复合数据类型介绍
复合数据类型介绍
一、什么是复合数据类型
基本数据类型是Go语言世界中的原子,以不同的方式组合基本数据类型得到的就是复合数据类型。复合类型是通过组合基础类型,来表达更加复杂的数据结构,即使用其他类型定义的类型,因而复合类型又称之为派生类型,数据类型分为值类型与引用类型。
二、值类型与引用类型
-
数值型复合类型:
-
数组(array)
-
结构体(struct)
-
-
引用型复合类型:
- 1 指针(pointer)
- 2 切片(slice)
- 3 字典(map)
- 4 通道(chan)
- 函数也属于引用类型
三、值类型
基础类型(数字、字符串、字符、布尔)以及数值型复合类型都属于值类型
对于值类型,即便我们在声明的时候都没有为其初始化值,那么编译器会依据它们的零值为它们申请好内存空间(分配于栈上),所以对于值类型我们都不必费心为其申请内存空间
var a int //int类型默认值为 0
var b string //string类型默认值为 空字串
var c bool //bool类型默认值为false
var d [2]int //数组默认值为[0 0]
fmt.Println(&a) //默认已经分配内存地址,所以我们可以直接使用&操作,取到的是一个合法的内存地址,而非nil
值类型的变量赋值操作,如 j = i ,实际上是在内存中将 i 的值进行了拷贝,如果修改某个变量的值i=3,不会影响另一个
var a =10 //定义变量a
b := a //将a的值赋值给b
b = 101 //修改b的值,此时不会影响a
fmt.Printf("值%v,内存地址%p\n",a,&a) //a的值是10,a的内存地址是0xc0000aa058
fmt.Printf("值%v,内存地址%p\n",b,&b) //b的值是101,b的内存地址是0xc0000aa070
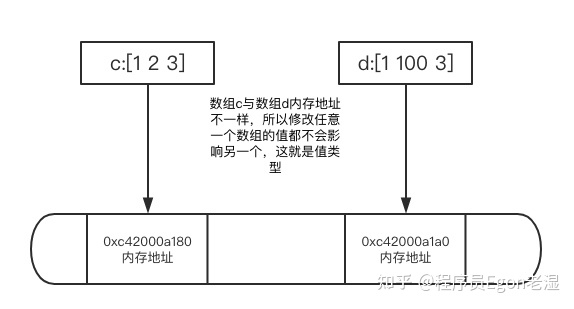
var c =[3]int{1,2,3} //定义一个长度为3的int类型的数组
d := c //将数组c赋值给d
d[1] = 100 //修改数组d中索引为1的值为100
fmt.Printf("值%v,内存地址%p\n",c,&c) //c的值是[1 2 3],c的内存地址是0xc0000ae090
fmt.Printf("值%v,内存地址%p\n",d,&d) //d的值是[1 100 3],d的内存地址是0xc0000ae0a8
值10,内存地址0xc0000aa058
值101,内存地址0xc0000aa070
值[1 2 3],内存地址0xc0000ae090
值[1 100 3],内存地址0xc0000ae0a8
三、引用类型
引用型复合类型(指针、切片、字典、通道)、函数、接口类型都属于引用类型。
对于引用类型,如果我们在声明的时候没有为其初始化“值”,那么默认零值为nil,nil代表空,编译器不会为其分配内存,而引用类型存在的意义在于引用了一个已经存在的内存空间,所以对于引用类型我们必须为其申请好内存才可以使用,需要用到函数new()和make()。
new()与make()的异同
相同点:
1. 都是针对引用类型的内存空间分配操作
2. 分配的内存都在堆上
3. 第一个参数都是一个类型,而不是一个值
不同点:
1. make 只用于引用类型map, slice, channel的内存分配,返回的还是这三个引用类型本身,而new返回的是一个指针
2. new多用于匿名变量的空指针操作,如new(int),new(string), new(array)等,而且内存置为零,此外,大多数场景下new并不常用
引用类型的变量赋值操作,如 j = i ,当然也是在内存中将 i 的值拷贝给了j,但是因为引用类型的变量直接存放的就是一个内存地址值(这个地址值指向的空间存的才是值),即i与j都是同一个地址。所以通过i或j修改对应内存地址空间中的值,另外一个也会修改。
var a = []int{1, 2, 3, 4, 5}
b := a //此时a,b都指向了内存中的[1 2 3 4 5]的地址
b[1] = 10 //相当于修改同一个内存地址,所以a的值也会改变
c := make([]int, 5, 5) //切片的初始化
copy(c, a) //将切片a拷贝到c
c[1] = 20 //copy是拷贝值、创建了新的底层数组,所以a不会改变
fmt.Printf("值a: %v,内存地址%p\n", a, &a)
fmt.Printf("值b: %v,内存地址%p\n", b, &b)
fmt.Printf("值c: %v,内存地址%p\n", c, &c)
d := &a //将a的内存地址赋值给d,取值用*d
a[1] = 11
fmt.Printf("值是d: %v,内存地址%p\n", *d, d) //d的值是[1 11 3 4 5],d的内存地址是0xc420084060
fmt.Printf("值是a: %v,内存地址%p\n", a, &a) //a的值是[1 11 3 4 5],a的内存地址是0xc420084060
值a: [1 10 3 4 5],内存地址0xc42000a180
值b: [1 10 3 4 5],内存地址0xc000004090
值c: [1 20 3 4 5],内存地址0xc0000040a8
值是d: [1 11 3 4 5],内存地址0xc000004078
值是a: [1 11 3 4 5],内存地址0xc000004078
a,b底层数组是一样的,即操作的都是同一个底层数组,但是上层切片不同,所以内存地址不一样。
引用类型的零值是nil,而nil只能与nil做相等性判断
// 例
var s []int // len(s) == 0, s == nil
s = nil // len(s) == 0, s == nil
s = []int(nil) // len(s) == 0, s == nil
s = []int{} // len(s) == 0, s != nil 此时不等于nil,而该切片仍然是空,所以如果你需要测试一个slice是否是空的,使用len(s) == 0来判断,而不应该用s == nil来判断
// 思考题
var a []string //声明一个字符串切片,初始零值为?
fmt.Printf("%#v\n",a) // []string(nil)
fmt.Println(a == nil) //true
var b []int // 声明一个整型切片,初始零值为?
fmt.Printf("%#v\n",b) // []int(nil)
fmt.Println(b == nil) //true
var c = []int{} //声明一个整型切片并初始,化初始零值为?
fmt.Printf("%#v\n",c) // []int{}
fmt.Println(c == nil) //false
关于函数
函数的参数传递机制是将实参的值拷贝一份给形参.只不过这个实参的值有可能是地址, 有可能是数据.
所以, 函数传参的传递其实本质全都是值传递,只不过该值有可能是数据(通常被简称为”值传递“),也有可能是地址(通常被简称为”引用传递“).
