Shockwave Flash"
"QuickTime Plug-in 7.7.3"
"Java Applet Plug-in"
In theory, all plugin names could be cloaked because web content can query navigator.plugins[] by plugin name. Unfortunately, we could not cloak all plugin names because many popular websites check for Flash or QuickTime by enumerating navigator.plugins[] and comparing plugin names one by one, instead of just asking for navigator.plugins["Shockwave Flash"] by name. These websites should be fixed.
The policy of which plugin names are uncloaked can be changed in the about:config pref plugins.enumerable_names. The pref’s value is a comma-separated list of plugin name prefixes (so the prefix "QuickTime" will match both "QuickTime Plug-in 6.4" and "QuickTime Plug-in 7.7.3"). The default pref cloaks all plugin names except Flash, Shockwave (Director), Java, and QuickTime. To cloak all plugin names, set the pref to the empty string "" (without quotes). To cloak no plugin names, set the pref to magic value "*" (without quotes).
Fonts
System fonts collected by Flash or Java applet, if installed, and sent via AJAX post. Font list was not sorted, which provides a bit or two of additional entropy. We can ask Adobe to either limit this list by default; or ask them to implement an API such that we can provide the list to them; or (made possible by OOPP) replace the OS API calls they use to get the font list, and give them our own. None of these things are easy, but given that this is #1, we should definitely do something here. The fastest option is probably to hack the OS API calls ourselves.
Font lists can also be determined by CSS introspection. We could perhaps reduce the available set to a smaller number of common fonts; and back off (exponentially?) if script attempts to brute-force the list. Could require that sites provide unusual fonts via WOFF?
User Agent
Detected from HTTP header. Pretty simple fix, but has the potential for breakage (as with any UA change!). For instance: Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.1.7) Gecko/20100106 Ubuntu/9.10 (karmic) Firefox/3.5.7. Remedies: remove the last point digit in the Firefox and Gecko versions, and the Gecko build date; for Linux, remove distribution and version; possibly remove CPU. Windows is actually the least unique since the OS version string only identifies the major version (e.g. XP), and by far the majority of users are on it.
Remove language and "Firefox" as well?
Boris Zbarsky points out that most parts of the UA lead to bad sniffing. Irish "ga-IE" and "Minefield" get detected as IE. Sites incorrectly sniff based on OS. Sites sniff for Gecko years rather than Gecko versions. Going from 3.0.9 to 3.0.10 probably breaks things. And quite a few sites sniff for "Firefox", which is a threat to the continued freedom of the web. So removing things from the UA string has a long-term positive effect on compatibility as well as privacy.
- There is another issue with UA spoofing. For some reason, Components.classes and Components.interfaces exist in the content-window javascript namespace. Gregory Fleischer used this to test for the existence of ephemeral interfaces to fingerprint both OS and Firefox version, down to the minor revision (FF3.5.3 was the latest release at the time). He has a number of other fingerprinting demos you should investigate as well. -- mikeperry
HTTP ACCEPT
Example: text/html, */* ISO-8859-1,utf-8;q=0.7,*;q=0.7 gzip,deflate en- us,en;q=0.5. Not sure we can do much here?
Screen resolution
Example: 1280x800x24. Can't mess with this, except perhaps to always report "24" for the color depth -- of dubious value.
- Mapping "32" to "24" or vice versa in the color depth would reduce entropy by ~0.9 bits. May be worthwhile.
- Torbutton takes two countermeasures with respect to screen resolution: quantising AvailWidth and AvailHeight, and setting Width and Height to the values of AvailWidth and AvailHeight. Torbutton currently errs in not doing this if the window is maximised. These measures might be appropriate in private browsing mode. -- Pde 03:12, 15 June 2010 (UTC)
Timezone
Too useful to break.
The reported entropy includes only whether the following were enabled: DOM localStorage, DOM sessionStorage, and (for IE) userData. It did nottest Flash LSOs, Silverlight cookies, HTML5 databases, or DOM globalStorage. We can't do anything to prevent testing whether these are enabled, but we can lock them down for third parties, as we will with cookies.
For Flash and Silverlight we need to pressure them to implement better APIs for controlling and clearing stored data. This is undoubtedly more important than anything else on this list, though it was ignored in this study since it does not fit within their definition of fingerprinting. We could be aggressive here by using the new Flash API for private browsing mode very liberally; or do something with the OS APIs as mentioned above.
Cookies enabled
Irrelevant due to low amount of entropy.
Extra credit
Other fingerprinting methods were mentioned, but not included, in the study. A Gartner report on fingerprinting services was referenced in the study, which will undoubtedly be interesting to read.
Examples:
Other data acquired via plugins
Undoubtedly Flash and Java provide other interesting tidbits. ActiveX and Silverlight, for example, allow querying the "CPU type and many other details". More study needed here.
Clock skew measurements
"41st Parameter looks at more than 100 parameters, and at the core of its algorithm is a time differential parameter that measures the time difference between a user’s PC (down to the millisecond) and a server’s PC." We can't break the millisecond resolution of Date.now, but we could try adding a small (< 100ms) offset to it. This would be generated per-origin, and would last for some relatively short time: life of session, life of tab, etc. Would have to be careful that it can't be reversed.
- Clock skew measurement isn't really a browser issue; it tends to be exposed by the operating system at the TCP level. It would be appropriate to assume that an attacker can obtain 4-6 bits of information about the identity of a host by this method. -- Pde 02:55, 15 June 2010 (UTC)
- This is not 100% correct. According to RFC 1323 sections 3.2 and 4.2.2, timestamps may only be used if the initial syn packet (not syn+ack) contains a timestamp field. This is a property of the client OS, and may be controllable on some platforms. The timestamp value is also not absolute, but is typically some arbitrary number of milliseconds with no specific reference point. TLS also has a timestamp, but this value is fully controlled by Firefox. -- mikeperry
- Agree that one could turn off the TCP RTTM option at the OS layer. My naive intuition is that all modern OSes have this turned on, and turning it off would be a radical intervention bad for congestion avoidance and possibly fingerprintable itself. Note that clock skew is a function of how fast a clock ticks, not of what time the clock has. An arbitrary reference point is sufficient for measuring clock skew. -- Pde08:23, 9 December 2010 (PST)
- Note also that it's not just clock skew, but also clock precision that can allow for fingerprinting - both in terms of how long certain operations take on a system and in terms of user action. For example, Scout Analytics provides software to fingerprint users based on typing cadence. One can also imagine tight loops of timed javascript that fingerprint users based on certain resource-intensive calls. One possibility might be to quantize Date values to the second, and then add random, monotonically increasing amounts of milliseconds to subsequent calls during private browsing mode. -- mikeperry
TCP stack
"ThreatMetrix claims that it can detect irregularities in the TCP/IP stack and can pierce through proxy servers". Not sure what this means yet.
- nmap's host fingerprinting options (and source code) are the first place to start for understanding the TCP/IP stack issues. Again, there's not much the browser can do about that.
- As for "pierce through proxy servers", my best guess is that they use the raw socket infrastructure provided by Flash, which does not respect the browser's proxy settings, in order to learn the client's IP. Not sure if Java and Silverlight have similar problems. -- Pde 02:58, 15 June 2010 (UTC)
JS behavioral tests
Can be used to gather information about whether certain addons are installed, exact browser version, etc. Probably nothing we can do here.
"TorButton has evolved to give considerable thought to fingerprint resistance [19] and may be receiving the levels of scrutiny necessary to succeed in that project [15]. NoScript is a useful privacy enhancing technology that seems to reduce fingerprintability."
"We identified only three groups of browser with comparatively good resistance to fingerprinting: those that block JavaScript, those that use TorButton, and certain types of smartphone."
We should study what TorButton does, and see if we can integrate some of its features. We can also recommend it, NoScript, and Flashblock to users. We could suggest improvements to relevant addons, such as providing options for blocking third party but not first party content. (This doesn't strictly solve anything, but makes gathering the data more difficult, since the third party now relies on the first party to collect it.)
- Unfortunately Flashblock does not appear to prevent Flash from reading and writing LSOs, so it's doubtful it can be relied upon to protect against fingerprinting. -- Pde 03:00, 15 June 2010 (UTC)
User interface
Things like geolocation, database access and such require the user to grant permission for a given site. For geolocation, this is done with an infobar. We should do everything we can to make it clear to users what they're providing, and give them centralized control of those permissions in the privacy panel. This is what the UX privacy proposals seek to do.
HTML5 Canvas
"After plugins and plugin-provided information, we believe that the HTML5 Canvas is the single largest fingerprinting threat browsers face today." - Tor Project. Original research: Pixel Perfect: Fingerprinting Canvas in HTML5, demo: HTML5 Canvas Fingerprinting.
See Also

 浙公网安备 33010602011771号
浙公网安备 33010602011771号